In a multi-model Model Service Mesh deployment, a Kubernetes service distributes inference requests randomly across all model serving runtimes. If a request reaches a runtime that does not host the target model, Model Service Mesh reroutes it internally until it finds the correct runtime. This rerouting adds latency.
Dynamic subset load balancing solves this problem by grouping runtimes based on the models they host. When an inference request arrives at the Service Mesh (ASM) gateway, the gateway reads the model name from the request header and routes the request directly to a runtime that hosts that model. This eliminates rerouting and reduces inference latency.
For the concept overview, see Dynamic subset load balancing.
How it works
Dynamic subset load balancing relies on two Istio resources: a DestinationRule defines *which runtimes* to group together, and a VirtualService defines *how to match requests* to those groups.
DestinationRule groups runtimes into subsets. ASM extends the standard DestinationRule with a
dynamicSubsetfield that groups endpoints by a label key. Model Service Mesh automatically updates runtime labels as models are loaded or unloaded, so subsets stay current without manual intervention.VirtualService matches incoming requests to subsets. ASM extends the standard VirtualService with a
headerToDynamicSubsetKeyfield that maps a request header (such asmodel) to the dynamic subset label key. The gateway uses this mapping to route each request to the correct subset.
If no subset matches the request, the fallbackPolicy determines what happens:
| Fallback policy | Behavior |
|---|---|
ANY_ENDPOINT | Routes to any available runtime regardless of labels. Preserves availability at the cost of potential rerouting. Used in this tutorial. |
Prerequisites
Before you begin, make sure that you have:
An ASM instance of V1.21.6.47 or later. For more information, see Create an ASM instance
A Container Service for Kubernetes (ACK) cluster added to the ASM instance. For more information, see Add a cluster to an ASM instance
Model Service Mesh enabled with the sklearn-mnist model deployed. For more information, see Use Model Service Mesh to roll out a multi-model inference service
Step 1: Deploy a second model
Dynamic subset load balancing targets multi-model scenarios. This step adds a tf-mnist model (a TensorFlow-based MNIST model served by the Triton runtime) alongside the existing sklearn-mnist model.
This step uses the persistent volume claim (PVC) my-models-pvc created in Use Model Service Mesh to roll out a multi-model inference service. The tf-mnist model content is everything inside the mnist directory.
Store the model on the persistent volume
Connect to the ACK cluster with kubectl, then copy the
mnistmodel directory to the persistent volume:kubectl -n modelmesh-serving cp mnist pvc-access:/mnt/models/Verify that the model exists on the persistent volume:
kubectl -n modelmesh-serving exec -it pvc-access -- ls -alr /mnt/models/Expected output:
-rw-r--r-- 1 502 staff 344817 Apr 23 08:17 mnist-svm.joblib drwxr-xr-x 3 root root 4096 Apr 23 08:23 mnist drwxr-xr-x 1 root root 4096 Apr 23 08:17 .. drwxrwxrwx 3 root root 4096 Apr 23 08:23 .
Deploy the inference service
Create a file named
tf-mnist.yamlwith the following content:apiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: name: tf-mnist namespace: modelmesh-serving annotations: serving.kserve.io/deploymentMode: ModelMesh spec: predictor: model: modelFormat: name: tensorflow storage: parameters: type: pvc name: my-models-pvc path: mnistApply the manifest:
kubectl apply -f tf-mnist.yamlWait for the image to pull, then verify that both models are ready:
kubectl get isvc -n modelmesh-servingExpected output:
NAME URL READY sklearn-mnist grpc://modelmesh-serving.modelmesh-serving:8033 True tf-mnist grpc://modelmesh-serving.modelmesh-serving:8033 True
(Optional) Step 2: Benchmark inference latency before optimization
Use fortio to measure baseline latency before enabling dynamic subset load balancing. To obtain the ASM ingress gateway IP address, see Integrate KServe with ASM to implement inference services based on cloud-native AI models.
Set the gateway IP and run a 60-second load test against the tf-mnist model:
ASM_GW_IP="<your-asm-gateway-ip>" fortio load -jitter=False -H 'model: tf-mnist' -c 1 -qps 100 -t 60s -payload '{"inputs": [{ "name": "inputs", "shape": [1, 784], "datatype": "FP32", "contents": { "fp32_contents": [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.01176471, 0.07058824, 0.07058824, 0.07058824, 0.49411765, 0.53333336, 0.6862745, 0.10196079, 0.6509804, 1.0, 0.96862745, 0.49803922, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.11764706, 0.14117648, 0.36862746, 0.6039216, 0.6666667, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.88235295, 0.6745098, 0.99215686, 0.9490196, 0.7647059, 0.2509804, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.19215687, 0.93333334, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.9843137, 0.3647059, 0.32156864, 0.32156864, 0.21960784, 0.15294118, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.07058824, 0.85882354, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.7764706, 0.7137255, 0.96862745, 0.94509804, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3137255, 0.6117647, 0.41960785, 0.99215686, 0.99215686, 0.8039216, 0.04313726, 0.0, 0.16862746, 0.6039216, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.05490196, 0.00392157, 0.6039216, 0.99215686, 0.3529412, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.54509807, 0.99215686, 0.74509805, 0.00784314, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.04313726, 0.74509805, 0.99215686, 0.27450982, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.13725491, 0.94509804, 0.88235295, 0.627451, 0.42352942, 0.00392157, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.31764707, 0.9411765, 0.99215686, 0.99215686, 0.46666667, 0.09803922, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.1764706, 0.7294118, 0.99215686, 0.99215686, 0.5882353, 0.10588235, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0627451, 0.3647059, 0.9882353, 0.99215686, 0.73333335, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.9764706, 0.99215686, 0.9764706, 0.2509804, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.18039216, 0.50980395, 0.7176471, 0.99215686, 0.99215686, 0.8117647, 0.00784314, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.15294118, 0.5803922, 0.8980392, 0.99215686, 0.99215686, 0.99215686, 0.98039216, 0.7137255, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.09411765, 0.44705883, 0.8666667, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.7882353, 0.30588236, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.09019608, 0.25882354, 0.8352941, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.7764706, 0.31764707, 0.00784314, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.07058824, 0.67058825, 0.85882354, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.7647059, 0.3137255, 0.03529412, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.21568628, 0.6745098, 0.8862745, 0.99215686, 0.99215686, 0.99215686, 0.99215686, 0.95686275, 0.52156866, 0.04313726, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.53333336, 0.99215686, 0.99215686, 0.99215686, 0.83137256, 0.5294118, 0.5176471, 0.0627451, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0] }}]}' -a ${ASM_GW_IP}:8008/v2/models/tf-mnist/inferExpected output:
View the fortio results in a browser:
fortio serverOpen
localhost:8080, click saved results, and select the JSON file to view the latency distribution.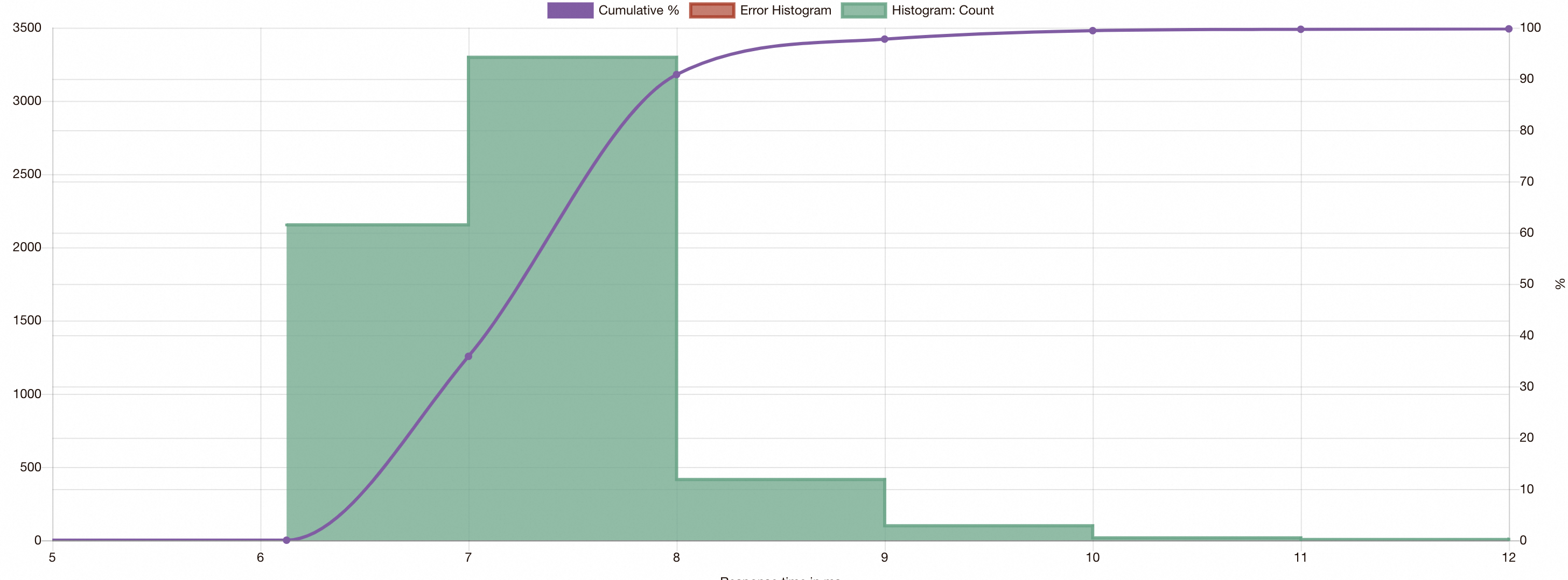
Without dynamic subset load balancing, some inference requests show increased latency because they are rerouted through Model Service Mesh before reaching the correct runtime.
Step 3: Enable dynamic subset load balancing
Inference requests reach Model Service Mesh through the modelmesh-serving service in the modelmesh-serving namespace. Configure a DestinationRule and a VirtualService on this service to route requests directly to the correct model serving runtime.
Create the DestinationRule
Apply the following DestinationRule to group model serving runtimes dynamically by the models they host. For more information, see Manage destination rules.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: modelmesh-serving
namespace: modelmesh-serving
spec:
host: modelmesh-serving
trafficPolicy:
loadBalancer:
dynamicSubset:
subsetSelectors:
- fallbackPolicy: ANY_ENDPOINT
keys:
- modelmesh.asm.alibabacloud.comKey fields:
| Field | Purpose |
|---|---|
dynamicSubset | Enables dynamic grouping of endpoints based on runtime labels, instead of static subset definitions |
keys | The label key used to group runtimes. Model Service Mesh sets the modelmesh.asm.alibabacloud.com label on each runtime to indicate which models it hosts |
fallbackPolicy: ANY_ENDPOINT | When no subset matches, routes to any available runtime instead of rejecting the request |
Update the VirtualService
Apply the following VirtualService to map the model request header to the dynamic subset key. For more information, see Manage virtual services.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: vs-modelmesh-serving-service
namespace: modelmesh-serving
spec:
gateways:
- grpc-gateway
hosts:
- '*'
http:
- headerToDynamicSubsetKey:
- header: model
key: modelmesh.asm.alibabacloud.com
match:
- port: 8008
name: default
route:
- destination:
host: modelmesh-serving
port:
number: 8033The headerToDynamicSubsetKey field is an ASM extension to the standard Istio VirtualService. When the gateway receives a request with a model: tf-mnist header, it looks up the value against the modelmesh.asm.alibabacloud.com label and routes the request to a runtime in the matching dynamic subset.
(Optional) Step 4: Benchmark inference latency after optimization
Run the same fortio test from Step 2 to compare latency.
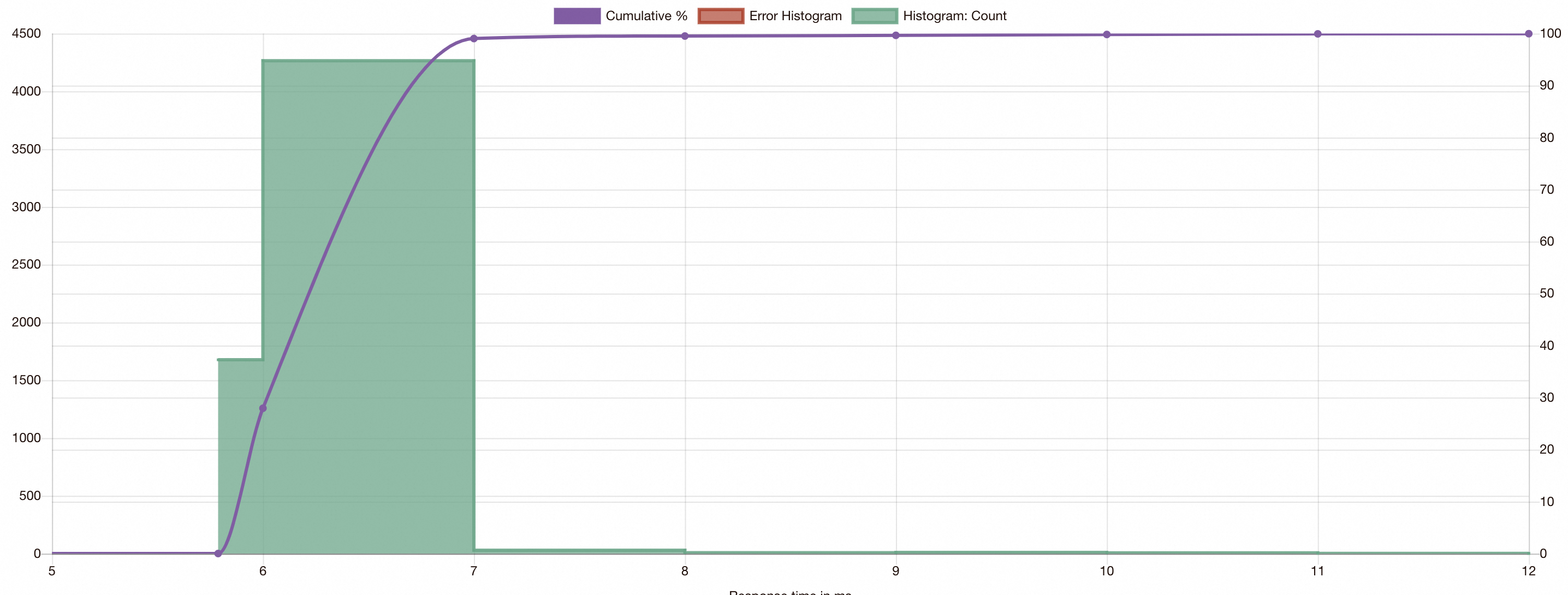
After enabling dynamic subset load balancing, all inference requests route directly to the correct runtime. The latency distribution tightens significantly, with no outliers caused by internal rerouting.