Schedule Machine Learning Designer pipelines offline with DataWorks tasks to update models periodically and sync them to OSS.
Prerequisites
-
All nodes in a pipeline run successfully.
-
DataWorks is activated and a workflow is created. For more information, see Create a workflow.
Ensure the workflow workspace matches your Machine Learning Designer pipeline workspace. Otherwise, setting the Path parameter to the workflow when creating an offline scheduling task will fail.
-
If the DataWorks workflow workspace operates in standard mode, synchronize the model generated by offline training to the production environment before scheduling periodical tasks because MaxCompute isolates data between development and production environments. For more information, see Periodically schedule a batch prediction pipeline.
Procedure
The ratio of PAI-Designer pipeline to Designer nodes in DataWorks is 1:N—create multiple Designer nodes in DataWorks based on the same PAI-Designer pipeline.
-
Log on to the PAI console, select a workspace, and click Enter Visualized Modeling (Designer). Double-click a pipeline to open it.
-
(Optional) Add the Model Export component to synchronize a model in Machine Learning Designer to OSS during periodical task scheduling.
-
On the Pipeline Attributes tab, set Data Storage to the OSS path where the model file is stored.
-
To export a model file in PMML format, click the model component (such as Logistic Regression for Binary Classification) and select Whether To Generate PMML on the Fields Setting tab.
NoteOnly specific model components support exporting model files in the PMML format. Skip this step for model components that do not support this feature.
-
Connect the model component to the downstream Model Export component. For more information, see Export a general-purpose model.
-
-
Schedule a Machine Learning Designer pipeline offline with DataWorks tasks.
-
In the upper-left corner of the canvas, click Periodic Scheduling. In the dialog box, click Create Scheduling Node. In the Create Node dialog box in DataWorks, specify a node name and click Confirm.
-
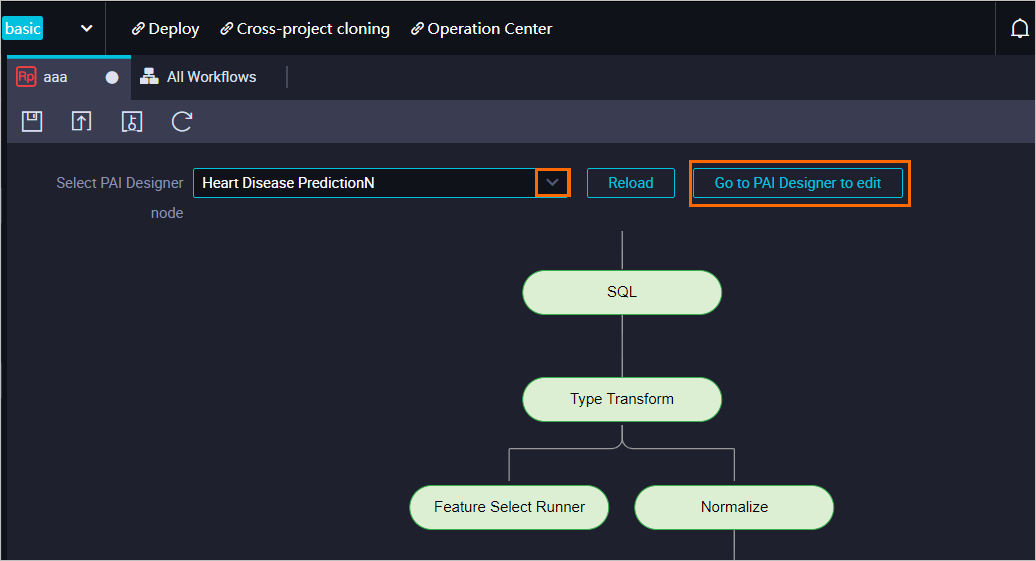
On the node edit page, select the pipeline created in Machine Learning Designer from the Select PAI Designer Experiment drop-down list.
To modify the pipeline in Machine Learning Designer, click Edit in PAI Designer.
-
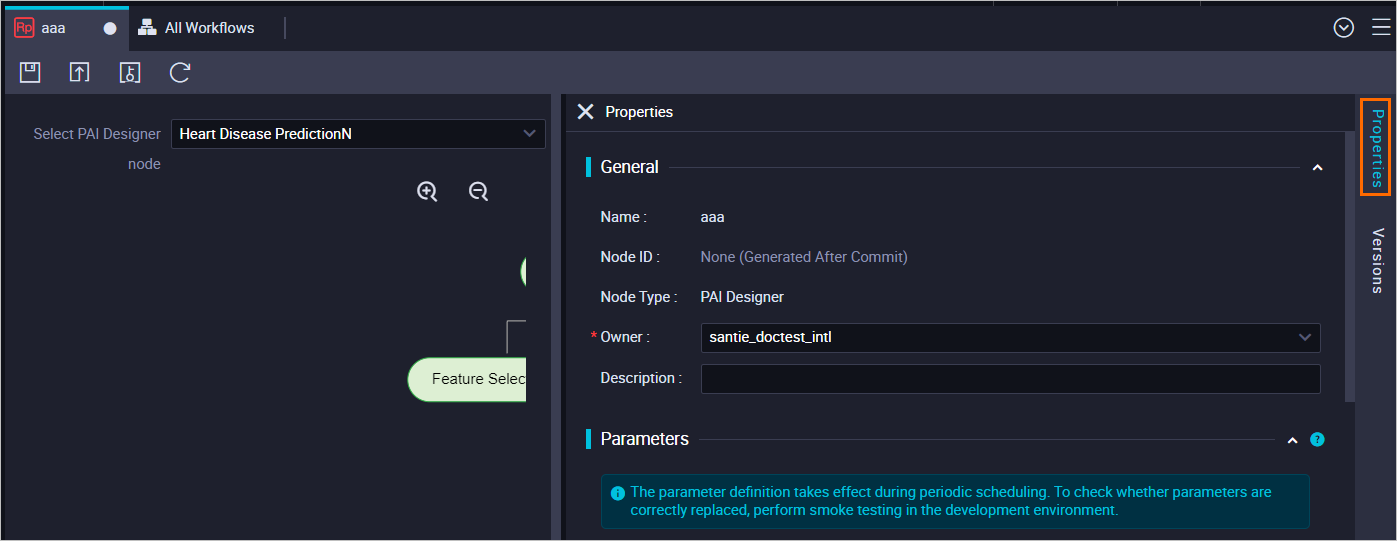
On the node edit tab, click the Properties tab in the right-side navigation pane. In the Properties panel, configure scheduling properties for the node.
The Properties panel contains the General, Scheduling Parameter, Schedule, Resource Group, and Dependencies sections. Specify a scheduling cycle in the Schedule section. DataWorks automatically runs the pipeline based on the specified scheduling cycle. For more information, see Configure scheduling properties.
NoteDuring scheduling in DataWorks, the system may report errors related to "Start Container timeout" due to occasional timeout issues. Enable the Auto Rerun upon Failure feature when configuring time properties to automatically rerun failed pipelines (excluding user-stopped pipelines) based on the specified number of reruns and rerun interval.
-
Click the
 and
and  icons in the toolbar and follow on-screen instructions to save and commit the node. Important
icons in the toolbar and follow on-screen instructions to save and commit the node. ImportantConfigure the Rerun and Parent Nodes parameters in the Properties panel before committing the node.
If the workspace operates in standard mode, click Deploy in the upper part of the page after committing a node. For more information, see Publish tasks.
-
Click Operation Center in the upper part of the page to view the status and operational logs of the machine learning task.
Backfill data for the node and test the pipeline as needed. For more information, see Manage auto-triggered tasks.
-
References
-
For more information about model prediction and deployment, see Model prediction and deployment.
-
Machine Learning Designer supports using the Update EAS Service(Beta) component to update online model services. For more information, see Periodically update online model services.