The Flink StarRocks connector loads data into StarRocks in batches using Stream Load, offering significantly higher throughput than Apache Flink's built-in Java Database Connectivity (JDBC) connector (flink-connector-jdbc). Alibaba Cloud provides the Flink StarRocks connector to help you cache data and then import the data to StarRocks at a time in Stream Load mode. This topic explains how to set up the connector and write data to StarRocks, with a complete example for synchronizing MySQL data in real time.
Prerequisites
Before you begin, ensure that you have:
-
Apache Flink 1.11 or later (1.13 recommended)
-
A StarRocks cluster with accessible frontend HTTP ports
Add the connector to your project
Download the connector source code from the starrocks-connector-for-apache-flink repository on GitHub.
Add the following dependency to your project's pom.xml:
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<!-- for Flink 1.11 and 1.12 -->
<version>x.x.x_flink-1.11</version>
<!-- for Flink 1.13 -->
<version>x.x.x_flink-1.13</version>
</dependency>Replace x.x.x with the latest version. Check the version information page for the current release.
Write data using the Flink connector
The connector provides two approaches for writing data to StarRocks. Use Method 1 for raw JSON streams; use Method 2 for SQL-based table creation and structured data.
Method 1: DataStream API
// -------- sink with raw JSON string stream --------
fromElements(new String[]{
"{\"score\": \"99\", \"name\": \"stephen\"}",
"{\"score\": \"100\", \"name\": \"lebron\"}"
}).addSink(
StarRocksSink.sink(
// the sink options
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx")
.withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port")
.withProperty("username", "xxx")
.withProperty("password", "xxx")
.withProperty("table-name", "xxx")
.withProperty("database-name", "xxx")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
.build()
)
);
// -------- sink with stream transformation --------
class RowData {
public int score;
public String name;
public RowData(int score, String name) {
......
}
}
fromElements(
new RowData[]{
new RowData(99, "stephen"),
new RowData(100, "lebron")
}
).addSink(
StarRocksSink.sink(
// the table structure
TableSchema.builder()
.field("score", DataTypes.INT())
.field("name", DataTypes.VARCHAR(20))
.build(),
// the sink options
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx")
.withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port")
.withProperty("username", "xxx")
.withProperty("password", "xxx")
.withProperty("table-name", "xxx")
.withProperty("database-name", "xxx")
.withProperty("sink.properties.column_separator", "\\x01")
.withProperty("sink.properties.row_delimiter", "\\x02")
.build(),
// set the slots with streamRowData
(slots, streamRowData) -> {
slots[0] = streamRowData.score;
slots[1] = streamRowData.name;
}
)
);Method 2: SQL table creation
Before running this method, add com.starrocks.connector.flink.table.StarRocksDynamicTableSinkFactory to src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory.
// create a table with `structure` and `properties`
tEnv.executeSql(
"CREATE TABLE USER_RESULT(" +
"name VARCHAR," +
"score BIGINT" +
") WITH ( " +
"'connector' = 'starrocks'," +
"'jdbc-url'='jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx'," +
"'load-url'='fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port'," +
"'database-name' = 'xxx'," +
"'table-name' = 'xxx'," +
"'username' = 'xxx'," +
"'password' = 'xxx'," +
"'sink.buffer-flush.max-rows' = '1000000'," +
"'sink.buffer-flush.max-bytes' = '300000000'," +
"'sink.buffer-flush.interval-ms' = '5000'," +
"'sink.properties.column_separator' = '\\x01'," +
"'sink.properties.row_delimiter' = '\\x02'," +
"'sink.max-retries' = '3'" +
"'sink.properties.*' = 'xxx'" + // stream load properties like `'sink.properties.columns' = 'k1, v1'`
")"
);Sink parameters
The following table describes all parameters for the Flink sink connector.
| Parameter | Required | Default value | Type | Description |
|---|---|---|---|---|
connector |
Yes | — | String | The connector type. Set to starrocks. |
jdbc-url |
Yes | — | String | The JDBC URL for connecting to StarRocks and running queries. |
load-url |
Yes | — | String | The HTTP addresses of frontends, in the format fe_ip:http_port;fe_ip:http_port. Separate multiple frontends with semicolons (;). |
database-name |
Yes | — | String | The StarRocks database name. |
table-name |
Yes | — | String | The StarRocks table name. |
username |
Yes | — | String | The username for connecting to the StarRocks database. |
password |
Yes | — | String | The password for connecting to the StarRocks database. |
sink.semantic |
No | at-least-once |
String | The delivery semantic. Valid values: at-least-once and exactly-once. |
sink.buffer-flush.max-bytes |
No | 94371840 (90 MB) |
String | The maximum buffer size before a flush is triggered. Valid range: 64 MB to 10 GB. |
sink.buffer-flush.max-rows |
No | 500000 |
String | The maximum number of rows in the buffer before a flush is triggered. Valid range: 64000 to 5000000. |
sink.buffer-flush.interval-ms |
No | 300000 |
String | The buffer flush interval in milliseconds. Valid range: 1000 to 3600000. |
sink.max-retries |
No | 1 |
String | The maximum number of retry attempts on failure. Valid range: 0 to 10. |
sink.connect.timeout-ms |
No | 1000 |
String | The connection timeout for the frontend HTTP addresses specified in load-url, in milliseconds. Valid range: 100 to 60000. |
sink.properties.* |
No | — | String | Stream Load properties passed directly to StarRocks. |
Usage notes
Default format and delimiters
Data is imported in CSV format by default. To use custom delimiters, set:
-
sink.properties.row_delimiter— row delimiter (e.g.,\\x02). Supported in StarRocks 1.15.0 and later. -
sink.properties.column_separator— column delimiter (e.g.,\\x01).
If you cannot find appropriate CSV delimiters for your data, switch to JSON format by setting sink.properties.format=json and sink.properties.strip_outer_array=true. Note that JSON import performance may deteriorate compared to CSV.
When creating tables and synchronizing data in a SQL client, escape the backslash (\):
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'Exactly-once semantics
To use sink.semantic=exactly-once, the external system must support the two-phase commit protocol. StarRocks does not natively support this protocol, so exactly-once delivery depends on Flink checkpointing. The flow works as follows: 1. When Flink generates a checkpoint, a batch of data and their labels are cached as state. 2. The system blocks until the cached data is written to StarRocks. 3. Once the write completes, Flink starts the next checkpoint. If StarRocks becomes unavailable, the Flink sink stream operators may be blocked for an extended period due to connection failure, triggering an alert and forcing the Flink import job to terminate.
Connectivity troubleshooting
If data queries succeed but writes fail, verify that your machine can reach the HTTP ports of the StarRocks backends. When you submit an import job, frontends forward write operations to the internal IP addresses and HTTP ports of backends.
For example, if your machine has a public IP address and the cluster frontends and backends are accessible via public IP addresses, but backends use internal IP addresses for intra-cluster communication — specifying public frontend addresses in load-url causes frontends to forward writes to backend internal IPs. If your machine cannot reach those internal IPs, the write fails.
If an import job is unexpectedly stopped, increase the memory capacity of the job.
Synchronize MySQL data to StarRocks using CDC
Use the Flink change data capture (CDC) connector and StarRocks migration tools to synchronize a MySQL database to a StarRocks cluster in near real time. StarRocks migration tools automatically generate CREATE TABLE statements based on the MySQL schema and StarRocks cluster configuration.
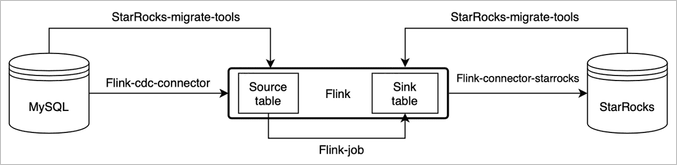
The diagram and some information in this section are sourced from Realtime synchronization from MySQL in the open-source StarRocks documentation.
Prerequisites
Before you begin, ensure that you have:
-
Apache Flink 1.13 (recommended) or 1.11 / 1.12
-
Access to a MySQL database and a StarRocks cluster
Set up the environment
-
Download Apache Flink. Apache Flink 1.13 is recommended. The earliest supported version is 1.11.
-
Download the Flink CDC connector for MySQL. Select the package that matches your Flink version.
-
Download the Flink StarRocks connector.
ImportantThe Flink StarRocks connector varies for Apache Flink 1.13, 1.11, and 1.12. Download the correct version.
-
Copy both
flink-sql-connector-mysql-cdc-xxx.jarandflink-connector-starrocks-xxx.jarto theflink-xxx/lib/directory. -
Download the smt.tar.gz package, decompress it, and edit the configuration file with your connection details. The configuration file uses the following sections: Sample configuration:
-
db— MySQL database connection information -
be_num— number of nodes in the StarRocks cluster -
[table-rule.N]— matching rules using regular expressions for database names and table names. Configure one section per rule set. -
flink.starrocks.*— StarRocks cluster configuration
[db] host = 192.168.**.** port = 3306 user = root password = [other] # number of backends in StarRocks be_num = 3 # `decimal_v3` is supported since StarRocks-1.18.1 use_decimal_v3 = false # file to save the converted DDL SQL output_dir = ./result [table-rule.1] # pattern to match databases for setting properties database = ^console_19321.*$ # pattern to match tables for setting properties table = ^.*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= flink.starrocks.sink.properties.column_separator=\x01 flink.starrocks.sink.properties.row_delimiter=\x02 flink.starrocks.sink.buffer-flush.interval-ms=15000 -
Create tables and start synchronization
-
Run
starrocks-migrate-toolto generateCREATE TABLEstatements. The output is written to the/resultdirectory. Runls resultto verify the generated files:flink-create.1.sql smt.tar.gz starrocks-create.all.sql flink-create.all.sql starrocks-create.1.sql -
Create the database and tables in StarRocks:
Mysql -h <IP address of a frontend> -P 9030 -u root -p < starrocks-create.1.sql -
Create Flink tables and start continuous data synchronization:
ImportantIf you are using Apache Flink earlier than 1.13, you cannot run the SQL script directly. Execute the SQL statements one by one and enable binary logging for the MySQL database.
bin/sql-client.sh -f flink-create.1.sql -
Check the status of running Flink jobs:
bin/flink list -runningView job details and status on the Flink web UI or in the log files under
$FLINK_HOME/log.
Configure multiple rule sets
To synchronize multiple databases or tables with different properties, add one [table-rule.N] section per rule set. Configure flink.starrocks.sink parameters independently for each rule set, such as different import frequencies.
Sample configuration with two rule sets:
[table-rule.1]
# pattern to match databases for setting properties
database = ^console_19321.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
# pattern to match databases for setting properties
database = ^database2.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
# If you cannot select appropriate CSV delimiters, switch to JSON format.
# Note that JSON import performance may deteriorate compared to CSV.
flink.starrocks.sink.properties.strip_outer_array=true
flink.starrocks.sink.properties.format=jsonConsolidate sharded tables
After horizontal sharding, data from a large table may be split across multiple tables or databases. Configure a single rule set to synchronize multiple source tables into one StarRocks table.
For example, if edu_db_1 and edu_db_2 each contain course_1 and course_2 with the same schema, the following rule consolidates all four tables into a single StarRocks table:
[table-rule.3]
# pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# pattern to match tables for setting properties
table = ^course_[0-9]*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030
flink.starrocks.load-url= 192.168.**.**:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=5000After running starrocks-migrate-tool, a many-to-one synchronization relationship is automatically created. The generated StarRocks table is named course__auto_shard by default. To rename it, edit the generated SQL files before running them.