To better meet the requirements of various business scenarios, StarRocks supports multiple data models. Data stored in StarRocks needs to be organized based on specific models. This topic describes the basic concepts, principles, system configurations, and scenarios of different import methods. Best practices and FAQ are also provided in this topic.
Background information
The data import feature allows you to cleanse and convert raw data based on the corresponding model and import the data to StarRocks for subsequent data query and use. StarRocks supports multiple import methods. You can use the import method that fulfills your business requirements based on the volume of data to be imported or import frequency.
The following figure shows different data sources and the corresponding import methods supported by StarRocks. 
You can use proper import methods based on different data sources:
Import offline data: If the data source is Hive or Hadoop Distributed File System (HDFS), we recommend that you use the Broker Load import method. For more information, see Broker Load. If a large number of data tables need to be imported, you can use Hive external tables whose performance is inferior to the Broker Load import method. However, data migration is not required in this case. If a single table contains a large amount of data, or you require precise deduplication to use the table as a global data dictionary, you can use the Spark Load import method. For more information, see Spark Load.
Import data in real time: After you synchronize log data and binary logs of databases to Kafka, we recommend that you use the Routine Load import method to import the data to StarRocks. For more information, see Routine Load. If multi-table joins and extract, transform and load (ETL) are required, you can use a Flink connector to process data in advance and write the data to StarRocks by using the Stream Load import method. For more information, see Flink connector and Stream Load.
Import data to StarRocks through programs: We recommend that you use the Stream Load import method. For more information, see Stream Load. You can refer to demos in Java or Python in the Stream Load topic.
Import text files: We recommend that you use the Stream Load import method. For more information, see Stream Load.
Import data from MySQL: We recommend that you use MySQL external tables and execute the
insert into new_table select * from external_tablestatement to import data.Import data within StarRocks: We recommend that you choose the INSERT INTO import method and use the external scheduler to implement simple ETL processing. For more information, see INSERT INTO.
The images and some information in this topic are from Overview of data loading of open source StarRocks.
Usage notes
Program connections are often established to import data to StarRocks. Take note of the following items when you import data to StarRocks:
Select an appropriate import method. You can select an import method based on your data volume, import frequency, or location of the data source.
For example, if the raw data is stored in HDFS, you can use the Broker Load method to import data.
Determine the protocol for the import method. If you use the Broker Load import method, the external system must be allowed to submit and view import jobs on a regular basis by using the MySQL protocol.
Determine the mode of data import. Data import is classified into synchronous and asynchronous modes. If asynchronous mode is used, the external system must run the command to view the data import and determine whether the import is successful based on the results of the command.
Set a label generation policy. The label generation policy must meet the principle that data imported in each job must be unique and static.
Ensure exactly-once delivery. The external system guarantees at-least-once delivery for data import, and the label mechanism of StarRocks ensures at-most-once delivery for data import. This way, the exactly-once delivery can be achieved for the overall data import.
Terms
Term | Description |
import job | Reads data from the specified data source, cleanses and converts the data, and then imports the data to StarRocks. After the data is imported, the data can be queried. |
label | Identifies an import job. All import jobs have a label. Labels can be specified by you or automatically generated by StarRocks. Labels are unique in a database. Each label can be used only for one successful import job. After an import job is complete, you cannot reuse the label of this import job to submit another import job. Only the labels of failed import jobs can be reused. This mechanism helps ensure that the data associated with a specific label can be imported only once. This way, the at-most-once delivery semantic is implemented. |
atomicity | All the loading methods provided by StarRocks can guarantee atomicity. Atomicity means that the qualified data within a job must be all successfully imported, or none of the qualified data is successfully imported. It never happens that some of the qualified data is loaded while the other data is not. Note that the qualified data does not include the data that is filtered out due to quality issues such as data type conversion errors. |
MySQL and HTTP protocol | StarRocks supports two communication protocols that can be used to submit import jobs: MySQL and HTTP. |
Broker Load | Uses deployed brokers to read data from external data sources such as HDFS and imports the data to StarRocks. The broker process uses its computing resources to preprocess and import data. |
Spark Load | Reprocesses data by using external resources such as Spark to generate intermediate files. StarRocks reads the intermediate files and imports the files. Spark Load is an asynchronous import method. You need to create an import job by using the MySQL protocol and check the import result by running a specific command. |
FE | A frontend (FE) node is the metadata and scheduling node of StarRocks. In the data import process, an FE node is used to generate import execution plans and schedule import jobs. |
BE | A backend (BE) node is the compute and storage node of StarRocks. A BE node is used to perform ETL operations on data and store data. |
tablet | A logical shard of the StarRocks table. A table can be divided into multiple tablets based on partitioning and bucket rules. For more information, see Data distribution. |
How it works
The following figure shows how an import job is run. 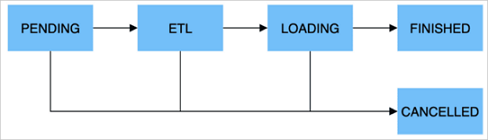
The following table describes the five stages of an import job.
Stage | Description |
PENDING | Optional. The job is submitted and waits to be scheduled by an FE node. This stage is included for a job that uses the Broker Load or Spark Load import method. |
ETL | Optional. The data is preprocessed, including cleansing, partitioning, sorting, and aggregation. Spark Load includes this step. He uses the external computing resource Spark to complete ETL. |
LOADING | Data is cleansed and converted at first and sent to BE nodes for processing. After all data is imported, the data is in queue and waits to take effect. At this time, the status of the job remains LOADING. |
FINISHED | When all data takes effect, the status of the job becomes FINISHED. At this time, the data can be queried. FINISHED is a final job state. |
CANCELLED | Before the status of the job becomes FINISHED, you can cancel the job at any time. StarRocks can also automatically cancel the job in case of import errors. CANCELLED is also a final job state. |
The following table describes the supported data types.
Type | Description |
Integer | TINYINT, SMALLINT, INT, BIGINT, and LARGEINT. Example: 1, 1000, and 1234. |
Floating point | FLOAT, DOUBLE, and DECIMAL. Example: 1.1, 0.23, and 0.356. |
Date | DATE and DATETIME. Example: 2017-10-03 and 2017-06-13 12:34:03. |
String | CHAR and VARCHAR. Example: "I am a student" and "a". |
Import methods
To meet various data import requirements, StarRocks provides five methods to import data from different data sources, such as HDFS, Kafka, and local files, or in different ways. StarRocks supports synchronous and asynchronous import modes.
All import methods support the CSV data format. Broker Load also supports the Parquet and ORC data formats.
Data import methods
Import method | Description | Import mode |
Broker Load | Uses the broker process to read data from external sources, and creates a job to import data to StarRocks by using the MySQL protocol. The submitted job is run in an asynchronous manner. The The Broker Load import method is applicable to the following scenario: The data to be imported is in a storage system that is accessible by the broker process, such as HDFS. The import data volume ranges from tens of GB to hundreds of GB. For more information, see Broker Load. | Asynchronous |
Spark Load | Preprocesses imported data by using external Spark resources. This improves the performance of StarRocks in importing large amounts of data and saves computing resources of StarRocks clusters. Spark Load is an asynchronous import method. You need to create an import job by using the MySQL protocol and run the Spark Load is suitable for the scenario where a large amount of data is migrated to StarRocks for the first time, and the data is in a storage system that is accessible by Spark clusters, such as HDFS. Terabytes of data can be imported. For more information, see Spark Load. | Asynchronous |
Stream Load | A synchronous import method. You can send an HTTP request to import a local file or a data stream to StarRocks and wait for the system to return the import result status. You can determine whether the import is successful based on the return result. Stream Load is applicable for importing local files or importing data from a data stream by using a program. For more information, see Stream Load. | Synchronous |
Routine Load | Automatically imports data from a specified data source. You can submit a routine import job by using the MySQL protocol. Then, a resident thread is generated to continuously read data from a data source, such as Kafka, and import the data to StarRocks. For more information, see Routine Load. | Asynchronous |
INSERT INTO | This import method is used in a way similar to the INSERT statement in MySQL. StarRocks allows you to use the | Synchronous |
Import modes
If you import data by using external programs, you must choose an import mode that best suits your business requirements before you determine the import method.
Synchronous mode
In synchronous mode, after an external system creates an import job, StarRocks synchronously runs the job. When the import job is complete, StarRocks returns the import result. The external system can determine whether the import is successful based on the return result.
Procedure:
An external system creates an import job.
StarRocks returns the import result.
The external system determines the import result. If the import job fails, another import job can be created.
Asynchronous mode
In asynchronous mode, after an external system creates an import job, StarRocks returns the result indicating that the job is created. This does not mean that the data is imported. The import job is asynchronously run. After the job is created, the external system polls the status of the import job by running a specific command. If the import job fails to be created, the external system can determine whether to create another import job based on the failure information.
Procedure:
An external system creates an import job.
StarRocks returns the result of creating an import job.
The external system determines whether to go to the next step based on the return result. If the import job is created, go to Step 4. If the import job fails to be created, go back to Step 1 and create an import job again.
The external system polls the status of the import job until the status changes to FINISHED or CANCELLED.
Scenarios
Scenario | Description |
Import data from HDFS | If the data to be imported is stored in HDFS and the data volume ranges from tens of GB to hundreds of GB, you can use the Broker Load method to import data to StarRocks. In this case, the HDFS data source must be accessible by the deployed broker process. The import job is run in an asynchronous manner. The If the data to be imported is stored in HDSF, and terabytes of data need to be imported, you can use the Spark Load method to import data to StarRocks. In this case, the HDFS data source must be accessible by the deployed Spark process. The import job is run in an asynchronous manner. The The Broker Load or Spark Load method supports importing data from other external data sources only if the broker or Spark process can read data from the data source. |
Import local files | If your data is stored in a local file and the data volume is less than 10 GB, you can use the Stream Load method to quickly import the data to StarRocks. An import job is created by using the HTTP protocol, and the import job is synchronously executed. You can determine whether the import is successful based on the return result of the HTTP request. |
Import data from Kafka | If you want to import data from a streaming data source such as Kafka to StarRocks in real time, you can use the Routine Load method. You can create a routine import job by using the MySQL protocol. StarRocks continuously reads and imports data from Kafka. |
Import data by using the INSERT INTO method | You can use the The |
Memory limits
You can set parameters to limit the memory usage of a single import job. This prevents the import job from occupying an excessive amount of memory and causing an out of memory (OOM) error. Ways used to limit the memory usage of jobs that adopt different import methods vary. For more information, see the corresponding topic for each import method.
In most cases, an import job is run on multiple BE nodes. You can set parameters to limit the memory usage of an import job on a single BE node, not on the entire cluster. In addition, you can specify the maximum memory size that can be used by import jobs on each BE node. For more information, see the General system configurations section of this topic. The system configuration sets the upper limit for the overall memory usage of all import jobs that run on a BE node.
A low memory usage limit may affect the import efficiency, because data is frequently written to the disk when the memory usage reaches the upper limit. However, an excessively high memory usage limit may cause an OOM error when import concurrency is high. Therefore, you must set memory-related parameters to proper values based on your business requirements.
General system configurations
Configurations of FE nodes
The following table describes the system configuration parameters of FE nodes. You can modify the parameters in the configuration file fe.conf of the FE node.
Parameter | Description |
max_load_timeout_second | The maximum and minimum import timeout periods. Unit: seconds. By default, the maximum timeout period is three days, and the minimum timeout period is 1 second. The import timeout period that you specify must be within this range. This parameter is valid for all types of import jobs. |
min_load_timeout_second | |
desired_max_waiting_jobs | The maximum number of import jobs that a wait queue can accommodate. Default value: 100. For example, if the number of import jobs in the PENDING state on the FE node reaches the value of this parameter, new import requests are rejected. The PENDING state indicates that the import job waits to be run. This parameter is valid only for asynchronous import jobs. If the number of asynchronous import jobs in the PENDING state reaches the upper limit, subsequent requests to create import jobs are rejected. |
max_running_txn_num_per_db | The maximum number of ongoing import jobs that are allowed in each database. Default value: 100. When the number of import jobs that run in a database reaches the maximum number that you specify, the subsequent import jobs are not run. In this situation, if a synchronous import job is submitted, the job is rejected. If an asynchronous import job is submitted, the job waits in queue. |
label_keep_max_second | The retention period of the history records for import jobs. StarRocks retains the records of import jobs that are complete and are in the FINISHED or CANCELLED state for a period. You can set the retention period by using this parameter. The default retention period is three days. This parameter is valid for all types of import jobs. |
Configurations of BE nodes
The following table describes the system configuration parameters of BE nodes. You can modify the parameters in the configuration file be.conf of the BE node.
Parameter | Description |
push_write_mbytes_per_sec | The maximum write speed per tablet on a BE node. The default value is 10, which indicates a write speed of 10 MB/s. In most cases, the maximum write speed ranges from 10 MB/s to 30 MB/s based on the schema and the system used. You can modify the value of this parameter to control the data import speed. |
write_buffer_size | The maximum memory block size. The imported data is first written to a memory block on the BE node. When the amount of imported data reaches the maximum memory block size that you specify, the data is written to the disk. The default size is 100 MB. If the maximum memory block size is exceedingly small, a large number of small files may be generated on the BE node. You can increase the maximum memory block size to reduce the number of files generated. If the maximum memory block size is excessively large, remote procedure calls (RPCs) may time out. For more information, see the description of the tablet_writer_rpc_timeout_sec parameter. |
tablet_writer_rpc_timeout_sec | The RPC timeout period for sending a batch of data (1024 rows) during the import process. Default value: 600. Unit: seconds. An RPC may involve operations of writing data in memory blocks of multiple tablets to disks. In this case, RPC timeout may occur due to disk write operations. You can adjust the RPC timeout period to reduce timeout errors, such as the send batch fail error. If you set the write_buffer_size parameter to a higher value, you must also increase the value of the tablet_writer_rpc_timeout_sec parameter. |
streaming_load_rpc_max_alive_time_sec | The waiting timeout period for each Writer thread. During the data import process, StarRocks starts a Writer thread to receive data from and write data to each tablet. Default value: 600. Unit: seconds. If a Writer process does not receive any data within the waiting timeout period that you specify, StarRocks automatically destroys the Writer thread. When the system processes data at a low speed, a Writer thread may not receive the next batch of data within a long period and therefore reports a |
load_process_max_memory_limit_percent | The maximum amount and the highest percentage of memory that can be consumed for all import jobs on each BE node. StarRocks identifies the smaller memory consumption among the values of the two parameters as the final memory consumption that is allowed.
|
load_process_max_memory_limit_bytes |