当您在尝试如 Prompt 工程、插件调用等优化方法后,模型表现仍然不及预期时,请使用阿里云百炼的模型调优。模型调优作为改进模型表现的核心策略,可以很好地提升模型在特定行业/业务的表现,对齐人类偏好,降低输出延迟。模型调优包含模型微调(SFT)、继续预训练(CPT)、模型偏好训练(DPO)三种模型训练方式。
模型调优介绍
模型调优作为重要的模型效果优化方式,可以:
提升模型在特定行业/业务表现
降低模型输出延迟
抑制模型幻觉
对齐人类的价值观或偏好
使用调优后的轻量级模型替代规模更大的模型
模型在调优过程中,会学习训练数据中的知识、语气、表达习惯、自我认知等业务/场景特征。也由于已经在训练过程中学习到了大量特定行业/场景的样例,训练后模型 One-Shot 或者 Zero-Shot 的 Prompt 效果会比训练前 Few-Shot 效果更好,这样可以节省大量输入 token,从而降低模型输出延迟。
模型调优流程

详情参见:
支持的模型
计费说明
计费方式 | 按训练的数据量计费 |
计费公式 | 模型训练费用 = (训练数据 Token 总数 + 混合训练数据 Token 总数)× 循环次数 × 训练单价(最小计费单位:1 token) 您可以查看模型调优控制台底部的预估训练费用,并单击计算详情,查看训练 Token 总数、循环次数和训练单价。 |
模型调优前必读
文本生成模型调优虽然能在特定业务/场景取得非常好的效果,但有以下限制:
阿里云百炼推荐您在考虑使用文本生成模型调优前先尝试使用的 Prompt 工程(Prompt Engineering)或插件调用(Function Calling)定制化您的应用,模型调优也通常作为改进模型表现“最后的手段”。因为:
在许多任务中,模型最初可能表现不佳,但通过应用正确的 Prompt 技巧可以改进结果,不一定需要使用模型调优。
迭代优化 Prompt、插件,比模型调优的迭代更敏捷、成本更低,因为模型调优的迭代可能需要重新收集数据、清洗优化数据、收集 bad case、发起客户调研等。
即使最后一定要进行模型调优,最初的 Prompt 工程、插件迭代优化相关工作也不会浪费。您的这些前期工作可以充分地在构建调优数据集时复用(用于构建数据集的输入)。
快速开始
使用控制台进行模型调优
调优步骤 | 控制台截图 |
步骤一:在模型调优页面点击创建训练任务。 |
|
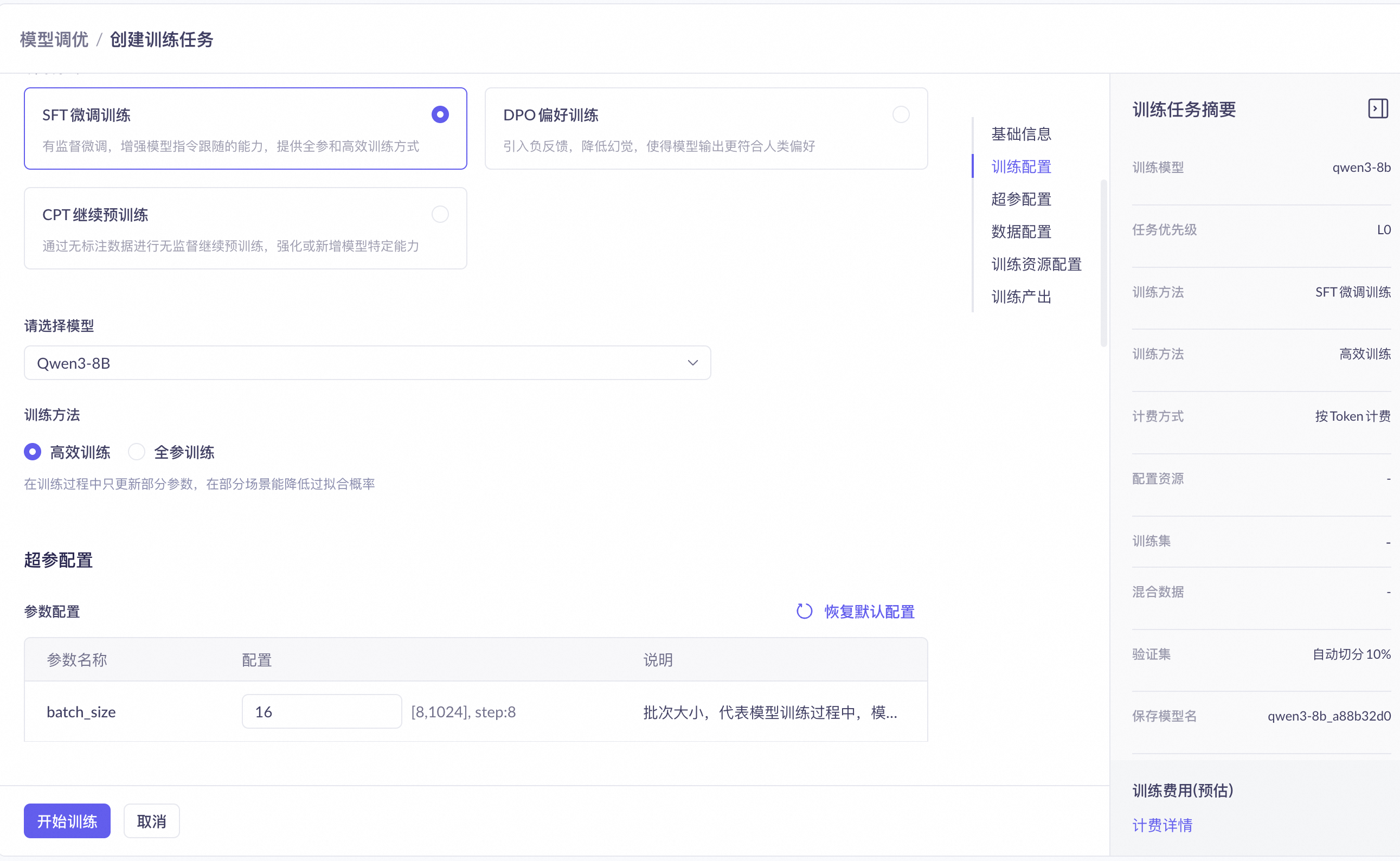
步骤二:训练配置
这个组合训练时间短,数据要求低。 | |
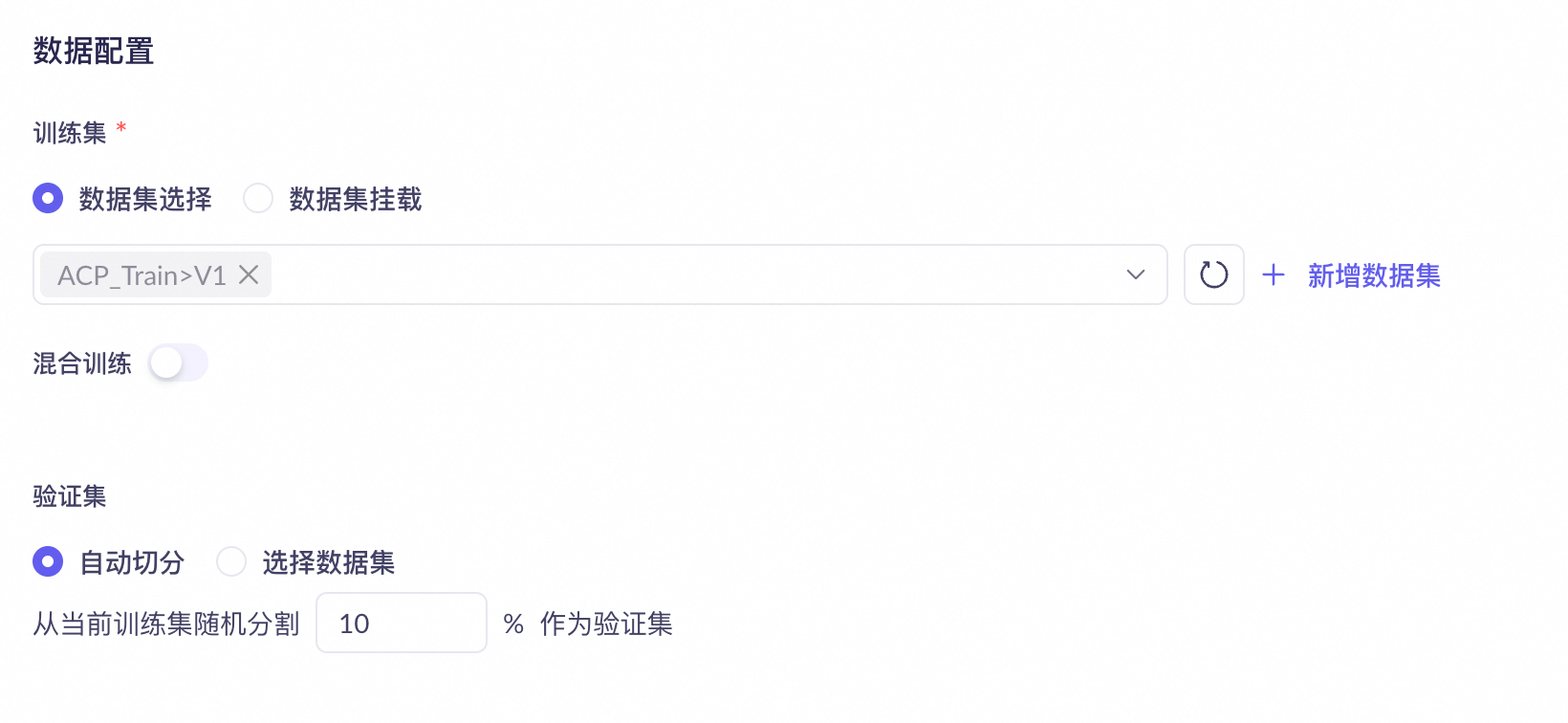
步骤三:数据配置
|
|
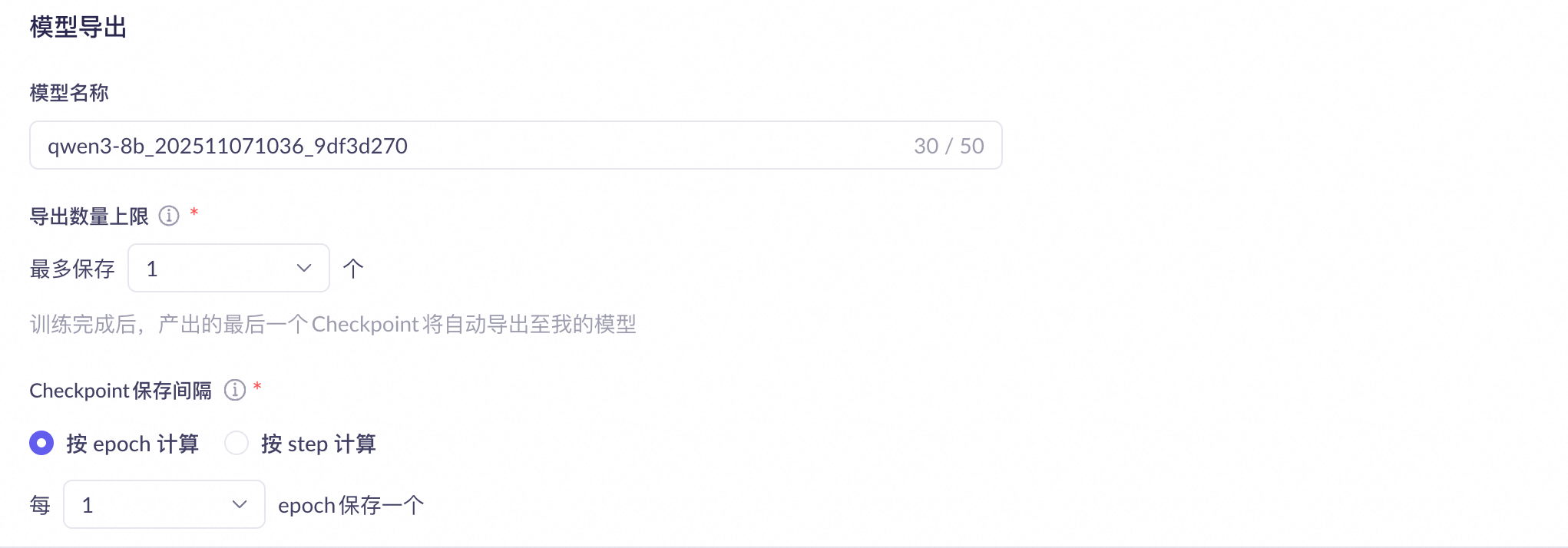
步骤四:配置模型参数快照(Checkpoint)保存参数
说明 在百炼平台上,模型调优完成后可以导出参数快照,导出后才能基于此版本的参数快照在百炼上进行模型部署。 导出的参数快照保存在云存储中,暂不支持访问或下载。 |
|
步骤五:点击“开始训练”后,等待模型训练完毕。 | |
步骤六:使用阿里云百炼的模型部署功能部署训练好的自定义模型,部署好后就可以对调优好的模型进行评测。模型部署相关信息请参见模型部署简介。 | |
典型的调优流程
百炼提供的三种调优方式并不互斥,而是递进的、相辅相成的。
CPT(可选)→ SFT → DPO(可选)
CPT (持续预训练)- 补知识 (通用模型知识的“广度”和“浅度”,无法满足专业领域的“深度”和“精度”要求)
金融模型:
学金融术语医疗模型:
记药品病理法律模型:
懂法条判例
SFT (监督微调)- 学做事
客服机器人:
学客服流程代码助手:
学编程范式工具调用 (Agent):
学使用 MCP
DPO (直接偏好优化)- 做得更好
安全与责任感:
拒有害建议简洁与有效性:
答干脆利落客观与中立:
评公正客观
调优数据格式
SFT 训练集
SFT ChatML(Chat Markup Language)格式训练数据,支持多轮对话和多种角色设置。
不支持OpenAI 的name、weight参数,所有的 assistant 输出都会被训练。
# 一行训练数据(json 格式),展开后典型结构如下:
{"messages": [
{"role": "system", "content": "系统输入1"},
{"role": "user", "content": "用户输入1"},
{"role": "assistant", "content": "期望的模型输出1"},
{"role": "user", "content": "用户输入2"},
{"role": "assistant", "content": "期望的模型输出2"}
...
]}system/user/assistant 区别请参见概述,训练数据集样例:SFT-ChatML格式示例.jsonl、SFT-ChatML格式示例.xlsx(xls、xlsx 格式只支持单轮对话)。
单条训练数据的所有 assistant 行都支持"loss_weight"参数,用于设置该行在训练时的相对重要性。(设置范围0.0 ~ 1.0,数值越大,重要性越高)
该参数属于邀测参数,如需使用,请联系您的商务经理。
{"role": "assistant", "content": "期望的模型输出1", "loss_weight": 1.0},
{"role": "assistant", "content": "期望的模型输出2", "loss_weight": 0.5}数据集构建技巧
数据集的规模要求
对于CPT来说,数据集最少需要五千万Token优质预训练数据;对于 SFT 来说,数据集最少需要上千条优质调优数据;对于 DPO 来说,数据集一般需要上百条人类偏好数据。如果数据调优后的模型评测结果不佳,最简单的改进方法是收集更多数据进行训练。
如果您缺乏数据,建议构建智能体应用,使用知识库索引来增强模型能力。当然在很多复杂的业务场景,可以综合采用模型调优和知识库检索结合的技术方案。
以客服场景为例,可以借助模型调优解决客服回答的语气、表达习惯、自我认知等问题,场景涉及的专业知识可以结合知识库,动态引入到模型上下文中。
阿里云百炼推荐您可以先构建 RAG 应用试运行,在收集到足够的应用数据后再通过模型调优继续提升模型表现。
您也可以采用以下策略扩充数据集:
让大模型模拟生成特定业务/场景的相关内容,辅助您生成更多用于调优数据。(生成模型建议选取表现优异、规模更大的模型)
通过应用场景收集、网络爬虫、社交媒体和在线论坛、公开数据集、合作伙伴与行业资源、用户贡献等各种方式,人工获取更多数据。
数据的多样性与均衡性
模型调优有不同场景,针对具体业务场景时,专业性更重要;而针对问答场景时通用性更重要。您需要根据模型负责的业务模块或使用场景进行数据用例设计。因此训练效果好坏并不是仅取决于数据量,更需要考虑针对场景的专业性和多样性。
这里以智能 AI 对话场景为例,介绍一个专业、多样的数据集应该包含的各种业务场景:
具体业务 | 多样化场景/业务 |
电商客服 | 活动推送、售前咨询、售中引导、售后服务、售后回访、投诉处理等。 |
金融服务 | 贷款咨询、投资理财顾问、信用卡服务、银行账户管理等。 |
在线医疗 | 病症咨询、挂号预约、就诊须知、药品信息查询、健康小建议等。 |
AI 秘书 | IT 信息、行政信息、HR 信息、员工福利解答、公司日历查询等。 |
旅游出行助手 | 旅行规划、出入境指南、旅行保险咨询、目的地风土人情介绍等。 |
企业法律顾问 | 合同审核、知识产权保护、合规性检查、劳动法律答疑、跨境交易咨询、个案法律分析等。 |
还请特别注意的是各个场景/业务的数据数量应相对均衡,数据比例符合实际场景比例,避免某一类数据过多导致模型偏向于学习该类特征,影响模型的泛化能力。
训练集与验证集拆分
当您使用控制台进行模型调优时,支持
自动将一个完整训练数据集拆分,随机抽取少量数据组成验证集。
选择独立上传数据集。
控制台可以在训练时及时方便地显示验证集 Loss 和 Token Accuracy。
常见问题
是否支持调优自己的模型呢?
百炼不支持调优和上传自己的模型,也不支持导出下载后的模型。