列存索引的目標是提供一個最簡便的方案,以加速業務中複雜耗時的SQL語句。您可以參考快速入門中的內容,以配置叢集的HTAP負載處理能力。此外,您可以參考進階使用中的內容對列存索引進行定製以滿足特定的業務需求。
快速入門
1. 添加列存索引唯讀節點
登入PolarDB控制台,在左側導覽列單擊集群列表,選擇叢集所在地區,找到目的地組群。單擊操作欄中的增删节点,添加列存索引唯讀節點。
2. 配置行列分流方案
您可以根據業務需求選擇行列自動分流或手動分流兩種方式,來使用列存索引。
-
行列自動分流:如果您的業務中,OLTP類型業務與OLAP類型業務是基於同一個應用程式訪問資料庫,則可以通過將兩類業務的讀請求根據預估執行代價(掃描行數)進行自動分流,從而分別路由至列存索引唯讀節點或唯讀行存節點。
-
行列手動分流:如果您的業務中,OLTP類型業務與OLAP類型業務是基於不同應用程式訪問資料庫,則可以為這些應用程式分別配置不同的叢集地址。隨後,將列存索引唯讀節點和唯讀行存節點分別配置到不同叢集地址(Endpoint)的服務節點中,從而實現行存和列存的分流。
行列自動分流
前往叢集詳情頁面,在数据库连接地區,修改集群地址的服務節點選項為開啟。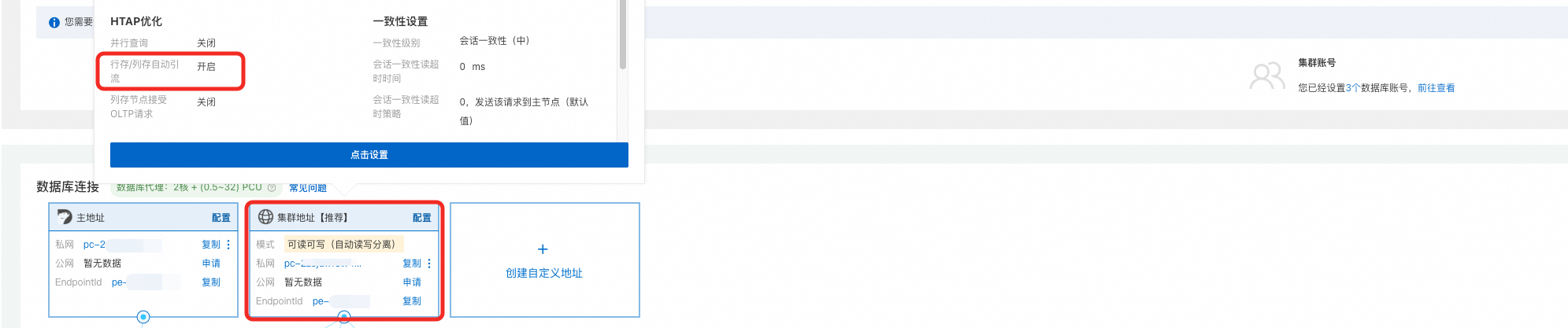
-
調整服務節點選項僅對新串連生效。請在完成調整後,重新串連叢集。
-
若您是使用DMS串連叢集,由於DMS預設使用主地址串連叢集,因此您需要手動修改為使用叢集地址串連PolarDB叢集。
-
行列自動分流的預設預估執行代價(掃描行數)為50000,您可以根據實際業務需求對該參數進行調整。
行列手動分流
前往叢集詳情頁面,在数据库连接地區,建立一個自訂地址,服務節點應僅包含服務節點。
3. 添加列存索引
您可以根據業務需求選擇手動添加或自動添加兩種方式,來為您的業務表添加列存索引。
查詢SQL語句中所涉及的所有列均需被列存索引完全覆蓋,才能使用列存索引實現查詢加速。
手動添加
列存索引為您提供全面的DDL語句,以支援您為業務表添加或刪除列存索引。您可以根據實際需求進行選擇:
|
DDL文法 |
樣本 |
|
|
|
|
|
-
添加列存索引時,您可以保留原有注釋。例如:
ALTER TABLE <table_name> COMMENT 'COLUMNAR=1 <原有注釋>';。 -
預設情況下,庫表級(批量)增加列存索引時,表注釋會修改為
'COLUMNAR=1 <原有注釋>'。
自動添加
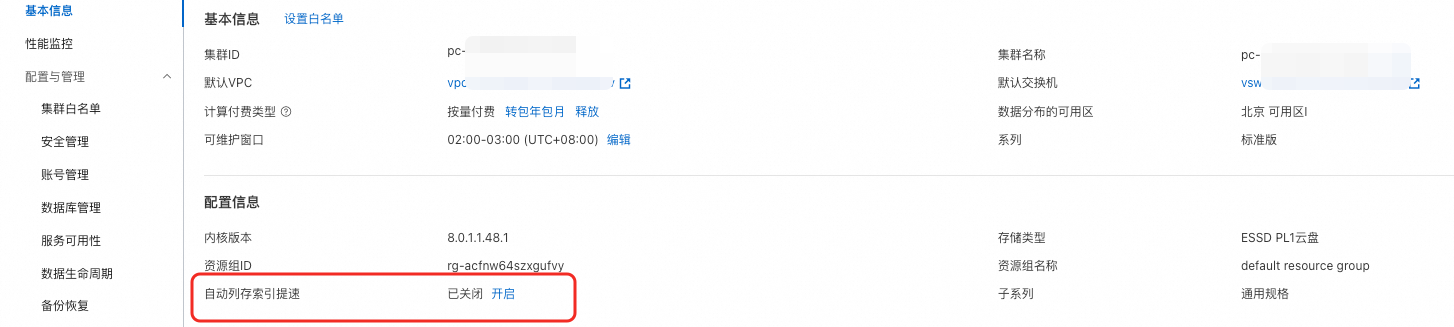
列存索引提供的自動無感提速(AutoIndex)功能,能夠根據您的慢SQL自動建立列存索引,從而顯著提升慢SQL的執行速度,無需您深入理解每一條慢SQL進行調優。隨著應用負載的變化,自動列存索引提速功能會持續監控並調整列存索引策略,以確保PolarDB叢集維持在最佳效能狀態。
您只需在PolarDB叢集詳情頁面,開啟自動列存索引提速功能即可體驗該功能帶來的效果:
(可選)4. 查詢列存索引構建進度
手動添加列存索引後,需要查看列存索引構建的執行進度,等待列存索引構建完成,即可體驗列存索引的查詢加速效果。
SELECT * FROM INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS;樣本如下:通過查看STATUS狀態是否為Safe to read,可以確認列存索引是否已構建完成。
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| SCHEMA_NAME | TABLE_NAME | CREATED_AT | STARTED_AT | FINISHED_AT | STATUS | APPROXIMATE_ROWS | SCANNED_ROWS | SCAN_SECOND | SORT_ROUNDS | SORT_SECOND | BUILD_ROWS | BUILD_SECOND | AVG_SPEED | SPEED_LAST_SECOND | ESTIMATE_SECOND |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| tpch | lineitem | 2024-10-21 13:44:02 | 2024-10-21 13:44:02 | 2024-10-21 13:50:11 | Safe to read | 590446240 | 600037902(100%) | 369 | 0 | 0 | 0(0%) | 0 | 1625058 | 0 | 0 |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
1 row in set, 1 warning (0.00 sec)(可選)5. 檢查SQL語句是否使用列存索引
列存執行計畫以橫向樹的形式輸出,該格式與行存執行計畫的輸出格式存在明顯區別。您可以通過使用Explain查看SQL的執行計畫,來判斷某條SQL語句是否可以使用列存索引加速功能。樣本如下:
列存執行計畫(橫向樹形式)
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| ID | Operator | Name | E-Rows | E-Cost | Extra Info |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| 1 | Select Statement | | | | IMCI Execution Plan (max_dop = 4, max_query_mem = 858993459) |
| 2 | └─Sort | | | | Sort Key: revenue DESC,o_orderdate ASC |
| 3 | └─Hash Groupby | | | | Group Key: (lineitem.L_ORDERKEY, orders.O_ORDERDATE, orders.O_SHIPPRIORITY) |
| 4 | └─Hash Join | | | | Join Cond: orders.O_ORDERKEY = lineitem.L_ORDERKEY |
| 5 | ├─Hash Join | | | | Join Cond: customer.C_CUSTKEY = orders.O_CUSTKEY |
| 6 | │ ├─Table Scan | customer | | | Cond: (C_MKTSEGMENT = "BUILDING") |
| 7 | │ └─Table Scan | orders | | | Cond: (O_ORDERDATE < 03/24/1995) |
| 8 | └─Table Scan | lineitem | | | Cond: (L_SHIPDATE > 03/24/1995) |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
8 rows in set (0.01 sec)行存執行計畫
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| 1 | SIMPLE | customer | NULL | ALL | PRIMARY | NULL | NULL | NULL | 147630 | 10.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | NULL | ref | PRIMARY,ORDERS_FK1 | ORDERS_FK1 | 4 | tpch100g.customer.C_CUSTKEY | 14 | 33.33 | Using where |
| 1 | SIMPLE | lineitem | NULL | ref | PRIMARY | PRIMARY | 4 | tpch100g.orders.O_ORDERKEY | 4 | 33.33 | Using where |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
3 rows in set, 1 warning (0.00 sec)協助工具輔助
在使用列存索引查詢複雜SQL語句時,您需要檢查SQL語句中是否存在未被索引覆蓋的列。如果發現有未被列存索引覆蓋的列,您可以針對該SQL語句擷取建立列存索引的DDL語句,或者針對某個業務批量擷取建立列存索引的DDL語句。執行擷取的DDL語句後,確保SQL語句中的所有列均被列存索引覆蓋,才可使用列存索引進行查詢加速。
PolarDB叢集內建的預存程序如下:
-
檢查SQL語句中是否存在未被索引覆蓋的列預存程序:
dbms_imci.check_columnar_index('<query_string>');。 -
擷取建立列存索引的DDL語句預存程序:
dbms_imci.columnar_advise('<query_string>');和dbms_imci.columnar_advise_by_columns('<query_string>');。 -
批量擷取建立列存索引的DDL語句預存程序:
dbms_imci.columnar_advise_begin();、dbms_imci.columnar_advise_show();和dbms_imci.columnar_advise_end();。
常見問題
更多資訊,請參考列存索引常見問題。
進階使用
您可以參考以下內容來最佳化列存索引的使用。
|
進階功能 |
說明 |
|
列存索引資料群組織的基本單位為行組(Row Group)。在每個行組中,不同的列會各自打包形成列資料區塊,這些列資料區塊按照行存未經處理資料的主鍵順序並行構建,整體上呈現無序狀態。您可以通過設定排序鍵來修改列資料區塊的排列順序,以提高查詢效能。 |
|
|
ETL(Extract Transform Load)功能可以讓您在讀寫(RW)節點上使用列存索引,讀寫(RW)節點上的SQL語句中的 |
|
|
Serverless功能可以根據業務負載進行自動擴縮容。在高峰時段自動升配,有效應對業務負載的突增。在低穀時段自動降配,有效降低使用成本。 |
|
|
Hybrid Plan是指在同一條查詢語句中同時使用列式索引和行式索引的查詢方式。Hybrid Plan能夠顯著提高寬表查詢的速度。在執行計畫中,對於適合使用列式索引的部分,將通過列存索引進行執行並擷取中間結果,該中間結果僅包含主鍵資訊。最後,通過主鍵結合InnoDB主索引來查詢需要的所有列資訊並進行輸出。 |
|
|
對于海量資料的複雜查詢,單個列存索引唯讀節點已無法滿足效能需求。您可以使用多機並行的方式進行查詢加速。 |
深入瞭解
如果您對列存索引的原理感興趣,您可以參考以下文檔以深入瞭解列存索引:
-
PolarDB 列存索引(IMCI)發表在