Accelerate data lake queries
Hologres integrates with Alibaba Cloud Data Lake Formation (DLF) and Object Storage Service (OSS) to let you run SQL queries directly against data in your OSS data lake — without moving the data into Hologres. Hologres pushes query execution to the data rather than pulling the data into the warehouse, so you get SQL analytics on large OSS datasets while avoiding duplication and import costs. Using foreign tables, Hologres maps your OSS data in place and queries it through standard SQL while the data stays in OSS.
What you'll learn
In this tutorial, you'll learn how to:
Activate OSS, DLF, and Hologres and load test data
Configure Hologres to connect to your OSS data lake
Query OSS data using Hologres foreign tables (no data movement)
Import OSS data into Hologres internal tables for higher-performance queries
How it works
Hologres uses the foreign data wrapper (FDW) mechanism to connect to DLF, which manages metadata for your OSS data lake. When you run a query against a foreign table, Hologres reads the data directly from OSS — no import required. Query performance is typically in the seconds-to-minutes range depending on data volume.
Foreign tables support data in these formats stored in OSS: Hudi, Delta, Paimon, ORC, Parquet, CSV, and SequenceFile.
For consistently faster queries or complex join-heavy workloads, import the data into Hologres internal tables. Internal tables store data inside Hologres and deliver better query performance and higher data processing throughput, but they incur additional storage costs. See Billing overview.
The following services work together in this solution:
Service | Role |
Object Storage Service (OSS) | Data lake storage — stores the raw data files |
Data Lake Formation (DLF) | Unified metadata catalog — tracks databases, tables, and schemas for OSS data |
Hologres | Query engine — accelerates analytics on OSS data using SQL |
Usage notes
Hologres shared clusters only support querying OSS data lakes using foreign tables.
Prerequisites
Before you begin, ensure that you have:
An Alibaba Cloud account with permissions to activate OSS, DLF, and Hologres
Superuser access to the Hologres instance (required to create extensions and foreign servers)
Prepare the environment
This tutorial uses the China (Shanghai) region as an example.
Step 1: Activate OSS and upload test data
Go to the OSS activation page and follow the on-screen instructions to activate the service.
NoteAfter you activate the OSS service, the default billing method is pay-as-you-go. To lower your OSS usage costs, we recommend that you purchase a resource plan.
Log in to the OSS console and create a bucket. For details, see Console quick start.
Download tpch_10g_orc_3.zip and upload it to a folder in your bucket.
The package contains only the
nation_orc,supplier_orc, andpartsupp_orctables used in this tutorial. After uploading, delete any system-generated files such as.DS_Store.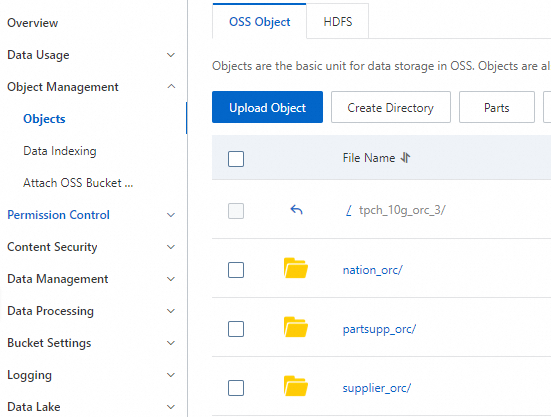
Step 2: Activate DLF and import metadata
Go to the DLF activation page and activate the service.
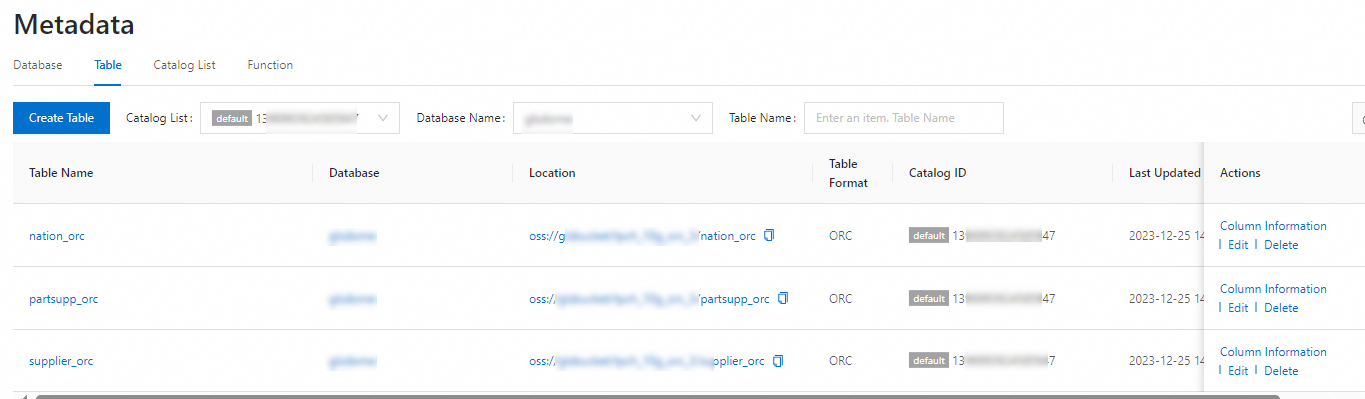
Log in to the DLF-Legacy console. On the Metadata Management page, click Create Database. This tutorial uses a database named
mydatabase. For details, see Databases, tables, and functions.On the Metadata Discovery page, create a job to import the OSS test data. For details, see Metadata discovery. After the job completes, the imported tables appear on the Table tab of the Metadata page.
Step 3: Purchase a Hologres instance
Purchase a Hologres instance by following the instructions in Purchase a Hologres instance.
Configure Hologres for data lake acceleration
Step 1: Enable the data lake acceleration feature
Go to the Hologres instances page. In the Actions column of your instance, click Lake Acceleration and confirm. The instance restarts after enabling this feature.
Step 2: Create a database
Log in to the Hologres instance and create a database. For details, see Connect and query with HoloWeb.
Step 3: Create the required extensions
Hologres V2.1 and later create the dlf_fdw extension by default. Check your instance version on the Instance Details page in the Hologres instance list. If your version is V2.1 or later, skip this step.Run the following statements as a superuser in the SQL Editor in HoloWeb. These operations apply to the entire database and only need to be performed once per database. For information about granting superuser permissions, see Grant permissions to a service account.
Create the
plpython3uextension:CREATE EXTENSION IF NOT EXISTS plpython3u;Enable the
dlf_fdwextension:CREATE EXTENSION IF NOT EXISTS dlf_fdw;
Step 4: Create a foreign server
Run the following statement to create a foreign server named dlf_server. This configures the endpoint information that Hologres uses to communicate with DLF and OSS. For parameter details, see Create a foreign server.
-- China (Shanghai) region example
CREATE SERVER IF NOT EXISTS dlf_server FOREIGN DATA WRAPPER dlf_fdw OPTIONS (
dlf_region 'cn-shanghai',
dlf_endpoint 'dlf-share.cn-shanghai.aliyuncs.com',
oss_endpoint 'oss-cn-shanghai-internal.aliyuncs.com'
);Query OSS data using foreign tables
A Hologres foreign table maps to data stored in OSS — the data itself stays in OSS and does not consume Hologres storage. Use foreign tables for ad hoc queries or when you want to avoid data duplication.
Tip: Keep large fact tables in OSS and query them as foreign tables. Import frequently joined dimension tables into Hologres as internal tables to get the best balance of cost and performance.
Step 1: Map OSS tables to Hologres foreign tables
-- Replace "mydatabase" with the name of your database in DLF.
IMPORT FOREIGN SCHEMA mydatabase LIMIT TO
(
nation_orc,
supplier_orc,
partsupp_orc
)
FROM SERVER dlf_server INTO public OPTIONS (if_table_exist 'update');Step 2: Run a query
After creating the foreign tables, query them directly. The following TPC-H Q11 example joins three tables across the OSS data lake:
-- TPC-H Q11: identify the most important subset of suppliers' parts
SELECT
ps_partkey,
SUM(ps_supplycost * ps_availqty) AS value
FROM
partsupp_orc,
supplier_orc,
nation_orc
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND RTRIM(n_name) = 'EGYPT'
GROUP BY ps_partkey
HAVING
SUM(ps_supplycost * ps_availqty) > (
SELECT SUM(ps_supplycost * ps_availqty) * 0.000001
FROM partsupp_orc, supplier_orc, nation_orc
WHERE ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND RTRIM(n_name) = 'EGYPT'
)
ORDER BY value DESC;The query returns rows ranked by part value. Results reflect data read live from OSS.
(Optional) Query OSS data using internal tables
Import OSS data into Hologres internal tables when you need faster, repeated queries or complex analytics. Internal tables store data inside Hologres for optimal query performance, but storage fees apply. See Billing overview.
Step 1: Create internal tables
-- Create the nation table
DROP TABLE IF EXISTS NATION;
BEGIN;
CREATE TABLE NATION (
N_NATIONKEY int NOT NULL PRIMARY KEY,
N_NAME text NOT NULL,
N_REGIONKEY int NOT NULL,
N_COMMENT text NOT NULL
);
CALL set_table_property('NATION', 'distribution_key', 'N_NATIONKEY');
CALL set_table_property('NATION', 'bitmap_columns', '');
CALL set_table_property('NATION', 'dictionary_encoding_columns', '');
COMMIT;
-- Create the supplier table
DROP TABLE IF EXISTS SUPPLIER;
BEGIN;
CREATE TABLE SUPPLIER (
S_SUPPKEY int NOT NULL PRIMARY KEY,
S_NAME text NOT NULL,
S_ADDRESS text NOT NULL,
S_NATIONKEY int NOT NULL,
S_PHONE text NOT NULL,
S_ACCTBAL DECIMAL(15, 2) NOT NULL,
S_COMMENT text NOT NULL
);
CALL set_table_property('SUPPLIER', 'distribution_key', 'S_SUPPKEY');
CALL set_table_property('SUPPLIER', 'bitmap_columns', 'S_NATIONKEY');
CALL set_table_property('SUPPLIER', 'dictionary_encoding_columns', '');
COMMIT;
-- Create the partsupp table
DROP TABLE IF EXISTS PARTSUPP;
BEGIN;
CREATE TABLE PARTSUPP (
PS_PARTKEY int NOT NULL,
PS_SUPPKEY int NOT NULL,
PS_AVAILQTY int NOT NULL,
PS_SUPPLYCOST DECIMAL(15, 2) NOT NULL,
PS_COMMENT text NOT NULL,
PRIMARY KEY (PS_PARTKEY, PS_SUPPKEY)
);
CALL set_table_property('PARTSUPP', 'distribution_key', 'PS_PARTKEY');
CALL set_table_property('PARTSUPP', 'bitmap_columns', 'ps_availqty');
CALL set_table_property('PARTSUPP', 'dictionary_encoding_columns', '');
COMMIT;Step 2: Import data from foreign tables
INSERT INTO nation SELECT * FROM nation_orc;
INSERT INTO supplier SELECT * FROM supplier_orc;
INSERT INTO partsupp SELECT * FROM partsupp_orc;Step 3: Run a query
-- TPC-H Q11 against internal tables
SELECT
ps_partkey,
SUM(ps_supplycost * ps_availqty) AS value
FROM
partsupp,
supplier,
nation
WHERE
ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND RTRIM(n_name) = 'EGYPT'
GROUP BY ps_partkey
HAVING
SUM(ps_supplycost * ps_availqty) > (
SELECT SUM(ps_supplycost * ps_availqty) * 0.000001
FROM partsupp, supplier, nation
WHERE ps_suppkey = s_suppkey
AND s_nationkey = n_nationkey
AND RTRIM(n_name) = 'EGYPT'
)
ORDER BY value DESC;Internal table queries return the same results as the foreign table query, but significantly faster for repeated or complex workloads.
Clean up
To avoid ongoing storage charges after completing this tutorial, delete the resources you created:
Drop the internal tables in Hologres:
DROP TABLE IF EXISTS NATION; DROP TABLE IF EXISTS SUPPLIER; DROP TABLE IF EXISTS PARTSUPP;Drop the foreign tables:
DROP FOREIGN TABLE IF EXISTS nation_orc; DROP FOREIGN TABLE IF EXISTS supplier_orc; DROP FOREIGN TABLE IF EXISTS partsupp_orc;Drop the foreign server:
DROP SERVER IF EXISTS dlf_server;Delete the test data from your OSS bucket or delete the bucket itself using the OSS console.
Troubleshooting
Error: ERROR: babysitter not ready,req:name:"HiveAccess"
The data lake acceleration feature is not enabled on your instance. Go to the Hologres instances page, click Lake Acceleration in the Actions column, and confirm to enable it.
What's next
This tutorial covered a basic end-to-end flow using test data. For a complete description of the data lake acceleration feature, including all supported parameters and configurations, see Speed up access to OSS with DLF.