Developers leverage Apache Flink's unified architecture for streaming and batch processing to build robust data applications. When developers choose between streaming and batch modes for a Flink job, a rule of thumb is to assess the latency requirements. Streaming mode is suitable for use cases in which data is generated continuously and requires near-real-time processing, such as real-time log monitoring and online fraud detection. Batch mode is ideal for processing large volumes of historical data when throughput is prioritized over latency, such as offline data analysis and report generation.
It's evident that streaming mode is the preferred choice for time-sensitive applications. However, is batch mode the only option for non-real-time data processing? Recently, the author discovered something fascinating while optimizing a data synchronization job executed in batch mode. The job logic was straightforward but involved multiple shuffle operations. During testing, the author noted that the job finished faster in streaming mode than in batch mode, which indicated that the former achieved higher throughput. Intrigued by this finding, the author further explored the potential advantages of using streaming mode in non-real-time scenarios.
The author's analysis shows that streaming mode can indeed surpass batch mode in terms of throughput if the job logic and data volume meet certain conditions. Streaming mode can also increase resource utilization. This suggests that specific batch jobs could benefit from a switch to streaming mode to enhance efficiency.
The following sections of this blog will delve into the differences between streaming and batch modes across several dimensions. By understanding these distinctions, developers can make informed decisions that best align with their needs.
Batch mode typically provides higher throughput than streaming mode for jobs involving multiple stateful operators, such as Join, Aggregate, and Reduce. This is because batch mode is designed to optimize the efficiency of processing bounded data sets. For example, the Join operator employs more efficient algorithms, such as Hash, Sort-Merge, and Nested-Loop, in batch mode. Additionally, data is sorted by key before being fed into an operator that performs key-based aggregation. This allows the operator to store the state data for each key in its memory, eliminating the need for external storage.
To illustrate this point, the Nexmark benchmark was used to evaluate Apache Flink's performance in streaming and batch modes under identical resource conditions (the TPC-DS benchmark was not used due to resource constraints). Compared with streaming mode, batch mode achieved faster job execution for most queries, with execution period reductions ranging from 17% to 92%, as shown in the following figure.

Notably, batch mode performs slower than streaming mode for query 10 (q10). This can be attributed to an extra sorting step introduced on the Sink node in batch mode, which results in additional CPU resource consumption. Another significant finding from the experiment is that streaming mode is more efficient than batch mode when a job contains only stateless operators, such as Map and Filter, and involves multiple shuffle stages. For example, query 0 (q0) involves only moving original data from the source table to the sink table. In this case, the job was completed approximately 18% faster in batch mode because an operator chain was created and no shuffling took place. However, it's important to note that in real-world scenarios, operator chaining may fail in stateless jobs due to inconsistent operator parallelism or certain job topologies. To illustrate this situation, the operator chain feature was disabled for q0 to introduce shuffling into the job. The following figure shows the job topology.

Under these conditions, tests showed that streaming mode achieved approximately 35% faster job execution than batch mode. When analyzing the following flame graphs to identify performance bottlenecks, the author found that shuffling in batch mode consumed more CPU resources than in stream mode during job execution.

In streaming mode, the data to be shuffled is transmitted through memory. In batch mode, the data is written to disk before shuffling, resulting in extra overhead. Moreover, optimizations that are intended to accelerate operator execution have a limited impact in the case of q0 because the processing logic is simple.
In summary, the design of in-memory shuffling makes streaming mode suitable for jobs involving many stateless operators and shuffling, especially when dealing with large volumes of data. Batch mode is ideal for jobs containing numerous stateful operators because it provides specific optimizations for stateful operators.
Resource Utilization
Streaming mode allows for real-time data transmission between the operators in a pipeline. When a job is run in this mode, all tasks are deployed and executed simultaneously to ensure that data is processed with minimum latency. As a result, the job must acquire all necessary resources upfront and continuously consume the CPU, memory, and network resources of the Flink cluster.
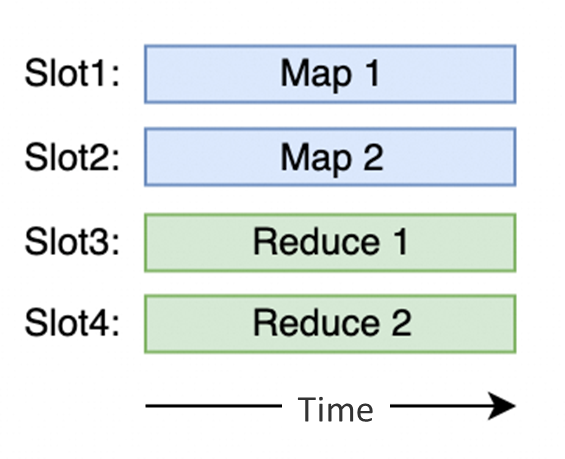
In contrast, batch mode separates tasks into different stages based on data dependencies. Tasks within the same stage can be executed at different times, whereas tasks in different stages are scheduled and executed in sequence. Therefore, a job can be started as long as there are enough resources to run a single task from any stage.

Streaming mode offers significant advantages over batch mode due to its capacity for continuous and stable data processing. In streaming mode, a job begins only when it has been allocated all required resources, and these resources keep stable throughout its execution. Conversely, batch mode processes jobs sequentially in stages, with each stage's duration varying based on resource availability. When resources are plentiful, all tasks in a stage can run simultaneously; however, with limited resources, only some tasks can be executed concurrently, leading to slower overall progress. In contrast, streaming mode guarantees a consistent data processing capacity that is not affected by the total resources available.
The advantage of batch mode over streaming mode lies in its capacity to optimize overall resource utilization within the cluster while minimizing resource wastage. As previously noted, jobs in batch mode have high adaptability to resource allocation; they can start using minimal available resources regardless of whether these resources meet the total requirements. This adaptability enables multiple batch jobs to operate concurrently within a cluster, optimizing resource distribution during both peak and off-peak periods. Conversely, in streaming mode, if the available resources fall short of the total required by a single job, the job cannot start, resulting in an underutilization of the remaining resources.
In conclusion, jobs that require constant and reliable data processing are best suited for streaming mode. This is due to the need for adequate resource allocation before starting the job, allowing it to run independently of resource fluctuations during execution. In contrast, latency-insensitive jobs that aim to maximize the utilization of available resources are ideal for batch mode, as this mode adjusts more flexibly to changes in resource availability.
The streaming mode employs a checkpoint-based snapshot recovery mechanism for fault tolerance. In the event of a failure, all tasks within the job will restore their state from the latest checkpoint and resume processing data from the corresponding consumer offset, eliminating the need to recalculate all historical data.

In batch mode, fault tolerance mainly depends on the task re-run mechanism. When a task fails, its results are discarded, and the task is executed again.
Several factors are taken into account to assess the fault tolerance costs in both streaming and batch modes.
In streaming mode, the job requires additional CPU and memory resources to create checkpoints, which must be stored in external storage services. This entails not only data processing but also increased computational and storage costs. Furthermore, during fault recovery, all tasks must pull checkpoint data. If slow reads happen due to a heavily loaded storage service, the entire recovery process can become time-consuming.
For batch mode, if a fault occurs in a task that requires a long time to complete, the recovery time is increased because the rerun mechanism starts processing from the beginning. On the other hand, if the computing cost of such tasks is high, the rerun mechanism will also consume considerable CPU and memory resources.
In batch mode, when a fault occurs in a long-running task, recovery time is extended since the rerun process starts from the beginning. If the computing cost for these tasks is high, the rerun mechanism will also use significant CPU and memory resources.
In scenarios with smaller state sizes and simpler topologies, streaming mode typically incurs lower fault tolerance costs compared to batch mode. This is due to the relatively low cost of checkpointing in streaming mode, where recovery can begin from the most recent checkpoint. In contrast, batch mode requires rerunning tasks from the start, which extends recovery time. However, in scenarios with large state sizes and complex topologies, streaming mode may entail higher fault tolerance costs than batch mode. This occurs because the volume of checkpoint data in streaming mode is substantial, leading to significant demands on computational resources and storage. Additionally, the recovery process from these checkpoints can be lengthy, potentially outweighing the costs associated with rerunning tasks.
When choosing the execution mode for a Flink job, it's important to thoroughly evaluate the specific needs and characteristics of each scenario rather than strictly adhering to established guidelines. While it is often believed that jobs with high real-time demands are best suited for streaming mode and those that do not require real-time processing are more appropriate for batch mode, a detailed analysis of factors such as the throughput, resource utilization, and fault tolerance costs can lead to more nuanced conclusions:
Suitable job types for streaming mode include: jobs with significant real-time requirements; stateless jobs involving numerous shuffle operations in non-real-time contexts; jobs requiring continuous and stable data processing; and jobs characterized by small state sizes, simple topologies, and low fault tolerance costs.
Suitable job types for streaming mode include: jobs with a large number of stateful operators in non-real-time scenarios; jobs requiring high resource utilization; and jobs characterized by large state sizes, complex topologies, and low fault tolerance costs.
Several factors must be taken in account to choosing the execution mode for Flink jobs. Developers can choose between streaming mode and batch mode based on varying business requirements and specific application scenarios to optimize job execution and resource utilization.
Introducing Fluss: Streaming Storage for Real-Time Analytics
Harnessing Streaming Data for AI-Driven Applications with Apache Flink

207 posts | 58 followers
FollowApache Flink Community - August 14, 2025
Apache Flink Community - April 10, 2025
Kevin Scolaro, MBA - May 16, 2024
Apache Flink Community - August 1, 2025
Neel_Shah - September 17, 2025
Farruh - June 9, 2026
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Big Data Consulting for Data Technology Solution
Big Data Consulting for Data Technology Solution
Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology.
Learn More Big Data Consulting Services for Retail Solution
Big Data Consulting Services for Retail Solution
Alibaba Cloud experts provide retailers with a lightweight and customized big data consulting service to help you assess your big data maturity and plan your big data journey.
Learn More ApsaraDB for HBase
ApsaraDB for HBase
ApsaraDB for HBase is a NoSQL database engine that is highly optimized and 100% compatible with the community edition of HBase.
Learn MoreMore Posts by Apache Flink Community

