Realtime Compute for Apache Flink supports two monitoring services — Cloud Monitor (free) and Managed Service for Prometheus (ARMS) — each offering metric-based and event-based alerts. This guide walks you through configuring alert rules for both services.
Limitations
Alert rules are not supported for Flink jobs running on session clusters.
Alert rules are not supported for batch jobs.
Workflow alerts are only available with Cloud Monitor.
ARMS event-based alerts support only
Job Failedevents. For other event types, use Cloud Monitor.
Choose your monitoring service
Your workspace uses either Cloud Monitor or ARMS depending on what you selected at creation. To verify which service your workspace uses, see How do I check the monitoring service type for my workspace?.
Alert type | Cloud Monitor | ARMS |
Metric-based | Key metrics; applies to single jobs or batches of jobs | Six key metrics; single job only |
Event-based |
|
|
To switch the monitoring service for your workspace, click  in the Actions column of your workspace on the Management Console.
in the Actions column of your workspace on the Management Console.
Read the prompt carefully before confirming the switch.
Recommended alerts
Before diving into configuration steps, the following table summarizes the alerts recommended for most Flink deployments. Configure these first to establish a baseline monitoring setup.
Metric | Alert type | Service | Recommended threshold | Why it matters |
| Metric-based | Cloud Monitor or ARMS | Any failure (>= 1) | Fires immediately when a job fails. Recommended for all applications. |
| Metric-based | ARMS | Observe your application under normal conditions, then set the threshold above the normal restart rate | Repeated restarts may indicate instability before a full failure occurs. |
| Metric-based | ARMS | Observe normal checkpoint frequency, then set the threshold below the minimum acceptable count | Consistently low checkpoint counts can signal that a job is making insufficient progress. |
| Metric-based | ARMS | Observe normal latency, then set the threshold above the acceptable maximum | Use composite metric alerts for more reliable latency monitoring. See Recommended monitoring configurations. |
Job failure events ( | Event-based | Cloud Monitor | N/A | Event-based job failure alerts complement metric-based alerts and can include ECS system events. |
To determine thresholds for metric-based alerts, monitor your application under normal operating conditions first. Use those observations as your baseline before setting alert thresholds.
Configure alert rules with Cloud Monitor
Prerequisites
To configure alert rules with Cloud Monitor, log on with your Alibaba Cloud account or as a RAM identity with the necessary permissions in the target namespace.
Metric-based alerts
Use metric-based alerts to monitor key performance indicators such as CPU usage, latency, or throughput across single jobs or batches of jobs.
Log on to the Cloud Monitor console.
In the left navigation pane, choose Alerts > Alert Rules.
Click Create Alert Rule and configure the following parameters. For other parameters, see Create an alert rule.
Single metric alerts can cause false positives or negatives in production. Composite metric alerts give a more accurate picture of actual business anomalies. For details, see Recommended monitoring configurations.
Parameter
Description
Product
Select Flink.
Resource Range
Select Instances. The alert rule applies to a specific Flink workspace.
Associated Resources
Click Add Instance. In the dialog, select your region and workspace (how to view your workspace ID), then click OK.
Rule Description
Click +Add Rule > Simple Metric or Combined Metrics to open the Configure Rule Description panel. After selecting a metric, the Dimension section appears. Configure namespace and deploymentId to monitor a specific job deployment, or leave them blank to monitor all job deployments across all namespaces. If the drop-down lists are empty, enter the values manually.
Click OK.
Event-based alerts
Use event-based alerts to get notified when specific system or workflow events occur, such as a job failure.
System event alerts
Subscribe to system events for single or multiple jobs.
Log on to the Cloud Monitor console.
In the left navigation pane, choose Event Center > Event Subscription.
On the Subscription Policy tab, click Create Subscription Policy.
On the Create Subscription Policy page, configure the following parameters. For other parameters, see Manage event subscriptions (Recommended).
Leaving Application group, Event Content, or Event Resources blank applies the subscription to all workspaces in your account.
Parameter
Description
Subscription Type
Select System Events.
Products
Select Flink.
Event name
Supported events:
JOB_FAILED,ECS.SystemFailure, andECS.SystemMaintenance.Event Content
Optionally, scope the alert to specific resources: <br>- Workspace ID: applies the rule to all jobs in that workspace. To get your workspace ID, see How do I view information such as the workspace ID? <br>- Namespace name: applies the rule to all jobs in that namespace. <br>- Deployment name: applies the rule to specific job deployments. Separate multiple names with commas (
,). Use the deployment ID when duplicate deployment names exist. <br>- Deployment ID: applies the rule to specific job deployments. Separate multiple IDs with commas (,). Get the deployment ID from the deployment details page.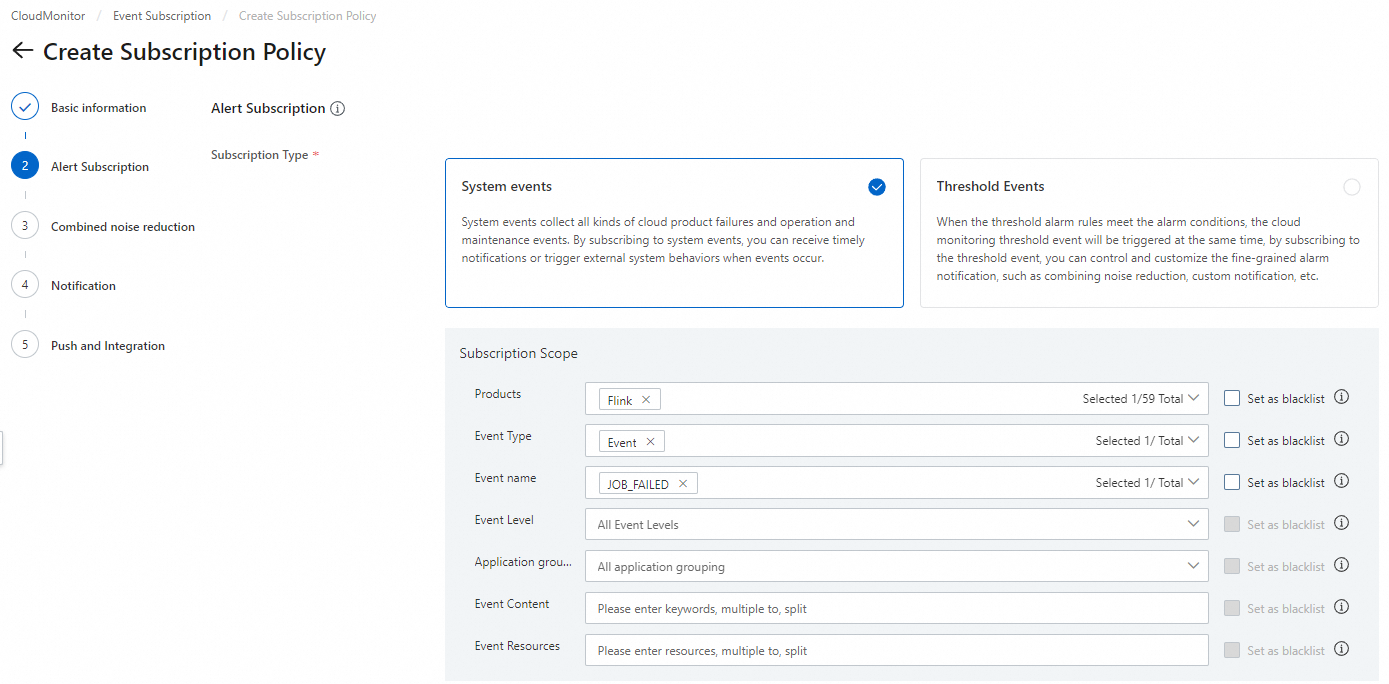
Workflow event alerts
Subscribe to workflow state-change events. For workflow details, see Manage workflows.
Step 1: Get the resource ID of the workflow task
Log on to the Cloud Monitor console.
In the left navigation pane, choose Event Center > System Event.
On the Event Monitoring tab, set SelectProduct to Flink, set SelectEvent Name to
flink:Workflow:TaskStateChange, and click Search.From the results, find the resource ID for your workflow task. The resource ID follows this format:
Workflow task state changes typically appear in Cloud Monitor with a delay of a few minutes.
Placeholder
Description
<AlibabaCloudAccountID>The ID of the Alibaba Cloud account that owns the Flink workspace.
<workspaceId-namespaceId>The workspace ID and namespace name joined by a hyphen (
-). For the workspace ID, see How do I view information such as the workspace ID?.<workflowDefinitionName>The workflow name.
<taskDefinitionName>The workflow task name.
acs:flink:cn-hangzhou:<AlibabaCloudAccountID>:resourceId/workspaceId/<workspaceId-namespaceId>#workflowDefinitionName/<workflowDefinitionName>#taskDefinitionName/<taskDefinitionName>You can also construct the resource ID directly using this format instead of searching for it.

Step 2: Create an event subscription
In the left navigation pane, choose Event Center > Event Subscription.
On the Subscription Policy tab, click Create Subscription Policy.
Configure the following parameters. For other parameters, see Manage event subscriptions (Recommended).
Parameter
Value
Subscription Type
System Events
Products
Flink
Event name
flink:Workflow:TaskStateChangeEvent Content
Filter by the target transition state. Examples:
toState: FAILED,toState: SUCCESS,fromState: SCHEDULED, toState: RUNNING.Event Resources
Enter the resource ID from Step 1. Separate multiple IDs with commas (
,).Event Type, Event Level, Application group
Leave blank.
Configure alert rules with ARMS
ARMS supports alert rules for six key metrics on individual job deployments. To monitor multiple metrics in a single rule, use a custom PromQL statement to create an alert rule. For broader coverage across multiple jobs, configure alert rules with Cloud Monitor instead.
The Development Console shows alert events from the last 48 hours only. For older alert history, go to Alert Management in the ARMS console.
Metric-based alerts
Single job configuration (Development Console)
Configure alert rules for a specific job from the Development Console, either from scratch or from a template.
Log on to Realtime Compute for Apache Flink's Management Console and click Console in the Actions column of your workspace.
In the left navigation pane, choose O&M > Deployments, then click your job deployment.
Select the Alarm tab, then the Alarm Rules subtab.
Click Add Rule > Custom Rule (or Create Rule by Template).
Enter the alert rule information. Content section Configure the conditions that trigger the alert. Flink periodically compares actual metric values against the threshold and fires an alert when a condition is met. Example: Monitoring
Checkpoint Count in 5 Minuteswith a time interval of 10 minutes, threshold of 2, and<=comparator — Flink checks every minute over a 10-minute window and fires an alert if the minimum successful checkpoint count within any 5-minute period drops to 2 or fewer. Effective Time The time window when the alert rule is active. Defaults to all day. Restrict to specific hours if needed, such as business hours (9 AM–6 PM). Alarm Rate The interval between repeated alert notifications, in minutes. Range: 1–1440 minutes (24 hours).Rule section
Parameter
Description
Name
The alert rule name. Must start with a letter and can contain lowercase letters, digits, and underscores (
_). Length: 3–64 characters.Description
Optional notes about the rule.
Parameter
Description
Metric
The metric to monitor. See Metric reference for available options and their alert logic.
Time Interval
The length of the historical data window queried on each check, in minutes.
Comparator
>=compares the maximum metric value against the threshold; alerts whenmax_value >= threshold.<=compares the minimum metric value; alerts whenmin_value <= threshold.Thresholds
The value to compare against the metric. Monitor your application under normal conditions to determine an appropriate baseline before setting this value.
Notification section
Parameter
Description
Notification
Select one or more notification methods: DingTalk, Email, SMS, Webhook, or Phone. Each selected method must have a corresponding notification object configured. For Phone notifications, make sure the recipient's number is verified — if the Unverified tag appears on the Contacts tab, click it to complete verification.
ImportantEnsure your chosen notification method has a corresponding notification object configured. For DingTalk, this means adding a DingTalk robot notification object after selecting DingTalk as the method.
Notification object
Select one or more notification objects. Click Notification object management to create objects. For details, see Workspace and namespace FAQ.
Advanced Settings
Option
Description
Alarm Noise Reduction
When enabled, alerts fire only when the threshold is met continuously. This prevents noise from temporary issues such as brief failovers during cluster scheduling or auto-tuning.
No Data Alarms
Fires an alert if no monitoring data is reported within the specified duration. Common causes: JobManager exceptions, job stops, or reporting pipeline failures.
Click OK. The alert rule is automatically enabled and appears in the alert rule list. You can stop, edit, or delete rules from the list.
Metric reference
Metric | Description | Unit | When to alert | Suggested action when triggered |
| Number of job restarts in the past minute. | Count | When restarts exceed the normal baseline | Check job logs for root causes. Repeated restarts may indicate resource contention or code-level exceptions. |
| Number of successful checkpoints in any 5-minute window. | Count | When count drops below the minimum acceptable level | Investigate checkpoint failures. Common causes: insufficient memory, backpressure, or slow state storage. |
| Business latency from data generation to source egress. Accuracy depends on timestamps from upstream systems — configure composite metric alerts for more reliable latency monitoring. See Recommended monitoring configurations. | Seconds | When latency exceeds your application's tolerance | Check source backpressure, downstream sink bottlenecks, or resource saturation. |
| Input records per second. | Records/s | When throughput drops unexpectedly below normal baseline | Check source connectivity and upstream data availability. |
| Output records per second. | Records/s | When throughput drops unexpectedly below normal baseline | Check sink connectivity and downstream system health. |
| Duration the source operator was not processing data. | Milliseconds | When idle time exceeds your tolerance for data gaps | Check whether the upstream data source has stopped producing data or the source connector has stalled. |
| Triggers when the job fails. Use this metric to configure a job failure alert. | — | Any failure | Review job logs and restart the job. If the issue recurs, check resource limits and code exceptions. |
Event-based alerts
ARMS supports event-based alerts for job failure events only. To configure a job failure alert, follow the metric-based alert steps and select Job Failed as the metric.
For other event types, use Cloud Monitor event-based alerts.
FAQ
How do I check the monitoring service type for my workspace?
You select the monitoring service type when creating a workspace. To verify it after creation, go to O&M > Deployments and click your job deployment name. If the Alarm tab appears, the workspace uses ARMS. If it doesn't appear, the workspace uses Cloud Monitor.

How do I add a DingTalk robot for alerts in the Development Console?
Add a custom DingTalk robot and get its webhook URL.
ImportantIn Security Settings, select Custom Keywords and set at least one keyword to Alert to receive alert messages.
Add a notification object.
Go to O&M > Deployments, click your job deployment name, and select the Alarm tab.
Click Add Rule > Custom Rule or Create Rule by Template.
In the panel, click Notification object management.
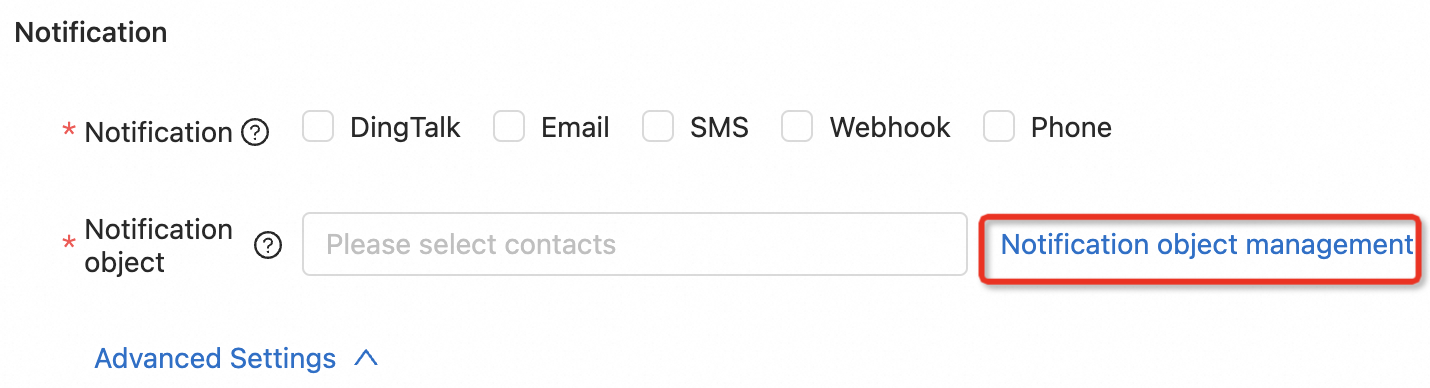
In the dialog, select the DingTalk tab and click Add DingTalk. Enter the robot name and webhook URL, then click Submit.
In the Create Rule or Create Rule Template panel, set Notification to DingTalk and Notification object to your DingTalk robot.
Click OK.
How do I create a webhook in the Development Console?
In the Create Rule or Create Rule Template panel, click Notification object management.
Select the Webhook tab and click Add Webhook.
Fill in the webhook details.
Parameter
Required
Description
Name
Yes
The webhook name.
URL
Yes
The webhook endpoint URL.
Headers
No
Request headers for cookies or tokens. Format:
key: value(space after the colon).Params
No
Request parameters. Format:
key: value(space after the colon).Body
Yes
The POST request body. Use the
$contentplaceholder to include the alert content in the body.Click OK.