PolarDB IMCI執行器預設用行號表示執行的中間結果,當大查詢所需資料量無法完全存放於記憶體時則可能會引發大量隨機且重複IO,從而影響執行效率。為瞭解決上述問題,IMCI執行器實現了基於中間結果物化的運算元集合,本文介紹了HashJoin運算元的物化版本HashMatch的實現細節。
設計方案
HashMatch實現主要分為build與probe兩個階段,其中build階段將左表每一行按join謂詞作為key構建出散列表,而probe階段則遍曆右表每一行並根據其對應的join謂詞尋找散列表,最終針對不同join類型依匹配結果輸出對應結果集。
對於build階段,可以將左表所有資料構建出一個散列表,但只用一個散列表存放全部資料會導致該散列表比較大,在構建過程中可能存在相對嚴重衝突和不斷擴容。為避免此問題,build階段可以將左表資料按一定規則進行分區,每一個分區各自構建獨立散列表,而probe階段則根據右表每一行所在分區尋找對應分區上的散列表進行相應處理。
Build階段
在IMCI中HashMatch的build功能是在DoOpen中完成,實際分為DoBuild與DoMerge兩階段,每一階段均採用線程組並發處理。
DoBuild
DoBuild階段線程組Workers各自向左表取資料,並按照資料分區Partition來構建每一分區的獨立散列表:
Worker\Partition | Partition0 | Partition1 | ... | PartitionN |
Worker0 | HashMap00 | HashMap01 | ... | HashMap0N |
Worker1 | HashMap10 | HashMap11 | ... | HashMap1N |
... | ... | ... | ... | ... |
WorkerM | HashMapM0 | HashMapM1 | ... | HashMapMN |
即每一個Worker在每一個Partition均構建一個散列表HashMap。其實除HashMap外,還儲存著一組chunk對象,其儲存物化後真正結果,而HashMap的uint64類型value只標記當前key所對應chunk位置,其中uint64按位分拆為uint16/uint16/uint32三部分,分別表示所屬Worker/chunk內位移/chunk數組索引等。 每一Worker並行從左表中取到元組,並按分區規則將該元組無須加鎖直接插入到該Worker和Partition所對應HashMap中,不斷重複該build步驟直到所有Worker取完左表為止。
DoMerge
DoBuild階段完成後,每一Worker在每一個Partition均構建出一張散列表HashMap。 Build階段構建出散列表主要用於Probe階段進行尋找判斷是否匹配,既然Build階段資料是按分區構建,那Probe階段也需要根據分區規則到指定分區的散列表中尋找。 而目前DoBuild構建出來的每一個分區均有Worker個散列表,當然Probe時可以依次尋找該Partition的所有Worker散列表,但為了後期Probe階段的便利性和尋找效能,HashMatch在DoBuild後進行DoMerge,即將每一Partition上所有Worker散列表合成一個散列表。
Build\Partition | Partition0 | Partition1 | ... | PartitionN |
Merge | HashMap0 | HashMap1 | ... | HashMapN |
DoMerge由線程組來完成,為了避免無意義鎖同步操作,採用每一線程獨自合并一個資料分割配置,由於Partition數目往往遠大於Worker數目,DoMerge階段各線程承擔工作量基本一致。
Build落盤
由於每一個Worker處理比較均衡,因此可以假設每個Worker處理資料量大致相同,直接將總記憶體均分值作為Worker記憶體配額。
限於記憶體容量,HashMatch並非總能將所有分區的HashMap與chunks維持在記憶體中,需要能夠按一定規則進行落盤。由於HashMap與chunks均按分區隔開,因此當記憶體不足時按分區落盤比較直觀。
當出現記憶體不足時,需要按一定規則將一些分區資料落盤,以便記憶體中分區能夠正常進行Build與Probe階段。目前HashMatch採用從最高分區開始整區落盤,直到能夠完成處理前面分區,若出現連一個分區均無法處理時則直接拋出OOM。
在DoBuild不斷構建的過程中,若當前Worker出現記憶體不足導致HashMap無法插入KV或不能儲存chunk資料時,需要將該Worker記憶體中編號最高分區的資料進行落盤,即將chunks集合按chunk寫入臨時檔案中並釋放chunks記憶體,同時直接刪除HashMap而不需要落盤,後面處理該分區時再從臨時檔案中載入chunks集合并通過chunks資料構建出該分區的HashMap。 對於一個Worker在記憶體中的最高分區號,其它Worker也是可見的。當一個Worker看到其它Worker的記憶體最高分區號比自己的小時,該Worker也會更新自己的最高分區號,並在適當時機進行記憶體釋放,在DoBuild階段也會不再構建大於最高分區號的分區中HashMap,但還是會將資料儲存到chunk中,當chunk滿後直接落盤。
Probe階段
Build階段讀取左表並構建出散列表,而Probe階段讀取右表資料後尋找散列表並根據匹配情況進行輸出, 既然Build階段已經將資料進行分區構建,那Probe階段也需要按Build階段所採用的資料分區規則來進行分區處理。
DoFetch
Probe階段同樣採用線程組處理方式,由父結點的Fetch操作來驅動。在DoFetch過程中,HashMatch的每個Worker同樣不斷fetch右表資料,對於fetch到的每一元組按分區規則到指定分區的HashMap中尋找,然後根據匹配情況進行處理,不斷重複該probe步驟直到所有Worker取完右表為止。
Probe落盤
若Build階段中記憶體無法儲存所有分區時,Probe階段也需要針對記憶體分區和磁碟分割進行分別處理。
在DoFetch過程中,當Worker取到右表資料後,若該元組對應的分區在記憶體中則直接尋找HashMap進行匹配處理,若該分區在磁碟中,則需要將該元組儲存到該Worker所屬Partition的chunk中,當該chunk滿時則需要刷盤並釋放chunk記憶體。當Worker取完右表並probe完成後,則表示記憶體中分區資料已經處理完成,可以釋放記憶體中所有分區。
當全部處理完記憶體中的分區後,開始處理磁碟中的分區,由於磁碟中分區的資料已經按分區儲存在不同臨時檔案中,為了避免鎖同步,probe階段仍採用一個磁碟分割由單獨Worker獨立完成,由於Partition數目往往遠大於Worker數目,因此一般不會存在Worker處理不均問題。
當Worker開始處理磁碟中分區時,主要也是分為build與probe兩階段:
build階段:先從該分區的臨時檔案中不斷讀取左表資料並序列化出chunk,然後根據左表chunk資料不斷構建HashMap,不斷重複該build步驟直到該Worker讀取完左表資料為止。
probe階段:從該分區的臨時檔案中不斷讀取右表資料並序列化出chunk,然後對其每一元組在該HashMap中尋找根據匹配情況進行處理,不斷重複該probe步驟直到該Worker讀取完右表資料為止。
當所有Worker處理完所有磁碟分割後則整個HashMatch結束。雖然文檔中按記憶體分區與磁碟分割進行不同處理說明,但實現時統一到了一套代碼中。
Probe流程
HashMatch中probe主要由ProbeMem、ProbeLeft與ProbeDisk等三個步驟組成,但其真正probe處理均由Probe函數完成:
ProbeMem用於從右表讀取資料並根據資料分區在記憶體或磁碟分別進行處理。若在記憶體中直接調用Probe處理,否則將資料儲存到臨時檔案,以便ProbeDisk處理指定磁碟分割時重新載入後再調用Probe處理。
ProbeLeft主要用於LeftOuter/LeftSemi/LeftAntiSemi等Left類型的Join,其遍曆整個HashMap所有KV並過濾出已匹配或未匹配過的元組。
ProbeDisk用於磁碟分割的probe操作,按分區來處理,處理指定磁碟分割時先從該分區的臨時檔案中載入chunk,然後直接調用Probe處理,若為Left類型的Join,還需要調用ProbeLeft對該分區進行處理。
Join邏輯
HashMatch實現Inner/LeftOuter/RightOuter/LeftSemi/LeftAntiSemi/RightSemi/RightAntiSemi及其PostFilter功能。所有join類型主體邏輯均可分為build與probe兩個階段,其中build階段基本相同(區別在於對null的處理),主要區別在於probe階段。在此只簡單描述不同join類型的處理邏輯。
Inner
對於右表每一元組,若該元組非null且匹配左表HashMap中元組則輸出該左表和右表元組。
LeftOuter
對於右表每一元組,若該元組非null且匹配左表HashMap中的元組,則輸出該左表和右表元組。 遍曆完右表後,對左表中所有均沒被匹配過的元組輸出該左表元組,而右表元組位置為null。 對於存在PostFilter的LeftOuter,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
RightOuter
對於右表每一元組,若該元組非null且匹配左表HashMap中元組則輸出該左表和右表元組,若不匹配則輸出右表元組,而左表元組位置置null。對於存在PostFilter的RightOuter,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
LeftSemi
LeftSemi流程類似LeftOuter,但其並不真正輸出左表和右表元組,而根據下面真值表輸出左表元組和NULL/TRUE/FALSE值,或僅輸出左表元組,或不輸出等。 對於存在PostFilter的LeftSemi,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
//+------------------------------+--------------+----------------+
//| mathched | semi_probe_ | ! semi_probe_ |
//+------------------------------+--------------+----------------+
//| normal true | (left, TRUE) | (left, ONLY) |
//+------------------------------+--------------+----------------+
//+------------------------------+--------------+----------------+
//| ! mathched | semi_probe_ | ! semi_probe_ |
//+------------------------------+--------------+----------------+
//|NULL v.s. (empty set) | | |
//|e.g., NULL IN (empty set) | (left, FALSE)| NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|NULL v.s. (set) | | |
//|e.g., NULL IN (1, 2, 3) | (left, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|left_row v.s. (set with NULL) | | |
//|e.g., 10 IN (1, NULL, 3) | (left, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|normal false | | |
//|e.g., 10 IN (1, 2, 3) | (left, FALSE)| NO_OUTPUT |
//+------------------------------+--------------+----------------+LeftAntiSemi
LeftAntiSemi流程類似LeftOuter,但其並不真正輸出左表和右表元組,而根據下面真值表僅輸出左表元組,或不輸出等。 對於存在PostFilter的LeftAntiSemi,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
//+------------------------------+----------------+
//| ! mathched | ! semi_probe_ |
//+------------------------------+----------------+
//|NULL v.s. (empty set) | |
//|e.g., NULL NOT IN (empty set) | (left, ONLY) |
//+------------------------------+----------------+
//|NULL v.s. (set) | |
//|e.g., NULL NOT IN (1, 2, 3) | (left, ONLY) |
//+------------------------------+----------------+
//|left_row v.s. (set with NULL) | |
//|e.g., 10 NOT IN (1, NULL, 3) | (left, ONLY) |
//+------------------------------+----------------+
//|normal false | |
//|e.g., 10 NOT IN (1, 2, 3) | (left, ONLY) |
//+------------------------------+----------------+RightSemi
RightSemi流程類似RightOuter,但其並不真正輸出左表和右表元組,根據下面真值表輸出右表元組和NULL/TRUE/FALSE值,或僅輸出右表元組,或不輸出等。 對於存在PostFilter的RightSemi,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
//+------------------------------+--------------+----------------+
//| mathched | semi_probe_ | ! semi_probe_ |
//+------------------------------+--------------+----------------+
//| normal true | (right, TRUE)| (right, ONLY) |
//+------------------------------+--------------+----------------+
//+------------------------------+--------------+----------------+
//| ! mathched | semi_probe_ | ! semi_probe_ |
//+------------------------------+--------------+----------------+
//|NULL v.s. (empty set) | | |
//|e.g., NULL IN (empty set) |(right, FALSE)| NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|NULL v.s. (set) | | |
//|e.g., NULL IN (1, 2, 3) |(right, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|left_row v.s. (set with NULL) | | |
//|e.g., 10 IN (1, NULL, 3) |(right, NULL) | NO_OUTPUT |
//+------------------------------+--------------+----------------+
//|normal false | | |
//|e.g., 10 IN (1, 2, 3) |(right, FALSE)| NO_OUTPUT |
//+------------------------------+--------------+----------------+RightAntiSemi
RightAntiSemi流程類似RightOuter,但其並不真正輸出左表和右表元組,而根據下面真值表僅輸出右表元組,或不輸出等。 對於存在PostFilter的RightAntiSemi,若匹配左表HashMap後還需要經過PostFilter來判斷其是否真正匹配。
//+------------------------------+----------------+
//| ! mathched | ! semi_probe_ |
//+------------------------------+----------------+
//|NULL v.s. (empty set) | |
//|e.g., NULL NOT IN (empty set) | (right, ONLY) |
//+------------------------------+----------------+
//|NULL v.s. (set) | |
//|e.g., NULL NOT IN (1, 2, 3) | (right, ONLY) |
//+------------------------------+----------------+
//|left_row v.s. (set with NULL) | |
//|e.g., 10 NOT IN (1, NULL, 3) | (right, ONLY) |
//+------------------------------+----------------+
//|normal false | |
//|e.g., 10 NOT IN (1, 2, 3) | (right, ONLY) |
//+------------------------------+----------------+實現
HashMatch將記憶體與磁碟處理、不同join類型與是否帶PostFilter功能均抽象為一套處理流程。
HashMap
HashMap為散列表實現,主要提供插入和尋找兩個介面:
size_t PutValue(uint64_t hash_code, const char *key_buf, uint64_t key_len, const uint64_t tuple);
ValueIterator FindValue(uint64_t hash_code, const char *key_data, const uint64_t key_len, const bool need_mark = false);同時提供兩個迭代器用於遍曆整張散列表:
enum IteratorType { Normal = 0, NoneMark = 1, Mark = 2, END };
class TableIterator {
public:
void Next();
bool IsValid() const { return valid_; }
ValueIterator GetIterator(IteratorType type);
private:
IteratorType type_ = IteratorType::END;
};
class ValueIterator {
struct Listener {
virtual void BlockEvent() {}
};
void SetListener(Listener *listener) { listener_ = listener; }
void Next();
bool IsValid() const { return valid_; }
private:
IteratorType type_ = IteratorType::Normal;
Listener *listener_ = nullptr;
};TableIterator迭代器用於遍曆HashMap的全部KV;而ValueIterator迭代器用於遍曆當前KV的全部資料區塊;其中TableIterator與ValueIterator均提供Normal/NoneMark/Mark三種迭代模型,用於不同join類型。
由於TableIterator用於遍曆全部HashMap,其主要用於LEFT_OUTER/LEFT_ANTI_SEMI/LEFT_SEMI等。
Info
HMInfo主要用於存放所有Worker共用全域資料,如記憶體分區號與分區對象,其中分區中儲存當前分區合并後的HashMap、左右表chunks集合與左右表臨時檔案對象。每一個分區HMPartition均有單獨臨時檔案,通過pread/pwrite函數與offset原子變數來提供給所有Worker進行原子讀寫操作。
Local Info
HMLocalInfo主要用於存放當前Worker的私人資料,如當前Worker的記憶體分區號與左右分區對象HMLocalPartitions,其中每一分區對象HMLocalPartition儲存當前Worker當前Partition的HashMap、chunks集合與正在寫待完整的chunk對象等。
Fetcher
HashMatch存在向左表取資料、右表取資料、從Info/LocalInfo記憶體chunks集合中讀取chunk對象、從臨時檔案中讀取並序列化出chunk對象等多種不同fetch方式,雖然方式各異但其fetch資料均為chunk對象,其用於Build與Probe階段。
class HashMatchFetcher final {
bool Fetch(Context &context, TupleChunk *&mat_chunk);
// fetch from left or right child
bool FetchMem(Context &context);
// fetch from info chunks (include load from temp files)
bool FetchDisk(Context &context, TupleChunk *&mat_chunk);
size_t part_index_ = 0;
TupleChunk chunk_;
};Builder
Builder類用於Build階段DoBuild操作,統一處理記憶體分區與磁碟分割的build功能。
左表構建(MemBuilder類):從左表中fetch到資料儲存到chunks集合中,若該元組屬於記憶體分區的則插入HashMap,屬於磁碟分割則將chunk資料落盤。
磁碟構建(DiskBuilder類):從暫存資料表中讀取chunks集合,並構建該分區的HashMap。
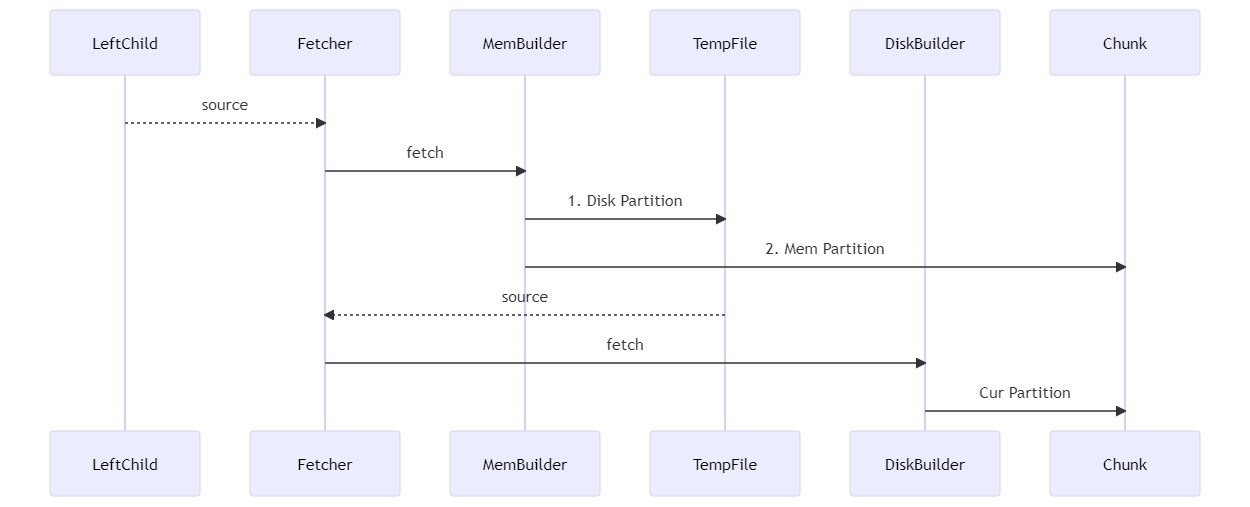
class HashMatchBuilder {
void Build();
virtual void ChunkResult(const size_t offset, const bool is_null,
const size_t part_index, const uint64_t hash_val,
const char *key_data, const size_t key_len) = 0;
virtual void ChunkDone() = 0;
HashMatchFetcher fetcher_;
};
class HashMatchMemBuilder final : public HashMatchBuilder {
void ChunkResult(const size_t offset, const bool is_null,
const size_t part_index, const uint64_t hash_val,
const char *key_data, const size_t key_len) override;
void ChunkDone() override;
TupleChunk origin_chunk_;
};
class HashMatchDiskBuilder final : public HashMatchBuilder {
void ChunkResult(const size_t offset, const bool is_null,
const size_t part_index, const uint64_t hash_val,
const char *key_data, const size_t key_len) override;
void ChunkDone() override;
const size_t part_index_ = 0;
};Prober
Probe階段ProbeMem/ProbeLeft/ProbeDisk操作均由Prober類完成,其統一處理記憶體分區與磁碟分割的probe功能。
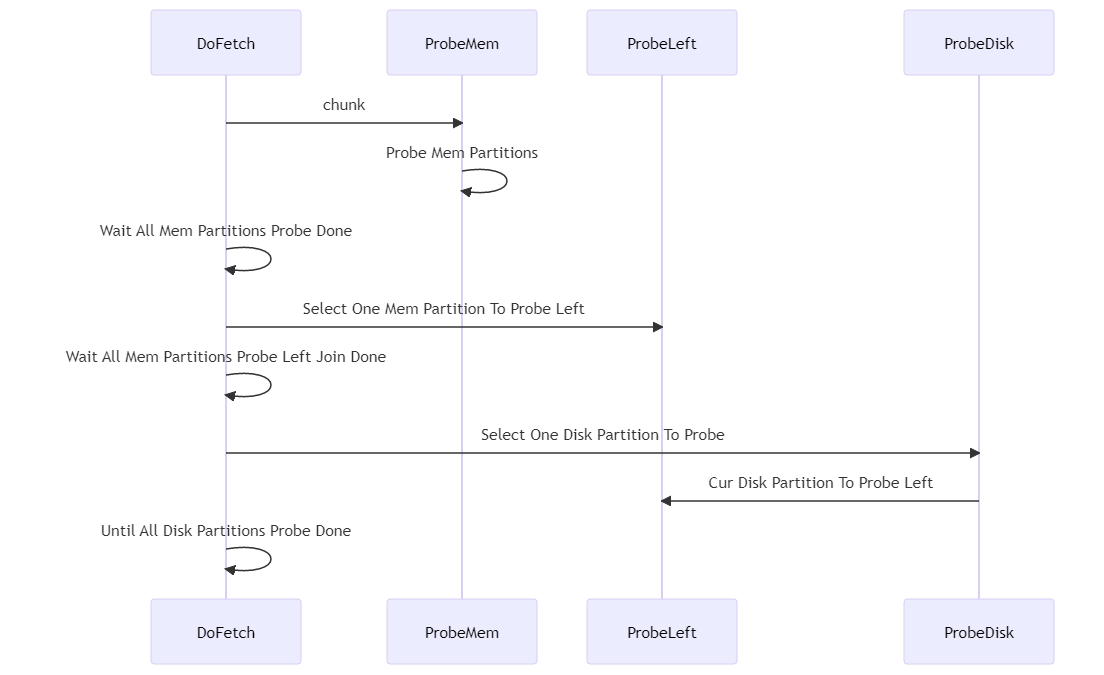
class HashMatchProber final {
public:
void ProbeResult(TupleChunk *tpchunk, size_t &chunk_off, const size_t chunk_size);
bool ProbeIter(Context &context, TupleChunk *tpchunk, size_t &chunk_off, const size_t chunk_size);
bool Probe(Context &context, TupleChunk *tpchunk, size_t &chunk_off, const size_t chunk_size, const bool disk);
private:
const HashMatch &join_;
HMInfo *info_ = nullptr;
HMLocalInfo *local_info_ = nullptr;
size_t part_index_ = 0;
PostFilter filter_;
LeftIterator lit_;
RightIterator rit_;
TraverseIterator tit_; // used for probe left
};HashMatchProber::PostFilter類主要對帶PostFilter的Join類型的Probe後期進行處理,即經過Probe得到結果集還需要再由PostFilter處理後才能確定其是否真正匹配。
struct PostFilter final {
bool Evaluate();
bool Probe(TupleChunk *tpchunk, size_t &chunk_off, const size_t chunk_size);
const HashMatchProber &prober_;
const RTExprTreePtr &post_expr_;
const HashMatchExpr &left_expr_;
const HashMatchExpr &right_expr_;
std::shared_ptr<Expressions::ExprEnv> post_env_ = nullptr;
};Prober提供LeftIterator/RightIterator/TraverseIterator等三種類型迭代器。
struct Iterator {
virtual void InitExpr() {}
virtual void FiniExpr() {}
virtual void Init(const size_t part_index);
virtual void Fini();
virtual bool Valid(Context &context) { return false; }
virtual void Next() = 0;
HashMatchProber &prober_;
PostFilter &filter_;
};HashMatchProber::LeftIterator類使用HashMap::ValueIterator來遍曆HashMap指定key的所有value並根據value定位到指定chunk元組,即對外提供指定key的所有元組功能,統一處理不同join類型和PostFilter功能。
// for Probe
struct LeftIterator final : public Iterator, public ValueIterator::Listener {
void BlockEvent() override;
bool Valid(Context &context) override;
void Next() override;
bool Find(const size_t part_index, const uint64_t hash_val,
const char *key_data, const uint64_t key_len);
ValueIterator it_;
};HashMatchProber::RightIterator類不斷使用HashMatchFetcher從右表或臨時檔案中擷取chunk集合并對外提供遍曆所有chunk所有元組的功能。 所有類型Join均由ProbeMem/ProbeDisk使用RightIterator擷取chunk,然後在該分區中尋找HashMap,若找到則構造LeftIterator對象來遍曆該key的所有元組,另外Left類型Join還需要ProbeLeft處理。
// for Probe
struct RightIterator : public Iterator {
bool Valid(Context &context) override;
void Next() override;
HashMatchFetcher fetcher_;
TupleChunk origin_chunk_;
size_t chunk_size_ = 0;
};HashMatchProber::TraverseIterator類主要用於Left類型Join,如LeftOuter/LeftSemi/LeftAntiSemi等,其使用HashMap::TableIterator遍曆整個HashMap並過濾出已匹配或未匹配的key,然後使用LeftIterator來遍曆該key的所有元組。 Left類型Join處理流程是先使用ProbeMem/ProbeDisk尋找HashMap並進行匹配處理,若匹配則在HashMap中標記該KV,然後由ProbeLeft來使用TraverseIterator來整個HashMap並過濾出已匹配或未匹配的KV處理即可。
// for ProbeLeft
struct TraverseIterator final : public Iterator {
bool Valid(Context &context) override;
void Next() override;
TableIterator tit_;
LeftIterator lit_;
IteratorType it_type_ = IteratorType::END;
};測試
在TPC-H,1 TB資料集,Q14上對比HashJoin與HashMatch的效能,其中HashJoin演算法與HashMatch基本一致,主要區分在於中間結果是否物化。
select
100.00 * sum(case
when p_type like 'PROMO%'
then l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from
lineitem,
part
where
l_partkey = p_partkey
and l_shipdate >= date '1995-09-01'
and l_shipdate < date '1995-09-01' + interval '1' month;在LRU緩衝與執行器記憶體均為100 GB配置下進行查詢:
Query(TPCH1T)
HashJoin
HashMatch
Q14
23.96秒
12.56秒
在LRU緩衝與執行器記憶體均為32 GB配置下進行查詢:
Query(TPCH1T)
HashJoin
HashMatch
Q14
>10分
35.73秒