This topic helps you troubleshoot and resolve issues with Elastic GPU Service by summarizing common issues encountered when using GPUs.
Category | Related questions |
GPU-accelerated instance | |
GPU card | |
GPU memory | |
GPU driver | |
GPU monitoring | |
Others | How do I install the cGPU service? The nvidia-smi -r command hangs after you install the cGPU service |
GPU-accelerated instances
Do GPU-accelerated instances support Android emulators?
Android emulators can be installed on only some GPU-accelerated instances.
Android emulators are supported only on the following GPU-accelerated compute-optimized ECS Bare Metal Instance families: ebmgn7e, ebmgn7i, ebmgn7, ebmgn6ia, ebmgn6e, ebmgn6v, ebmgn6i.
Can the configuration of a GPU-accelerated instance be changed?
You can change the configuration of only some GPU-accelerated instances.
For more information about the instance types that support configuration changes, see Instance type change restrictions and checks.
Can a standard ECS instance family be upgraded or changed to a GPU-accelerated instance family?
No, you cannot directly upgrade or change a standard ECS instance family to a GPU-accelerated instance family.
For more information about the instance types that support configuration changes, see Instance type change restrictions and checks.
How do I transfer data between a GPU-accelerated instance and a standard ECS instance?
No special settings are required to transfer data.
A GPU-accelerated instance provides the same user experience as a standard ECS instance but with added GPU acceleration. By default, GPU-accelerated instances and ECS instances in the same security group can communicate over the internal network. No special configuration is required.
What is the difference between a GPU and a CPU?
The following table compares GPUs and CPUs.
Comparison | GPU | CPU |
Arithmetic Logic Unit (ALU) | Has many ALUs that excel at handling large-scale concurrent computations. | It has a small number of powerful Arithmetic Logic Units (ALUs). |
Control unit | Has a relatively simple control unit. | Has a complex control unit. |
Cache | Has a small cache that serves threads instead of storing accessed data. | Has large cache structures that can store data to improve access speed and reduce latency. |
Response method | Integrates all tasks before batch processing. | Responds to individual tasks in real-time. |
Scenarios | Suitable for compute-intensive, highly similar, and multi-threaded parallel high-throughput computing scenarios. | Suitable for logically complex serial computing scenarios that require fast response times. |
GPU cards
After I purchase a GPU-accelerated instance, why can't the nvidia-smi command find the GPU card?
Cause: If the nvidia-smi command cannot find the GPU card, it is because the Tesla or GRID driver is not installed or the installation failed on your GPU-accelerated instance.
Solution: To use the high-performance features of your GPU-accelerated instance, you must install the correct driver for your instance type. The following instructions describe how to install the driver:
For a vGPU-accelerated instance, you must install a GRID driver. For more information, see:
For a GPU-accelerated compute-optimized instance, you can install a Tesla or GRID driver. For more information, see:
How do I view the details of a GPU card?
The steps to view GPU card details vary by operating system. The following instructions describe how to view the details:
On Linux, you can run the
nvidia-smicommand to view the GPU card details.On Windows, you can view the GPU card details in .
To view information such as GPU idle rate, usage, temperature, and power, go to the CloudMonitor console. For more information, see GPU monitoring.
A GPU initialization failure (such as RmInitAdapter failed!) occurs when I use a GPU on Linux
Symptoms: The GPU device goes offline, and the system cannot detect the GPU card. For example, when you use a GPU on Linux, a GPU initialization failure error is reported. After you run the
sh nvidia-bug-report.shcommand, you can see theRmInitAdapter failederror message in the generated log, as shown in the following figure:
Cause: The GPU System Processor (GSP) component may be in an abnormal state. This causes the device to go offline and the system to be unable to detect the GPU card.
Solution: Restart the instance from the console. This action performs a complete GPU reset and usually resolves the issue. If the issue persists, see GPU device loss due to XID 119/XID 120 errors when using a GPU for further troubleshooting. We recommend that you disable the GSP feature.
GPU memory
Why does an instance with 48 GB of GPU memory show about 3 GB less in nvidia-smi?
This occurs because the Error-Correcting Code (ECC) feature is enabled. ECC occupies a portion of the GPU memory. For an instance with 48 GB of memory, ECC uses approximately 2 GB to 3 GB. You can run the nvidia-smi command to check the ECC status. `OFF` indicates that ECC is disabled, and `ON` indicates that ECC is enabled.
How do I disable the ECC feature to free up GPU memory?
Command line: Stop all processes that use the GPU. Run
nvidia-smi -e 0to disable ECC. Then, runnvidia-smi -rto reset the GPU.Startup script: Add
nvidia-smi -e 0andnvidia-smi -rto the first line of the/etc/rc.localstartup script. For some systems, the path is/etc/rc.d/rc.local. Then, restart the instance.
What do I do if an error indicating a GPU is in use by another client occurs when I disable ECC?
This error indicates that a component or process is still using the GPU. Make sure no GPU processes are running on the machine. If you cannot stop them manually, create a snapshot backup. Then, add the nvidia-smi -e 0 and nvidia-smi -r commands to the /etc/rc.local startup script. For some systems, the path is /etc/rc.d/rc.local. Restart the instance for the changes to take effect.
GPU drivers
What driver do I need to install for a vGPU-accelerated instance?
vGPU-accelerated instances require a GRID driver.
For general-purpose computing or graphics acceleration scenarios, you can load the GRID driver when you create the GPU-accelerated instance, or install it using Cloud Assistant after creation. The following instructions describe how to install the driver:
Load the GRID driver when you create a new instance. For more information, see Load a GRID driver from an image with a pre-installed driver.
Install the GRID driver using Cloud Assistant after you create the instance. For more information, see:
Can I upgrade CUDA to 12.4 or the NVIDIA driver to 550 or later on a vGPU-accelerated instance?
This is not supported.
vGPU-accelerated instances depend on the platform-provided GRID driver. The driver version is restricted, and you cannot install drivers from the official NVIDIA website. To upgrade, you must use a gn or ebm series GPU-accelerated instance.
What driver do I need to install to use tools such as OpenGL and Direct3D for graphics acceleration on a GPU-accelerated compute-optimized instance?
Install the driver based on the operating system of your GPU-accelerated instance. The following instructions describe how to install the driver:
For a Linux GPU-accelerated compute-optimized instance, install a Tesla driver. For more information, see:
For a Windows GPU-accelerated compute-optimized instance, install a GRID driver. For more information, see:
Why is the CUDA version I see after installation different from the one I selected when creating the GPU-accelerated instance?
The CUDA version returned by the nvidia-smi command shows the highest CUDA version that your GPU-accelerated instance supports. It does not represent the CUDA version you selected when you created the instance.
After I install a GRID driver on a Windows GPU-accelerated instance, what do I do if a black screen appears when I use a VNC connection from the console?
Cause: After you install a GRID driver on a Windows GPU-accelerated instance, the GRID driver takes control of the virtual machine's (VM) display output. VNC can no longer obtain the image from the integrated graphics. This causes a black screen, which is expected behavior.
Solution: Connect to the GPU-accelerated instance using Workbench. For more information, see Connect to a Windows instance using Workbench.
How do I get a GRID License?
The method to obtain a license depends on your operating system. The following instructions describe how to obtain a license:
To install the GRID driver on a GPU-accelerated instance that runs Windows, you can use a pre-installed driver image or install the driver manually.
To install a GRID driver on a Linux GPU-accelerated instance, you can obtain the license from a pre-installed driver image or using Cloud Assistant.
How do I upgrade a GPU driver (Tesla or GRID)?
You cannot directly upgrade a GPU driver (Tesla or GRID). You must first uninstall the old version, restart the system, and then install the new version. For more information, see Upgrade a Tesla or GRID driver.
Upgrade the driver during off-peak hours. Before you upgrade, create a snapshot to back up disk data to prevent data loss. For more information, see Create a snapshot.
A system crash and a kernel NULL pointer dereference error occur after you install NVIDIA driver version 570.124.xx (Linux) or 572.61 (Windows)
Symptoms: On some instance types, the system reports a
kernel NULL pointer dereferenceerror when you install NVIDIA driver version 570.124.xx (Linux) or 572.61 (Windows), or when you run thenvidia-smicommand after the installation. The following log shows the error:Solution: Avoid using driver version 570.124.xx (Linux) or 572.61 (Windows). We recommend that you use version 570.133.20 (Linux) or 572.83 (Windows) or later.
The nvidia-smi command returns a "No devices were found" error if you select NVIDIA Proprietary for the kernel module type during driver installation
Symptoms: On some instance types, if you select NVIDIA Proprietary for the kernel module type during driver installation, the nvidia-smi command returns a
No devices were founderror after the installation.

Cause: Not all GPU models are compatible with the NVIDIA Proprietary driver.
Recommended kernel module type configuration:
For Blackwell architecture GPUs: You must use the open-source driver (select
MIT/GPL).For Turing, Ampere, Ada Lovelace, and Hopper architecture GPUs: We recommend that you use the open-source driver (select
MIT/GPL).For Maxwell, Pascal, and Volta architecture GPUs: You can only select
NVIDIA Proprietary.
GPU monitoring
How do I view the resource usage (vCPU, network traffic, bandwidth, and disk) of a GPU-accelerated instance?
You can use one of the following methods to view monitoring data such as vCPU usage, memory, average system load, internal bandwidth, public bandwidth, network connections, disk usage and reads, GPU usage, GPU memory usage, and GPU power.
Product console
ECS console: This console provides metrics such as vCPU usage, network traffic, disk I/O, and GPU monitoring. For more information, see View monitoring information in the ECS console.
CloudMonitor console: This console provides more fine-grained monitoring, such as infrastructure monitoring, operating system monitoring, GPU monitoring, network monitoring, process monitoring, and disk monitoring. For more information, see Host monitoring.
Expenses and Costs center
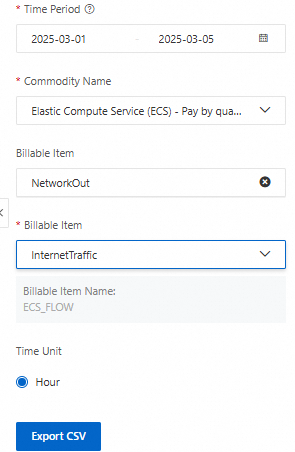
On the View Usage Details page, you can filter by the following fields to view the traffic usage of an ECS instance: Time Period, Commodity Name, Billable Item, Billable Item, and Time Unit. Click Export CSV to export the resource usage information for the instance. For more information, see Billing details.
 Note
NoteThe data in the usage details is the raw resource usage. It is different from the billable usage data in the billing details. The query results are for reference only and cannot be used for reconciliation.
Others
How do I install the cGPU service?
You can install and use the cGPU service through the Docker runtime environment of ACK. This is the recommended method for both enterprise users and individual users who have completed identity verification. For more information, see Manage the shared GPU scheduling component.
The nvidia-smi -r command hangs after you install the cGPU service
Symptoms: In an environment where the cGPU service is loaded (which you can confirm by running the
lsmod | grep cgpucommand), thenvidia-smi -rcommand hangs and cannot be terminated when you try to reset the GPU. An error message also appears in thedmesgsystem log.
Cause: The cGPU component is still using the GPU device. This blocks the hardware reset operation.
Solution:
Uninstall cGPU: Uninstall the cGPU component. After the uninstallation, the
nvidia-smi -rcommand resumes and returns a result.Restart the instance: If the issue persists after the uninstallation, restart the instance from the console. Running the reboot command inside the instance is not effective.
ImportantDo not reset the GPU by running commands such as
nvidia-smi -r, detaching the device, or reinstalling the driver when the cGPU service is loaded. Always uninstall the cGPU service first to prevent failures.