概述
阿里雲 OpenLake 是一款面向巨量資料、搜尋與人工智慧一體化情境的新一代開放湖倉平台。該平台基於資料湖形成(Data Lake Formation,DLF)構建統一的中繼資料目錄,融合了結構化、半結構化、非結構化及向量資料,實現了“一份資料、多引擎協同、全域檢索、全鏈路治理”的 Agentic Data 架構。
OpenLake 支援 Paimon、Iceberg、Lance 等主流開放表格式,打通了從資料入湖、特徵工程、向量化、檢索增強到大模型訓練與推理的完整閉環,為企業提供高效能、低成本、高可用、易治理的多模態資料基礎設施。
該平台適用於互連網、金融、零售、製造、教育、自動駕駛等需要處理多模態資料並構建人工智慧原生應用的企業。

產品優勢
開放標準,打破資料孤島
全面相容 Paimon、Iceberg、Lance 等開源表格式,支援 Parquet、ORC、Avro、CSV 等開放檔案標準。
無縫對接 Spark、Flink、Trino、StarRocks、Hologres、MaxCompute 等主Realtime Compute引擎,避免資料移轉與格式轉換成本。
基於 DLF Omni Catalog 實現五類資料(結構化、半結構化、非結構化、向量、流式)統一編目,真正實現“一次入湖、多處可用”。
高效能引擎協同,計算高效
多引擎(Spark/Flink/StarRocks/Hologres/MaxCompute)平權訪問同一份湖資料,無需冗餘拷貝。
通過 DLF 統一中繼資料服務,實現跨引擎 許可權一致、Schema 同步、事務隔離。
批處理、Realtime Compute、互動式查詢與 AI 訓練共用儲存,顯著提升資源使用率與端到端效率。
支援高並發、低延遲混合負載,滿足 T+1 批處理與秒級即時分析並存情境。
統一開發治理,降低複雜度
通過 OpenLake Studio(整合於 DataWorks)提供 Notebook + SQL IDE + 可視化調度 一體化開發體驗。
中繼資料、資料許可權、血緣追蹤、任務編排、品質監控集中管理,實現“開發即治理”。
支援大規模、高並發任務調度,保障企業級 SLA 與穩定性。
全鏈路可追溯、可審計、可復原,滿足合規要求。
Data + Search + AI 融合,釋放資料價值
融合結構化表、非結構化檔案(映像/音視頻/文檔)與向量資料,構建多模態統一湖倉。
原生支援 SQL 查詢、全文檢索索引(OpenSearch/Elasticsearch)與向量相似性搜尋(Milvus/PgVector)。
為大模型 RAG、智能 Agent 提供高品質、可檢索、可治理的資料供給管道。
打通“資料入湖 → 特徵工程 → 向量化 → 檢索增強 → 模型推理”全鏈路,加速 AI 應用落地。
核心功能
功能 | 說明 | 文檔連結 |
統一中繼資料與表管理 | 通過 DLF 支援 Paimon/Iceberg/Lance/Parquet 等格式的統一目錄 | |
儲存成本最佳化 | 基於 OSS 智能分層、壓縮與生命週期策略,降低儲存成本 | |
即時湖流一體 | Flink + Fluss + DLF 實現秒級入湖、分鐘級可見 | |
企業級高效能引擎 | 整合 Serverless Spark、Flink、Hologres、MaxCompute 等雲原生引擎 | 什麼是EMR Serverless Spark、什麼是阿里雲Realtime ComputeFlink版、什麼是即時數倉Hologres、什麼是MaxCompute |
巨量資料 & AI 協同開發 | OpenLake Studio 融合 Notebook、SQL 與可視化調度 | |
Agent & Copilot 整合 | OpenLake Agent / MCP 協議支援多模態智能體直接存取湖倉 |
典型架構方案
方案一:經典湖倉架構(Serverless Spark + StarRocks + DLF)
適用情境:T+1批處理為主,旨在實現高性價比和免營運的離線分析情境(例如報表、商業智慧、使用者畫像)。
組件:EMR Serverless Spark(批處理) + StarRocks(亞秒級查詢) + DLF(統一中繼資料)。
替代方案:AWS Redshift + Glue、Databricks(批處理)、Hive + Presto。
優勢:成本降低 30%+,查詢效能提升 3–5 倍,免營運。
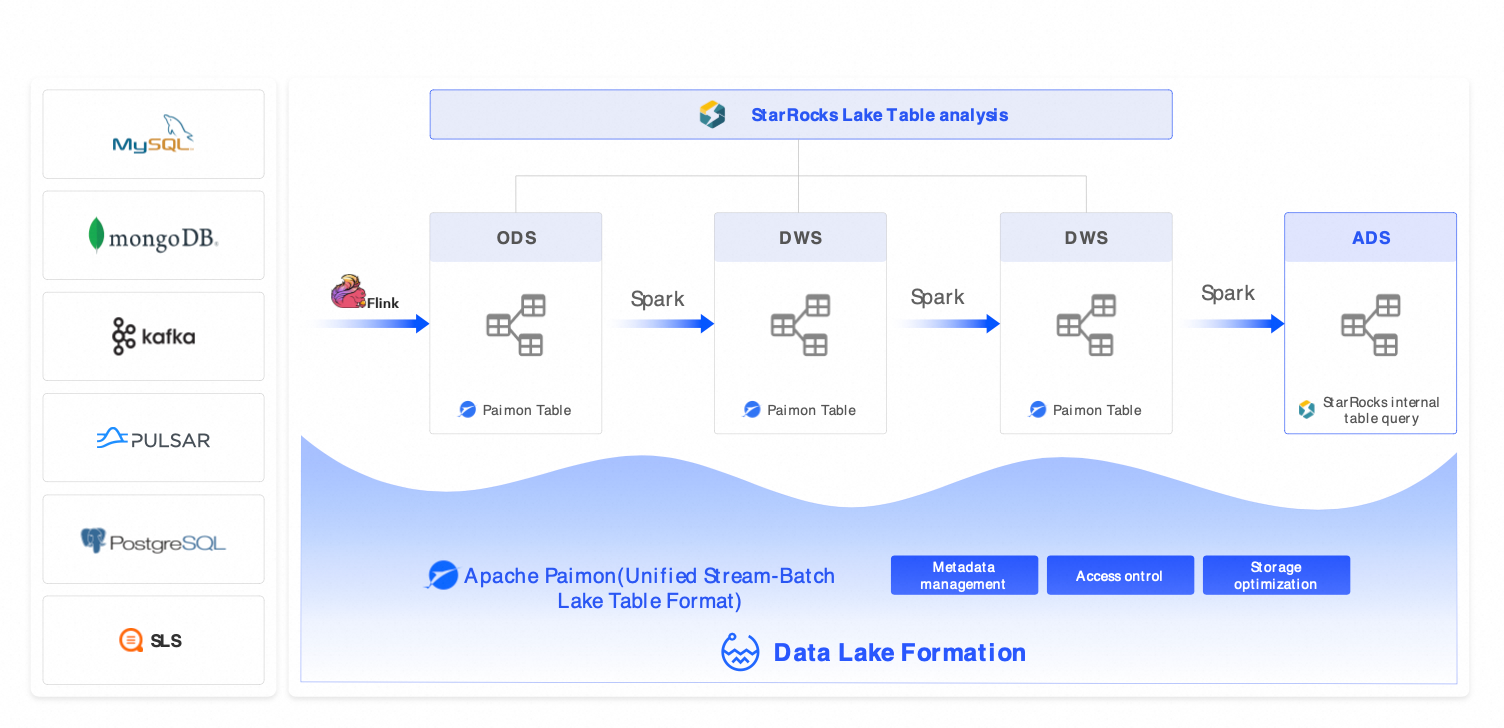
方案二:流式湖倉架構(Flink + Hologres + DLF)
適用情境:秒級~分鐘級近即時分析(如即時風控、投放效果監控、IoT 裝置監控)。
組件:Flink(流式 ETL) + Hologres(即時 Serving) + DLF(跨引擎協同)。
替代方案:Kafka + ClickHouse + Hive、AWS Kinesis + Redshift。
優勢:端到端資料 10 分鐘可見,查詢延遲 < 1 秒。

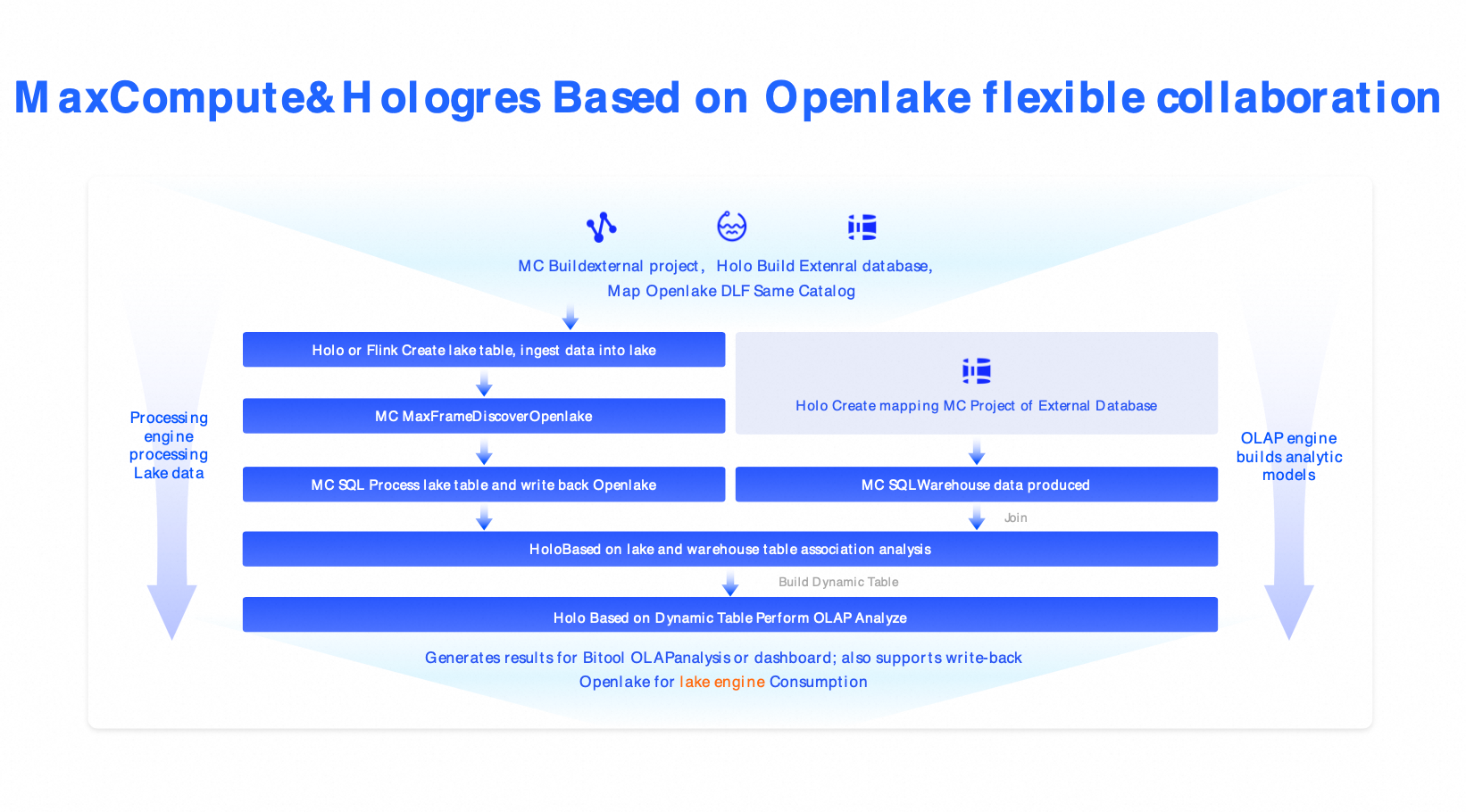
方案三:雲原生湖倉架構(MaxCompute + Hologres + DLF)
適用情境:金融、政務等領域對安全、合規及大規模處理具有嚴格要求。
組件:MaxCompute(PB 級批處理) + Hologres(毫秒寫入) + DLF(治理)。
替代方案:Snowflake、Azure Synapse、Databricks 商業版。
優勢:企業級安全、Auto Scaling、RPO=0、RTO<30 分鐘。
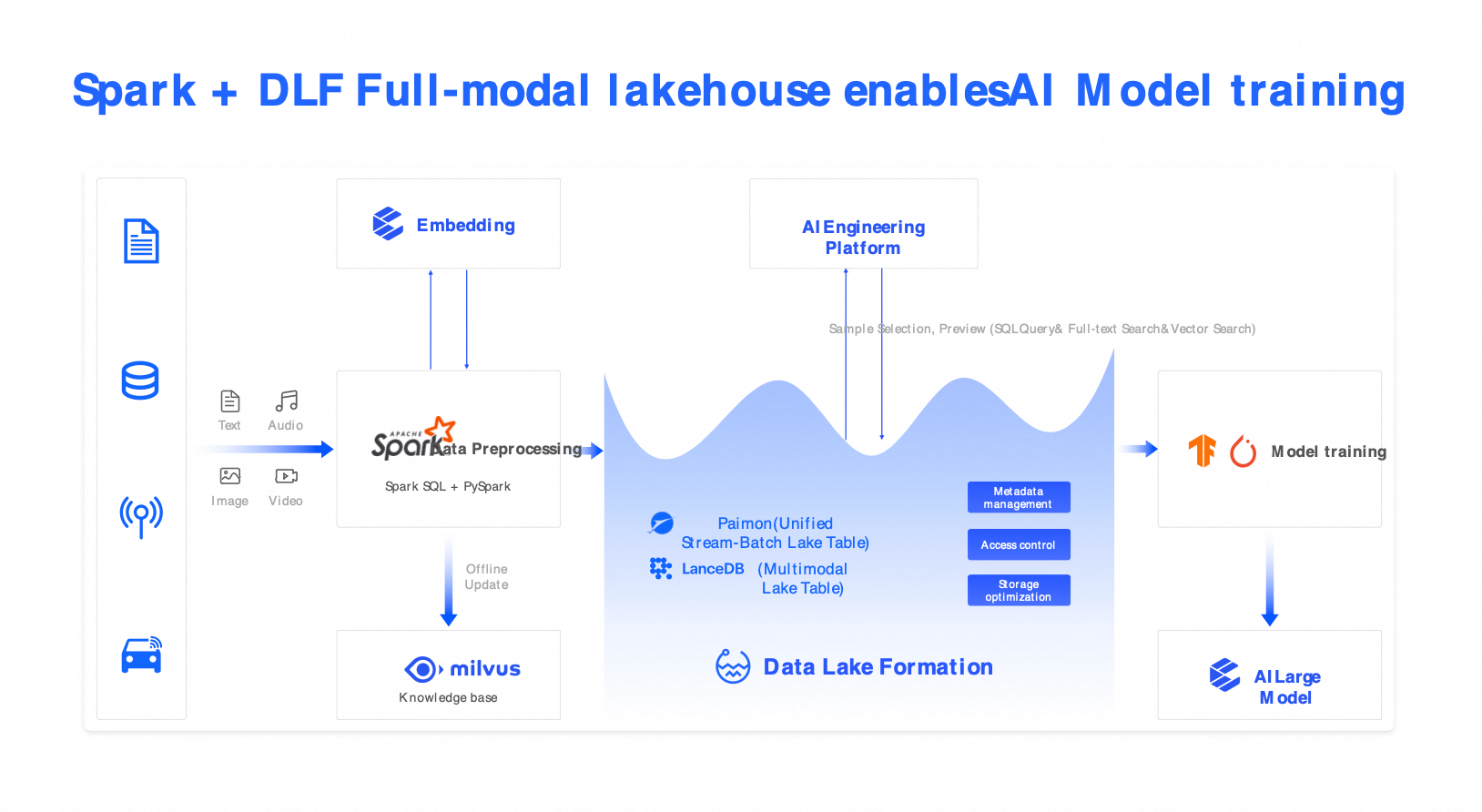
方案四:全模態向量湖(Spark + Milvus + DLF)
適用情境:AI 訓練、多模態語義檢索、RAG 應用、智能客服、自動駕駛感知資料管理等。
組件:Spark(多模態預先處理) + Milvus(向量檢索) + DLF(統一編目)。
能力:支援文本、映像、音頻及視頻的混合檢索,採用SQL與向量聯集查詢的方式。
優勢:樣本篩選效率提升 5 倍,支援大模型高品質微調。
適用情境:AI 訓練、多模態語義檢索、RAG 應用、智能客服、自動駕駛感知資料管理等。