本文将详细介绍如何在控制台进行模型调优任务,并帮助您选择正确的调优方式与参数。模型调优包含模型微调(SFT)、继续预训练(CPT)、模型偏好训练(DPO)三种模型训练方式。
模型调优流程

步骤一:选择调优方式
前往模型调优页面,点击“创建训练任务”按钮。
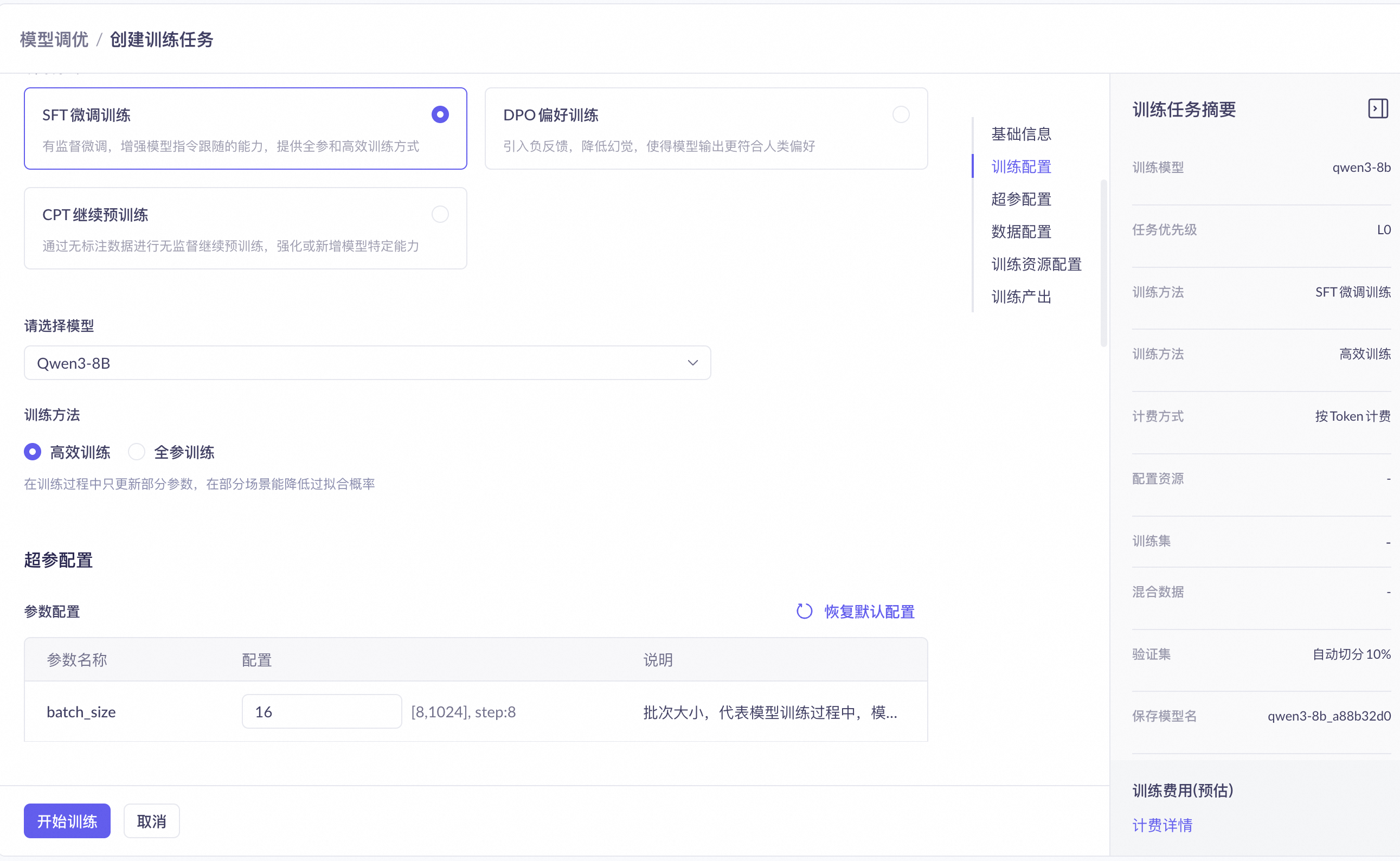
在基础信息区域,可以设置任务名称和任务优先级。任务优先级分为 L0(低)、L1(中低)、L2(中高)、L3(高)四级,影响训练任务的调度顺序。优先级越高,训练任务越早被调度执行。
CPT、SFT、DPO 如何选择
CPT(继续预训练,Continual Pre-Training)目的是通过海量的无标记训练数据,提升模型在特定行业的表现。
SFT-有监督-模型微调(Supervised Fine-Tuning)目的是通过针对性的数据集和训练,提升模型在特定业务的表现。
DPO-有监督-直接偏好优化(Direct Preference Optimization)训练数据集数据同时提供正负样本,通过引入负反馈,降低幻觉,对bad case进行针对性优化。
百炼提供的三种调优方式并不互斥,而是递进的、相辅相成的。
CPT(可选)→ SFT → DPO(可选)
CPT (持续预训练)- 补知识 (通用模型知识的“广度”和“浅度”,无法满足专业领域的“深度”和“精度”要求)
金融模型:
学金融术语医疗模型:
记药品病理法律模型:
懂法条判例
SFT (监督微调)- 学做事
客服机器人:
学客服流程代码助手:
学编程范式工具调用 (Agent):
学使用 MCP
DPO (直接偏好优化)- 做得更好
安全与责任感:
拒有害建议简洁与有效性:
答干脆利落客观与中立:
评公正客观
SFT 训练集
SFT ChatML(Chat Markup Language)格式训练数据,支持多轮对话和多种角色设置。
不支持OpenAI 的name、weight参数,所有的 assistant 输出都会被训练。
# 一行训练数据(json 格式),展开后典型结构如下:
{"messages": [
{"role": "system", "content": "系统输入1"},
{"role": "user", "content": "用户输入1"},
{"role": "assistant", "content": "期望的模型输出1"},
{"role": "user", "content": "用户输入2"},
{"role": "assistant", "content": "期望的模型输出2"}
...
]}system/user/assistant 区别请参见概述,训练数据集样例:SFT-ChatML格式示例.jsonl、SFT-ChatML格式示例.xlsx(xls、xlsx 格式只支持单轮对话)。
单条训练数据的所有 assistant 行都支持"loss_weight"参数,用于设置该行在训练时的相对重要性。(设置范围0.0 ~ 1.0,数值越大,重要性越高)
该参数属于邀测参数,如需使用,请联系您的商务经理。
{"role": "assistant", "content": "期望的模型输出1", "loss_weight": 1.0},
{"role": "assistant", "content": "期望的模型输出2", "loss_weight": 0.5}两种训练方式的数据量要求请参见数据集的规模要求。
阿里云百炼推荐您以先 CPT(可选),后 SFT,再 DPO,最后 RL 的顺序使用模型调优:
先收集海量(至少1000万Token)的特定领域的无标签样本,进行CPT训练,将模型训练成特定行业/领域的专家。
在应用上线前,使用足够多(1000+)的特定场景/业务的正样本,即收集场景/业务输入+模型期望输出,进行SFT 训练。
您的应用试运行/上线后,收集足够多(100+)的用户反馈(如:点赞、点踩、反馈)或者 bad case,将这些数据制作成 DPO 训练集,进行 DPO 训练。
如需进一步提升模型的推理与工具调用能力,可在 SFT/DPO 训练后进行 RL(强化学习)训练。RL 训练通过 DashScope SDK 或 CLI 启动。
模型选择
如果您是第一次进行模型调优,请选择您期望的预置模型。
如果您是因为模型训练效果不好需要再次训练某个模型,请选择自定义模型 > 您需要二次训练的模型。
全参训练与高效训练
全参训练通过全量更新模型参数的方式进行学习。
高效训练采用低秩适应(Low-Rank Adaptation,LoRA)的方式,通过矩阵分解的方法,更新分解后的低秩部分参数。
由于两种训练方式的费用相同,阿里云百炼推荐您如果模型支持全参训练,请优先选择全参训练,因为全参训练效果比高效训练效果要好,性价比更高。
步骤二:参数配置
训练参数介绍:
并不是所有模型都支持所有参数的调节,请以控制台显示为准
参数名称 | 推荐设置 | 超参作用 | |
批次大小 (batch_size) | 使用默认值 | 批次大小,代表模型训练过程中,模型更新模型参数的数据步长,可理解为模型每看多少数据即更新一次模型参数,一般建议的批次大小为16/32,表示模型每看16或32条数据即更新一次参数。取值范围:SFT [32, 8192],DPO [8, 1024],CPT [128, 2048]。 |
|
学习率 (learning_rate) | 高效训练:1e-4量级 全参训练:1e-5量级 CPT训练:1e-5量级 | 控制模型修正权重的强度。 如果学习率设置得太高,模型参数会剧烈变化,导致调优后的模型表现不一定更好,甚至变差; 如果学习率太低,调优后的模型表现不会有太大变化。 | |
循环次数 (n_epochs) | 数据量 < 10,000, 循环 3~5次 数据量 > 10,000, 循环 1~2次 具体需要结合实验效果进行判断 | 模型遍历训练的次数,请根据模型调优实际使用经验进行调整。 模型训练循环次数越多,训练时间越长,训练费用越高。取值范围 [1, 200]。 | |
验证步数 (eval_steps) | 使用默认值 | 训练阶段针对模型的验证间隔步长,用于阶段性评估模型训练准确率、训练损失。 该参数影响模型调优进行时的 Validation Loss 和 Validation Token Accuracy 的显示频率。 | |
学习率调整策略 (lr_scheduler_type) | 推荐选择“linear”或“Inverse_sqrt”。 | 在模型训练中动态调整学习率的策略。 各策略详情请参考学习率调整策略介绍。 | |
序列长度 (max_length) | 设置为模型支持的最大值 | 指的是单条训练数据 token 支持的最大长度。如果单条数据 token 长度超过设定值: SFT 会直接丢弃该条数据,不进行训练; DPO 则会自动截断超出配置长度的后续 token,截短后的数据仍会被训练。 字符与 token 之间的关系请参考 Token和字符串之间怎么换算。取值范围 [500, 32768]。 | |
学习率预热比例 (warmup_ratio) | 使用默认值 | 学习率预热占用总的训练过程的比例。学习率预热是指学习率在训练开始后由一个较小值线性递增至学习率设定值。 该参数主要是限制模型参数在训练初始阶段的变化幅度,从而帮助模型更稳定地进行训练。 比例过大效果与过低的学习率相同,会导致调优后的模型表现不会有太大变化。 比例过小效果与过高的学习率相同,可能导致调优后的模型表现不一定更好,甚至变差。取值范围 [0, 1]。
| |
权重衰减 (weight_decay) | 使用默认值 | L2正则化强度。L2正则化能在一定程度上保持模型的通用能力。数值过大会导致模型调优效果不明显。取值范围 [0, 0.2]。 | |
高效训练参数 | |||
LoRA阿尔法 (lora_alpha) | 使用默认值 | 用于控制原模型权重与LoRA的低秩修正项之间的结合缩放系数。 较大的Alpha值会给予LoRA修正项更多权重,使得模型更加依赖于调优任务的特定信息; 而较小的Alpha值则会让模型更倾向于保留原始预训练模型的知识。 | |
LoRA丢弃率 (lora_dropout) | 使用默认值 | LoRA训练中的低秩矩阵值的丢弃率。 使用推荐数值能增强模型通用化能力。 数值过大会导致模型调优效果不明显。取值范围 [0, 0.2]。 | |
LoRA秩值 (lora_rank) | 设置为模型支持的最大值 | LoRA训练中的低秩矩阵的秩大小。秩越大调优效果会更好一点,但训练会略慢。 | |
是否冻结VIT(freeze_vit) | 使用默认值 | 用于冻结视觉主干网络的参数,使其在训练过程中不更新权重。仅适用于 千问-VL(视觉理解)模型。 警告 只有 freeze_vit 设置为“true”时,模型才能进行按 Token 用量计费。 | |
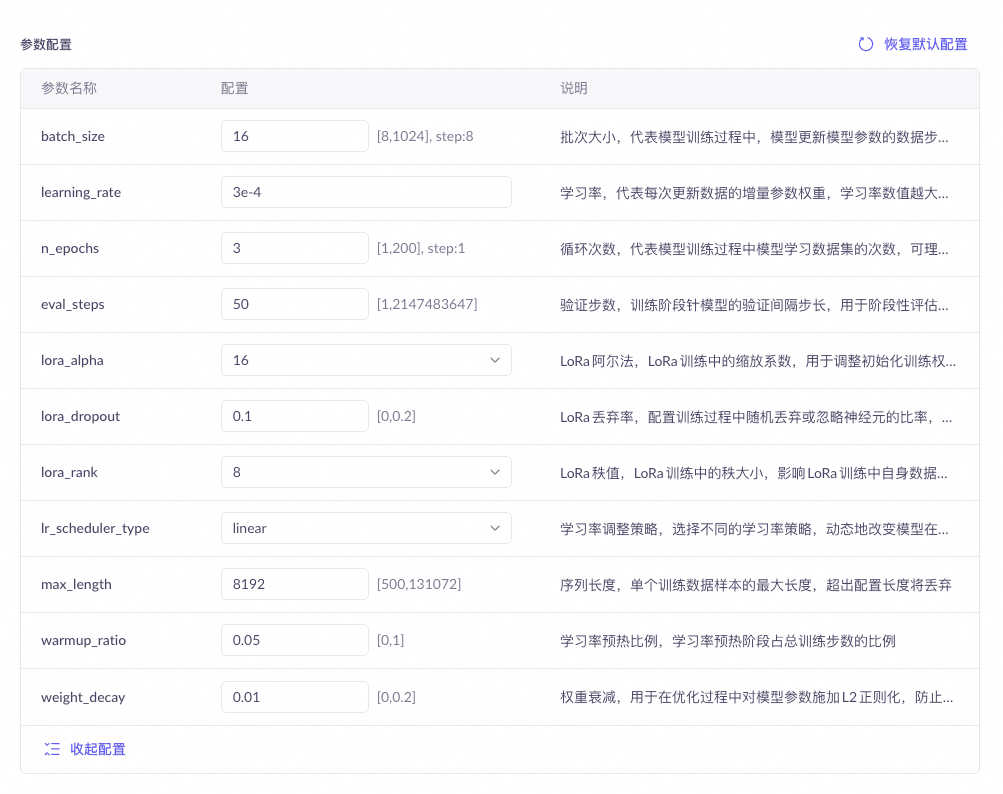
不同训练方式支持的参数有所不同:
SFT(高效训练):支持以上全部参数。
DPO(高效训练):支持除"是否冻结VIT"(freeze_vit)外的全部参数。
CPT(全参训练):仅支持批次大小、学习率、循环次数、验证步数、学习率调整策略、序列长度,不支持 LoRA 相关参数、学习率预热比例和权重衰减。
学习率调整策略介绍
“学习率调整策略” 是在 超参配置 > 更多配置 下的第一个配置,配置包含8种不同的策略。
策略详情请参见:
Linear:学习率线性递减。 使用场景:适合训练过程较短的任务。
| Polynomial:学习率按照一个预定义的多项式函数随训练迭代次数或周期数逐渐减少。 使用场景:Polynomial 可以更精细地控制学习率减少速度,适用于任务比较复杂的场景。 但内置多项式系数为1,效果同 Linear,不推荐使用。
|
Cosine:学习率变化符合余弦函数曲线。 使用场景:适合需要进行精细调整、训练过程较长的任务。 | Cosine_with_restarts:学习率按照余弦函数的形状周期性地减少至某个最小值,而且在每个周期结束时,学习率会“重启”成预设值,然后开启下一周期。 使用场景:适用于需要模型从局部最优解中跳出来,尝试寻找更好全局解的情况。 但经过实测,学习率并不会在函数曲线底部“重启”成预设值,不推荐使用。 |
Constant:学习率不变, “学习率预热比例”参数无效。 使用场景:适合初步探索模型性能。 | Constant_with_warmup:学习率不变,但“学习率预热比例”参数有效。 使用场景:适合初步探索模型性能。 |
Inverse_sqrt:学习率逐渐减小,减小量与迭代次数的平方根的倒数正相关。 使用场景:适合于 SFT 微调,能较好地平衡学习效率与模型收敛。
| reduce_lr_on_plateau:当监控的指标(验证损失或验证准确率)在连续多个epoch内没有显著改进时,自动降低学习率。 使用场景:当模型很难进一步提高性能时,reduce_lr_on_plateau 可以帮助模型继续优化和提升。
|

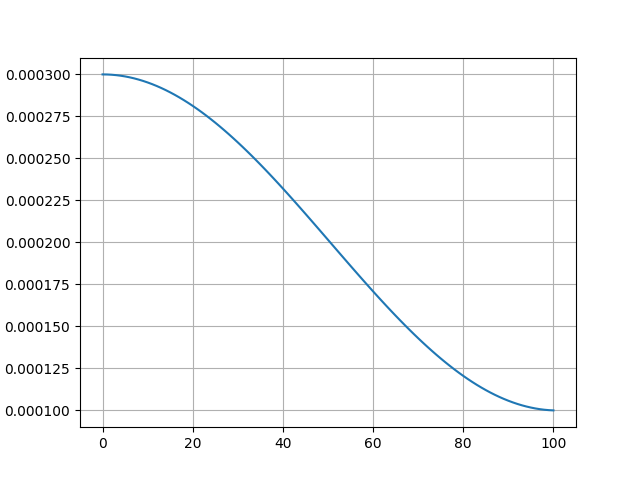

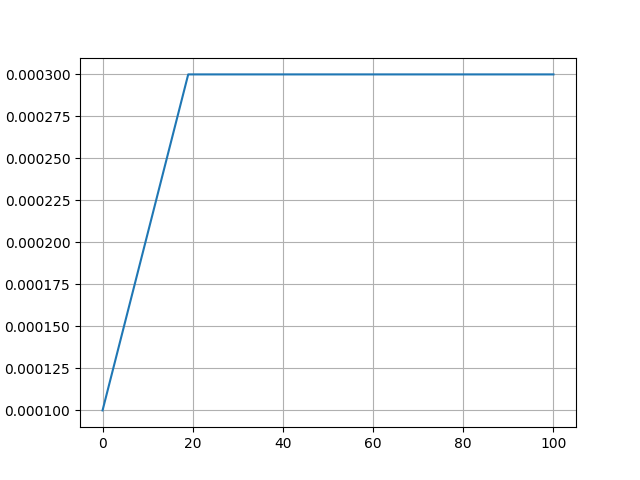

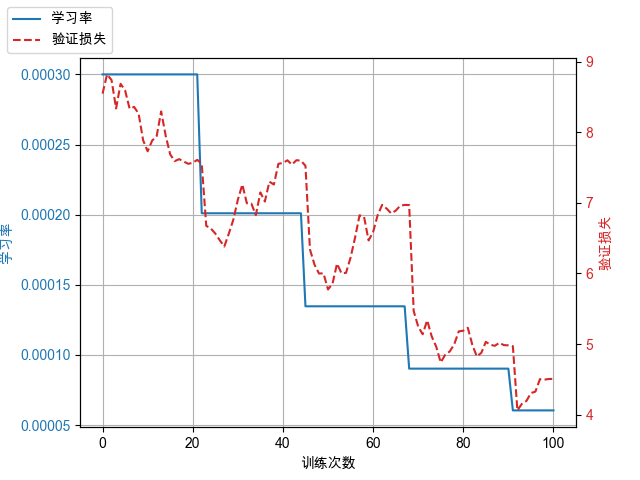
图中学习率下限梯度、最小值均为示意,实际学习率下限梯度、最小值以实际使用为准。
步骤三:选择训练数据
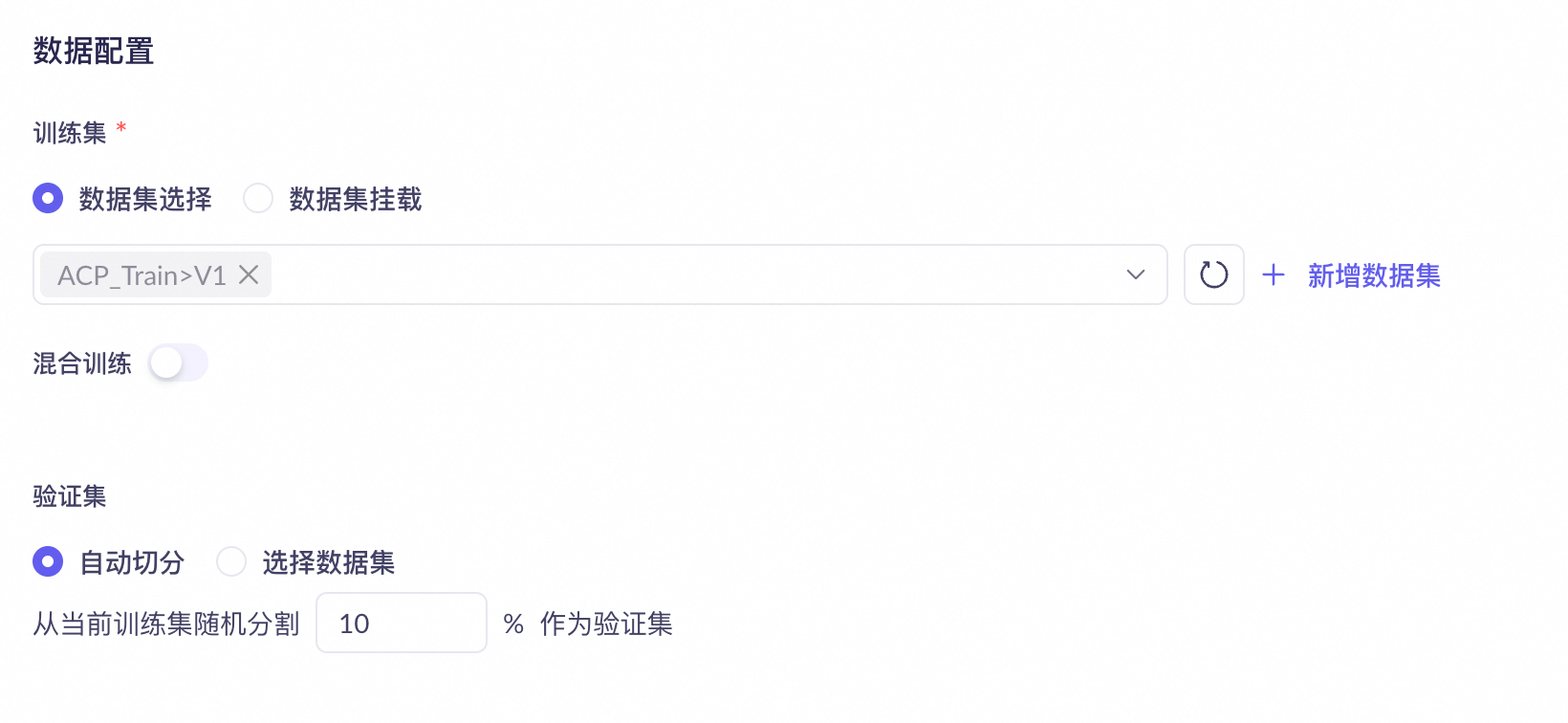
数据集构建技巧请参考数据集构建技巧。上传调优数据集请前往数据管理页面。
在数据配置区域,可以设置以下内容:
训练数据集:选择已上传的调优数据集作为训练数据。
混合训练数据:开启后,可以额外添加混合训练数据集。混合训练数据用于在微调过程中保持模型的通用能力,避免模型因过度适应特定任务数据而丧失原有的通用对话能力。如果您有多个业务场景的数据,建议开启混合训练。
验证集:支持自动切分和独立上传两种方式。选择自动切分时,平台将从训练数据集中随机抽取 10% 的数据作为验证集。您也可以选择独立上传单独的验证数据集。验证集用于在训练过程中评估模型效果,显示验证损失(Validation Loss)和验证准确率(Validation Token Accuracy)。
步骤四:训练资源配置
在训练资源配置区域,选择训练任务的计费方式。平台提供以下三种计费方式:
按 Token 计费:使用平台共享资源,按实际消耗的 Token 数量计费。可能需要排队等待。不支持 RL 训练。
训练单元·预付费:使用已购买的专属训练资源,训练速度更快,无需排队等待。
训练单元·后付费:使用专属训练资源,训练速度更快,无需排队等待,按实际使用时长(小时)计费,无需预先购买。
详细计费说明和价格请参见模型调优简介 - 计费说明。
预付费训练单元管理
选择训练单元·预付费后,可在模型调优页面点击管理训练资源进行训练单元的购买与管理。支持以下操作:
操作 | 说明 |
购买 | 按月购买训练单元实例。同类型训练单元在有效期内只能购买一次,如需增加配额,请使用扩容操作。 |
扩容 | 增加训练单元实例数。 |
缩容 | 减少训练单元实例数,按实际使用时长以小时单价的 1.2 倍计费,剩余费用将退还。缩容后实例数不能少于当前使用中的数量。 |
续费 | 延长训练单元使用时长。 |
退订 | 提前退订训练单元。退订按实际使用时长以小时单价的 1.2 倍计费,剩余预付金额扣除退订费用后退还。 |
步骤五:训练产出
以下配置适用于 SFT、DPO、CPT 训练。
在百炼平台上,模型调优完成后可以导出参数快照,导出后才能基于此版本的参数快照在百炼上进行模型部署。
导出的参数快照保存在云存储中,暂不支持访问或下载。
在模型导出的配置项下,可以设置:
模型名称:设置训练产出模型的名称。训练完成后,产出的最后一个 Checkpoint 将以该名称自动发布至我的模型。
保存模型数量限制:设置最多保留的 Checkpoint 数量。
Checkpoint 保存间隔:设置 Checkpoint 的保存频率,支持按 epoch(训练轮次)或 step(训练步数)保存。
模型加密(安全升级):开启后,平台会为模型文件启用 OSS 服务端加密,使用 OSS 完全托管密钥进行加解密(SSE-OSS),加密算法为 AES256。
步骤六:训练模型
点击“开始训练” > 确认“模型调优计费提醒” > 模型开始训练。
如遇权限不足,请参考:模型调优时报权限不足怎么办?
模型训练时点击”查看日志”按钮可以查询模型训练过程中实时产生的日志,也可以前往指标的标签页查看训练损失(Training Loss)、验证损失(Validation Loss)、验证准确率(Validation Token Accuracy)。
训练完成后,请确认训练损失(Training Loss)与验证损失(Validation Loss)的差异变化趋势。
如果训练损失逐渐减小而验证损失逐渐增大,说明模型已经过拟合训练数据,训练可能失败,训练效果可能不佳。建议按照以下推荐方法(推荐程度有先后顺序)进行优化,重新训练,提升训练效果:
使用数据增强,增加训练数据多样性和数据量。
收集更多训练数据,增加训练数据多样性和数据量。
调整超参,包括:减少“训练次数”、减小“学习率”、减小“批次大小”、增大“权重衰减”、提高“LoRA丢弃率”、提高“学习率预热比例”。
如果训练损失没有明显变化或逐渐增大(不常见),说明模型欠拟合训练数据,训练失败。建议按照以下推荐方法(推荐程度有先后顺序)进行优化,继续训练:
检查数据质量,确保数据清洗充分。
调整超参,包括:增大“训练次数”、增大“学习率”、增大“批次大小”、减小“权重衰减”、降低“LoRA丢弃率”、降低“学习率预热比例”。
如果没有上述情况请继续后续步骤。
步骤七:发布模型用于部署
仅 SFT微调训练支持选择发布训练中间状态的模型快照
模型训练完成后,根据步骤五:训练产出中的配置,产出的最后一个 Checkpoint 会以设定的模型名称自动发布至我的模型页面。
如需发布其他训练中间阶段的 Checkpoint,可以在训练任务详情页的产出标签页中查看所有保存的 Checkpoint 列表,选择目标 Checkpoint 并点击发布模型。
产出标签页中包含以下信息:Checkpoint ID、训练保存信息、模型发布状态、模型名称、剩余保存时长、创建时间、操作。
Checkpoint 有保存时长限制,超过保存时长后将被自动清理,届时将无法再发布该 Checkpoint。请及时发布所需的模型快照。
发布完成后的模型可以在我的模型页面查看,并进行部署。
步骤八:部署模型
前往我的模型页面中快速查询模型支持的部署模式、模型 ID 等相关信息,部署好后就可以对调优好的模型进行评测。模型部署相关信息请参见模型部署简介。
常见问题
什么时候可以使用模型调优功能?
文本生成模型调优虽然能在特定业务/场景取得非常好的效果,但有以下限制:
阿里云百炼推荐您在考虑使用文本生成模型调优前先尝试使用的 Prompt 工程(Prompt Engineering)或插件调用(Function Calling)定制化您的应用,模型调优也通常作为改进模型表现“最后的手段”。因为:
在许多任务中,模型最初可能表现不佳,但通过应用正确的 Prompt 技巧可以改进结果,不一定需要使用模型调优。
迭代优化 Prompt、插件,比模型调优的迭代更敏捷、成本更低,因为模型调优的迭代可能需要重新收集数据、清洗优化数据、收集 bad case、发起客户调研等。
即使最后一定要进行模型调优,最初的 Prompt 工程、插件迭代优化相关工作也不会浪费。您的这些前期工作可以充分地在构建调优数据集时复用(用于构建数据集的输入)。
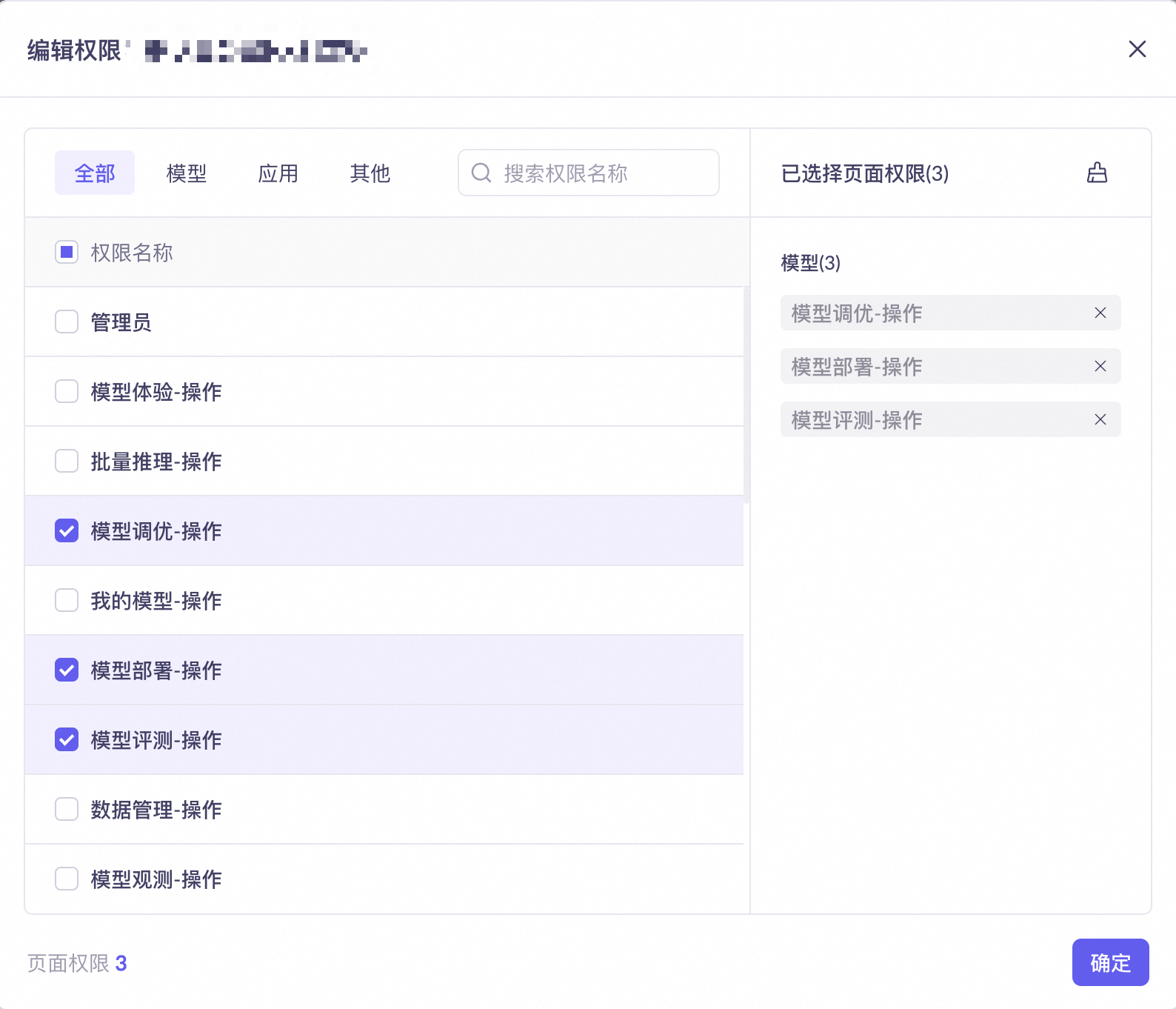
模型调优时报权限不足怎么办?
请联系您的平台或空间管理员,检查并开通以下权限:
账号拥有发起调优任务所在的业务空间下 模型调优-操作、模型部署-操作、模型评测-操作 的页面权限。
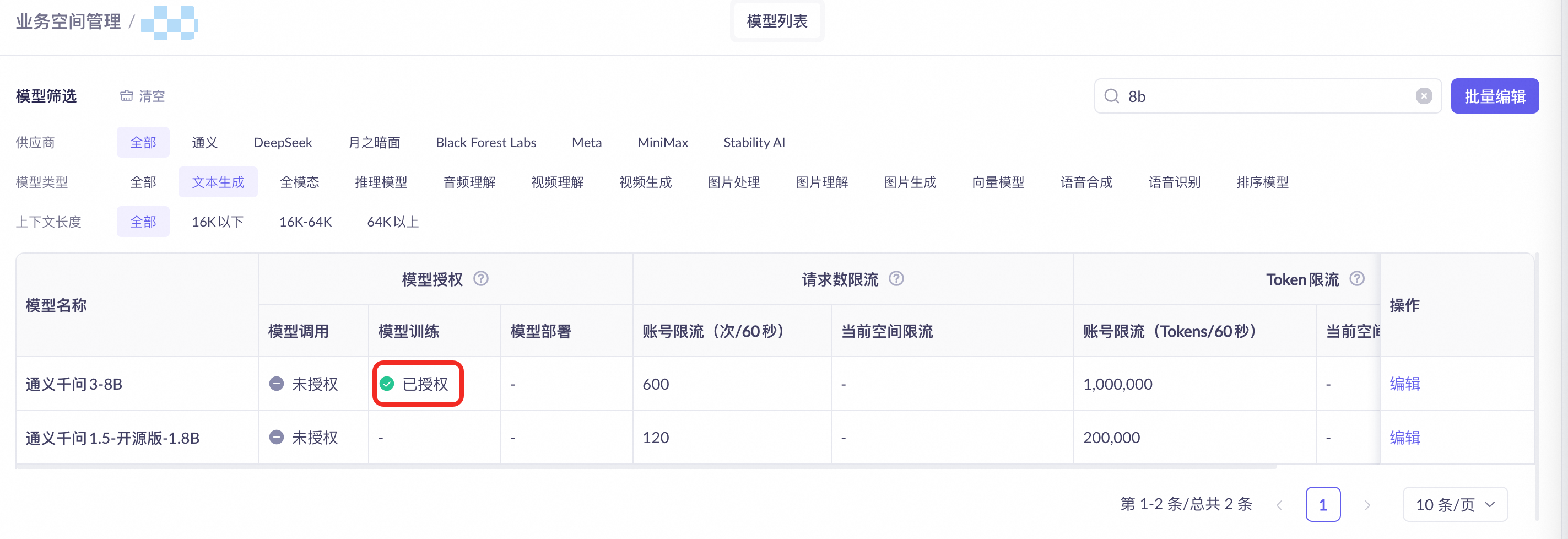
需要发起调优任务所在的业务空间拥有对特定模型进行模型训练(调优)的权限。
相关介绍请参考:授权子业务空间模型调用。控制台链接:百炼-业务空间管理。
如果模型调优后,评测的效果不好怎么办?
如果您使用的是人工评测,请检查评测维度是否符合业务或场景。
收集在模型评测时评测结果不佳的测试用例,统计分析评测结果不佳的原因,根据分析结果调整训练数据集,继续迭代调优模型。
根据评测结果不佳的用例生成 DPO 用例,对模型进行 DPO 训练。
模型调优、模型部署、模型评测怎么收费?
模型调优支持按Token计费和模型训练单元(预付费/后付费)两种计费方式。按Token计费使用平台共享资源,按实际消耗的 Token 数量计费;训练单元使用专属训练资源,训练速度更快。训练好的模型在部署后只收取部署费用,不收取模型的调用费用。模型评测不额外收费。详细数据请参考模型训练与部署计费。
在阿里云百炼调优完成的模型可以下载到本地部署吗?
阿里云百炼平台进行调优的模型不支持导出,只支持在阿里云百炼上部署后测试、调用。
模型调优训练失败,提示训练数据量不足怎么办?
当模型调优训练失败且原因为训练数据量不足时,您可以尝试调整序列长度(max_length)参数来解决。
原因说明
序列长度决定了单条训练数据支持的最大Token长度。在SFT(有监督微调)训练中,超过序列长度的数据会被直接丢弃。如果序列长度设置过大,可能导致大量训练数据因超长被丢弃,实际参与训练的数据量不足,从而导致训练失败。
解决方案
在创建训练任务时,展开参数配置,找到max_length(序列长度)参数。
将序列长度调整为较小的值(如8192),使更多训练数据能够满足长度要求,参与模型训练。
重新提交训练任务。
您可以在模型调优任务列表中,点击训练失败任务右侧的查看日志,查看具体的训练失败原因。