DataWorks Data Map provides detailed lineage information for tables and DataService Studio APIs on their respective details pages, helping you trace data origins and manage dependencies. The console categorizes compute and metadata by type, such as EMR Hive, Data Lake Formation (DLF), and Data Lake Formation (DLF-Legacy). This page explains how to view lineage for each type.
Table Lineage
Viewing entry point
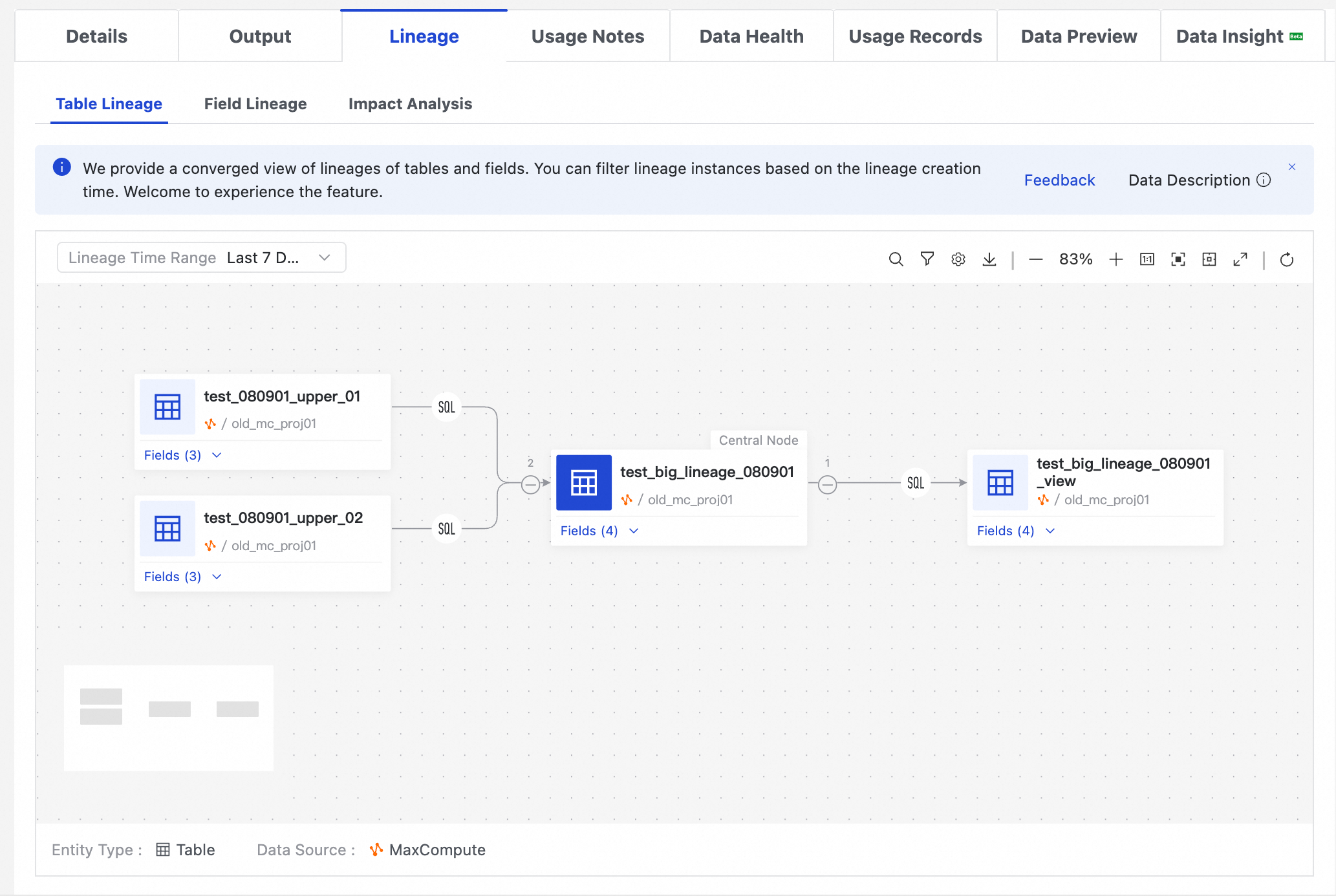
In Data Map, find a table and navigate to its details page. Click the Lineage Information tab to view table-level and field-level lineage details. You can also perform an impact analysis to obtain a list of downstream tables, download the list as a local file, or send change notifications by email.
Data Map displays lineage parsed from scheduling jobs and data forwarding information. Lineage from manual operations, such as temporary queries, is not included. Offline data lineage is updated on a T+1 basis.
To view complex, multi-level lineage in a larger area, click the Open in New Page button (the full-screen icon) in the upper-right toolbar of the lineage graph. This opens the lineage on a separate page. This button is available on lineage tabs for tables, datasets, DataService Studio APIs, and AI assets.
If the data lineage feature is not enabled for your workspace or tenant, a subscription page appears when you navigate to the lineage tab. Follow the on-screen instructions to purchase or enable the feature.
Limits for each data source
EMR Hive, DLF, and DLF-Legacy
-
EMR Hive: To manage metadata for an EMR cluster in DataWorks, you must first configure EMR-HOOK on the cluster. If EMR-HOOK is not configured, lineage cannot be displayed in DataWorks. For more information, see Configure EMR-HOOK for Hive.
-
DLF and DLF-Legacy: For tables in Data Lake Formation (DLF) and Data Lake Formation (DLF-Legacy), lineage is displayed in Data Map after metadata is collected. This is supported when compute jobs use DLF metadata with the Serverless Spark, Serverless StarRocks, or Serverless Flink engine. For other engines or scenarios, lineage display depends on metadata acquisition and parsing capabilities. For more information, see Metadata acquisition.
ImportantThe Serverless Spark, Serverless StarRocks, and Serverless Flink engines must be associated with a DataWorks workspace. Otherwise, the corresponding lineage is considered irrelevant to DataWorks and is ignored.
-
For EMR Hive compute clusters: Lineage viewing is not supported for EMR on ACK Spark clusters but is supported for EMR Serverless Spark clusters.
-
For EMR Hive compute clusters: Lineage is not available for tasks that run on EMR Presto nodes.
-
EMR Impala engine: Lineage acquisition for EMR Impala jobs depends on Impala's own lineage logs. In the EMR cluster console, go to Cluster Services > Impala > Configuration. Set the
lineage_event_log_dirparameter to/mnt/disk1/log/impala/lineage_logand restart the Impala service. After you perform these steps, DataWorks Data Map can display table-level and field-level lineage for EMR Impala jobs.Note-
Only Impala jobs on EMR DataLake clusters are supported. Both HMS (corresponding to the EMR Hive data source type) and DLF (corresponding to the DLF data source type) metadata are supported.
-
There are no requirements on the EMR cluster version or the Impala version. Impala only needs to be deployed on the cluster.
-
This feature is currently in gray release. Before using it, submit a ticket or contact Alibaba Cloud technical support to enable it.
-
AnalyticDB for MySQL
-
Run the SQL statement
set adb_config RC_LINEAGE_INFO_LOG_ENABLE=trueon the corresponding engine to enable the data lineage feature for the AnalyticDB for MySQL instance. -
When the metadata source is of the AnalyticDB for Spark type, automatic collection is supported.
-
When the metadata source is of the AnalyticDB for Spark type, you can enable real-time lineage by configuring the Spark parameter
spark.sql.queryExecutionListeners = com.aliyun.dataworks.meta.lineage.LineageListener.
For tables of the AnalyticDB for MySQL type, some SQL processing commands do not support generating lineage information in Data Map. The following limits apply.
-
SQL commands that do not support lineage display:
Unsupported SQL
Example
join,union, or the use of keywords such as*are not supported.For example, the following SQL uses
*, so Data Map cannot display the lineage.INSERT INTO test SELECT * FROM test1, test2 WHERE test1.id = test2.idSubqueries are not supported.
For example, the following SQL contains a subquery, so Data Map cannot display the lineage.
SELECT column1, column2 FROM table1 WHERE column3 IN (SELECT column4 FROM table2 WHERE column5 = 'value') -
Examples of SQL commands that support lineage display:
-
Example 1: Create a table named A (without specifying columns) and select specific columns (excluding *) from table B as the content of table A. For example:
CREATE TABLE test AS SELECT id,name FROM test1; -
Example 2: Insert specific columns (excluding *) from table A that meet the condition column1 = value1 into table B (without specifying columns). For example:
INSERT INTO test SELECT id,name FROM test1 WHERE name='test'; -
Example 3: Overwrite specific columns (excluding *) from table A into table B in a database. For example:
INSERT OVERWRITE INTO db_name.test SELECT id,name FROM test1;
-
CDH
To display table lineage for CDH Spark SQL and CDH Spark node data processing in Data Map, configure the Spark parameters for each data processing module in .
Log on to the DataWorks console. In the target region, click in the left-side navigation pane. Select a workspace from the drop-down list and click Go to Management Center.
-
In the left-side navigation pane, click Cluster Management, and then find the target CDH cluster that you have created.
-
Click Edit Spark Parameters.

-
Add Spark parameters based on the specific data processing module.
For example, to display table lineage for data processing by CDH Spark SQL and CDH Spark nodes in the Operation Center - Scheduled Instances module in Data Map, add the following parameters in the corresponding module:
-
Spark Property Name:
spark.sql.queryExecutionListeners. -
Spark Property Value:
com.aliyun.dataworks.meta.lineage.LineageListener.
-
-
Click Confirm to complete the editing.
Lindorm
Lineage information collection is supported only in instance mode. Connection string mode does not support lineage information collection.
To display table lineage for Lindorm Spark and Lindorm Spark SQL node data processing in Data Map, configure the Spark parameters for each data processing module in .
Log on to the DataWorks console. In the target region, click in the left-side navigation pane. Select a workspace from the drop-down list and click Go to Management Center.
-
In the left-side navigation pane, click Computing Resources, and then find the Lindorm compute resource that you have created.
-
Click Edit Spark Parameters.
-
Add Spark parameters based on the specific data processing module.
For example, to display table lineage for data processing by Lindorm Spark and Lindorm Spark SQL nodes in the Operation Center - Scheduled Instances module in Data Map, add the following parameters in the corresponding module:
-
Spark Property Name:
spark.sql.queryExecutionListeners. -
Spark Property Value:
com.aliyun.dataworks.meta.lineage.LineageListener.
-
-
Click Confirm to complete the Spark parameter configuration.
Lineage support for each data source
The original E-MapReduce category in Data Map has been split into EMR Hive, DLF, and DLF-Legacy based on metadata sources. The following table lists the lineage support by data source category as displayed in the current console.
|
Data source |
Data Integration |
Data Studio |
||
|
Table-level lineage |
Column-level lineage |
Table-level lineage |
Column-level lineage |
|
|
AnalyticDB MySQL
|
|
|
|
|
|
AnalyticDB PostgreSQL
|
|
|
|
|
|
ClickHouse
|
|
|
|
|
|
CDH/CDP
|
|
|
Hive, Impala, Spark, Spark SQL
|
Hive, Impala, Spark, Spark SQL
|
|
EMR Hive
|
(OSS, Hive)
|
(OSS, Hive)
|
Supported engines: E-MapReduce, Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
Supported engines: E-MapReduce, Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
|
DLF-Legacy
|
(OSS, Hive)
|
(OSS, Hive)
|
Supported engines: E-MapReduce, Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
Supported engines: E-MapReduce, Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
|
DLF
|
(OSS, Hive)
|
(OSS, Hive)
|
Supported engines: Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
Supported engines: Serverless Spark, Serverless StarRocks, Serverless Flink, and EMR Impala (EMR DataLake clusters only; currently in gray release; contact Alibaba Cloud technical support to enable it before use).
|
|
Hologres
|
|
|
|
|
|
Kafka
|
(Kafka synchronized to MaxCompute/Hologres) |
|
|
|
|
Lindorm
|
|
|
|
|
|
MaxCompute
|
|
|
|
|
|
MySQL
|
(MySQL synchronized to MaxCompute/Hologres) |
|
|
|
|
Oracle
|
|
|
|
|
|
OceanBase
|
|
|
|
|
|
OSS
|
|
|
|
|
|
PolarDB MySQL
|
|
|
|
|
|
PolarDB PostgreSQL
|
|
|
|
|
|
PostgreSQL
|
|
|
|
|
|
StarRocks
|
|
|
|
|
|
SQL Server
|
|
|
|
|
|
Tablestore (OTS)
|
|
|
|
|
 Details page
Details page Real-time synchronization
Real-time synchronizationDataService Studio API lineage
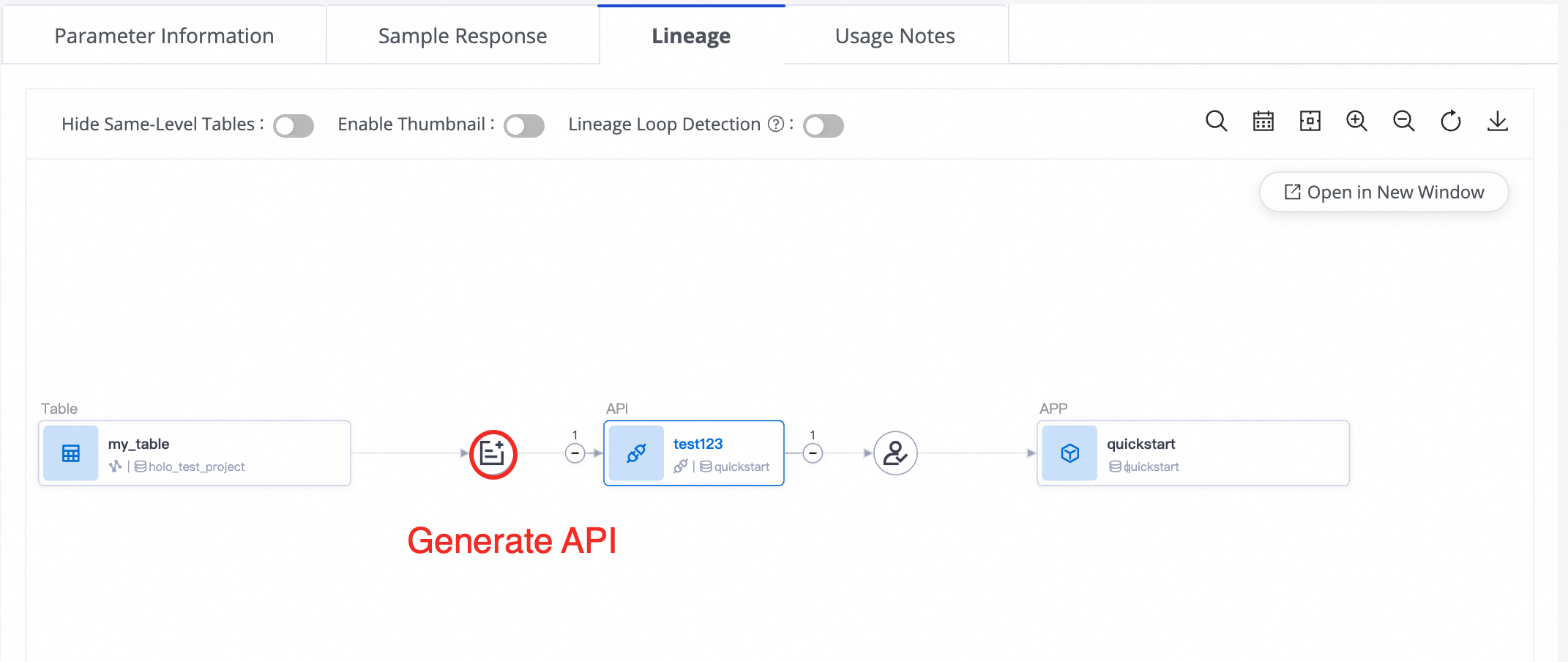
Find a DataService Studio API in Data Map and navigate to its details page. Click the Lineage Information tab to view the API lineage details.
AI asset lineage
AI asset lineage traces input datasets, output result sets, and relationships between models used in model training. For more information, see AI asset lineage.