The cloud-native AI suite is an ACK solution that provides full-stack infrastructure for building and operating AI and machine learning workloads on Kubernetes. It handles resource management, job scheduling, data acceleration, and lifecycle tooling so your team can focus on model development and training rather than cluster management.
The suite exposes all capabilities through a CLI, multi-language SDKs, and the ACK console, and integrates with Alibaba Cloud AI services, open source frameworks, and third-party AI tools through the same interfaces.
Supported workloads
The cloud-native AI suite supports the following AI/ML workload types:
| Workload | Supported tools |
|---|---|
| Distributed model training | TensorFlow, PyTorch, DeepSpeed, Horovod, Kubeflow |
| Batch (offline) inference | Apache Spark, Apache Flink |
| Real-time inference | vLLM, Triton Inference Server, KServe |
| ML pipeline orchestration | Kubeflow Pipelines, Argo Workflows |
| Interactive model development | Jupyter notebooks, PAI Data Science Workshop (DSW) |
| Self-managed engines | Any custom runtime or framework |
Architecture
Built on Container Service for Kubernetes (ACK), the cloud-native AI suite manages heterogeneous compute, storage, and network resources downward and exposes standard Kubernetes clusters and APIs upward. On top of this base, it provides the scheduling, data orchestration, workflow, and lifecycle components your AI workloads need.

PAI integration. The suite integrates with Platform for AI (PAI) to form a high-performance, elastic AI platform. ACK improves the elasticity and efficiency of the PAI services Data Science Workshop (DSW), Deep Learning Containers (DLC), and Elastic Algorithm Service (EAS). Deploy Lightweight Platform for AI in your ACK cluster with a few clicks to bring PAI's deeply optimized algorithms and engines into containerized workloads and accelerate both training and inference. For more information, see What is PAI?
Key features
| Feature | Description | References |
|---|---|---|
| Heterogeneous resource management | Centrally schedule and manage NVIDIA GPUs, NPUs, FPGAs, VPUs, and RDMA alongside standard ACK resources. Monitor GPU allocation, utilization, and health in multiple dimensions. Enable GPU sharing, GPU memory isolation, and topology-aware GPU scheduling to improve resource utilization. | Overview of ACK clusters for heterogeneous computing, Enable GPU monitoring for an ACK cluster, GPU sharing |
| AI job scheduling | Extend the Kubernetes-native scheduling framework for distributed training jobs. Supported policies include gang scheduling (coscheduling), First In First Out (FIFO) scheduling, capacity scheduling, fair sharing, and bin packing and spread. Configure priority-based job queues and elastic quotas per tenant. Orchestrate complex pipelines with Kubeflow Pipelines or Argo Workflows. | GPU sharing, Scheduling of AI workloads |
| Elastic scheduling | Dynamically scale the number of workers and nodes during distributed deep learning jobs without interrupting training or affecting model precision. Workers are added when idle resources are available and released when resources are scarce, helping avoid node failures, reducing job launch wait time and improving overall cluster utilization. | Kubernetes-based elastic training |
| AI data orchestration and acceleration | Fluid introduces a dataset abstraction over heterogeneous storage backends. ack-fluid ingests data from different storage services and aggregates it into a unified dataset, supporting both on-cloud and on-premises storage in hybrid cloud environments. Per-dataset distributed cache services enable dataset warmup, cache capacity monitoring, and elastic scaling, reducing the overhead of remote data ingestion and improving GPU compute efficiency. | Elastic datasets, Accelerate data access in serverless cloud computing |
| AI job lifecycle management | Arena covers the full production workflow: data management, model development, training, and inference service deployment, while abstracting resource scheduling, environment configuration, and monitoring. Compatible with TensorFlow, PyTorch, and other mainstream AI stacks, with multi-language SDK support. ack-arena is an optimized Arena installation you can deploy to an ACK cluster directly from the console. Visualized dashboards and AI Developer Console let you monitor cluster status and submit training jobs without using the CLI. | Configure the Arena client, Access AI Dashboard, Log on to AI Developer Console |
Use cases
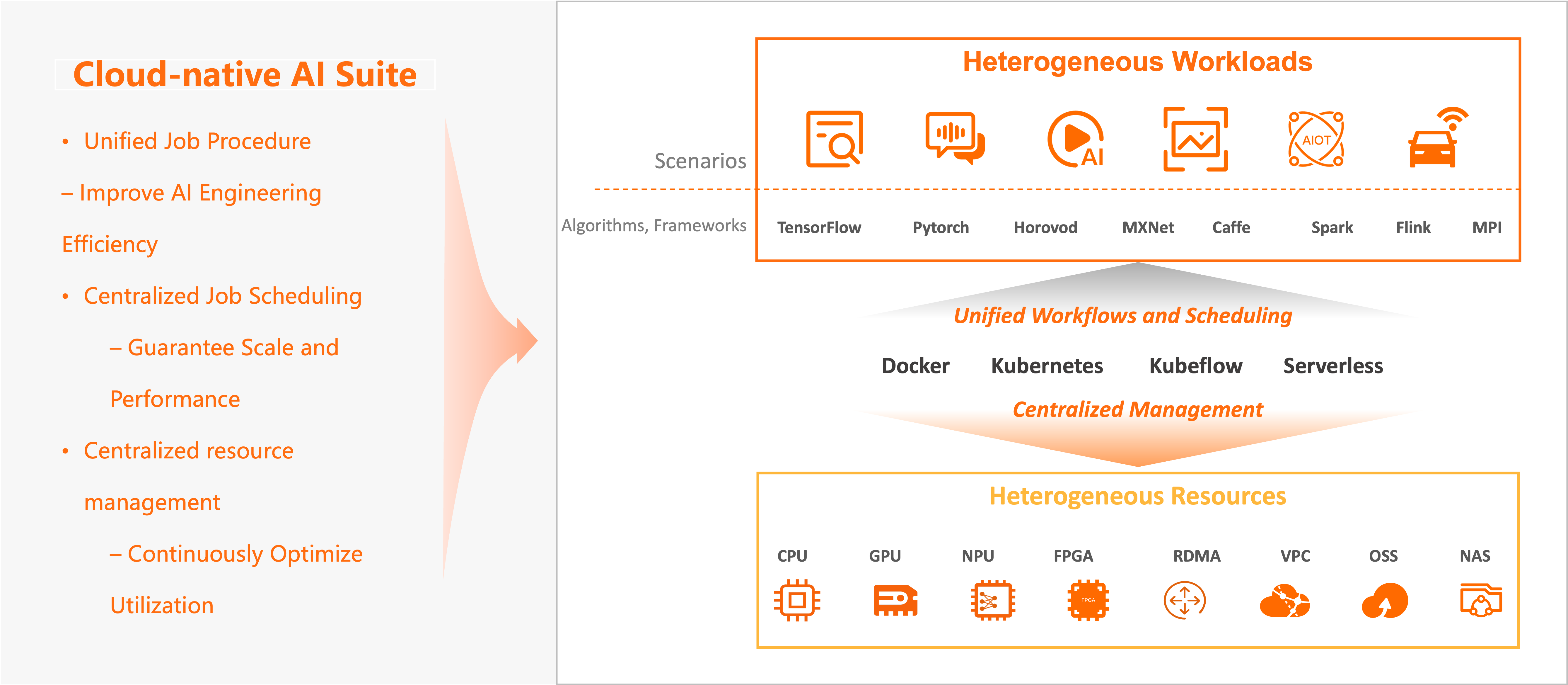
Maximize heterogeneous resource utilization
The suite abstracts all heterogeneous resources in the cloud — compute (CPUs, GPUs, NPUs, VPUs, FPGAs), storage (Object Storage Service (OSS), Apsara File Storage NAS, Cloud Parallel File Storage (CPFS), HDFS), and network (TCP and RDMA) — into a unified management layer. Centralized allocation, scaling, and software/hardware optimization keep utilization continuously high.
Run heterogeneous AI workloads at scale
The suite is compatible with mainstream open source engines including TensorFlow, PyTorch, DeepSpeed, Horovod, Apache Spark, Flink, Kubeflow, KServe, vLLM, and Triton Inference Server, as well as self-managed engines and runtimes. It continuously optimizes training performance, efficiency, and cost while improving the development and operations experience.
User roles
| Role | Responsibilities |
|---|---|
| O&M administrator | Build AI infrastructure and handle daily administration. See Deploy the cloud-native AI suite, Manage users, Manage elastic quota groups, and Manage datasets. |
| Algorithm engineer and data scientist | Develop models, run training jobs, and deploy inference services. See Model training in Kubernetes clusters, Manage models in MLflow Model Registry, and Analyze and optimize models. |
Get started
Follow these steps based on your role.
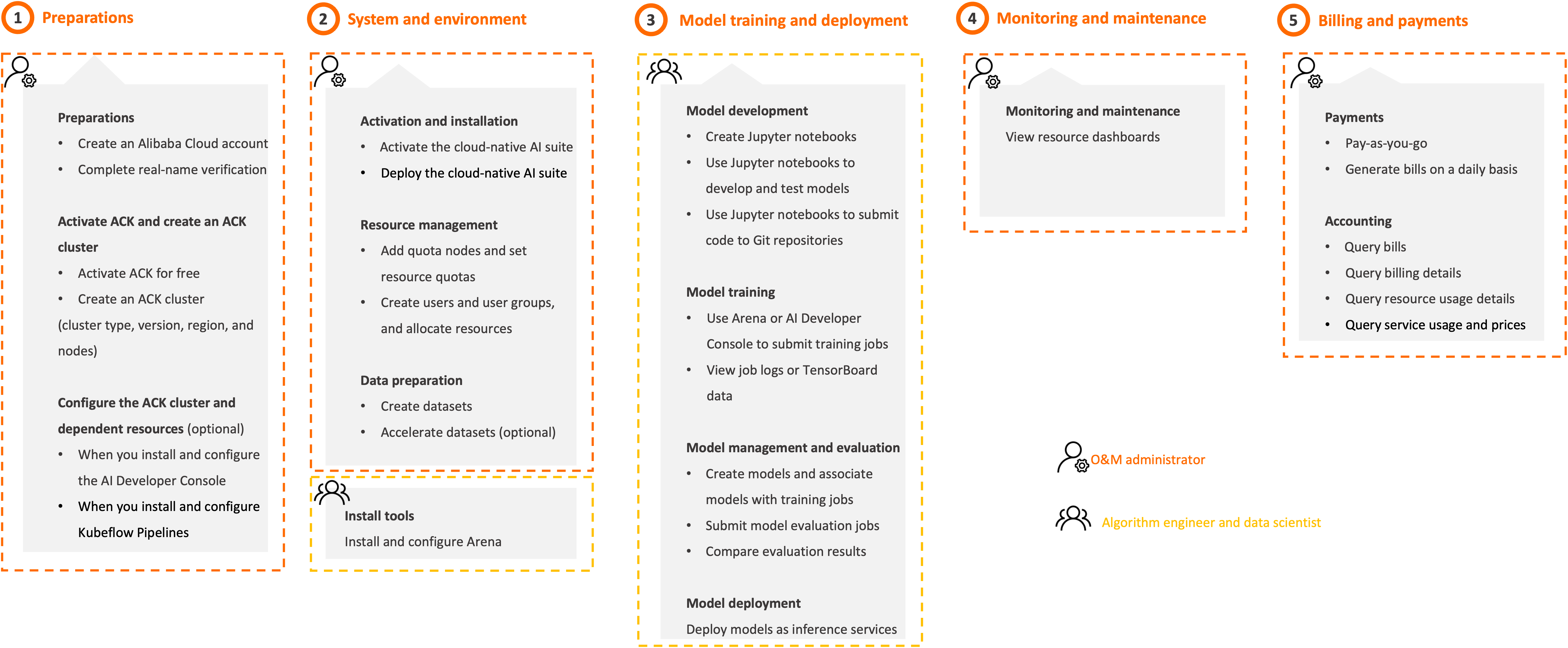
Step 1: Preparations (O&M administrator)
Create an Alibaba Cloud account
Create an Alibaba Cloud account and complete real-name verification. See Create an Alibaba Cloud account. Go to the Alibaba Cloud signup page to get started.Alibaba Cloud account registration page
Create an ACK cluster
Activate ACK and create a cluster with the following configuration. See Create an ACK managed cluster.
Cluster type: ACK Pro cluster, ACK Serverless Pro cluster, or ACK Edge Pro cluster
Kubernetes version: 1.18 or later
Region: the region in which you activated ACK
Go to the ACK consoleACK consoleACK console to create the cluster.
(Optional) Configure cluster dependencies
Configure the following dependencies before deploying the suite components.
AI Dashboard and AI Developer Console
Install the Prometheus agent and Logtail in the cluster.
Create a Resource Access Management (RAM) policy for the cluster. See Authorization.
To access AI Dashboard and AI Developer Console via a domain name, install the NGINX Ingress controller and enable internal or public access.
To use the pre-installed MySQL database as storage, attach Enterprise SSDs (ESSDs) to the cluster nodes.
To use ApsaraDB RDS as storage, purchase an ApsaraDB RDS instance and create a Secret named
kubeai-rdsin thekube-ainamespace.
See Install and configure AI Dashboard and AI Developer Console for the full setup.
Kubeflow Pipelines
To use pre-installed MinIO as storage, attach ESSDs to the cluster nodes.
To use Object Storage Service (OSS) as storage, activate OSS, purchase a bucket, and create a Secret named
kubeai-ossin thekube-ainamespace. See Activate OSS and Install and configure Kubeflow Pipelines.
Step 2: System and environment (O&M administrator)
Activate and install the cloud-native AI suite
Go to the activation page to activate the suite.
Install the suite and its components. See Deploy the cloud-native AI suite and Component introduction and release notes.
Go to the ACK consoleACK consoleACK console to manage the installation.
Manage users and quotas
Add quota nodes and set resource quotas.
Create users and user groups, allocate resources, and associate quota groups. See Manage users, Manage user groups, and Manage elastic quota groups.
Generate a kubeconfig file and a logon token for each new user. See Generate the kubeconfig file and logon token of the newly created user.
Use AI Dashboard and kubectl to complete these tasks.
The AI Console (AI Dashboard and AI Developer Console) was rolled out via whitelist starting January 22, 2025. Existing deployments before that date are unaffected. If your account is not whitelisted, install and configure the AI Console through the open-source community. See Open-source AI Console for instructions.
Prepare data
Create datasets.
(Optional) Accelerate datasets. See Elastic datasets.
Step 3: Model training and deployment (Algorithm engineer and data scientist)
Install the Arena CLI or AI Developer Console to get started. See Configure the Arena client and Install and configure AI Dashboard and AI Developer Console.
The AI Console (AI Dashboard and AI Developer Console) was rolled out via whitelist starting January 22, 2025. Existing deployments before that date are unaffected. If your account is not whitelisted, install and configure the AI Console through the open-source community. See Open-source AI Console for instructions.
Alternatively, use Lightweight Platform for AI.
Develop models
Create and use a Jupyter notebook. See Create and use a Jupyter notebook.
Develop and test the model in the notebook.
Submit code to a Git repository from the notebook.
Train models
Submit a training job using AI Developer Console or Arena.
View job logs or TensorBoard data.
See Model training for details.
Manage models
Create a model and associate it with a training job.
Manage the model using AI Developer Console or the Arena CLI. See Manage models in MLflow Model Registry.
Deploy models
Deploy a model as an inference service. See Deploy AI services.
Use AI Developer Console and Arena for training and deployment tasks.
Step 4: Monitoring and maintenance (O&M administrator)
Use AI Dashboard for all monitoring and management tasks.
Monitor resources
View dashboards for clusters, nodes, training jobs, and resource quotas. See Work with cloud-native AI dashboards.
Manage quotas
Create, query, update, and delete quota groups and their resources. Change resource types as needed. See Manage elastic quota groups.
Manage users
Create, query, update, and delete users and user groups. See Manage users and Manage user groups.
Manage datasets
Create, query, update, and delete datasets and data. Accelerate datasets as needed. See Manage datasets and Elastic datasets.
Manage elastic jobs
View elastic jobs and job details. See View elastic jobs.
Step 5: Billing (O&M administrator)
The cloud-native AI suite has been free of charge since 00:00:00 (UTC+8) on June 6, 2024. See Billing of the cloud-native AI suite for details.
Go to Expenses and Costs to query bills, billing details, resource usage, and service prices.
Billing
The cloud-native AI suite is free of charge. See Billing of the cloud-native AI suite.
Related resources
| Reference | Description |
|---|---|
| Cloud-native AI suite developer guide and Cloud-native AI suite O&M guide | End-to-end practices for development and operations work |
| Release notes | Release notes for the cloud-native AI suite |