The aliyun-knn plug-in is a vector search engine developed by the Alibaba Cloud Elasticsearch team. It uses the vector library of Proxima, a vector search engine designed by Alibaba DAMO Academy. This plug-in can meet your requirements on vector searches in various scenarios, such as image search, video fingerprinting, facial and speech recognition, and commodity recommendation. This topic describes how to use the aliyun-knn plug-in.
This topic is for reference only. The aliyun-knn plug-in is used by existing Elasticsearch clusters of earlier versions.
We recommend that you purchase an Elasticsearch cluster of V8.15 or later. This way, you can directly use the native vector search capabilities provided by the engine kernel to implement new vector search business.
Background information
Use scenarios
The vector search engine of Alibaba Cloud Elasticsearch is used in numerous production scenarios inside Alibaba Group, such as Pailitao, Image Search, Youku video fingerprinting, Qutoutiao video fingerprinting, Taobao commodity recommendation, customized searches, and Crossmedia searches.
Principle
The vector search feature of Alibaba Cloud Elasticsearch is implemented based on the aliyun-knn plug-in. The plug-in is compatible with all versions of open source Elasticsearch. Therefore, you can use the plug-in without additional learning costs. In addition to real-time incremental synchronization and near-real-time (NRT) searches, vector indexes support the other features of open source Elasticsearch in distributed searches. The features include multiple replica shards and restoration.
NoteThe aliyun-knn plug-in does not support data migration that is performed by using snapshots in Object Storage Service (OSS) or by using DataWorks. If you want to migrate data, we recommend that you use Logstash.
Algorithms
The aliyun-knn plug-in supports the Hierarchical Navigable Small World (HNSW) and Linear Search algorithms. These algorithms are suitable for processing small amounts of data from in-memory storage. The following descriptions provide comparison between the performance of the algorithms.
Table 1. Comparison between the performance of HNSW and Linear Search
The following table lists the performance metrics of the two algorithms on an Alibaba Cloud Elasticsearch V6.7.0 cluster. Configurations of the test environment:
Cluster configuration: two data nodes, each of which offers 16 vCPUs, 64 GiB of memory, and one 100-GiB standard SSD
Datasets: SIFT 128-dimensional float-type vectors
Total data records: 20 million
Index settings: default settings
Performance metric
HNSW
Linear Search
Top-10 recall ratio
98.6%
100%
Top-50 recall ratio
97.9%
100%
Top-100 recall ratio
97.4%
100%
Latency (p99)
0.093s
0.934s
Latency (p90)
0.018s
0.305s
Notep is short for percentage. For example, latency (p99) indicates the number of seconds that are required to respond to 99% of queries.
Prerequisites
The aliyun-knn plug-in is installed. Whether this plug-in is installed by default is determined by your Elasticsearch cluster version and the kernel version of your Elasticsearch cluster.
Cluster version
Kernel version
Description
V6.7.0
Earlier than V1.2.0
You must manually install the aliyun-knn plug-in on the Plug-ins page of the Elasticsearch console based on the instructions provided in Install and remove a built-in plug-in.
You cannot use the script query and index warm-up features of the aliyun-knn plug-in. If you want to use these features, we recommend that you use an Elasticsearch cluster with the AliES kernel. For more information, see AliES release notes.
When you create a vector index, you can set the
distance_methodparameter only to its default valueSquaredEuclidean.
V6.8
None
V7.4
None
V7.7
None
V6.7.0
V1.2.0 or later
The aliyun-knn plug-in is integrated into the apack plug-in, which is installed by default. If you want to remove or reinstall the aliyun-knn plug-in, you must perform operations on the apack plug-in. For more information, see Use the physical replication feature of the apack plug-in.
You can use the script query and index warm-up features and extended functions of the aliyun-knn plug-in. Before you use the features and functions, make sure that the kernel version of your cluster is V1.3.0 or later. For more information, see Upgrade the version of a cluster.
If a mapping parsing error is reported when you create a vector index, upgrade the kernel version of your cluster to V1.3.0 or later and try again.
V7.10.0
V1.4.0 or later
The aliyun-knn plug-in is integrated into the apack plug-in, which is installed by default. If you want to remove or reinstall the aliyun-knn plug-in, you must perform operations on the apack plug-in. For more information, see Use the physical replication feature of the apack plug-in.
If the kernel version of your cluster is V1.4.0 or later, the version of the apack plug-in is the latest. You can run the GET _cat/plugins?v command to obtain the version of the apack plug-in.
Other versions
None
The vector search feature is not supported.
NoteThe kernel version is different from the version of the apack plug-in. You can run the GET _cat/plugins?v command to obtain the version of the apack plug-in.
Indexes are planned for your cluster.
Algorithm
Use scenario
In-memory storage
Remarks
HNSW
Each node stores only small volumes of data.
A low response latency is required.
A high recall ratio is required.
Yes
HNSW is based on the greedy search algorithm and obeys triangle inequality. Triangle inequality states that the total sum of the costs from A to B and the costs from B to C must be greater than the costs from A to C. Inner product spaces do not obey triangle inequality. In this case, you must convert them to Euclidean spaces or spherical spaces before you use the HNSW algorithm.
After you write data to your Alibaba Cloud Elasticsearch cluster, we recommend that you call the force merge API on a regular basis during off-peak hours to merge the segments in shards. This reduces the response latency.
Linear Search
Brute-force searches need to be performed.
A recall ratio of 100% is required.
Latency increases with the volume of the data that needs to be processed.
Effect comparison is required.
Yes
None.
Your cluster is planned.
Item
Description
Data node specifications (required)
The data node specifications must be 16 vCPUs and 64 GiB of memory or higher.
NoteWhen you use the aliyun-knn plug-in to create indexes, numerous computing resources are required. If the data node specifications of your cluster are small, bottlenecks may easily occur. In severe cases, cluster stability may be affected. Therefore, we recommend that you use a cluster whose data node specifications are 16 vCPUs and 64 GiB of memory or higher.
Node type
Your cluster must contain independent dedicated master nodes.
Off-heap memory size
The off-heap memory size of your cluster must be greater than twice the total size of vector data in your cluster.
For example, an index contains only one 960-dimensional float-type field. The index contains 400 documents, and float-type data occupies 4 bytes of memory. In this case, the vector data in the index occupies 1.5 MB of memory, which is calculated by using the following formula: 960 × 400 × 4. Therefore, you must make sure that the off-heap memory size of the cluster is greater than 3 MB, which is calculated by using the following formula: 1.5 × 2.
NoteDuring forced merging, both old data and new data occupy memory. If you need to perform forced merging, you must make sure that the off-heap memory size of the cluster is greater than four times the total size of vector data in the cluster.
For a cluster whose memory specification is 64 GiB or higher, the off-heap memory size of the cluster is approximately equal to the value of the following formula: Total memory size - 32 (GiB).
Write throttling
Vector indexing is a CPU-intensive job. We recommend that you do not maintain a high write throughput. A peak write throughput lower than 5,000 transactions per second (TPS) is recommended for a data node with 16 vCPUs and 64 GiB of memory.
When the system processes queries on vector indexes, it loads all the indexes to node memory. If nodes are out of memory, the system reallocates shards. Therefore, we recommend that you do not write large amounts of data to your cluster when the system is processing queries.
NoteThe preceding table lists only estimated items. You need to plan your cluster based on your business requirements. We recommend that you plan sufficient memory for your cluster and perform stress testing before you use your cluster.
Limits
Before you install the aliyun-knn plug-in, you must make sure that the specifications of data nodes in your cluster are 16 vCPUs and 64 GiB of memory or higher. If the specifications of data nodes in your cluster do not meet the requirements, upgrade the data nodes. For more information, see Upgrade the configuration of a cluster.
When you use the aliyun-knn plug-in, some advanced features provided by the AliES kernel cannot be used. For example, if you enable the physical replication feature, you must disable this feature before you use the aliyun-knn plug-in. For more information, see Use the physical replication feature of the apack plug-in.
The aliyun-knn plug-in does not support data migration that is performed by using snapshots in OSS or by using DataWorks. If you want to migrate data, we recommend that you use Logstash.
Create a vector index
Log on to the Kibana console of your Elasticsearch cluster and go to the homepage of the Kibana console as prompted.
For more information about how to log on to the Kibana console, see Log on to the Kibana console.
NoteIn this example, an Elasticsearch V6.7.0 cluster is used. Operations on clusters of other versions may differ. The actual operations in the console prevail.
In the left-side navigation pane of the page that appears, click Dev Tools.
On the Console tab of the page that appears, run the following command to create a vector index:
PUT test { "settings": { "index.codec": "proxima", "index.vector.algorithm": "hnsw" }, "mappings": { "_doc": { "properties": { "feature": { "type": "proxima_vector", "dim": 2, "vector_type": "float", "distance_method": "SquaredEuclidean" } } } } }NoteYou can add other types of fields that are supported by Elasticsearch to the vector index.
If the following mapping parsing error is reported when you create a vector index, upgrade the kernel version of your cluster and try again:
"type": "mapper_parsing_exception", "reason": "Mapping definition for [feature] has unsupported parameters: [distance_method : SquaredEuclidean].
Part
Parameter
Default value
Description
settings
index.codec
proxima
Specifies whether to create the proxima vector index. Valid values:
proxima: The system creates the proxima vector index. This index supports vector searches. We recommend that you set this parameter to proxima.
null: The system does not create the proxima vector index but creates only forward indexes. In this case, fields of the proxima_vector type do not support HNSW- or Linear Search-based queries. These fields support only script queries.
NoteIf your cluster stores large volumes of data and you do not have high requirements on the latency of queries, you can remove the parameter or set the parameter to null. In this case, you can use the script query feature to search for the k-nearest neighbors (k-NN) of a vector. This feature is available only for V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later.
index.vector.algorithm
hnsw
The algorithm that is used to search for vectors. Valid values:
hnsw: HNSW
linear: Linear Search
index.vector.general.builder.offline_mode
false
Specifies whether to use the offline optimization mode to create the vector index. Valid values:
false: The offline optimization mode is not used.
true: The offline optimization mode is used. In this case, the number of segments that are written to the vector index is significantly reduced. This improves write throughput.
NoteThe offline optimization mode is available only for V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later. You are not allowed to perform script queries on the indexes for which the offline optimization mode is used.
If you want to write all of your data to your cluster at a time, we recommend that you use the offline optimization mode.
mappings
type
proxima_vector
The field type. For example, if you set the type parameter to proxima_vector for the feature field, the feature field is a vector-type field.
dim
2
The number of vector dimensions. This parameter is required. Valid values: 1 to 2048.
vector_type
float
The data type of vectors. Valid values:
float
short
binary
If you set this parameter to binary, the vector data that you want to write to the vector index must be of the uint32 data type. This indicates that the vector data must be represented by an unsigned 32-bit decimal array. In addition, the value of the dim parameter must be a multiple of 32.
For example, if you want to write the 64-bit binary business data 1000100100100101111000001001111101000011010010011010011010000100 to your vector index, write the vector [-1994006369, 1128900228] to the index.
NoteOnly V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later support all the preceding three data types. Other clusters support only the float data type.
distance_method
SquaredEuclidean
The function that is used to calculate the distance between vectors. Valid values:
SquaredEuclidean: calculates the Euclidean distance without square root extraction.
InnerProduct: calculates the inner product.
Cosine: calculates the cosine similarity.
Hamming: calculates the Hamming distance. This function is available only when you set the vector_type parameter to binary.
NoteOnly V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later support all the preceding four functions. For V6.8, V7.4, and V7.7 clusters, you can set this parameter only to its default value
SquaredEuclidean.For more information about the preceding functions, see Distance measurement functions.
The implementation of the Hamming function is special. If the HNSW or Linear Search algorithm is used, indexes do not support standard k-NN searches. Only script queries are supported, and the commands for script queries are compatible with the script_score parameter. If you want to use this parameter in the command of a script query, you must test the availability of the command first based on your business.
NoteYou can run the GET /_cat/plugins?v command to obtain the version of the apack plug-in. If the version of the apack plug-in does not meet the requirements, you can submit a ticket to ask Alibaba Cloud engineers to update your apack plug-in.
The aliyun-knn plug-in also supports some advanced search parameters. For more information, see Advanced parameters.
Run the following command to add a document:
POST test/_doc { "feature": [1.0, 2.0] }NoteIf you set the vector_type parameter to binary when you create the vector index, the vector data that you want to write to the vector index must be of the uint32 data type. This indicates that you must convert your data to an unsigned 32-bit decimal array before you add a document. In addition, the value of the dim parameter must be a multiple of 32. If you set the vector_type parameter to a value other than binary, the length of your vector data must be the same as the value specified for the dim parameter.
Search for a vector
Standard search
Run the following command to perform a standard search for a vector:
GET test/_search { "query": { "hnsw": { "feature": { "vector": [1.5, 2.5], "size": 10 } } } }The following table describes the parameters in the preceding command.
Parameter
Description
hnsw
The algorithm that is used to search for the vector. The value must be the same as that of the algorithm parameter specified when you create the index.
vector
The vector for which you want to search. The length of the array for the vector must be the same as the value of the dim parameter specified in the mappings part.
size
The number of recalled documents.
NoteThe size parameter in a vector search command is different from the size parameter provided by Elasticsearch. The former controls the number of documents recalled by the aliyun-knn plug-in, whereas the latter controls the number of documents recalled for a search. When you perform a vector search, the system recalls the top N documents based on the value of the size parameter in the related vector search command and recalls all the matching documents based on the value of the size parameter provided by Elasticsearch. Then, the system returns results based on the top N documents and all the matching documents.
We recommend that you set the two size parameters to the same value. The default value of the size parameter provided by Elasticsearch is 10.
NoteThe aliyun-knn plug-in also supports some advanced search parameters. For more information, see Advanced parameters.
Script query
You can perform script queries only by using the script_score parameter. For example, you can use the script_score parameter to score each document in a query response. The score is calculated by using the following formula:
1/(1+l2Squared(params.queryVector, doc['feature'])). The following code provides a sample script query request:GET test/_search { "query": { "match_all": {} }, "rescore": { "query": { "rescore_query": { "function_score": { "functions": [{ "script_score": { "script": { "source": "1/(1+l2Squared(params.queryVector, doc['feature'])) ", "params": { "queryVector": [2.0, 2.0] } } } }] } } } } }Script queries in Alibaba Cloud Elasticsearch do not support the functions provided by X-Pack. Only the functions described in the following table are supported.
Function
Description
l2Squared(float[] queryVector, DocValues docValues)The function that is used to search for a vector based on a Euclidean distance.
hamming(float[] queryVector, DocValues docValues)The function that is used to search for a vector based on a Hamming distance.
cosineSimilarity(float[] queryVector, DocValues docValues)cosine(float[] queryVector, DocValues docValues)
The function that is used to search for a vector based on a cosine similarity.
NoteWe recommend that you use the
cosineSimilarity(float[] queryVector, DocValues docValues)function for V6.7 clusters and use thecosine(float[] queryVector, DocValues docValues)function for V7.10 clusters.NoteYou can perform script queries only in V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later. You can run the GET /_cat/plugins?v command to obtain the version of the apack plug-in. If the version of the apack plug-in does not meet the requirements, you can submit a ticket to ask Alibaba Cloud engineers to update your apack plug-in.
Parameters in the preceding functions:
float[] queryVector: the query vector. You can set this parameter to a formal or actual parameter.
DocValues docValues: the document vectors.
You cannot perform script queries on the indexes that are created by using the
offline optimization mode.
Index warm-up
Searches are performed on vector indexes in in-memory storage. After you write data to a vector index, the latency of the first search is high. This is because the index is still being loaded to memory. To address this issue, the aliyun-knn plug-in provides the index warm-up feature. This feature allows you to warm up your vector indexes and load them to the memory of your on-premises machine before the aliyun-knn plug-in provides vector search services. This significantly reduces the latency of vector searches.
Run the following command to warm up all vector indexes:
POST _vector/warmupRun the following command to warm up a specific vector index:
POST _vector/{indexName}/warmup
NoteThe index warm-up feature is available only for V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later. You can run the GET _cat/plugins?v command to obtain the version of the apack plug-in. If the version of the apack plug-in does not meet the requirements, you can submit a ticket to ask Alibaba Cloud engineers to update your apack plug-in.
If your cluster stores a large number of vector indexes, the indexes store large volumes of data, and vector searches are required only for a specific vector index, we recommend that you warm up only the specific vector index to improve the search performance.
Vector scoring
A unified scoring formula is provided for vector searches. The formula depends on distance measurement functions. The distance measurement functions affect the sorting of search results.
Scoring formula:
Score = 1/(Vector distance + 1)
By default, the scoring mechanism uses Euclidean distances without square root extraction to calculate scores.
In practice, you can calculate a distance based on a score. Then, optimize vectors based on the distance to increase the score.
Distance measurement functions
The scoring mechanism varies based on the distance measurement function. The following table describes the distance measurement functions supported by the aliyun-knn plug-in.
Distance measurement function | Description | Scoring formula | Use scenario | Example |
SquaredEuclidean | This function is used to calculate the Euclidean distance between vectors. The Euclidean distance, also called Euclidean metric, refers to the actual distance between points or the natural length of a vector in an m-dimensional space. Euclidean distances are widely used. A Euclidean distance in a two- or three-dimensional space is the actual distance between points. | For example, two n-dimensional vectors [A1, A2, ..., An] and [B1, B2, ..., Bn] exist.
Note By default, the scoring mechanism uses Euclidean distances without square root extraction to calculate scores. | A Euclidean distance can reflect the absolute difference between the characteristics of individual numbers. Therefore, Euclidean distances are widely used to analyze the differences between numbers from various dimensions. For example, you can use a user behavior metric to analyze the differences or similarities between user values. | The Euclidean distance without square root extraction between two-dimensional vectors [0, 0] and [1, 2] is 5, which is calculated by using the following formula: (1 - 0)² + (2 - 0)². |
Cosine | This function is used to calculate the cosine similarity between vectors. The function calculates the cosine of the angle between the vectors to obtain the cosine similarity between them. | For example, two n-dimensional vectors [A1, A2, ..., An] and [B1, B2, ..., Bn] exist.
| A cosine similarity reflects the differences between vectors from orientations. Cosine similarities are used to score content to obtain the similarities or differences between user interests. In addition, cosine similarities are subject to the orientations of vectors rather than the numbers in them. Therefore, the cosine similarities can address the issue that users may use different measurement standards. | The cosine similarity between two-dimensional vectors [1, 1] and [1, 0] is 0.707. |
InnerProduct | This function is used to calculate the inner product between vectors. An inner product is also called a dot product. A dot product is a dyadic operation that takes two vectors of the real number R and returns a scalar for the real number. | For example, two n-dimensional vectors [A1, A2, ..., An] and [B1, B2, ..., Bn] exist.
| The inner product takes both the angle and absolute length between the vectors into consideration. After vectors are normalized, the formula for inner products is equivalent to that for cosine similarities. | The inner product between two-dimensional vectors [1, 1] and [1, 5] is 6. |
Hamming (available only for vectors of the BINARY data type) | In information theory, the Hamming distance between strings of the same length equals the number of positions at which symbols differ. d(x, y) is used to represent the Hamming distance between the strings x and y. In other words, a Hamming distance measures the minimum number of substitutions that are required to change the string x into the string y. | For example, two n-bit binary strings x and y exist.
| Hamming distances are used to detect or fix the errors that occur when data is transmitted over computer networks. A Hamming distance can also be used as an error estimation method to determine the number of different characters between binary strings. | The Hamming distance between 1011101 and 1001001 is 2. Note When you use the aliyun-knn plug-in, the vector data that you want to write to your vector index must be of the uint32 data type. This indicates that the vector data must be represented by an unsigned 32-bit decimal array. In addition, the value of the |
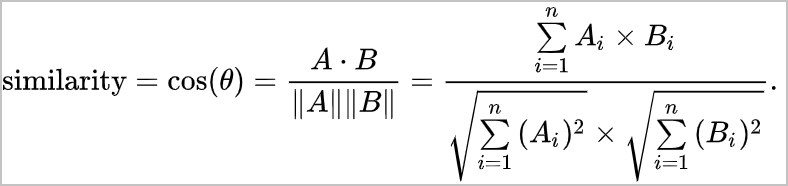
Only V6.7.0 clusters whose apack plug-in is of V1.2.1 or later and V7.10.0 clusters whose apack plug-in is of V1.4.0 or later support all the preceding four functions. You can run the GET _cat/plugins?v command to obtain the version of the apack plug-in for your cluster. If the version of the apack plug-in does not meet the requirements, your cluster supports only the SquaredEuclidean function. If you want to use other functions, you can submit a ticket to ask Alibaba Cloud engineers to update your apack plug-in.
You can configure the distance_method parameter in the mappings part to specify the distance measurement function that is used for your vector index.
Circuit breaker parameters
Parameter | Description | Default value |
indices.breaker.vector.native.indexing.limit | If the off-heap memory usage exceeds the value specified by this parameter, write operations are suspended. After the system creates indexes and releases the memory, the system resumes the write operations. If the circuit breaker is triggered, the consumption of system memory is high. In this case, we recommend that you throttle the write throughput. | 70% |
indices.breaker.vector.native.total.limit | The maximum proportion of off-heap memory used to create vector indexes. If the actual off-heap memory usage exceeds the value specified by this parameter, the system may reallocate shards. | 80% |
The preceding circuit breaker parameters are cluster-level parameters. You can run the GET _cluster/settings command to view the values of the parameters. We recommend that you retain default values for the parameters.
Advanced parameters
Table 2. Index creation parameters for HNSW
Parameter | Description | Default value |
index.vector.hnsw.builder.max_scan_num | The maximum number of the nearest neighbors that can be scanned when a graph is created under the worst case. | 100000 |
index.vector.hnsw.builder.neighbor_cnt | The maximum number of the nearest neighbors that each node can have at layer 0. We recommend that you set this parameter to 100. The quality of a graph increases with the value of this parameter. However, inactive indexes consume more storage resources. | 100 |
index.vector.hnsw.builder.upper_neighbor_cnt | The maximum number of the nearest neighbors that each node can have at a layer other than layer 0. We recommend that you set this parameter to 50% of the value specified for the neighbor_cnt parameter. Maximum value: 255. | 50 |
index.vector.hnsw.builder.efconstruction | The number of the nearest neighbors that can be scanned when a graph is created. The quality of a graph increases with the value of this parameter. However, a longer time period is required to create indexes. We recommend that you set this parameter to 400. | 400 |
index.vector.hnsw.builder.max_level | The total number of layers, which includes layer 0. For example, if you have 10 million documents and the scaling_factor parameter is set to 30, use 30 as the base number and round the logarithm of 10,000,000 up to the nearest integer. The result is 5. This parameter does not have a significant impact on vector searches. We recommend that you set this parameter to 6. | 6 |
index.vector.hnsw.builder.scaling_factor | The scaling factor. The volume of data at a layer equals the volume of data at its upper layer multiplied by the scaling factor. Valid values: 10 to 100. The number of layers decreases with the value of scaling_factor. We recommend that you set this parameter to 50. | 50 |
You can set the preceding parameters in the settings part only after you set the index.vector.algorithm parameter to hnsw.
Table 3. Search parameters for HNSW
Parameter | Description | Default value |
ef | The number of the nearest neighbors that are scanned during an online search. A large value increases the recall ratio but slows down searches. Valid values: 100 to 1000. | 100 |
The following code provides a sample search request:
GET test/_search
{
"query": {
"hnsw": {
"feature": {
"vector": [1.5, 2.5],
"size": 10,
"ef": 100
}
}
}
}FAQ
Q: How do I evaluate the recall ratio of documents?
A: You can create two indexes. One uses the HNSW algorithm and the other uses the Linear Search algorithm. Keep the other index settings consistent for the two indexes. Use a client to add the same vector data to the indexes, and refresh the indexes. Then, use the same query vector to perform queries on the indexes, compare the document IDs returned by the indexes, and find out the document IDs that are returned by both indexes.
NoteDivide the number of document IDs that both indexes return by the total number of returned document IDs to calculate the recall ratio of the documents.
Q: When I write data to my cluster, the system returns the
circuitBreakingExceptionerror. What do I do?A: This error indicates that the off-heap memory usage exceeds the proportion specified by the indices.breaker.vector.native.indexing.limit parameter and that the write operation is suspended. The default proportion is 70%. In most cases, the write operation is automatically resumed after the system creates indexes and releases memory. We recommend that you add a retry mechanism to the data write script on your client.
Q: Why is the CPU still working after the write operation is suspended?
A: The system creates vector indexes during both the refresh and flush processes. The index creation task may be still running even if the write operation is suspended. Computing resources are released after the final refresh is complete.
Q: When I use the aliyun-knn plug-in, the following error is reported:
class_cast_exception: class org.apache.lucene.index.SoftDeletesDirectoryReaderWrapper$SoftDeletesFilterCodecReader cannot be cast to class org.apache.lucene.index.SegmentReader (org.apache.lucene.index.SoftDeletesDirectoryReaderWrapper$SoftDeletesFilterCodecReader and org.apache.lucene.index.SegmentReader are in unnamed module of loader 'app'). What do I do?A: Disable the physical replication feature for indexes. For more information, see Use the physical replication feature of the apack plug-in.
Q: When I use the aliyun-knn plug-in to perform a vector search, the search is slow, or the search is suspended due to high memory usage. What do I do?
A: When the aliyun-knn plug-in is used for vector searches, in-memory vectors are used. This consumes a large number of memory resources. During a vector search, the system loads index data to the memory of data nodes. If the data nodes store large volumes of index data, the search may be slow or suspended. To avoid this issue, you must make sure that the volume of the data that is stored on each data node is no more than half of the total memory size of the data node. If the memory sizes of data nodes in your cluster are excessively small, we recommend that you upgrade the data nodes. For more information, see Upgrade the configuration of a cluster.
Q: Is the best practice for the aliyun-knn plug-in provided?
A: The Alibaba Cloud developer community provides the business scenarios and best practice of the aliyun-knn plug-in.
Q: I cannot use
must_not existsto filter documents in which the value of the feature field is empty. What do I do?A: Vector data is stored in a special manner and may be incompatible with DSL queries. You can use the following script to filter the documents:
GET jx-similar-product-v1/_search { "query": { "bool": { "must": { "script": { "script": { "source": "doc['feature'].empty", "lang": "painless" } } } } } }