This topic describes how to submit a single-node TensorFlow training job using Arena and monitor training progress with TensorBoard.
Prerequisites
Before you begin, ensure that you have:
-
A GPU-enabled Kubernetes cluster. For details, see Create a Kubernetes cluster that contains GPUs.
-
Cluster nodes with public internet access. For details, see Enable Internet access for a cluster.
-
The Arena client installed and configured. For details, see Configure the Arena client.
-
A Persistent Volume Claim (PVC) named
training-datawith the MNIST dataset stored in thetf_datadirectory. For details, see Configure NAS shared storage.
Background
This example pulls training code from a GitHub repository using git-sync. The MNIST dataset is stored in shared storage backed by NAS (Network Attached Storage), accessed through a PVC named training-data. The dataset is in the tf_data directory inside the PVC.
When you run arena submit tf, Arena creates a TFJob custom resource in your cluster. If you enable TensorBoard, Arena also creates a TensorBoard deployment and service. Understanding these Kubernetes objects helps when you need to debug failed jobs or inspect cluster resources directly.
Step 1: Check GPU availability
Before submitting a job, confirm that GPU resources are available in the cluster:
arena top nodeExpected output:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
0/4 (0.0%)The cluster has two GPU nodes, each with two idle GPUs available.
Step 2: Submit a TensorFlow training job
Submit a single-node, single-GPU TensorFlow training job:
arena submit tf \
--name=tf-mnist \
--working-dir=/root \
--workers=1 \
--gpus=1 \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/tensorflow-mnist-example:2.15.0-gpu \
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=master \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/tf_data/logs \
"python /root/code/arena/examples/tensorflow/mnist/main.py --data /mnt/tf_data/mnist.npz --dir /mnt/tf_data/logs"Expected output:
service/tf-mnist-tensorboard created
deployment.apps/tf-mnist-tensorboard created
tfjob.kubeflow.org/tf-mnist created
INFO[0005] The Job tf-mnist has been submitted successfully
INFO[0005] You can run `arena get tf-mnist --type tfjob -n default` to check the job statusParameters
The command supports the following categories of configuration:
-
Job identity and compute:
--name,--workers,--gpus,--image -
Code synchronization:
--sync-mode,--sync-source,--env -
Data access:
--data -
Monitoring:
--tensorboard,--logdir
| Parameter | Required | Description | Default |
|---|---|---|---|
--name |
Required | The job name. Must be globally unique. | None |
--working-dir |
Optional | The directory where the training command runs. | /root |
--gpus |
Optional | The number of GPUs allocated to each worker node. | 0 |
--image |
Required | The address of the container registry for the training environment. | None |
--sync-mode |
Optional | The code synchronization mode. Valid values: git, rsync. |
None |
--sync-source |
Optional | The repository URL for code synchronization. Use with --sync-mode. The code is cloned to the code/ directory under --working-dir. In this example, the cloned path is /root/code/arena. |
None |
--data |
Optional | Mounts a PVC to the training environment. Format: <pvc-name>:<mount-path>. Run arena data list to see available PVCs in the current cluster. |
None |
--tensorboard |
Optional | Starts a TensorBoard service for the training job. If omitted, TensorBoard is not started. | None |
--logdir |
Optional | The path TensorBoard reads event data from. Use with --tensorboard. |
/training_logs |
To verify that the training-data PVC is available, run arena data list: If no PVC is listed, create one. For details, see Configure NAS shared storage.
NAME ACCESSMODE DESCRIPTION OWNER AGE
training-data ReadWriteMany 35mUse a private Git repository
To pull code from a private repository, set the GIT_SYNC_USERNAME and GIT_SYNC_PASSWORD environment variables:
arena submit tf \
--name=tf-mnist \
--working-dir=/root \
--workers=1 \
--gpus=1 \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/tensorflow-mnist-example:2.15.0-gpu \
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=master \
--env=GIT_SYNC_USERNAME=yourname \
--env=GIT_SYNC_PASSWORD=yourpwd \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/tf_data/logs \
"python /root/code/arena/examples/tensorflow/mnist/main.py --data /mnt/tf_data --dir /mnt/tf_data/logs"Arena uses git-sync internally for code synchronization. All environment variables defined in the git-sync project are supported.
This example pulls source code from GitHub. If the pull fails due to network issues, the demo image already includes the sample code at /code/github.com/kubeflow/arena/examples/tensorflow/mnist/main.py. Submit the job without code synchronization:
arena submit tf \
--name=tf-mnist \
--working-dir=/root \
--workers=1 \
--gpus=1 \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/tensorflow-mnist-example:2.15.0-gpu \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/tf_data/logs \
"python /code/github.com/kubeflow/arena/examples/tensorflow/mnist/main.py --data /mnt/tf_data/mnist.npz --dir /mnt/tf_data/logs"Step 3: Monitor the training job
Use the following commands to track job status and GPU usage after submission.
-
List all Arena-managed jobs:
arena listExpected output:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE tf-mnist RUNNING TFJOB 3s 1 1 192.168.xxx.xxx -
Check GPU usage for the job:
arena top jobExpected output:
NAME STATUS TRAINER AGE GPU(Requested) GPU(Allocated) NODE tf-mnist RUNNING TFJOB 29s 1 1 192.168.xxx.xxx Total Allocated/Requested GPUs of Training Jobs: 1/1 -
Check cluster-level GPU usage:
arena top nodeExpected output:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated) cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 1 cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0 --------------------------------------------------------------------------------------------------- Allocated/Total GPUs In Cluster: 1/4 (25.0%) -
View the job details, including instance status and TensorBoard endpoint:
arena get -n default tf-mnistExpected output:
Name: tf-mnist Status: RUNNING Namespace: default Priority: N/A Trainer: TFJOB Duration: 22s CreateTime: 2026-01-26 16:01:42 EndTime: Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tf-mnist-chief-0 Running 45s true 1 cn-beijing.192.168.xxx.xxx Tensorboard: Your tensorboard will be available on: http://192.168.xxx.xxx:31243NoteThe TensorBoard endpoint is shown only when
--tensorboardis enabled during job submission.
Step 4: View TensorBoard
After the job starts, forward the TensorBoard service port to your local machine and open it in a browser.
-
Map the TensorBoard service to port 9090 on your local machine:
ImportantPort forwarding with
kubectl port-forwardis not suitable for production environments — it is not reliable, secure, or extensible. Use it only for development and debugging. For production-grade networking in ACK clusters, see Ingress management.kubectl port-forward -n default svc/tf-mnist-tensorboard 9090:6006 -
In a browser, go to
http://localhost:9090to view the training metrics.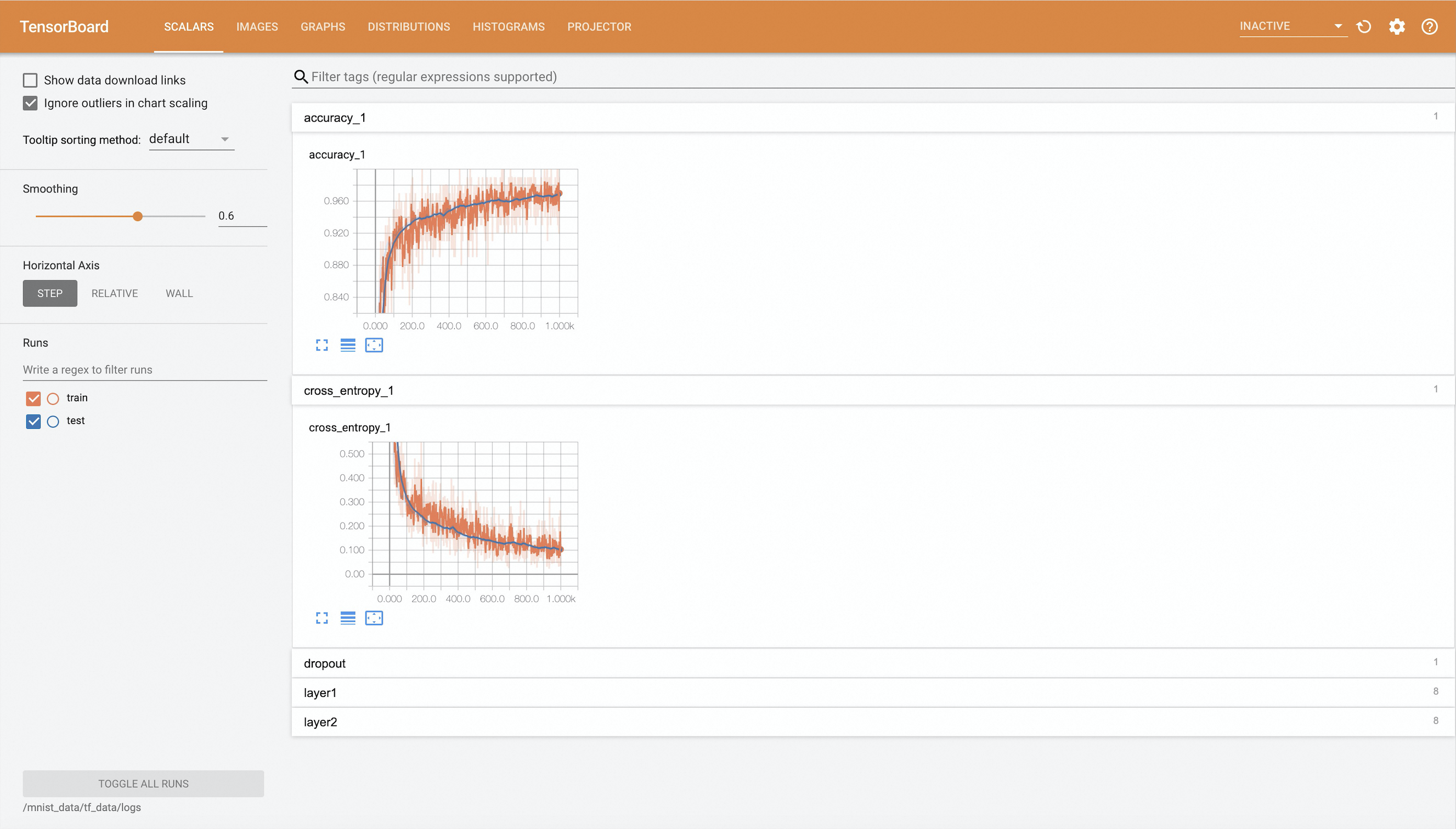
Step 5: View the training job log
View the job log:
arena logs -n default tf-mnistExpected output:
Train Epoch: 14 [55680/60000 (93%)] Loss: 0.029811
Train Epoch: 14 [56320/60000 (94%)] Loss: 0.029721
Train Epoch: 14 [56960/60000 (95%)] Loss: 0.029682
Train Epoch: 14 [57600/60000 (96%)] Loss: 0.029781
Train Epoch: 14 [58240/60000 (97%)] Loss: 0.029708
Train Epoch: 14 [58880/60000 (98%)] Loss: 0.029761
Train Epoch: 14 [59520/60000 (99%)] Loss: 0.029684
Test Accuracy: 9842/10000 (98.42%)
938/938 - 3s - loss: 0.0299 - accuracy: 0.9924 - val_loss: 0.0446 - val_accuracy: 0.9842 - lr: 0.0068 - 3s/epoch - 3ms/step-
Stream logs in real time: add
-f -
Show only the last N lines: add
-t Nor--tail N -
See all options: run
arena logs --help
(Optional) Step 6: Clean up
After the training job completes, delete it to free up cluster resources:
arena delete -n default tf-mnistExpected output:
INFO[0002] The training job tf-mnist has been deleted successfully