本文介紹了列存索引的技術背景、簡介以及技術架構等內容。
技術背景
MySQL生態HTAP資料庫解決方案
MySQL是一款主要面向OLTP型情境設計的開來源資料庫,開源社區的研發方向側重於加強其交易處理能力。如提升單核效能、多核擴充性和增強叢集能力,以提升可用性等。在處理巨量資料量下複雜查詢所需要的能力方面,如最佳化器處理子查詢的能力、高效能運算元HashJoin、SQL並存執行能力等,MySQL社區一直將其放在比較低優先順序上,因此,MySQL的資料分析能力提升進展緩慢。
隨著MySQL發展為世界上最為流行的開來源資料庫系統,使用者在其中儲存了大量的資料,並且運行著關鍵的商務邏輯,對這些資料進行即時分析成為一個日益增長的需求。當單機MySQL不能滿足需求時,使用者尋求一個更好的解決方案。如MySQL+專用AP資料庫的搭積木方案、基於多副本的Divergent Design方法以及一體化的行列混合儲存方案等。
MySQL+專用AP資料庫的搭積木方案
該方案由兩套系統來分別滿足OLTP和OLAP型需求,在兩套系統中間通過資料同步工具進行資料的即時同步。使用者甚至可以增加一層Proxy,自動將TP型負載路由到MySQL上,將分析性負載路由到OLAP資料庫上,對應用程式層屏蔽底層資料庫的部署拓撲。架構圖如下: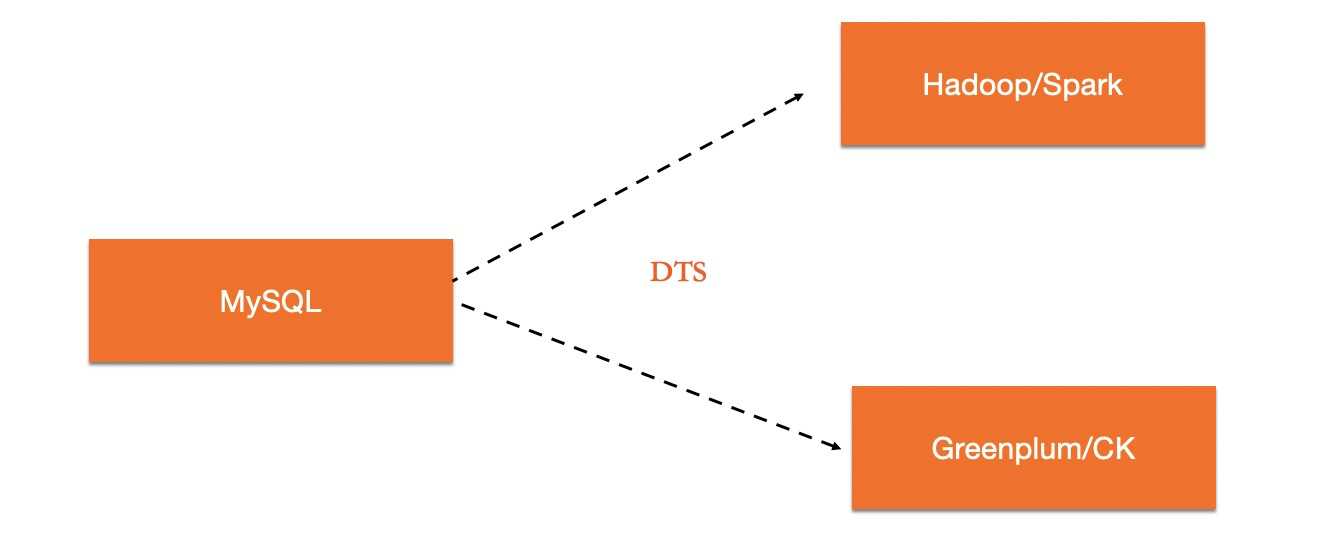
該架構有其靈活之處。如對於TP資料庫和AP資料庫都可以各自選擇最好的方案,而且實現了TP/AP負載的完全隔離。但是其缺點也是顯而易見的。首先,在技術上需要維護兩套不同技術體系的資料庫系統,其次由於兩套系統處理機制的差異,維護上下遊的資料即時一致性也非常具有挑戰性。而且存在資料同步延遲,下遊AP系統儲存的經常是過時的資料,從而導致無法滿足即時分析的需求。
基於多副本的Divergent Design方法
隨著互連網而興起的新興資料庫產品很多都相容了MySQL協議,這些分散式資料庫產品大部分採用了分布式Share Nothing方案,其一個核心特點是使用分布式一致性協議來保障單個partition多副本之間的資料一致性。由於一份資料在多個副本之間完全獨立,因此在不同副本上使用不同格式進行儲存,來服務不同的查詢負載是一個易於實施的方案。典型的如TiDB,其從TiDB4.0開始,位於一個Raft Group中的其中一個副本上,使用列式儲存(TiFlash)來響應AP型負載,並通過TiDB的智能路由功能來自動選取資料來源。實現了一套資料庫系統同時服務OLTP型負載和OLAP型負載。
該方法在諸多Research及Industry領域的工作中都被借鑒並使用,並日益成為分布式資料領域一體化HTAP的事實標準方案。 但應用這個方案的前提是使用者需要將資料移轉到對應的NewSQL資料庫系統中,而這往往會帶來各種相容性問題。
一體化的行列混合儲存方案
比多副本的Divergent Design方法更進一步的方案,即在同一個資料庫執行個體中採用行列混合儲存的方案,同時響應TP型和AP型負載。這是傳統商用資料庫Oracle、SQL Server和DB2等不約而同採用的方案。
Oracle公司在2013年發表的Oracle 12C上,發布了Database In-Memory套件,其最核心的功能為In-Memory Column Store,即通過行列混合儲存/進階查詢最佳化(物化運算式,JoinGroup)等技術來提升OLAP效能。
微軟在SQL Server 2016 SP1上,開始提供Column Store Indexs功能,使用者可以根據負載特徵,靈活的使用純行存表、純列存表、行列混合表以及列存表+行存索引等多種模式。
IBM在2013年發布的10.5版本(Kepler)中,增加了DB2 BLU Acceleration組件,通過列式資料存放區配合記憶體計算以及DataSkipping技術,大幅提升分析情境的效能。
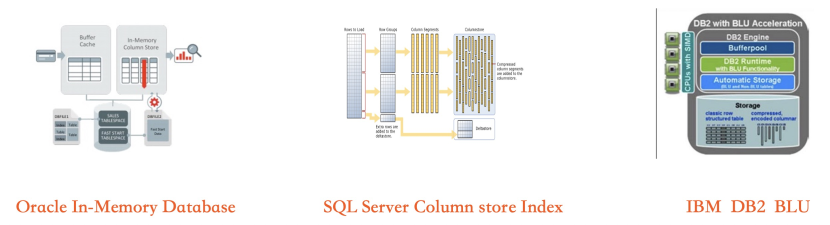
三家領先的商用資料庫廠商,均同時採用了行列混合儲存結合記憶體計算的技術路線。列式儲存由於有更好的IO效率(壓縮、DataSkipping、列裁剪)以及CPU計算效率(Cache Friendly),因此要達到最極致的分析效能必須使用列式儲存,而列式儲存中由於索引稀疏導致索引精準度問題決定了它不可能成為TP情境的儲存格式。因此,行列混合儲存成為一個必選方案。但在行列混合儲存架構中,行存索引和列存索引在隨機更新資料時存在效能鴻溝,必須藉助DRAM的低讀寫延時來彌補列式儲存更新效率低的缺陷。因此,在低延時線上交易處理和高效能即時資料分析兩大前提下,行列混合儲存結合記憶體計算成為最優方案。
對比上述三種方案,從組合搭積木的方案到Divergent Design方法,再到一體化的行列混合儲存方案。其整合度越來越高,使用者的使用體驗也越來越好。但是其對核心工程實現上的挑戰也越來越大。而基礎軟體的作用就是將複雜留給自己,將簡單留給使用者。因此,一體化的行列混合儲存方案更為符合技術發展趨勢。
PolarDB MySQL AP能力的演化
PolarDB MySQL版能力棧與開源MySQL類似,長於TP但AP能力較弱。由於PolarDB提供了單個叢集最大500 TB的儲存能力,同時其交易處理能力遠超使用者自建MySQL。因此,PolarDB使用者傾向於在單個叢集上儲存更多的資料,同時會在這些資料上進行一些複雜的彙總查詢。藉助於PolarDB一寫多讀架構,使用者可以根據實際需求增加多個RO節點以運行複雜查詢,從而避免分析型查詢對TP負載的幹擾。
MySQL架構在AP情境的缺陷
PolarDB並行查詢突破CPU瓶頸
並行查詢方塊架(Parallel Query)可以在查詢資料量到達一定閾值時,自動啟動並存執行。在儲存層將資料分區到不同的線程上,由多個線程並行計算,並將結果流水線匯總到匯流排程。最後,匯流排程做簡單歸併返回給使用者,以提高查詢效率。 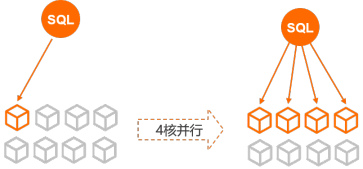
並行查詢突破了單核執行效能的限制,利用多核CPU的平行處理能力,使得部分SQL查詢耗時成指數級下降。
PolarDB列式儲存
並存執行架構突破了CPU擴充能力的限制,帶來了顯著的效能提升。然而,受限於行式儲存及行式執行器的效率限制,單核執行效能存在天花板,其峰值效能依然與專用的OLAP系統存在差距。要更進一步的提升分析效能,則需要引入列式儲存:
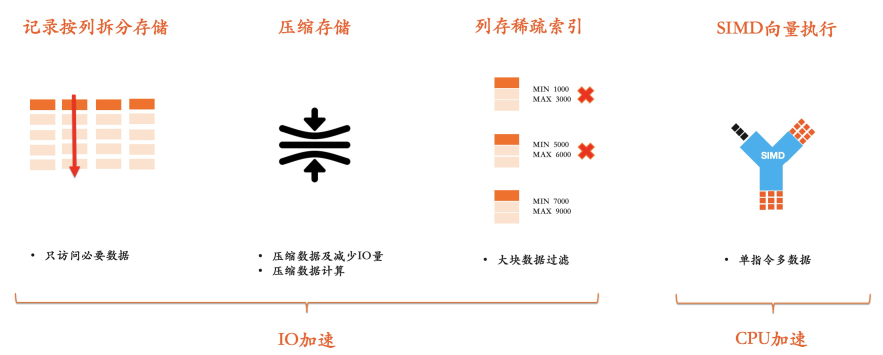
在分析情境,經常需要訪問某個列的大量記錄,而列存按列拆分儲存的方式會避免讀取不需要的列。其次,列存會將相同屬性的列連續儲存,其壓縮效率也遠超行存,通常可以達到10倍以上。列存中大Block Storage的結構,結合MIN/MAX等粗糙索引資訊可以實現大範圍的資料過濾。所有這些行為都極大的提升了IO的效率。在儲存計算分離架構下,減少通過網路讀取的資料量可以對查詢處理的回應時間帶來立竿見影的提升。
列式儲存同樣能提高CPU在處理資料時的執行效率。首先,列存的緊湊相片順序可提升CPU訪問記憶體的效率,減少由L1/L2 Cache miss導致的執行停頓時間。其次,在列式儲存上可以應用SIMD技術來進一步提升單核吞吐能力。
簡介
PolarDB In-Memory Column Index功能提供了列式儲存以及記憶體計算能力,讓使用者可以在一套資料庫上同時運行TP和AP型混合負載,在保證現有PolarDB優異的OLTP效能的同時,大幅提升了在巨量資料量上運行複雜查詢的效能。原理圖如下:
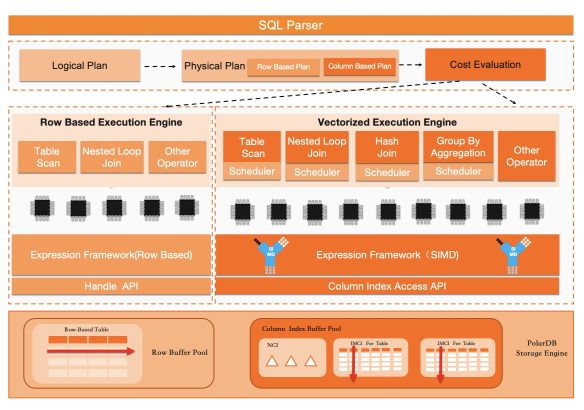
列存索引使用行列混合儲存技術。同時,結合PolarDB基於共用儲存一寫多讀的架構特徵,其包含如下幾個關鍵的技術創新點:
儲存引擎(InnoDB)支援儲存列式索引(Columnar Index),使用者可以通過DDL語句為一張表中的全部列或者部分列建立列索引,列索引採用列壓縮儲存,其儲存空間消耗會遠小於行存格式。預設列索引會全部常駐記憶體以實現最大化分析效能。但是,當記憶體不夠時也支援將其持久化到共用儲存中。
在SQL執行器層,重寫了一套面向列存的執行器引擎架構(Column-oriented),該執行器架構充分利用列式儲存的優勢,如以4096行的一個Batch為單位訪問儲存層的資料,使用SIMD指令提升CPU單核心處理資料的吞吐,所有關鍵運算元均支援並存執行。在列式儲存上,新的執行器對比MySQL原有的行存執行器有數量級的效能提升。
支援行列混合執行的最佳化器架構,該最佳化器架構會根據下發的SQL語句能否在列索引上執行來覆蓋查詢,並且其所依賴的函數及運算元能否在列式執行器中執行來決定是否啟動列式索引。最佳化器會同時對行存執行計畫和列存執行計畫做代價估算,並選中代價較低的執行計畫。
使用者可以使用叢集中的一個RO節點作為分析型節點,在該RO節點上配置產生列存索引,複雜查詢運行在列存索引上並使用所有可用CPU的計算能力,在獲得最大執行效能的同時不影響該叢集上的TP型負載的可用記憶體和CPU資源。
以上幾個關鍵技術的結合,使得PolarDB成為了一個真正的HTAP資料庫系統。
技術架構
行列混合最佳化器
PolarDB有一套面向行存的最佳化器組件,引擎層支援列存功能之後,此部分需要進行功能增強。最佳化器需要能夠判斷一個查詢應該被調度到行存執行還是列存執行。基於此,列存索引通過一套白名單機制和執行代價計算架構來完成此項任務。系統保證對支援的SQL語句進行加速查詢,同時相容運行不支援的SQL。
如何?100%的MySQL相容性
通過一套白名單機制來實現相容性。 使用白名單機制是基於如下幾點考量。
系統可用資源(主要是記憶體)限制。
一般情況下,不會為資料庫中全部表的所有列上都建立列索引。當一條查詢語句中使用到的列沒有在列存中存在時,其不能在列存上執行。
效能。
重寫一套面向列存的SQL執行引擎,包括所有的物理執行運算元和運算式計算,其所覆蓋的情境相對MySQL原生行存能夠支援的範圍有欠缺。當下發的SQL語句中包含一些列存索引不支援的運算元片段或者列類型時,需要能夠識別攔截並切換回行存執行。
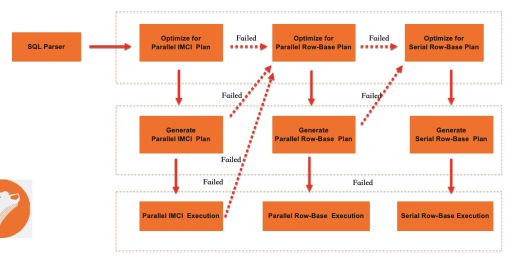
目前,白名單規則校正的內容包含SQL語句中的資料類型、運算元、計算運算式以及其他情境。其他情境如不支援multi statement等。
MySQL已經發展了數十年,其支援的各種列類型和SQL文法非常豐富。在IMCI中,初期重點最佳化在分析型查詢語句中最常見的SQL效能問題。即使適用情境有所限制,IMCI能夠啟動並執行SQL文法對MySQL功能的相容性也遠超絕大部分OLAP系統。對於那些不能在列存上執行的SQL,則直接回退到MySQL原生執行引擎,因此實現了100%的MySQL相容。
查詢計劃轉換
兼顧行列混合執行的最佳化器
面向列式儲存的執行引擎
IMCI是一套面向列存最佳化並完全獨立於現有MySQL行式執行器的執行引擎。重寫執行器的目的是為了消除現有行存執行引擎在執行分析型SQL時效率低的兩個關鍵瓶頸點,即按行訪問導致的虛函數訪問開銷以及無法並存執行。
向量化並存執行器
IMCI執行器引擎使用經典的火山模型,但是藉助了列存儲存以及向量執行來提升執行效能。
火山模型中,SQL產生的文法樹所對應的關係代數中,每一種操作會抽象為一個Operator,執行引擎會將整個SQL構建成一個Operator樹,查詢樹自頂向下調用Next()介面,資料則自底向上被拉取處理。該方法的優點是其計算模型簡單直接,通過把不同物理運算元抽象成一個個迭代器。每一個運算元只關心自己內部的邏輯即可,使得各個運算元之間的耦合性降低,從而比較容易寫出一個邏輯正確的執行引擎。
在IMCI執行引擎中,每個Operator也使用迭代器函數來訪問資料,但不同的是每次調用迭代器會返回一批資料,而不是一行,可以認為這是一個使用了向量化模式的火山模型。
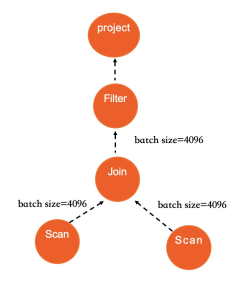
串列執行受制於單核計算效率、訪存延時、IO延遲等限制,執行能力有限。而IMCI執行器在幾個關鍵物理運算元(Scan/Join/Agg等)上均並存執行。除物理運算元需要支援並行外,IMCI的最佳化器也支援產生並存執行計劃,最佳化器在確定一個表的訪問方式時,會根據需要訪問的資料量來決定是否啟用並存執行,如果確定啟用並存執行,則會參考一系列狀態資料(包括當前系統可用的CPU/Memory/IO資源、目前已經調度和在排隊的任務資訊、統計資訊、query的複雜程度、使用者可配置的參數等)。 根據這些資料會計算出一個推薦的DOP值給一個運算元,而一個運算元內部會使用相同的DOP。同時,DOP也支援使用者使用Hint進行設定。
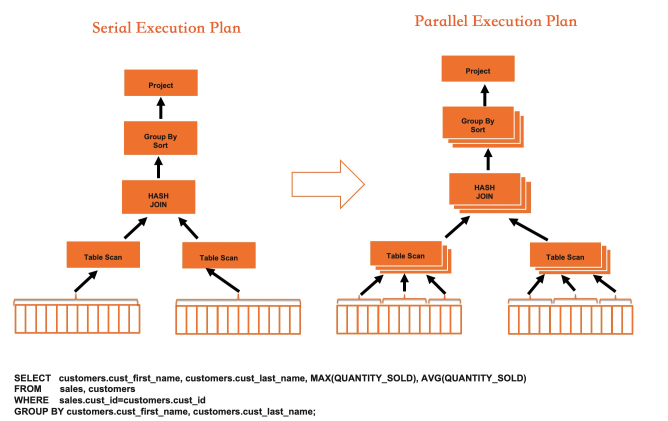
基於以上兩點最佳化思路,重新實現了所有物理執行運算元,包括TableScan、HashJoin、NestedLoopJoin、Groupby等。下面以HashJoin為例展示執行器的並行化及向量化加速效果。在IMCI中,HashJoin按如下流程執行:
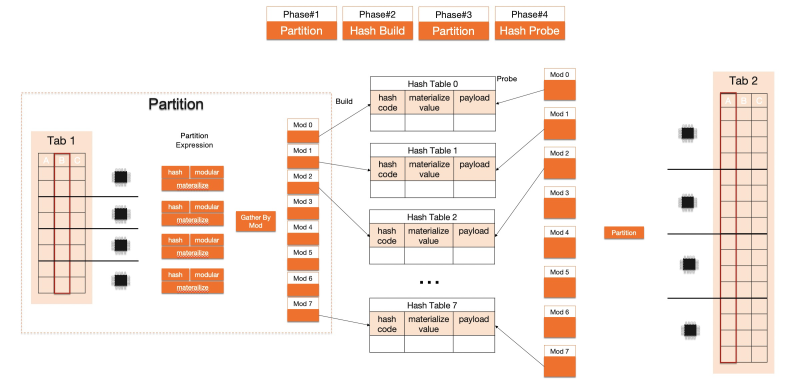
向量化執行解決了單核執行效率低的問題,而並存執行突破了單核的計算瓶頸。二者結合使得IMCI執行速度相比傳統MySQL行式執行有了數量級的提升。
向量化運算式體系
AP型情境,SQL中經常會包含很多涉及到一個或者多個值、運算子和函數組成的計算過程,這都是屬於運算式計算的範疇。運算式的求值是一個計算密集型的任務,因此,運算式的計算效率是影響整體效能的一個關鍵的因素。
傳統MySQL的運算式計算體系以一行為一個單位的逐行運算,一般稱其為迭代器模型實現。由於迭代器對整張表進行了抽象,整個運算式實現為一個樹形結構。但是,這種抽象會同時帶來效能上的損耗,因為在迭代器進行迭代的過程中,每一行資料的擷取都會引發多層的函數調用。同時,逐行地擷取資料會帶來過多的 I/O,對緩衝也不友好。MySQL採用樹形迭代器模型,是受到儲存引擎存取方法的限制,導致其很難對這些計算複雜的邏輯進行最佳化。
而在列存格式下,由於每一列的資料都單獨順序儲存,涉及到某一個特定列上的運算式計算過程都可以批量進行。對每一個計算運算式,其輸入和輸出都以Batch為單位,在Batch的處理模式下,計算過程可以使用SIMD指令進行加速。
向量化運算式的關鍵最佳化點:
充分利用列式儲存的優勢,使用分批處理的模型代替迭代器模型,使用SIMD指令重寫了大部分常用資料類型的運算式核心實現。例如,所有數字類型(int、decimal、double)的基本數學運算(+、 -、*、/、abs),全部都使用對應的SIMD指令實現。在AVX512指令集的加持下,單核運算效能數倍提升。
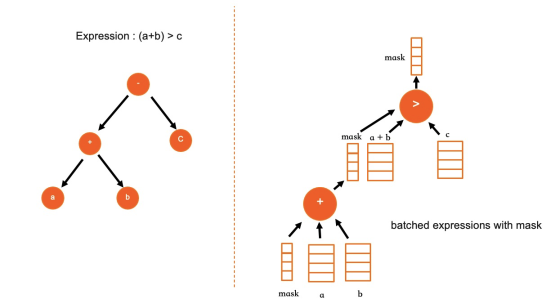
採用了與PostgreSQL類似運算式實現方法:在SQL編譯及最佳化階段,IMCI的運算式以一個樹形結構來儲存(與現有行式迭代器模型的表現方法類似)。但是,在執行之前會對該運算式樹狀架構進行一個後序遍曆,將其轉換為一維數組來儲存,在後續計算時只需要遍曆該一維數組結構即可以完成運算。由於消除了樹形迭代器模型中的遞迴過程,計算效率更高。同時該方法對計算過程提供簡潔的抽象,將資料和計算過程分離,適合并行計算。
行列混合儲存
事務型應用和分析型應用對儲存引擎有著截然不同的要求,前者要求索引可以精確定位到每一行並支援高效的增刪改操作,而後者則需要支援高效批量掃描處理。這兩個情境對儲存引擎的設計要求完全不同,有時甚至互相矛盾。因此,設計一個一體化的儲存引擎能同時服務OLTP型和OLAP型負載非常具有挑戰性。目前市場上HTAP儲存引擎做的比較好的只有幾家有幾十年研發積累的大型企業,如Oracle (In-Memory Column Store)、Sql Server(In Memory Column index)、DB2(BLU)等。TiDB只能通過將多複本集群中的一個副本調整為列存來支援HTAP需求。
一體化的HTAP儲存引擎一般使用行列混合的儲存方案,即引擎中同時存在行存和列存,行存服務於TP,列存服務於AP。相比於部署獨立一套OLTP資料庫加一套OLAP資料庫來滿足業務需求,單一的HTAP引擎具有如下的優勢:
行存資料和列存資料具有即時一致性,能滿足很多苛刻的業務需求,所有資料寫入即可見於分析型查詢。
低成本。使用者可以非常方便的指定哪些列甚至一張表的哪個範圍的儲存為列存格式。全量資料繼續以行存儲存。
管理營運方便,使用者無需關注資料在兩套系統之間同步及資料一致性問題。
PolarDB採用了和Oracle、Sql Server等商用資料庫類似的行列混合儲存技術,即In-Memory Column Index:
建表時可以指定部分表或者列為列存格式,或者對已有的表可以使用
ALTER TABLE語句為其增加列存屬性,分析型查詢會自動使用列存格式來進行查詢加速。列存資料預設以壓縮格式儲存在磁碟上,並可以使用In-Memory Column Store Area來做緩衝並加速查詢,傳統的行格式依然儲存在Buffer Pool中供OLTP型負載使用。
所有事務的增刪改操作都會即時反饋到列存儲存,保證了事務層級的資料一致性。
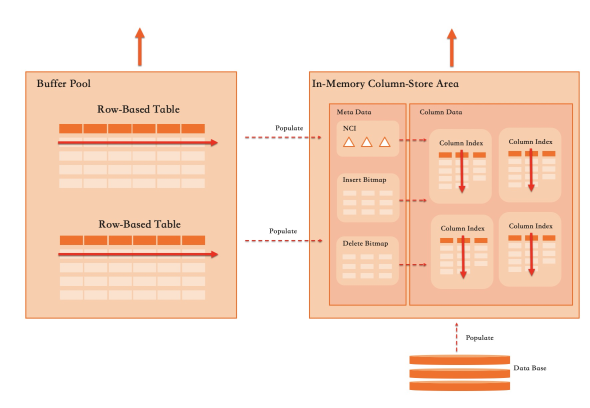
實現一個行列混合的儲存引擎非常困難,但是在InnoDB這樣一個成熟的面向OLTP負載最佳化的儲存引擎中增加列存,又面臨不同的情況:
滿足OLTP業務的需求是第一優先順序。因此,增加列存不能對TP效能有太大影響。這要求維護列存必須足夠輕量,必要時需要犧牲AP效能來維持TP效能。
列存的設計無需考慮事務並發情境下對資料的影響,以及資料的unique check等問題,這些問題在行存系統中已經被解決,而這些問題對ClickHouse等單獨的列存引擎來說,非常難以處理。
由於有一個久經考驗的行存系統的存在,列存系統出現任何問題,都可以切換回行存系統響應查詢請求。
上述條件可謂有利有弊,這也影響了對整個行列混合儲存的方案設計。
表現為Index的列存
在MySQL外掛程式式的儲存引擎架構下,增加列存支援最簡單的方案是實現一個單獨的儲存引擎,如Inforbright以及MarinaDB的ColumnStore都採用了這種方案。而PolarDB採用了將列存實現為InnoDB的二級索引方案,主要基於如下幾點考量:
InnoDB原生支援多索引,Insert、Update和Delete操作都會以行粒度apply到Primary Index和所有的Secondary Index上,並且保證事務。將列存實現為一個二級索引可以複用這套交易處理架構。
在資料編碼格式上,二級索引的列存可以和其他行存索引使用完全一樣的格式,直接記憶體拷貝即可,不需要考慮charset和collation等資訊。
二級索引操作非常靈活,可以在建表時指定索引所包含的列,也可以後續通過DDL語句對一個二級索引中包含的列進行增加或者刪除操作。例如,使用者可以將需要分析的int、float和double列加入列索引,而對於一般只需要點查但是又佔用大量空間的text和blob欄位,則可以保留在行存中。
崩潰恢複過程可以複用InnoDB的Redo交易記錄模組,與現有實現無縫相容。同時也方便PolarDB的物理複製過程,支援在獨立RO節點或者Standby節點上產生列存索引提供分析服務。
二級索引與主表有一樣的生命週期,方便管理。
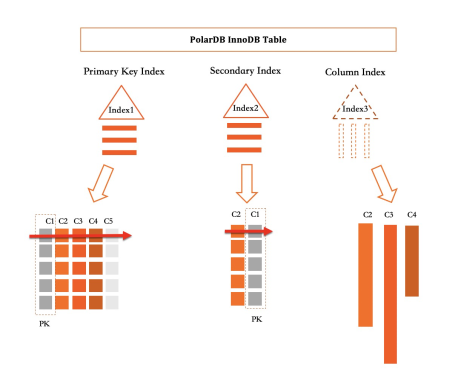
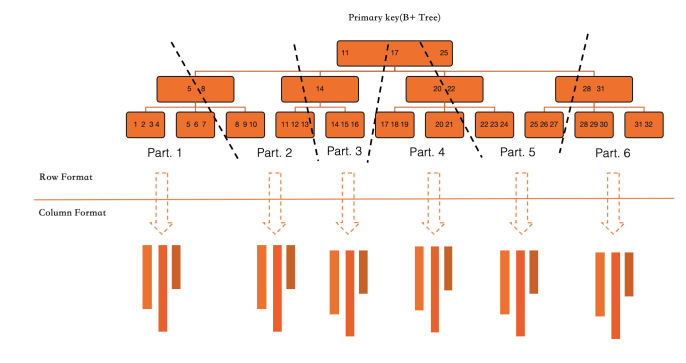
如上圖所示,在PolarDB中,所有Primary Index和Secondary Index都實現為一個B+Tree。而列索引在定義上是一個Index,但其實是一個虛擬索引,用於捕獲對該索引覆蓋列的增刪改操作。
對於上面的表,其主表(Primary Index)包含(C1、C2、C3、C4、C5) 5列資料, Secondary Index索引包含(C2、C1)兩列資料,在普通二級索引中,C2與C1編碼成一行儲存在B+tree中。而其中的列存索引包含(C2、C3、C4)三列資料。在實際實體儲存體時,會對三列進行拆分隔離儲存區 (Isolated Storage),每一列都會按寫入順序轉成列存格式。
列存實現為二級索引的另一個好處是執行器的工程實現非常簡單,在MySQL中已經存在覆蓋索引的概念,即一個查詢所需要的列都在一個二級索引中儲存,則這個二級索引中的資料滿足查詢需求,使用二級索引相對於使用Primary Index可以極大減少讀取的資料量進而提升查詢效能。當一個查詢所需要的列都被列索引覆蓋時,藉助列存的加速作用,可以數十倍甚至數百倍的提升查詢效能。
列存資料群組織
對Column Index中的每一列,其儲存都使用了無序且追加寫的格式。結合標記刪除及後台非同步compaction實現空間回收。其具體實現上有如下幾個關鍵點:
列索引中記錄按RowGroup進行組織(目前每個RowGroup包含64K行),每個RowGroup中不同的列會各自打包形成DataPack。
每個RowGroup都採用追加寫,分屬每個列的DataPack也是採用追加寫入模式。對於一個列索引,只有Active RowGroup負責接受新的寫入。當該RowGroup寫滿之後即凍結,其包含的所有Datapack會轉為壓縮格儲存到磁碟上,同時記錄每個資料區塊的統計資訊便於過濾。
列存RowGroup中每新寫入一行都會分配一個RowID用於定位,屬於一行的所有列都可以用該RowID計算定位,同時系統維護PK到RowID的映射索引,以支援後續的刪除和修改操作。
更新操作採用標記刪除的方式,對於刪除操作直接設定BitMap即可。對於更新操作,首先根據RowID計算出其原始位置並設定刪除標記,然後在ActiveRowGroup中寫入新的資料版本。
當一個RowGroup中的無效記錄超過一定閾值,則會觸發後台非同步compaction操作,其作用一方面是回收空間,另一方面可以讓有效資料存放區更加緊湊,提升分析型查詢單的效率。
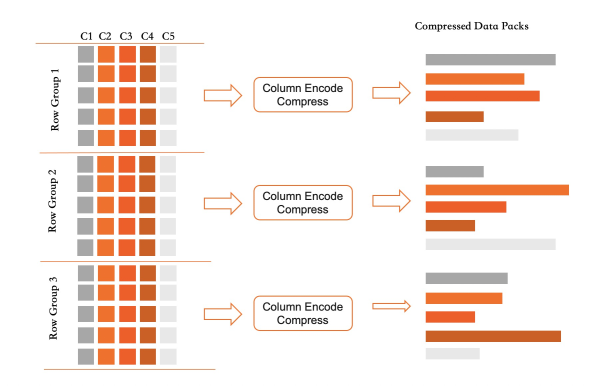
採用這種資料群組織方式,一方面滿足了分析型查詢按列進行批量掃描過濾的要求。另一方面對於TP型事務操作影響非常小,寫入操作只需要按列追加寫到記憶體即可,刪除操作只需要設定一個刪除標記位。而更新操作則是一個標記刪除附加一個追加寫。列存在支援事務層級更新的同時,幾乎不影響OLTP的效能。
全量及增量行轉列
以下兩種情況會執行行轉列操作:
第一種情況:使用DDL語句對部分列建立列索引(對一張已存在的表有分析型需求),此時需要掃描全表資料以建立列索引。
第二種情況:在事務操作過程中對涉及到的列執行行轉列。
對於全錶行轉列的情形,使用並行掃描的方式對InnoDB中的Primary Key進行掃描,並依次將所有涉及到的列轉換為列存形式,該操作的速度非常快,其基本僅受限於伺服器可用的IO吞吐速度和CPU資源。該操作是一個online-DDL過程,不會阻塞線上業務的運行。
在一張表上建立列索引之後,所有的更新事務將會同步更新行存和列存資料,以保證二者的事務一致性。下圖示範了開啟和關閉IMCI功能的差異性。
未開啟IMCI功能時,事務對所有行的更新都會先加鎖,然後在對資料頁進行修改,在事務提交之前會對所有加鎖的記錄一次性釋放鎖。
開啟IMCI功能之後,事務系統會建立一個列存更新緩衝,在所有資料頁被修改的同時,會記錄所涉及到的列存的修改操作,在事務結束並釋放鎖之前,該緩衝會應用到列存系統。
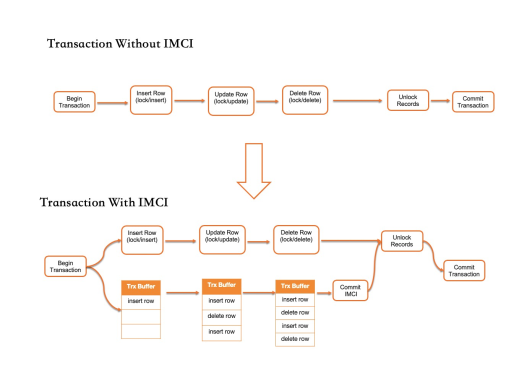
對於一般的OLTP型請求,最後的記憶體資料頁更新只佔事務操作過程的很少一部分時間,因此此方法對TP型事務時延的影響非常小。對於操作了非常多的行的大事務,則會直接將其對列索引的更新即時應用到列存儲存,但是在事務提交之前不對外可見,也保證了大事務的提交延時增加在一個非常小的時間範圍。同時為了更進一步的降低對TP效能的影響,當AP型查詢對資料的即時性要求不高時, 列索引支援非同步應用對列存的更新操作。
列存儲存提供了與行存一樣的交易隔離等級。對於每個寫操作,RowGroup中的每一行都會記錄修改該行的事務編號,而對於DeleteBitMap,每個標記刪除操作也會記錄該標誌位的事務編號。藉助寫入事務號和刪除事務號,AP型查詢可以用非常輕量級的方式獲得一個全域一致性的快照。
列索引粗糙索引
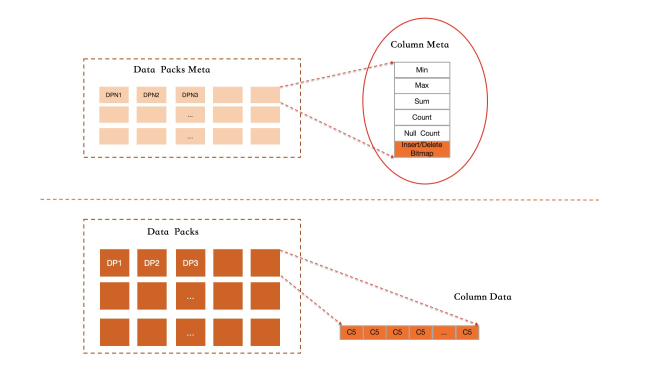
由前述列舉的儲存格式可以看出,IMCI中所有的Datapack都採用無序且追加寫的方式,因此無法像InnoDB的普通有序索引那樣,可以精準的過濾掉不符合要求的資料。在IMCI中,藉助統計資訊來進行資料區塊過濾,以此來達到降低資料訪問單價的目的。
在每個Active Datapack終結寫入的時候,會預先進行計算,並產生Datapack所包含資料的最小值、最大值、數值的總和、空值的個數和記錄總條數等資訊。所有這些資訊會維護在DataPacks Meta元資訊地區並常駐記憶體。由於凍結的Datapack中還會存在資料的刪除操作,因此統計資訊的更新維護會放到後台完成。
對於查詢請求,會根據查詢條件將Datapacks分為相關、不相關、可能相關三大類,從而減少實際的資料區塊訪問。而對於一些彙總查詢操作,如count和sum等,可以通過預先計算好的統計值進行簡單的運算得出,這些資料區塊甚至都不需要進行解壓。
採用基於統計資訊的粗糙索引方案,對於一些需要精準定位部分資料的查詢並不是很友好。但是在一個行列混合儲存引擎中,列索引只需要輔助加速那些會涉及到大量資料掃描的查詢,在這個情境下使用列存索引會具有顯著的優勢。而對於那些只會訪問到少量資料的SQL,最佳化器通常會基於代價模型計算得出基於行存而得到的一個成本更低的方案。
行列混合儲存下的TP和AP資源隔離
行列混合儲存可以在一個叢集中同時支援AP型查詢和TP型查詢。但很多業務有很高的OLTP型負載,而突發性的OLAP型負載可能干擾到TP型業務的響應時延。因此負載隔離在HTAP資料庫中是一個必須支援的功能。藉助一寫多讀架構,可以非常方便地對AP型負載和TP型負載進行隔離。在PolarDB技術架構下,有如下幾個部署方式:
第一種方式:在RW上開啟行列混合儲存,此種部署模式可以支援輕量級的AP查詢,以TP負載為主,且AP型請求比較少時可以採用。或者使用PolarDB進行報表查詢,且資料來自批量資料匯入的情境。
第二種方式:RW支援OLTP型負載,並啟動一個AP型RO開啟行列混合儲存以支援查詢,此種部署模式下CPU資源可以實現100%隔離,同時該AP型RO節點上的記憶體可以100%分配給列存儲存和執行器。但是,由於使用相同的共用儲存,因此在IO上會相互產生一定影響。
第三種方式:RW和RO均支援OLTP型負載,在單獨的Standby節點開啟行列混合儲存以支援AP型查詢,由於Standby是使用獨立的共用儲存叢集,這種方案在第二種方案支援CPU和記憶體資源隔離的基礎上,還可以實現IO資源的隔離。
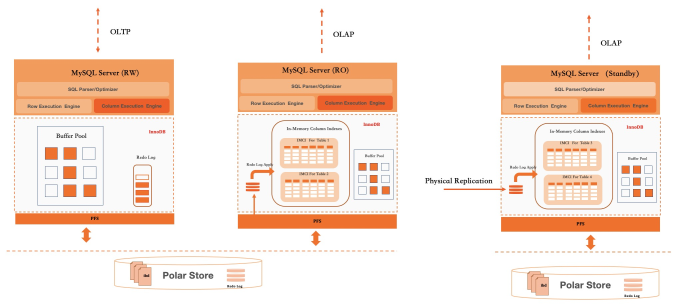
除上述部署架構上的不同,和可以支援的資源隔離不同之外。在PolarDB內部對於一些需要使用並存執行的大查詢,支援動態並行度調整(Auto DOP),這個機制會綜合考慮當前系統的負載以及可用的CPU和記憶體資源,對單個查詢所用的資源進行限制,以避免單個查詢消耗的資源太多,影響其他請求的處理。
OLAP效能
詳情請參見列存索引(IMCI)效能。