Routine Load continuously ingests data from Apache Kafka into StarRocks on EMR. Once a load job is running, StarRocks polls the Kafka topic automatically — you control the job lifecycle with SQL statements (pause, resume, or stop).
Use Routine Load when you need a persistent, always-on ingestion pipeline from Kafka. If you need one-time bulk loading, use Stream Load or Broker Load instead.
How it works
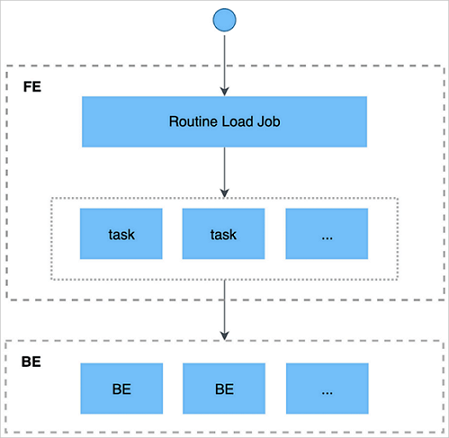
Routine Load uses a two-tier scheduling model:
Submit a load job to the frontend (FE) through any MySQL-compatible client.
The JobScheduler splits the job into multiple tasks. Each task covers a specific subset of Kafka partitions.
The TaskScheduler assigns each task to a backend (BE). The BE treats the task as a Stream Load job and writes data to StarRocks.
After the task completes, the BE reports the result to the FE.
The FE creates new tasks for the next batch, or retries failed tasks.
This cycle repeats continuously, keeping data flowing without interruption.
Key concepts
| Term | Description |
|---|---|
| RoutineLoadJob | The load job submitted to the FE |
| JobScheduler | Splits a RoutineLoadJob into tasks based on configured rules |
| Task | A single unit of work derived from a RoutineLoadJob |
| TaskScheduler | Schedules task execution across backend nodes |
Images and some information in this topic are from Continuously load data from Apache Kafka in the open-source StarRocks documentation.
Prerequisites
Before you begin, make sure:
Kafka version is V0.10.0.0 or later
The Kafka cluster uses no authentication or SSL authentication (other authentication types are not supported)
Messages are in CSV or JSON format — the Array type is not supported
For CSV: each message is one line; the line must not end with a line feed character
Quick start
This example shows how to create a Routine Load job that reads from a local Kafka cluster.
1. Create the load job
CREATE ROUTINE LOAD routine_load_wikipedia ON routine_wiki_edit
COLUMNS TERMINATED BY ",",
COLUMNS (event_time, channel, user, is_anonymous, is_minor, is_new, is_robot, is_unpatrolled, delta, added, deleted)
PROPERTIES
(
"desired_concurrent_number"="1",
"max_error_number"="1000"
)
FROM KAFKA
(
"kafka_broker_list"= "localhost:9092",
"kafka_topic" = "starrocks-load"
);2. Verify the job is running
SHOW ROUTINE LOAD FOR load_test.routine_load_wikipedia;Look for State: RUNNING in the output. If the state is NEED_SCHEDULE, wait a moment and run the command again — the job transitions to RUNNING shortly after scheduling completes.
Create a load job
Syntax
CREATE ROUTINE LOAD [database.][job_name] ON [table_name]
[COLUMNS TERMINATED BY "column_separator" ,]
[COLUMNS (col1, col2, ...) ,]
[WHERE where_condition ,]
[PARTITION (part1, part2, ...)]
[PROPERTIES ("key" = "value", ...)]
FROM KAFKA
[(data_source_properties1 = 'value1',
data_source_properties2 = 'value2',
...)]Run HELP ROUTINE LOAD; to view the full syntax reference.
Parameters
Required parameters
| Parameter | Description |
|---|---|
job_name | Name of the load job. Must be unique within a database. Typically formatted as a timestamp plus table name. Optionally prefix with the database name: database.job_name. |
table_name | Name of the destination table. |
DATA_SOURCE | Data source type. Set to KAFKA. |
Data filtering and mapping
| Parameter | Description |
|---|---|
COLUMNS TERMINATED BY | Column separator in the source data. Default: \t. |
COLUMNS | Maps source columns to destination table columns, and defines derived columns. See Column mapping below. |
WHERE | Filters rows before loading. Rows filtered by the WHERE condition are not counted as error rows. |
PARTITION | Loads data into specific partitions of the destination table. If omitted, StarRocks routes data to the matching partition automatically. |
Job behavior (PROPERTIES)
| Parameter | Default | Description |
|---|---|---|
desired_concurrent_number | 3 | Maximum number of concurrent tasks the job can split into. Must be greater than 0. |
max_batch_interval | 10 | Task scheduling interval in seconds. Valid range: 5–60. In V1.15 and later, this sets how often tasks are scheduled; the actual data consumption time is controlled by routine_load_task_consume_second in fe.conf (default: 3s), and the task timeout by routine_load_task_timeout_second in fe.conf (default: 15s). |
max_batch_rows | 200000 | Maximum rows each task can read. Must be ≥ 200,000. In V1.15 and later, this parameter is used only to define the error detection window size: 10 × max_batch_rows. |
max_batch_size | 100 MB | Maximum bytes each task can read. Valid range: 100 MB–1 GB. Deprecated in V1.15 and later — use routine_load_task_consume_second in fe.conf instead. |
max_error_number | 0 | Maximum error rows allowed within the sampling window. Must be ≥ 0. The default of 0 means no error rows are allowed. |
strict_mode | Enabled | When enabled, rows where a non-null source value converts to NULL after type casting are dropped. Set to false to disable. |
timezone | Session time zone | Time zone applied to all time zone-sensitive functions during the load. |
Kafka source properties
| Property | Required | Description |
|---|---|---|
kafka_broker_list | Yes | Broker connection info. Format: ip:port. Separate multiple brokers with commas. |
kafka_topic | Yes | Kafka topic to subscribe to. |
kafka_partitions | No | Specific partitions to subscribe to. |
kafka_offsets | No | Start offset for each subscribed partition. |
property | No | Additional Kafka properties, equivalent to --property in Kafka Shell. |
Column mapping
Use the COLUMNS clause to map source columns to destination table columns.
Mapped columns — skip or reorder source columns. For example, if the destination table has columns col1, col2, col3 but the source has four columns where the fourth maps to col3:
COLUMNS (col2, col1, temp, col3)
-- "temp" is a placeholder that absorbs the third source column without loading itDerived columns — compute column values from source data. For example, to populate col4 as the sum of col1 and col2:
COLUMNS (col2, col1, temp, col3, col4 = col1 + col2)Manage load jobs
View job status
List all load jobs in a database, including stopped and canceled ones:
USE <database>;
SHOW ALL ROUTINE LOAD;View a specific running job by name:
SHOW ROUTINE LOAD FOR <database>.<job_name>;StarRocks only shows running jobs with SHOW ROUTINE LOAD. Completed and not-yet-started jobs are not returned. Use SHOW ALL ROUTINE LOAD to include stopped and canceled jobs.
Run HELP SHOW ROUTINE LOAD; or HELP SHOW ROUTINE LOAD TASK; for more options.
Output fields
The SHOW ROUTINE LOAD output includes the following key fields:
| Field | Description |
|---|---|
State | Job status: RUNNING, PAUSED, NEED_SCHEDULE, or STOPPED |
Statistic | Cumulative load statistics since job creation |
receivedBytes | Total bytes received |
errorRows | Number of rows that failed to load |
committedTaskNum | Number of tasks committed by the FE |
loadedRows | Number of rows successfully loaded |
loadRowsRate | Load throughput in rows/second |
abortedTaskNum | Number of tasks aborted on the backend |
totalRows | Total rows received (including error and filtered rows) |
unselectedRows | Rows filtered out by the WHERE condition |
receivedBytesRate | Data receive rate in bytes/second |
taskExecuteTimeMs | Total task execution time in milliseconds |
ErrorLogUrls | URLs for downloading error logs from the load process |
Progress | Current Kafka consumer offset per partition |
Example output
*************************** 1. row ***************************
Id: 14093
Name: routine_load_wikipedia
CreateTime: 2020-05-16 16:00:48
PauseTime: N/A
EndTime: N/A
DbName: default_cluster:load_test
TableName: routine_wiki_edit
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","columnToColumnExpr":"event_time,channel,user,is_anonymous,is_minor,is_new,is_robot,is_unpatrolled,delta,added,deleted","maxBatchIntervalS":"10","whereExpr":"*","maxBatchSizeBytes":"104857600","columnSeparator":"','","maxErrorNum":"1000","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"starrocks-load","currentKafkaPartitions":"0","brokerList":"localhost:9092"}
CustomProperties: {}
Statistic: {"receivedBytes":150821770,"errorRows":122,"committedTaskNum":12,"loadedRows":2399878,"loadRowsRate":199000,"abortedTaskNum":1,"totalRows":2400000,"unselectedRows":0,"receivedBytesRate":12523000,"taskExecuteTimeMs":12043}
Progress: {"0":"13634667"}
ReasonOfStateChanged:
ErrorLogUrls: http://172.26.**.**:9122/api/_load_error_log?file=__shard_53/error_log_insert_stmt_47e8a1d107ed4932-8f1ddf7b01ad2fee_47e8a1d107ed4932_8f1ddf7b01ad2fee, http://172.26.**.**:9122/api/_load_error_log?file=__shard_54/error_log_insert_stmt_e0c0c6b040c044fd-a162b16f6bad53e6_e0c0c6b040c044fd_a162b16f6bad53e6, http://172.26.**.**:9122/api/_load_error_log?file=__shard_55/error_log_insert_stmt_ce4c95f0c72440ef-a442bb300bd743c8_ce4c95f0c72440ef_a442bb300bd743c8
OtherMsg:
1 row in set (0.00 sec)Pause a load job
PAUSE ROUTINE LOAD FOR <job_name>;The job enters PAUSED state. Data ingestion stops, but the job is not terminated — Statistic and Progress stop updating. Resume the job with RESUME ROUTINE LOAD when ready.
Run HELP PAUSE ROUTINE LOAD; for examples.
Resume a load job
RESUME ROUTINE LOAD FOR <job_name>;The job temporarily enters NEED_SCHEDULE state while the FE reschedules tasks. It returns to RUNNING shortly after, and Statistic and Progress resume updating.
Run HELP RESUME ROUTINE LOAD; for examples.
Stop a load job
STOP ROUTINE LOAD FOR <job_name>;The job enters STOPPED state. Ingestion is terminated permanently — stopped jobs cannot be resumed. A stopped job does not appear in SHOW ROUTINE LOAD output.
Run HELP STOP ROUTINE LOAD; for examples.