本文介紹了PolarDB IMCI中GroupJoin運算元的一些限制條件和實現方式,以及其他資料的一些相關實現。閱讀本文前請先瞭解基礎的HASH JOIN與HASH GROUP BY演算法。
背景
SELECT
key1,
SUM(sales) as total_sales
FROM
fact_table LEFT JOIN dimension_table ON fact_table.key1 = dimension_table.key1
GROUP BY
fact_table.key1
ORDER BY
total_sales
LIMIT 100;在PolarDB IMCI中,類似以上查詢語句的執行計畫是先執行一遍HASH JOIN,再執行HASH GROUP BY key1。在這兩個操作中,都會使用key1建立雜湊表(注意fact_table.key1 = dimension_table.key1),執行計畫說明如下:
-
HASH JOIN:使用dimension_table.key1建雜湊表,使用fact_table.key1查雜湊表並輸出資料;
-
HASH GROUP BY:使用fact_table.key1建雜湊表,寫入雜湊表的過程中做彙總運算。
從執行效率的角度來看,這兩個操作可以合并成一個,使用dimension_table.key1建雜湊表以及做彙總運算,使用fact_table.key1查雜湊表以及做彙總運算,因此節省了使用fact_table.key1建雜湊表的時間。這種將HASH JOIN與HASH GROUP BY兩個運算元合并成一個的操作,就是GroupJoin。
從執行效率的角度來看,將這兩個操作合并成一個操作,不僅可以減少一次建雜湊表的操作,還可以減小中間結果大小。因為JOIN是一個可能使“結果集膨脹”的運算,一張表的一行可能會匹配上另一張表的多行,最壞情況下便是笛卡兒積:N行的表與M行的表JOIN的結果最大可能是N×M的結果集。因此在HASH JOIN+HASH GROUP BY的執行方式中,一張N行的雜湊表可能會輸出N×M×S行結果(S代表selectivity,0≤S≤1),然後在HASH GROUP BY的grouping操作中再被彙總成一張新的雜湊表,這會造成資源浪費。即使是上面例子中“事實表”(大表,大小為M)與“維度資料表”(小表,大小為N)的LEFT OUTER JOIN,且key1都是unique key,也是從一張N行的雜湊表, 經過HASH JOIN輸出M行結果,然後彙總成M行的雜湊表。相對而言,GroupJoin只需要在N行的雜湊表中完成join&aggr運算,不僅中間結果變少了,同時記憶體佔用也變小了。
基於以上考慮,PolarDB MySQL版在PolarDB IMCI中增加了GroupJoin運算元。
演算法設計
概述
IMCI裡的GroupJoin實現,是HashJoin與HashGroupby兩個運算元的融合:
-
先使用左表(小表)建立雜湊表,涉及左表的aggr函數會在建雜湊表的時候直接運算掉。這個過程與對左表彙總(i.e., HashGroupby left_table)的操作是相同的。
-
使用右表(大表)查雜湊表,查詢命中則在hash table entry上運算涉及右表的aggr函數,否則丟棄或者直接輸出。
以上介紹了IMCI GroupJoin演算法的基本思路,下文會對演算法進行詳細的描述以及介紹簡化的方法。
限制條件
出於實現的複雜度考慮,相對於理論上最完備的GroupJoin實現,PolarDB MySQL版做了如下幾點限制:
-
group by key要完全符合某一邊,且只能是某一邊的join key,雖然某些情況下join key的一部分,也能唯一定義這個key(i.e., functional dependency);
-
RIGHT JOIN、GROUP BY RIGHT的情境,要求right keys是unique keys。否則可能會轉成LEFT JOIN、GROUP BY LEFT的方式,或者不使用GroupJoin;
-
任意一個aggr函數只能單獨引用左表,或者單獨引用右表;如果原GROUP BY運算元中的aggr函數同時引用了左右兩個表(e.g., SUN(t1.a+t2.a)),則不適用GroupJoin。
演算法
INNER JOIN/GROUP BY LEFT
此情境如下SQL所示:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1假設實際執行順序與SQL描述一樣,且Join過程中不會動態換邊。
-
使用左表建雜湊表,並且建立雜湊表的過程中直接運算涉及左表的aggr函數;涉及右表的aggr函數,對應設一個“repeat count”,這等同於一個hash table entry對應的payload的數量;
-
在join過程中,使用右表查雜湊表,如果不匹配,則右表的行直接被丟棄;如果匹配,左表的aggr context的“repeat count”會增加1,右表的aggr函數直接進行運算;
-
join完成後,只輸出曾經被匹配上的hash table entry的aggr結果,沒有被匹配上的hash table entry全部忽略;
-
輸出aggr結果時,要考慮“repeat count”,例如如果一個SUM(expr)的結果是200,“repeat count”是5,則最終結果是1000。
INNER JOIN/GROUP BY RIGHT
此情境如下SQL所示:
l_table INNER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1考慮到l_table.key1=r_table.key1,這種情況被歸到“INNER JOIN, GROUP BY LEFT”裡。
LEFT OUTER JOIN/GROUP BY LEFT
此情境如下SQL所示:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1-
使用左表建雜湊表,建雜湊表的過程中運算左表的aggr函數;涉及右表的aggr函數,對應設一個“repeat count”;
-
在join過程中,使用右表查雜湊表,如果不匹配,則右表的行直接被丟棄;如果匹配,左表的aggr context的“repeat count”會增加1,右表的aggr函數直接進行運算;
-
與INNER JOIN不同,此情境中join完成後,被匹配上的hash table entry的aggr結果直接輸出,沒有被匹配上的每個hash table entry單獨成為一個GROUP,對應的右表的aggr函數的輸入都是NULL。
LEFT OUTER JOIN/GROUP BY RIGHT
此情境如下SQL所示:
l_table LEFT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1-
使用左表建雜湊表,建雜湊表的過程中運算左表的aggr函數;涉及右表的aggr函數,對應設一個 “repeat count”;
-
在join過程中,使用右表查雜湊表,如果不匹配,則右表的行直接被丟棄;如果匹配,左表的aggr context的“repeat count”會增加1,右表的aggr函數直接進行運算;
-
與其他情境不同,此情境中join完成後,被匹配上的hash table entry的aggr結果直接輸出,沒有被匹配上的所有hash table entry成為一個GROUP,對應的右表的aggr函數的輸入都是NULL。
RIGHT OUTER JOIN/GROUP BY LEFT
此情境如下SQL所示:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY l_table.key1-
使用左表建雜湊表,建立雜湊表的過程中運算左表的aggr函數;涉及右表的aggr函數,對應設一個“repeat count”;
-
與其他情境不同,此情境在join過程中,使用右表查雜湊表,如果匹配,左表的aggr context的“repeat count”會增加1,右表的aggr函數直接進行運算;如果不匹配,則右表的所有不匹配的行成為一個GROUP,對應的左表的aggr函數結果都是NULL;
-
與其他情境不同,此情境在join完成後,被匹配上的hash table entry的aggr結果直接輸出,沒有被匹配上的所有hash table entry全都忽略。
RIGHT OUTER JOIN/GROUP BY RIGHT
此情境如下SQL所示:
l_table RIGHT OUTER JOIN r_table
ON l_table.key1 = r_table.key1
GROUP BY r_table.key1限制條件
要求r_table.key1必須是distinct的,否則這種join是不合法的;如果不能確定r_table.key1是distinct的,則需要在最佳化器裡將這種join+groupby轉成LEFT OUTER JOIN、GROUP BY LEFT。
執行步驟
-
使用左表建雜湊表,建雜湊表的過程中運算左表的aggr函數;涉及右表的aggr函數,對應設一個“repeat count”;
-
與其他情境不同,此情境在join過程中,使用右表查雜湊表,如果匹配,直接輸出左右表的aggr結果;如果不匹配,也輸出aggr結果,此時左表的aggr結果都是NULL;
-
與其他情境不同,此情境在join完成後,GroupJoin即完成,不需要處理任何hash table entry。
運行時落盤(spilling)處理
GroupJoin的落盤處理,類似於partition-style的HashJoin&HashGroupby的落盤處理,方法如下:
-
GroupJoin的整體演算法採用分區(partition)的方式;
-
使用左表構建雜湊表時,記憶體中的partition,構建hash table的演算法與演算法一節描述一致;
-
使用左表構建雜湊表時,不在記憶體中的partition,刷到磁碟中對應的臨時檔案,後續新寫入這個partition 的資料也會直接刷到磁碟中對應的臨時檔案;落盤的partition會建立一個bloomfilter,方便後續尋找的時候快速過濾掉不可能匹配的右表資料;
-
完成左表的雜湊表構建後,使用右表資料查雜湊表:
相關實現
2011年的一篇論文Accelerating Queries with Group-By and Join by Groupjoin(簡稱 paper_1)從理論角度闡述了GroupJoin在不同查詢計劃中的可行性,但是不涉及太多實現的細節。論文描述了GroupJoin運算時的約束,以及適用GroupJoin的情境,比如不同aggr函數如何處理等,描述得比較抽象,整體可讀性不是很好。
2021年有一篇論文A Practical Approach to Groupjoin and Nested Aggregates (簡稱 paper_2)描述了如何在(記憶體)資料庫中高效地實現GroupJoin運算元。這篇論文的幾個重點是:
1. 解關聯子查詢的演算法中使用GroupJoin
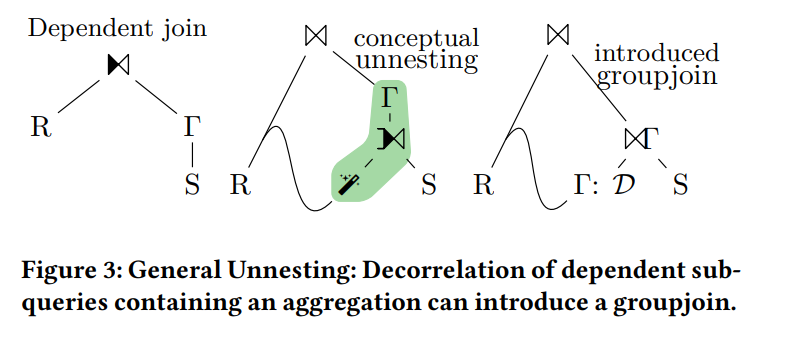
在解決“關聯項上方有 GROUP BY”這種關聯子查詢時,有一種方式是引入“MagicSet”操作(也就是 table distinct)並在上方增加一個JOIN+GROUP BY,從而完成子查詢的去關聯。這種模樣的執行計畫,恰好符合GroupJoin的適用情境。由於IMCI目前也使用了類似的解關聯演算法,但是目前暫時不能產生此類shared children的執行計畫。
2. Eager aggregation
簡單來說,就是在hash build的過程中,把hash build那一邊的aggr函數直接計算掉,而不是為每個hash table entry保留完整的payload,最後再運算aggr函數。這與IMCI的實現思路是一樣的。
3. 使用memoizing的方式解決並發查雜湊表做彙總運算時的衝突
舉個極端的例子:hash probe的過程中,所有資料都命中hash table的同一個entry,因此要在此entry進行彙總運算(比如SUM(2 * col)),因此需要使用同一個“aggr context”運行aggr函數;例如,對於 SUM() 彙總函式來說,就是不斷使用同一個sum_value進行加法操作。即使是原子變數的加法操作,遇到contention也是有效能問題的,更何況是通用的彙總函式運算。這篇論文的思路是為所有“沒有搶到entry所有權”的線程建立各自的local hash table進行運算,對於每個entry,利用CAS指令設定一個owner thread id,除了owner thread外,後續到來的thread都使用自己的local hash table進行運算,最後再將這些local hash table合并到global hash table裡。
4. 並不是所有情境都適用於GroupJoin
有些情境更適用於Join+Groupby。舉個例子,假設hash build一邊的selectivity很低,hash probe完成後,這一邊的大多數行都不會被選中,那麼就會遇到了一個兩難的境地了:
-
如果在hash build的時候,同時把這一邊的彙總運算做掉(i.e.,eager aggregation),則不需要保留hash table的payload,節省了記憶體,但是因為join的selectivity很低,大多數行最後都不會被選中,因此這些提前運算的agg運算都浪費掉了;
-
如果不提前做aggr運算,則需要多花一些記憶體;但是在join的selectivity很高(大多數行都被選中)的情況下,這些記憶體本可以通過提前進行的aggr運算節省掉。
所以,如果join的selectivity很低,那麼更好的方式或許是:join完後,得到非常少的group,然後在HashGroupby中做局部性很強的彙總操作。因此,這篇論文提出了幾種情境下不同的實現。而為了知道一個查詢適用於哪種情境,需要最佳化器提供selectivity和cardinality的估算,因此論文後面配套提供了一些最佳化器裡用到的估算方法。
從實現者的角度看來,上面所說的“兩難的境地”其實並不是太大的問題,這是因為:
-
PolarDB IMCI幾乎總是用小的一邊(小表)建雜湊表;
-
即使JOIN的selectivity很低,使用eager aggregation提前運算彙總函式的策略,雖然浪費了針對一個小表的運算時間,但是無論如何也節省了記憶體,並不是一無所獲;這種情況下,相對於HashJoin+HashGroupby,也算是時間換空間。
在IMCI的實現裡面,除了上文說的RIGHT JOIN+GROUP BY RIGHT情境,PolarDB IMCI幾乎總是認為GroupJoin的執行效率是優於HashJoin+HashGroupby。
從作者以及論文裡面的測試情況來看,上述的兩篇論文應該都來自慕尼黑大學的hyper資料庫團隊。除hyper外,目前還沒有見到其他資料庫實現GroupJoin運算元,但是應該有“shared hash table”操作的其他實現方式,後續再進一步討論。
GroupJoin在TPCH中的應用
TPCH是一個常用的測試一個AP系統的分析查詢能力的benchmark。在TPCH的22條查詢中,有不少都是適用GroupJoin運算元的。不過,除了TPCH Q13,其他的查詢語句都需要經過一定改造才能適用GroupJoin運算元。
Q13
TPCH Q13,可以直接適用GroupJoin運算元:
select
c_count,
count(*) as custdist
from
(
select
c_custkey,
count(o_orderkey) as c_count
from
customer
left outer join orders on c_custkey = o_custkey
and o_comment not like '%pending%deposits%'
group by
c_custkey
) c_orders
group by
c_count
order by
custdist desc,
c_count desc;-
在IMCI中,如果不使用GroupJoin,則執行計畫如下:
1 Project | Exprs: temp_table4.temp_table2.COUNT(orders.o_orderkey), temp_table4.COUNT(0) 2 Sort | Exprs: temp_table4.COUNT(0) DESC,temp_table4.temp_table2.COUNT(orders.o_orderkey) DESC 3 HashGroupby | OutputTable(4): temp_table4 | Grouping: temp_table2.COUNT(orders.o_orderkey) | Output Grouping: temp_table2.C 4 HashGroupby | OutputTable(2): temp_table2 | Grouping: customer.c_custkey | Output Grouping: customer.c_custkey | Aggrs: C 5 HashJoin | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: customer.c_custkey = orders.o_custkey 6 CTableScan | InputTable(0): customer | Pred: (TRUE PRED) 7 CTableScan | InputTable(1): orders | Pred: ( NOT (orders.o_comment LIKE "%pending%deposits%")) -
如果使用GroupJoin,執行計畫如下:
9 Project | Exprs: temp_table4.temp_table2.COUNT(orders.o_orderkey), temp_table4.COUNT(0) 10 Sort | Exprs: temp_table4.COUNT(0) DESC,temp_table4.temp_table2.COUNT(orders.o_orderkey) DESC 11 HashGroupby | OutputTable(4): temp_table4 | Grouping: temp_table2.COUNT(orders.o_orderkey) | Output Grouping: temp_table2.C 12 GroupJoin | Grouping: customer.c_custkey (unique) | JoinMode: LEFT OUTER | JoinPred: customer.c_custkey = orders.o_custke 13 CTableScan | InputTable(0): customer | Pred: (TRUE PRED) 14 CTableScan | InputTable(1): orders | Pred: ( NOT (orders.o_comment LIKE "%pending%deposits%"))
Q3
對TPCH的Q3而言,GroupJoin的最佳化需要經過一系列等價變換:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit
10;Q3的一種可行的執行計畫如下(IMCI中的執行計畫): DERKEY,TEMPTABLE
1 Project | Exprs: temp_table3.lineitem.l_orderkey, temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount), temp_...
2 TopK | Limit = 10 | Exprs: temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount) DESC,temp_table3.orders.o_orderdate
3 HashGroupby | OutputTable(3): temp_table3 | Grouping: lineitem.l_orderkey orders.o_orderdate orders.o_shippriority | Output: lineitem.l_orderkey, orders.o_orderdate, orders.o_shippriority, SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount)
4 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey
5 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey
6 CTableScan | InputTable(0): orders | Pred: (orders.o_orderdate < 03/15/1995 00:00:00.000000)
7 CTableScan | InputTable(1): customer | Pred: (customer.c_mktsegment = "BUILDING")
8 CTableScan | InputTable(2): lineitem | Pred: (lineitem.l_shipdate > 03/15/1995 00:00:00.000000)由於此SQL的grouping keys是l_orderkey、o_orderdate、o_shippriority,與任何一個join keys都不相同,因此並不能直接適用GroupJoin。通過一些等價推導,可得出以下結論:
-
由於lineitem與orders表的join predicate是l_orderkey=o_orderkey,而且是INNER JOIN,因此可以判斷出,這個join的結果集裡面,l_orderkey=o_orderkey;
-
由於l_orderkey=o_orderkey,因此 GROUP BY l_orderkey、o_orderdate、o_shippriority 等價於 GROUP BY o_orderkey、o_orderdate、o_shippriority;
-
由於o_orderkey是orders表的PRIMARY KEY,因此每一個o_orderkey都能直接確定唯一的o_orderdate和o_shippriority (i.e.,o_orderdate and o_shippriority functionally depend on o_orderkey);
-
由於o_orderkey能唯一確定o_orderdate和o_shippriority,因此GROUP BY o_orderkey、o_orderdate、o_shippriority等價於GROUP BY o_orderkey;
由上面的推導,可以將Q3的group by clause等價變換成GROUP BY o_orderkey,如此可適用於GroupJoin了:KEY,TEMPTABLE3.SUM(LINETTEM.EXTENDEDPRTCE*1.00-LUNETEM._DLSCOL
Project | Exprs: temp_table3.lineitem.l_orderkey, temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount), temp_
TopK | Limit = 10 | Exprs: temp_table3.SUM(lineitem.l_extendedprice * 1.00 - lineitem.l_discount) DESC,temp_table3.ANY_VALUE(orders.o_orderdate)
GroupJoin | Grouping: lineitem.l_orderkey | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey
CTableScan | InputTable(0): orders | Pred: (orders.o_orderdate < 03/15/1995 00:00:00.000000)
CTableScan | InputTable(1): customer | Pred: (customer.c_mktsegment = "BUILDING")
CTableScan | InputTable(2): lineitem | Pred: (lineitem.l_shipdate > 03/15/1995 00:00:00.000000)這種“functional dependency”的推導,對最佳化器有一定要求。目前MySQL最佳化器中,實現了部分functional dependency的推導,但是依然無法推匯出上面的GROUP BY o_orderkey變換。經過嘗試,發現SQL SERVER是可以推匯出GROUP BY o_orderkey變換的,這方面有比較完備的理論,但是IMCI目前在這方面還沒有完全實現。在TPCH裡面,Q3/Q4/Q10/Q13/Q18/Q20/Q21都有這種特徵,如果能做這種等價推導,將可以縮短GROUP BY的grouping keys,提高彙總操作的速度。
Q10
TPCH的Q10也不能直接適用GroupJoin:
select
c_custkey,
c_name,
sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
from
customer,
orders,
lineitem,
nation
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-10-01'
and o_orderdate < date '1993-10-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
order by
revenue desc
limit
20;如果要使用GroupJoin,需要做以下兩個變換:
-
通過等價變換把grouping keys變成c_custkey(customer表的PRIMARY KEY),這個變換與上文的Q3類似;
-
Join order要調整,使得customer表的JOIN在最外層。
其中1總是有益的,但是2中join order的調整,不一定是有益的。
Q17
TPCH的Q17包含一條關聯子查詢:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#44'
and p_container = 'WRAP PKG'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);其去關聯的方式有幾種,目前IMCI針對scalar aggr實現的兩種去關聯演算法得到的執行計畫分別是:
Project | Exprs: temp_table7.temp_table6.SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice)) / 7.0
ComputeScalar | Exprs: temp_table6.SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice)) / 7.0
HashGroupby | OutputTable(6): temp_table6 | Grouping: None | Output Grouping: None | Aggrs: SUM(temp_table3.ANY_VALUE(lineitem.l_extendedprice))
FILTER | Pred: ((CAST temp_table3.ANY_VALUE(lineitem.l_quantity)/DECIMAL(15, 2) as DECIMAL(38, 12)) < 0.2 * temp_table3.AVG(lineitem.l_quantity))
HashGroupby | OutputTable(3): temp_table3 | Grouping: temp_sequence.SEQUENCE_VALUE | Output Grouping: None | Aggrs: AVG(lineitem.l_quantity)
HashJoin | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: part.p_partkey = lineitem.l_partkey
SEQUENCE | SequenceID: (55440)
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: lineitem.l_partkey = part.p_partkey
CTableScan | InputTable(0): lineitem | Pred: (TRUE PRED)
CTableScan | InputTable(1): part | Pred: ((part.p_brand = "Brand#44") AND (part.p_container = "WRAP PKG"))
CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)RE
Project | Exprs: temp_table7.temp_table6.SUM(lineitem.l_extendedprice) / 7.0
ComputeScalar | Exprs: temp_table6.SUM(lineitem.l_extendedprice) / 7.0
HashGroupby | OutputTable(6): temp_table6 | Grouping: None | Output Grouping: None | Aggrs: SUM(lineitem.l_extendedprice)
FILTER | Pred: ((CAST lineitem.l_quantity/DECIMAL(15, 2) as DECIMAL(38, 12)) < 0.2 * temp_table3.AVG(lineitem.l_quantity))
HashMatch | HashMode: DYNAMIC | JoinMode: LEFT_OUTER | JoinPred: part.p_partkey = temp_table3.lineitem.l_partkey
HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: lineitem.l_partkey = part.p_partkey
CTableScan | InputTable(0): lineitem | Pred: (TRUE PRED)
CTableScan | InputTable(1): part | Pred: ((part.p_brand = "Brand#44") AND (part.p_container = "WRAP PKG"))
HashGroupby | OutputTable(3): temp_table3 | Grouping: lineitem.l_partkey | Output Grouping: lineitem.l_partkey | Aggr
CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)這些執行計畫都不適用GroupJoin運算元。如果採用MagicSet運算元的去關聯方式,在移除MagicSet運算元之前,會得到一個適合GroupJoin的中間態:
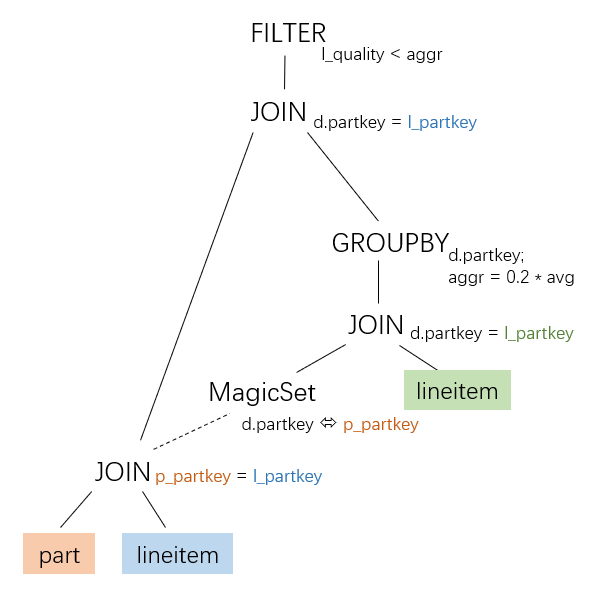
也就是paper_2中所描述的過程: NERALNESTING:DEEORRELATIONOFDEPENDENTSUB-
因此可以適用GroupJoin。目前IMCI部分實現了採用MagicSet運算元的去關聯方式,但是不會產生hared children的執行計畫,因此IMCI裡面無法對TPCH Q17適用GroupJoin。
Q18
TPCH Q18也是可以適用GroupJoin的,不過依然要利用等價變換轉換執行計畫,才能得到適用GroupJoin的執行計畫。為了方便描述,不失一般性,此處把Q18裡的IN子查詢以及最後的ORDER BY去掉:
select
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice對於這個查詢,做如下等價推導:
-
因為c_custkey是customer表的PRIMARY KEY,因此c_name可以由c_custkey唯一確定(functional dependency);同理o_orderkey是orders表的PRIMARY KEY,o_orderdate與o_totalprice都可以由o_orderkey唯一確定。因此,group by clause可以被等價轉換為GROUP BY c_custkey, o_orderkey;
-
由於customer表與orders表的join predicate是c_custkey=o_custkey,因此可以斷言,join的結果集中,c_custkey=o_custkey;
-
由於c_custkey=o_custkey,因此group by clause可以被等價轉換為GROUP BY o_custkey, o_orderkey;
-
由於o_orderkey唯一確定o_custkey (o_orderkey是orders表的主鍵),因此group by clause可以被等價改寫為GROUP BY o_orderkey。
經過以上等價推導,整個查詢可以被等價改成類似如下一個SQL:
select
ANY_VALUE(c_name),
ANY_VALUE(c_custkey),
o_orderkey,
ANY_VALUE(o_orderdate),
ANY_VALUE(o_totalprice),
sum(l_quantity)
from
customer,
orders,
lineitem
where
c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
o_orderkey-
不帶GroupJoin的執行計畫
1 Project | Exprs: temp_table3.ANY_VALUE(customer.c_name), temp_table3.ANY_VALUE(customer.c_custkey), temp_table3.orders.o_orderkey, temp_table3.ANY_VALUE(orders.o_orderdate), temp_table3.ANY_VALUE(orders.o_totalprice), temp_table3.SUM(lineitem.l_quantity) 2 HashGroupby | OutputTable(3): temp_table3 | Grouping: orders.o_orderkey | Output Grouping: orders.o_orderkey | Aggrs: ANY_VALUE(customer.c_name), ANY_VALUE(customer.c_custkey), ANY_VALUE(orders.o_orderdate), ANY_VALUE(orders.o_totalprice), SUM(lineitem.l_quantity) 3 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey 4 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey 5 CTableScan | InputTable(0): orders | Pred: (TRUE PRED) 6 CTableScan | InputTable(1): customer | Pred: (TRUE PRED) 7 CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED) -
帶GroupJoin的執行計畫
1 Project | Exprs: temp_table4.ANY_VALUE(customer.c_name), temp_table4.ANY_VALUE(customer.c_custkey), temp_table4.orders.o_orderkey 2 GroupJoin | Grouping: orders.o_orderkey | JoinMode: INNER | JoinPred: orders.o_orderkey = lineitem.l_orderkey 3 HashJoin | HashMode: DYNAMIC | JoinMode: INNER | JoinPred: orders.o_custkey = customer.c_custkey 4 CTableScan | InputTable(0): orders | Pred: (TRUE PRED) 5 CTableScan | InputTable(1): customer | Pred: (TRUE PRED) 6 CTableScan | InputTable(2): lineitem | Pred: (TRUE PRED)
上面的等價推導,因為能減少GROUP BY的grouping keys的長度,因此針對常規的執行計畫,也是有用的。
Q20
TPCH Q20的關聯子查詢的pattern與Q17是類似的:採用MagicSet運算元的去關聯方式,在移除MagicSet運算元之前,會得到一個適合GroupJoin的中間態。
select
...
and ps_availqty > (
select
0.5 * sum(l_quantity) < ! --- scalar aggr --->
from
lineitem
where
l_partkey = ps_partkey < ! --- 關聯項 1 --->
and l_suppkey = ps_suppkey < ! --- 關聯項 2 --->
and l_shipdate >= '1993-01-01'
and l_shipdate < date_add('1993-01-01', interval '1' year)
)其他
按論文paper_1和paper_2所述,Q5/Q9/Q16/Q21這4條SQL都適用GroupJoin運算元,但是暫時還沒找到合適的轉換路徑;通過查詢hyper資料庫的執行計畫(https://hyper-db.de/interface.html#),它的最佳化器也沒有為這幾條SQL產生帶有GroupJoin的執行計畫。
相關實現
TPCH benchmark裡面的許多query都是JOIN+GROUP BY的模式,因此TPCH裡有不少的query都能通過GroupJoin最佳化掉。在論文paper_1裡,作者列出Q3/Q5/Q9/Q10/Q13/Q16/Q17/Q20/Q21這些query在使用GroupJoin與不使用GroupJoin兩種情況下的效能:
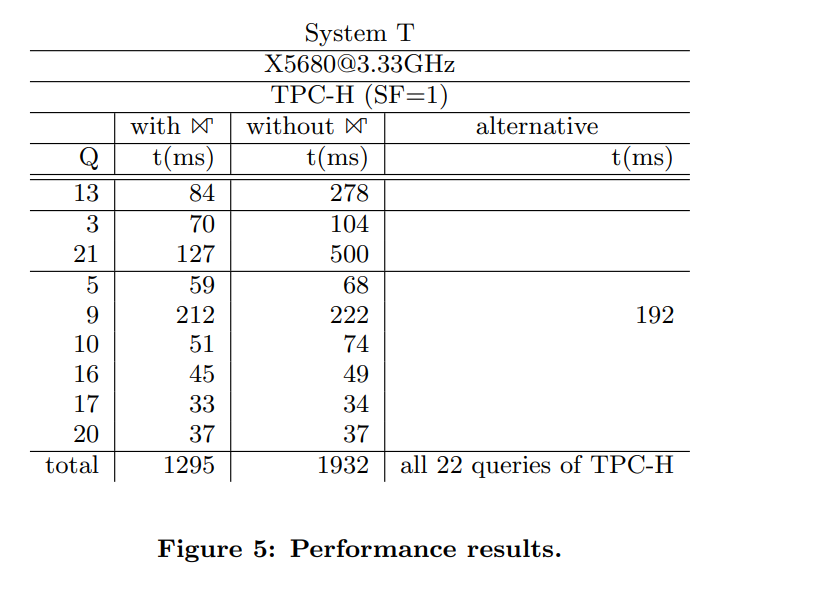
此處使用的是TPCH 1 GB的資料量。可以看出GroupJoin對最佳化TPCH類型query有一定的作用(總體時延1932ms降到1295ms)。
在論文paper_2中,則是分別列出了Q3/Q13/Q17/Q18這些query在使用GroupJoin與不使用GroupJoin幾種情況下的效能(TPCH 10 GB資料量):
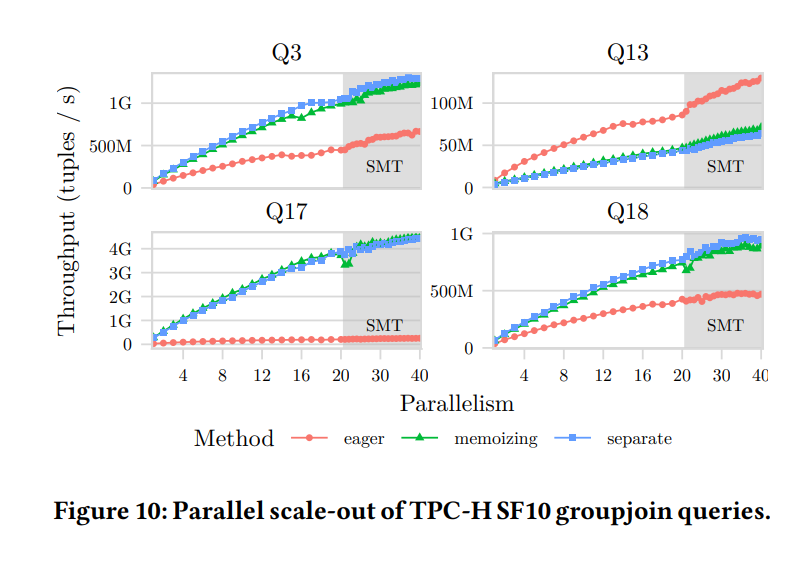
圖中的幾組線條含義如下:
-
圖中 “seperate”這一組線條代表“分別做JOIN和GROUP BY”,也就是不使用GroupJoin;
-
圖中“eager”代表上文所說的“eager aggregation”這一最佳化;
-
圖中“memoizing”代表上文所說的“如何處理並發查雜湊表做aggr運算時的衝突”這一最佳化。 可以看到,在 Q3/Q13/Q17/Q18 這4條query中:
-
"memoizing" 的方式幾乎總是與一般的HASH JOIN+HASH GROUP BY的方式有著類似的效能;
-
eaegr aggregation的方式只在Q13這一條query中佔有優勢,其餘都不佔優勢。
-
按照圖中的資料可得:不同的處理方法,在不同情境中差別很大。因此這個資料呼應了作者提出的 “GroupJoin 的執行方式,需要最佳化器提供更準確的統計資訊,以選擇最優的執行方式”這一觀點,而不是無差別地選擇某一種GroupJoin演算法,甚至無差別地選擇使用GroupJoin。
雖然如此,對於這個結論,PolarDB有不同的觀點:
-
文章中使用tuples per second這個指標來衡量演算法的好壞,但是與PolarDB IMCI中得到的結論卻不太一樣。使用IMCI在並發度=32的情況下測試Q3/Q13/Q18這3條query的GroupJoin運算元的throughput(單位tuples/s),結果如下:
Query
HashJoin+HashGroupby
GroupJoin
Q3
130 MB
152 MB
Q13
11 MB
33 MB
Q18
315 MB
1 GB
說明Q17在IMCI裡暫時無法使用GroupJoin。
這個測試資料與前述資料在量級上是相似的,但是每條query都稍有不同。也許是實現方式的不同,從PolarDB的測試資料中可以觀察到,除了上文說的right join+groupby right情況外,GroupJoin幾乎總是優於HashJoin+HashGroupby的。
-
對於上面3.a的結論,即“memoizing”的方式幾乎總是與一般的HASH JOIN+HASH GROUP BY的方式有著類似的效能,根據我們的觀察,TPCH的這幾條query只有非常少量的contention,因此memoizing的方式所用的local hash table等,在實際運行時基本不會用到,因此在這幾條query裡面,這個演算法得到的效能與HASH JOIN+HASH GROUP BY是類似的;論文裡引用這幾條query的效能作為對比,其實不說明問題。PolarDB是通過直接加鎖的方式來測試回合時的contention的。
總結
從效果來講,因為GroupJoin在運行時能避免的重複的工作,因此在某些情境能得到比較大的效能提升。這個效果已經在實際應用中得到驗證。因此從結果的角度,GroupJoin是值得實現的。
從通用性來講,GroupJoin並不通用。GroupJoin只適用於equal join+group by且要求grouping keys與任意一邊join keys相同,而且對aggr函數、實現方式等有諸多限制;這是一種特化,而隨之而來的是比較大的實現和維護代價。從開發的角度來說,應該花更大力氣去最佳化“通用路徑”,利用通用路徑的效能提升來達到最佳化SQL查詢效率的目的,而不是通過為某個情境尋求定製性的解法。因此從這個角度來說,GroupJoin不是一個好方法。
因此在實現的時候,應該做一定的裁剪或簡化,不追求在一個特化實現裡面實現最完備的功能,但是追求最常見情境的效用(效能)最大化。