This guide shows you how to connect DataWorks to EMR Serverless StarRocks and use five DataWorks features with your StarRocks data: data integration, data development and scheduling, ad-hoc analysis, API generation, and metadata management.
Overview
StarRocks is a next-generation, high-speed Massively Parallel Processing (MPP) database for unified analytics. EMR Serverless StarRocks is a fully managed service for open-source StarRocks on Alibaba Cloud. You can create and manage StarRocks instances without provisioning infrastructure.
As an online analytical processing (OLAP) engine compatible with the MySQL protocol, StarRocks supports:
Multi-dimensional OLAP analysis
Data lake analysis
High-concurrency queries
Real-time data analysis
DataWorks connects to EMR Serverless StarRocks through a data source. After connecting, you can run data integration jobs, schedule recurring tasks, perform interactive analysis, build data APIs, and manage metadata from a single platform.
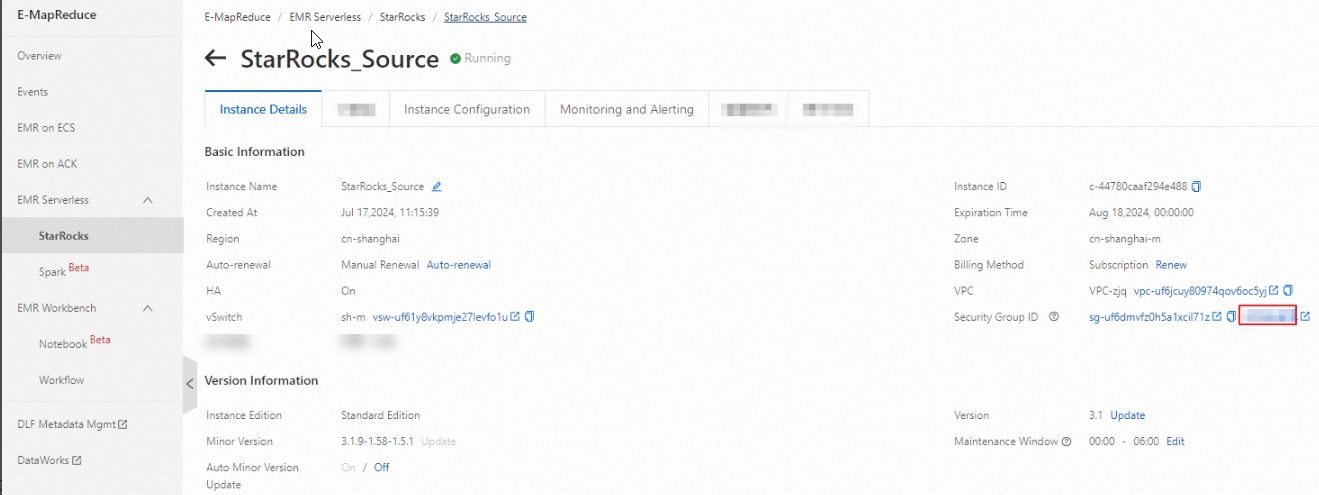
After you create a StarRocks instance, you can view instance details in the EMR console. You can also connect to the instance through EMR StarRocks Manager to view database and table information.
Choose the right feature
Use the following table to decide which DataWorks feature fits your goal.
| Goal | DataWorks feature | When to use |
|---|---|---|
| Move data into StarRocks from external sources | Data Integration | Sync data from MySQL, Hive, Kafka, OSS, HDFS, or other sources into StarRocks tables on a recurring schedule. |
| Run and schedule SQL tasks | Data Development + Operation Center | Create StarRocks SQL tasks, debug them, and run them on a recurring schedule with dependency management. |
| Run ad-hoc queries | Data Analysis | Interactively query, analyze, and share data in StarRocks tables without a scheduled job. |
| Expose StarRocks data as REST APIs | DataService Studio | Generate and publish API endpoints that serve StarRocks data to downstream applications. |
| Search and manage metadata | Data Map | Catalog StarRocks metadata, search for tables, view table details, or trace data lineage. |
Key concepts
| Concept | Description | References |
|---|---|---|
| Resource group | Runs DataWorks tasks. You must purchase, bind, and configure a resource group before using DataWorks features. | Resource group fees, Resource group management |
| Data source | A connection to an external data store. For EMR Serverless StarRocks, create a StarRocks data source. | StarRocks data source |
| Data Integration | Synchronizes data between heterogeneous data sources in batch or real-time mode. | Data Integration overview |
| Data Development and Operation Center | Data Development lets you write and debug tasks. Operation Center runs them on a recurring, automated schedule. | DataStudio (Old Version), Operation Center overview |
| Data Analysis | Online service for interactive data querying, editing, and sharing. | Data Analysis |
| DataService Studio | Platform for building, managing, and publishing data APIs with codeless and code-based interfaces. | DataService Studio |
| Data Map | Metadata management module with global search, metadata detail viewing, data preview, data lineage, and data category management. | Data Map overview |
Prerequisites
Complete all of the following before you begin:
Activate DataWorks and create a workspace. See Purchasing guide.
Purchase and configure a resource group. Bind the resource group to your workspace and configure its network settings. See Resource group management.
Create an EMR Serverless StarRocks instance. See Quickly use an all-in-one instance.
Add the DataWorks resource group IP address to your StarRocks whitelist. In the EMR console, open your StarRocks instance and add the IP address to the whitelist.
Navigate to the DataWorks console
Most procedures in this guide start from the DataWorks console. Use these steps each time:
Log on to the DataWorks console.
In the top navigation bar, select the target region.
In the left-side navigation pane, choose the target service (specified in each section below).
Select the target workspace from the drop-down list and click Go to.
The sections below reference this as "navigate to the DataWorks console" and specify the exact menu path.
Create a data source
A StarRocks data source connects DataWorks to your StarRocks database. All DataWorks features use this connection.
For workspaces that Use Data Studio (New Version), a data source is automatically created when you bind an EMR Serverless StarRocks compute resource. You do not need to follow the steps below.
For workspaces that do not use Use Data Studio (New Version), you must create the data source manually.
For full parameter details, see StarRocks data source.
Open the Data Sources page
Navigate to the DataWorks console.
In the left-side navigation pane, choose More > Management Center.
Select the desired workspace and click Go to Management Center.
In the left-side navigation pane of the Management Center page, click Data Sources.
Click Add Data Source.
Choose a connection method based on network connectivity between your StarRocks instance and DataWorks resource group. For help, see Overview of network connectivity solutions.
Option A: Connect over an internal network
Use this method when your StarRocks instance and DataWorks resource group are in the same VPC or can communicate over the Alibaba Cloud internal network.
| Parameter | Description |
|---|---|
| Configuration Mode | Select Alibaba Cloud Instance Mode. |
| Alibaba Cloud Account | Select Current Alibaba Cloud Account if the StarRocks instance belongs to the same account as DataWorks. Select Another Alibaba Cloud Account if it belongs to a different account -- provide the UID Of Another Alibaba Cloud Account and configure a RAM Role. See Cross-account authorization (RDS, Hive, or Kafka). |
| Region | Select the region where your EMR Serverless StarRocks instance resides. |
| Instance | Select your Serverless StarRocks instance. |
| Database Name | Enter the database name. Find this in EMR StarRocks Manager on the Metadata Management page. |
| Username / Password | Enter the instance credentials. An admin user is created by default when you create a StarRocks instance. The password is the one set during instance creation. |
| Connection Configuration | Test connectivity between the data source and your resource group. A status of Connected confirms the connection is working. |
Option B: Connect over the Internet
Use this method when your StarRocks instance and DataWorks resource group are not on the same internal network and you need to connect through the public endpoint.
| Parameter | Description |
|---|---|
| Configuration Mode | Select Connection String Mode. |
| Host Address/IP Address | Enter the Public endpoint of the FE node in your EMR Serverless StarRocks instance.  |
| Port | Enter the FE query port. The default query port is 9030. |
| Load URL | Enter the addresses of StarRocks FE nodes for StreamLoad. Use the format FE public IP address:FE HTTP port. Separate multiple addresses with commas. |
| Database Name | Enter the database name. Find this in EMR StarRocks Manager under Metadata Management. |
| Username / Password | Enter the instance credentials. An admin user is created by default when you create a StarRocks instance. The password is the one set during instance creation. |
| Connection Configuration | Test connectivity between the data source and your resource group. A status of Connected confirms the connection is working. |
Verification: After you save the data source, return to the Data Sources list and confirm your new StarRocks data source appears with a Connected status.
Sync data with Data Integration
Use DataWorks Data Integration to sync data from external sources -- including MySQL, Hive, Kafka, OSS, and HDFS -- into EMR Serverless StarRocks tables. The following example syncs data from MySQL to StarRocks.
For full details on configuring a StarRocks synchronization task, see StarRocks data source.
Create and run a batch synchronization task
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Development and O&M > Data Development.
Select the desired workspace and click Go to Data Development.
Create a new batch synchronization node.
Set the source data source to MySQL.
Set the destination data source to StarRocks.

Select a resource group for the task.
Test the connectivity to both the source and destination data sources.
Click Properties in the right sidebar.
Configure the scheduling parameters:
Set the scheduling cycle (for example, daily or hourly).
Set the rerun policy.
Assign a resource group for the node.
Click Submit.
Click Deploy to publish the task to Operation Center for recurring execution.
Verification: After deployment, open Operation Center and confirm the synchronization task appears in the task list with the correct schedule.
Develop and schedule SQL tasks
Create a StarRocks node in DataStudio for SQL tasks that run on a recurring schedule. You can write SQL, debug it interactively, and set up automated scheduling.
Create and schedule a StarRocks SQL task
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Development and O&M > Data Development.
Select the desired workspace and click Go to Data Development.
Create a new StarRocks node.
Select the connected StarRocks data source.
Write your EMR Serverless StarRocks SQL statements in the editor.
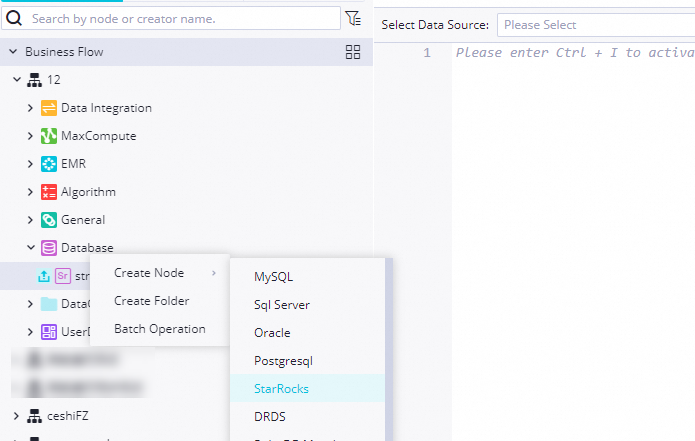
To debug the SQL, select the statements you want to run.
Click the Run button.
Select a resource group when prompted to run the debugging task.
After successful debugging, click Properties in the right sidebar.
Configure the scheduling parameters:
Set the scheduling cycle (for example, daily or hourly).
Set the rerun policy.
Assign a resource group for the task.
Click Submit.
Click Deploy to publish the task to Operation Center for recurring execution.
Verification: After deployment, open Operation Center and confirm the task appears with the correct schedule and dependency settings.
Run ad-hoc queries with Data Analysis
Use the Data Analysis service to run ad-hoc queries against EMR Serverless StarRocks tables without setting up a scheduled task.
Set up and run a query
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Analysis and Service > DataAnalysis.
Click Go to DataAnalysis.
In the left-side navigation pane, click SQL Query.
Click the
 icon in the left sidebar.
icon in the left sidebar.Click More > System Management.
On the System Management page, set the query resource group for the StarRocks engine type to the resource group your task uses.

Return to the SQL Query page.
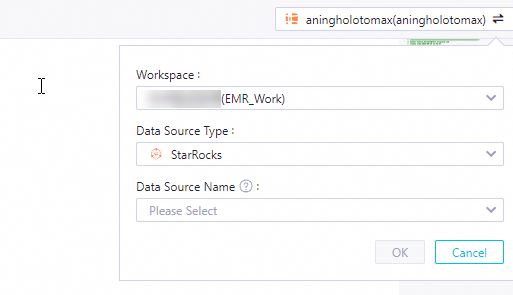
In the upper-right corner, switch the engine type to StarRocks.
Select your data source.
Write and run your query statements to analyze data in EMR Serverless StarRocks.
Verification: After running a query, confirm that results appear in the results panel below the editor.
Generate APIs with DataService Studio
Use DataService Studio to generate REST APIs that serve data from StarRocks data sources. DataService Studio provides both a codeless UI and a code editor. The code editor can automatically generate request and response parameters from an SQL query.
The following steps describe how to create an API using the codeless UI.
Create and publish a StarRocks API
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Analysis and Service > DataService Studio.
Select the desired workspace and click Go to DataService Studio.
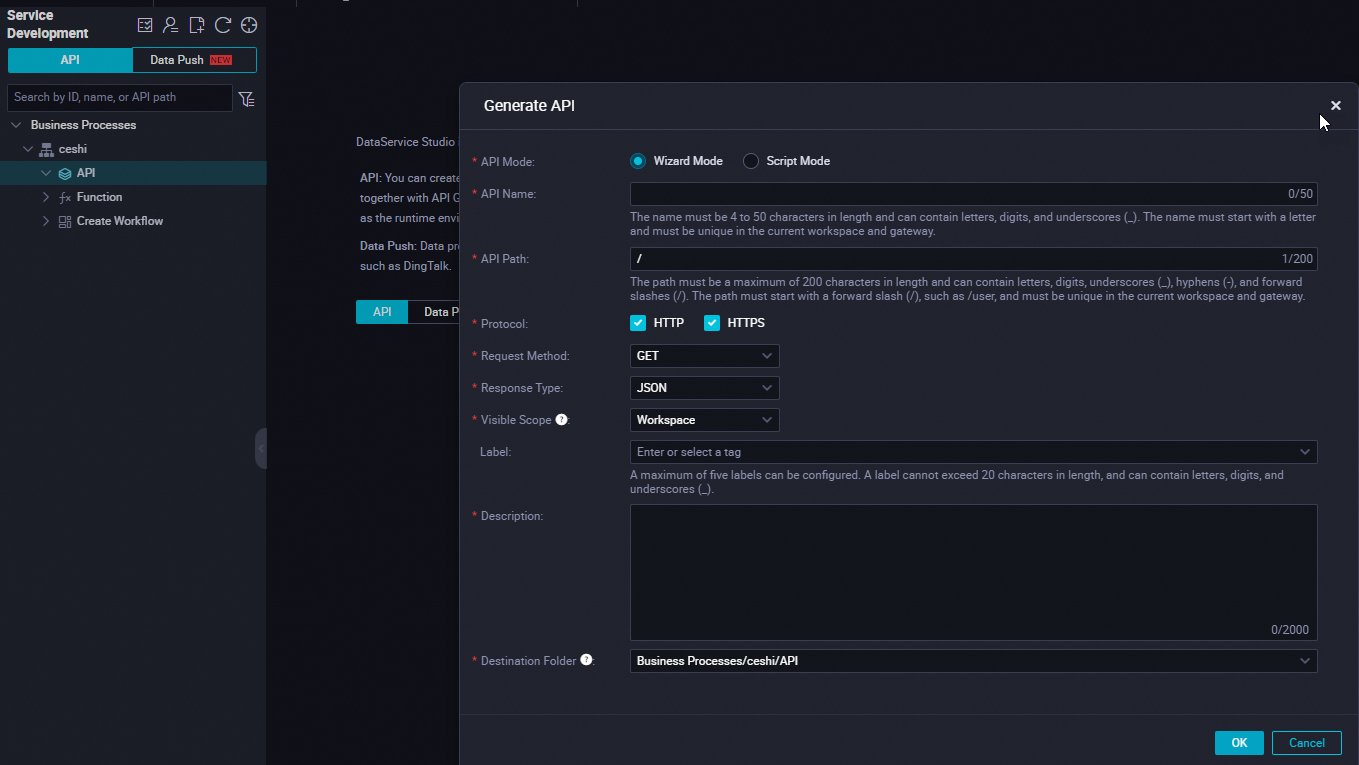
Create a new API.
Set the data source type to StarRocks.
Select the StarRocks data source you created and the target table.
Configure the API parameters (request parameters and response parameters) as prompted on the page.
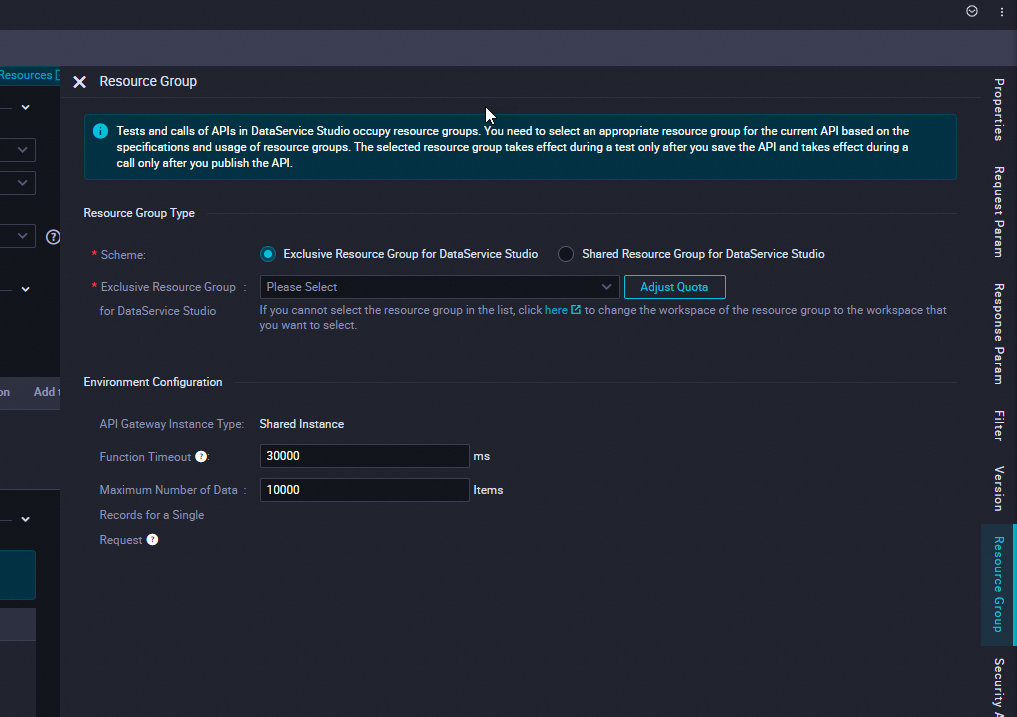
Click Resource Group in the right sidebar.
Set the resource group to an exclusive resource group for DataService Studio.
Test the API to make sure it returns the expected results.
Click Submit.
Click Deploy to publish the API.
Verification: After publishing, call the API endpoint and confirm it returns the expected data.
Manage metadata with Data Map
Data Map lets you catalog, search, and explore metadata for StarRocks tables.
Acquire metadata
Configure metadata acquisition to crawl your StarRocks data source and catalog its metadata.
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Governance > Data Map.
Click Go to Data Map.
In the left-side navigation pane, click the
 icon.
icon.Click the Manage button in the upper-right corner of the StarRocks module.
Switch to the Data Sources for Which No Crawler Is Created tab.
In the Actions column, click Metadata Acquisition.
Configure the Resource Group Name.
Click Test Network Connectivity to verify the connection.
Set the Collection Plan.
Click Confirmation to save the metadata acquisition configuration.

For more details, see Metadata acquisition.
Only serverless resource groups can run this task.
Verification: After saving, return to the Data Map main page and confirm that your StarRocks data source appears with an active crawler.
Search for tables
Find StarRocks tables by name, type, or other attributes.
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Governance > Data Map.
Click Go to Data Map.
In the left-side navigation pane, click the
 icon.
icon.On the Data Source tab, select StarRocks.
Use the search bar at the top to search for tables by type.

For more details, see Query and manage common data.
View table details
View detailed information about a specific StarRocks table, including schema, output records, lineage, and usage notes.
Navigate to the DataWorks console.
In the left-side navigation pane, choose Data Governance > Data Map.
Click Go to Data Map.
On the Data Map homepage or in search results, find the target table.
Click the table name to open the table details page.
Review the following tabs: Details, Output, Lineage, and Usage Notes.

For more details on table information, see Query and manage common data.
StarRocks serverless clusters of V3.1.13, V3.2.9, and later versions support metadata and data lineage analysis. For configuration details, see View data lineage.