Apache Flink has emerged as a leading framework for stream processing, offering two distinct programming interfaces: Flink SQL (declarative) and DataStream API (imperative). This guide helps developers understand their differences, strengths, and ideal use cases through code examples, architectural diagrams, and performance insights.
Flink SQL provides a declarative approach using standard SQL syntax to process both bounded (batch) and unbounded (streaming) data. Key features include:
-- Create a Kafka-backed table
CREATE TABLE user_clicks (
user_id INT,
url STRING,
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'clicks',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
-- Tumbling window aggregation using Window TVF
SELECT
window_start,
window_end,
COUNT(user_id) AS click_count
FROM TABLE(
TUMBLE(
TABLE user_clicks,
DESCRIPTOR(event_time),
INTERVAL '1' MINUTE
)
)
GROUP BY window_start, window_end;Flink SQL treats streams as dynamic tables that evolve over time. This enables SQL operations on unbounded data streams.

Tips: learn more about dynamic table by reading Apache Flink's documentation.
Time attributes like event Time and processing Time are two fundamental concepts in Apache Flink, which are crucial for understanding how stream processing works, especially in scenarios involving real-time data.
Both event time and processing time is used in Flink SQL, for eample:
CREATE TABLE user_actions (
user_id STRING,
action STRING,
event_time TIMESTAMP(3), -- Event time from the data
processing_time AS PROCTIME(), -- Processing time generated by Flink
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND -- Watermark for event time
) WITH (
'connector' = 'kafka',
'topic' = 'user_actions',
'format' = 'json'
); Windowed aggregations are a powerful technique used in data analysis to perform calculations over a defined window of data, often based on time or other criteria. This allows for the computation of metrics such as sums, averages, counts, and more over specific intervals or partitions of the data.
Calculate hourly user activity:
SELECT
window_start,
window_end,
COUNT(DISTINCT user_id) AS active_users
FROM TABLE(
TUMBLE(
TABLE user_actions,
DESCRIPTOR(event_time),
INTERVAL '1' HOUR
)
)
GROUP BY window_start, window_end;Streaming joins in Flink SQL enable real-time correlation of unbounded data streams by leveraging Flink's unified batch/stream processing model. Unlike batch joins that process finite datasets, streaming joins must handle continuous data arrival, out-of-order events, and state management challenges. Below is a structured analysis of key concepts and implementation details:
Flink SQL supports three primary join patterns for streaming data:
| Join Type | Characteristics | State Management | Use Cases |
|---|---|---|---|
| Regular Join | • Continuous updates as new data arrives• Supports all SQL join types (INNER/LEFT/RIGHT/FULL) | Requires unbounded state retention (until TTL expiration) | Real-time dashboard metrics |
| Interval Join | • Joins events within a time range• Use time attributes (processing or event time) | Bounded state (events outside time window discarded) | Fraud detection in 5-min windows |
| Temporal Join | • Joins a stream with a versioned table (e.g., dimension table)• Uses FOR SYSTEM_TIME AS OF syntax |
State tied to temporal table's update frequency | Enriching orders with currency rates |
| Lookup Join | • Enrich stream with external table data• On-demand external system queries | No persistent state (external lookup) | Adding product info from database to orders |
you can enrich clickstream data with user profiles in Flink SQL:
CREATE TABLE user_profiles (
user_id STRING,
country STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydb',
'table-name' = 'users'
);
SELECT
u.user_id,
u.country,
COUNT(c.click_id) AS click_count
FROM clicks c
JOIN user_profiles u
ON c.user_id = u.user_id; The MATCH_RECOGNIZE clause is a powerful SQL feature introduced in 2016 as part of the SQL:2016 standard, designed for pattern recognition within relational data. It allows users to define and detect specific patterns in rows of data, making it particularly useful for complex event processing (CEP) and time-series analysis.
Identify failed login sequences:
SELECT *
FROM login_attempts
MATCH_RECOGNIZE (
PARTITION BY user_id
ORDER BY event_time
MEASURES
START_ROW.event_time AS start_time,
LAST(FAIL.event_time) AS end_time
AFTER MATCH SKIP TO LAST FAIL
PATTERN (START FAIL{3})
DEFINE
FAIL AS action = 'login_failed'
); Flink SQL treats batch processing as a special case of streaming where the input data is bounded. This unified approach enables:a special case of streaming where the input data is bounded. This unified approach enables:
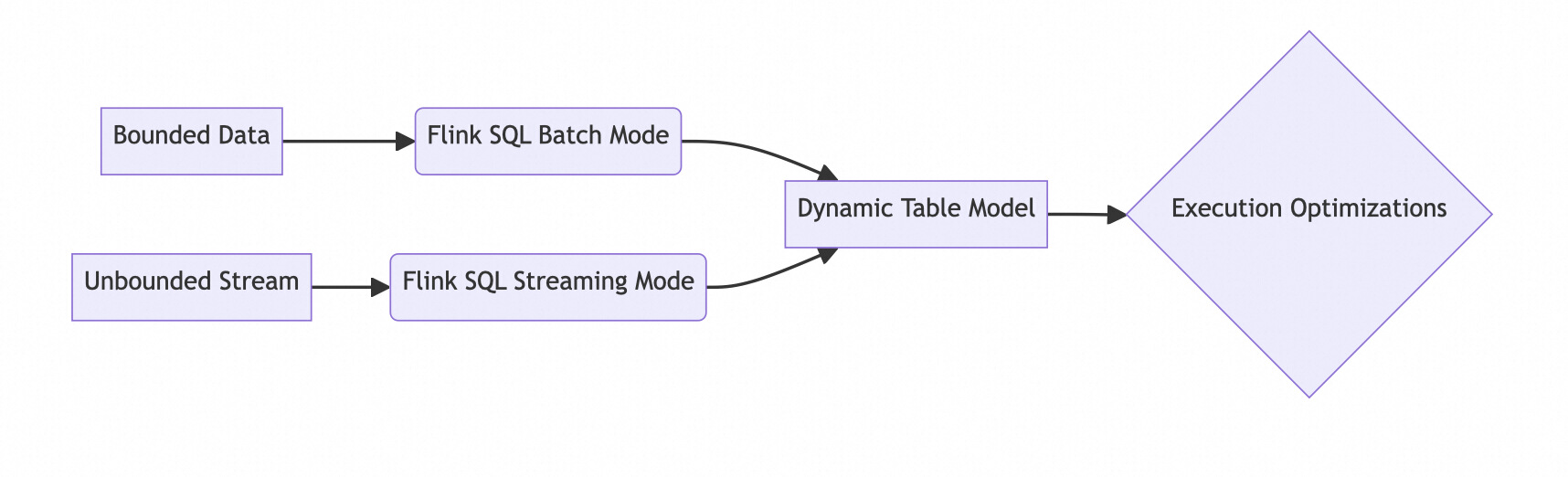
| Aspect | Streaming Mode | Batch Mode |
|---|---|---|
| Time Semantics | Event-time/Processing-time with watermarks | Implicit time (data order irrelevant) |
| ORDER BY Support | Only time-based sorting | Any column sorting |
| Watermarks | Required for event-time processing | Not applicable |
Example Watermark Definition
CREATE TABLE orders (
order_id STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);| Join Type | Streaming Mode | Batch Mode |
|---|---|---|
| Regular Joins | Continuous updates as new data arrives | Single complete computation |
| Temporal Joins | Optimized using time attributes | Not available |
| State Management | Requires continuous state retention | No state during job |
Streaming Join Example
SELECT *
FROM orders
JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currencyEffective streaming joins depend on precise time handling:
Event-Time Joins:
-- Click events table (with watermark)
CREATE TABLE clicks (
user_id STRING,
click_time TIMESTAMP(3),
WATERMARK FOR click_time AS click_time - INTERVAL '30' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'clicks',
'format' = 'json'
);
-- Purchase events table (with watermark)
CREATE TABLE purchases (
user_id STRING,
purchase_time TIMESTAMP(3),
amount DECIMAL(10,2),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '20' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases',
'format' = 'json'
);
-- Event-time interval join query
SELECT
c.user_id,
c.click_time,
p.purchase_time,
p.amount,
TIMESTAMPDIFF(MINUTE, c.click_time, p.purchase_time) AS mins_diff
FROM clicks c
JOIN purchases p
ON c.user_id = p.user_id
AND p.purchase_time
BETWEEN c.click_time - INTERVAL '30' MINUTE
AND c.click_time + INTERVAL '15' MINUTE;MIN(clicks_watermark, purchases_watermark)
30 MINUTE + 15 MINUTE = 45 minutes. Outdated state beyond this interval is automatically cleaned.purchase_time + 15m, corresponding click events will no longer wait for new purchase events, triggering output of final window results.Lookup Joins:
SELECT * FROM A
JOIN B FOR SYSTEM_TIME AS OF A.PROCTIME()
ON A.key = B.keyUses the latest version of dimension tables .
| Use Case | Example |
|---|---|
| Real-time dashboards | Aggregating metrics every 5 seconds |
| ETL pipelines | Cleaning & transforming IoT device data |
| Fraud detection | Pattern matching on transaction streams |
| Customer analytics | Joining clickstream with user profiles |
Apache Flink provides a layered API architecture designed to balance accessibility, flexibility, and performance. Flink SQL sits at the top of this hierarchy but maintains deep interoperability with lower-level APIs like DataStream API and Table API. Below is a detailed analysis of their relationships and integration mechanisms.
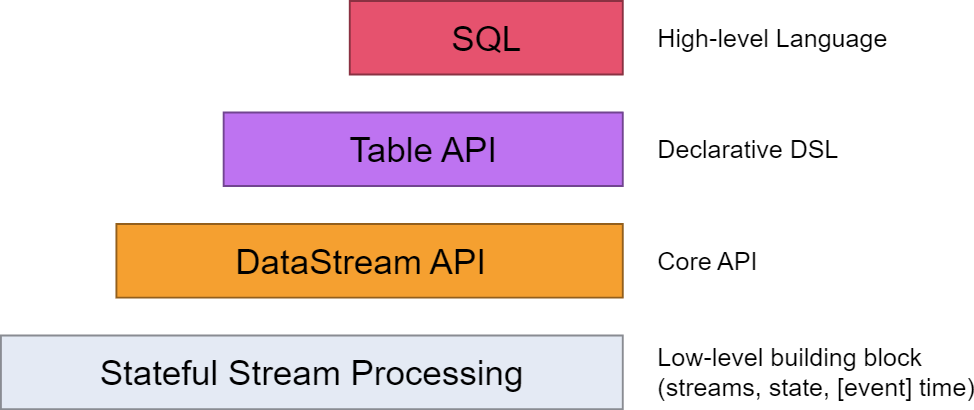
Flink's APIs are structured to address different abstraction levels and use cases:
| API Layer | Key Characteristics |
|---|---|
| Flink SQL | • ANSI SQL-compliant• Declarative syntax for batch/stream unification• Highest abstraction layer (#user-content-15) |
| Table API | • Language-integrated (Java/Scala/Python)• Relational operations (e.g., select, join)• Shares planner with Flink SQL (#user-content-3) |
| DataStream API | • Imperative programming (Java)• Fine-grained control over time, state, and windows• Foundation for stream processing |
The DataStream API offers low-level control over streaming logic, ideal for complex event processing:
DataStream<UserClick> clicks = env
.addSource(new FlinkKafkaConsumer<>("clicks", new JSONDeserializer(), properties));
DataStream<ClickCount> counts = clicks
.keyBy(click -> click.userId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.process(new CountClicksPerWindow());
counts.addSink(new ElasticsearchSink<>());Every DataStream program follows this structure:
// 1. Create execution environment
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. Define data source
DataStream<String> text = env.readTextFile("input.txt");
// 3. Apply transformations
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.keyBy(0)
.sum(1);
// 4. Define output sink
counts.print();
// 5. Execute
env.execute("WordCount"); | Component | Description |
|---|---|
StreamExecutionEnvironment |
Entry point for job configuration |
DataStream |
Immutable distributed data collection |
Transformation |
Operator defining data processing logic |
Sink |
Output system (Kafka, JDBC, files, etc.) |

Purpose: Read data from external systems into Flink.
Key Sources:
Example:
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>(...)); Purpose: Process and manipulate streaming data.
| Transformation | Description |
|---|---|
| Map | 1:1 element transformation (e.g., parsing strings to objects) |
| Filter | Discard unwanted elements (e.g., remove invalid records) |
| KeyBy | Partition data by a key for stateful operations (e.g., group by user ID) |
| Window | Group events into time-based buckets (e.g., 5-minute aggregates) |
| Process | Custom logic via ProcessFunction (e.g., complex event detection) |
Example:
stream
.map(record -> parseRecord(record))
.filter(record -> record.isValid())
.keyBy(record -> record.getUserId())
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.sum("value"); Purpose: Track and update information across events in stateful operations.
| State Type | Use Case |
|---|---|
| ValueState | Single value per key (e.g., user session count) |
| ListState | Append-only list per key (e.g., recent transactions) |
| MapState | Key-value storage per key (e.g., user profile attributes) |
Why It Matters:
Enables stateful computations (e.g., running totals, session tracking)
Automatically fault-tolerant via checkpoints
Purpose: Manage event ordering and out-of-order data.
| Time Concept | Description |
|---|---|
| Event Time | Timestamp embedded in data (e.g., sensor reading time) |
| Processing Time | System time when Flink processes the event |
| Watermarks | Signal event-time progress (e.g., "no events older than X will arrive") |
Example Watermark:
stream.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(10))
.withTimestampAssigner((event, ts) -> event.getTimestamp())
); Purpose: Write processed results to external systems.
| Sink Type | Example Use Case |
|---|---|
| Databases | Write aggregates to PostgreSQL/MySQL |
| Message Queues | Emit alerts to Kafka/Pulsar |
| Filesystems | Store results in HDFS/S3 |
| Dashboards | Stream metrics to Elasticsearch/Grafana |
Example:
stream.addSink(new ElasticsearchSink<>(...)); Purpose: Recover from failures without data loss.
| Mechanism | Description |
|---|---|
| Checkpoints | Periodic snapshots of state (configurable intervals) |
| Savepoints | Manual state snapshots for version upgrades or pipeline changes |
| State Backends | Storage for state (e.g., RocksDB for large state, Memory for speed) |
Configuration:
env.enableCheckpointing(1000); // 1-second checkpoint interval
env.setStateBackend(new RocksDBStateBackend(...)); Flexibility: Mix stateless (e.g., map, filter) and stateful (e.g., window, ProcessFunction) operations.
Precision: Fine-grained control over time, state, and partitioning.
Resilience: Built-in mechanisms to handle failures and late-arriving data.
Scalability: Parallel execution across distributed keys and operators.
For new developers, start with simple pipelines (e.g., Source → Map → Sink) and gradually incorporate stateful operations like keyBy and window as you gain familiarity. The DataStream API's power lies in its ability to combine these building blocks for complex, production-grade streaming logic.
The DataStream API in Apache Flink is particularly advantageous in scenarios where users require fine-grained control over various aspects of stream processing. Here’s a detailed explanation of when to choose the DataStream API based on the provided evidence:
| Scenario | DataStream API Advantage |
|---|---|
| Custom window triggers | Full control over windowing logic |
| Low-level state access | Direct state manipulation |
| Microsecond latency | Bypass SQL optimizer overhead |
| Complex event patterns | Native ProcessFunction support |
Custom Window Triggers:
ProcessFunction to handle events based on specific conditions or time-based logic .Low-Level State Access:
ValueState, ReducingState, and ListState to manage state efficiently .Microsecond Latency:
Complex Event Patterns:
ProcessFunction support. This allows developers to implement sophisticated event-driven logic, such as pattern recognition, anomaly detection, and rule-based alerting. The integration with Flink’s Complex Event Processing (CEP) library further enhances this capability, enabling real-time pattern recognition and processing .Flink SQL offers a higher-level, declarative approach that is easier to learn and use, making it suitable for users who prefer SQL-like syntax and require automatic state management. On the other hand, the DataStream API provides a lower-level, imperative approach that offers full flexibility and control, making it better suited for complex scenarios where custom logic and fine-grained optimization are required.
Below are the summary of the key differences:
| Feature | Flink SQL | DataStream API |
|---|---|---|
| Abstraction Level | High (declarative SQL) | Low (imperative Java/Scala) |
| Learning Curve | Easy for SQL users | Steeper (requires coding skills) |
| State Management | Automatic (managed by Flink) | Manual (developer-controlled) |
| Custom Logic | Limited to UDFs/UDTFs | Full flexibility (custom operators) |
| Performance | Optimized via Calcite planner | Depends on implementation efficiency |
| Use Cases | ETL, real-time analytics | Complex event processing, low-latency |
| Criteria | Flink SQL | DataStream API |
|---|---|---|
| Development speed | ✔️ (Declarative, no coding) | ❌ (Requires Java/Scala expertise) |
| Custom state logic | ✔️ (Enhanced via UDAFs & PTFs) | ✔️ (Full control via KeyedState) |
| BI tool integration | ✔️ (JDBC/ODBC connectors) | ❌ (Requires custom sink development) |
| Latency Profile | ✔️ Sub-second latency (typical 100ms-1s)✔️ Micro-batch optimizations | ✔️ Millisecond-level latency✔️ True event-at-a-time processing✔️ Native low-level optimizations |
Use Flink SQL: For rapid prototyping, standard operations, and ease of development, especially when working with simple data processing tasks like data cleaning, real-time reporting, or data warehousing .
Switch to DataStream API: For advanced state management, complex logic, or scenarios requiring low latency. This is particularly useful when developers need full control over the processing pipeline and can invest the time and effort required for more complex development .
In some cases, a hybrid approach can be beneficial. For example, using Flink SQL for initial data processing and then converting the results to a DataStream for further complex processing can leverage the strengths of both APIs .
The choice between Flink SQL and the DataStream API depends on the specific requirements of the project, including development speed, complexity of state logic, integration with BI tools, and latency requirements. A hybrid approach can also be considered to combine the strengths of both APIs.
numRecordsOutPerSecond) and latency via Flink's REST API.Ready to unlock the full potential of real-time data processing? Dive into Alibaba Cloud's Realtime Compute for Apache Flink and experience the game-changing power of Flink SQL and DataStream API firsthand. Whether you're building complex event-driven applications or performing real-time analytics, our platform offers the tools you need to simplify development and scale effortlessly. Start your journey today with a free trial and see how Alibaba Cloud makes it easy to harness the speed and flexibility of stream processing. Want to learn more? Explore Flink’s comprehensive documentation on Alibaba Cloudto get step-by-step guidance and best practices tailored to your needs. Don’t wait—transform your data processing capabilities now!
Apache Flink FLIP-4: Enhanced Window Evictor for Flexible Data Eviction Before/After Processing

207 posts | 58 followers
FollowApache Flink Community China - March 29, 2021
Alibaba Clouder - December 2, 2020
Data Geek - May 9, 2023
Apache Flink Community - March 31, 2025
Apache Flink Community China - November 8, 2023
Apache Flink Community - May 30, 2025
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Media Solution
Media Solution
An array of powerful multimedia services providing massive cloud storage and efficient content delivery for a smooth and rich user experience.
Learn More ApsaraVideo Media Processing
ApsaraVideo Media Processing
Transcode multimedia data into media files in various resolutions, bitrates, and formats that are suitable for playback on PCs, TVs, and mobile devices.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn MoreMore Posts by Apache Flink Community

