本文以Qwen3-32B模型為例,示範如何在ACK中部署SGLang PD分離推理引擎的模型推理服務。
背景知識
Qwen3-32B
Qwen3-32B 是通義千問系列最新一代的大型語言模型,基於328億參數的密集模型架構,兼具卓越的推理能力與高效的對話效能。其最大特色在於支援思考模式與非思考模式的無縫切換。在複雜邏輯推理、數學計算和代碼產生任務中表現出眾,而在日常對話情境下也可高效響應。模型具備出色的指令遵循、多輪對話、角色扮演和創意寫作能力,並在Agent任務中實現領先的工具調用表現。原生支援32K上下文,結合YaRN技術可擴充至131K。同時,支援100多種語言,具備強大的多語言理解與翻譯能力,適用於全球化應用情境。有關更多詳細資料,請參閱部落格、GitHub和文檔。
SGLang
SGLang 是一個高效能的大型語言模型與多模態模型服務推理引擎,通過前後端協同設計,提升模型互動速度與控制能力。其後端支援 RadixAttention(首碼緩衝)、零開銷 CPU 調度、PD分離、Speculative decoding、連續批處理、PagedAttention、TP/DP/PP/EP並行、結構化輸出、chunked prefill及多種量化技術(FP8/INT4/AWQ/GPTQ)和多LoRA批處理,顯著提升推理效率。前端提供靈活編程介面,支援鏈式產生、進階提示、控制流程、多模態輸入、平行處理和外部互動,便於構建複雜應用。支援 Qwen、DeepSeek、Llama等產生模型,E5-Mistral等嵌入模型以及 Skywork 等獎勵模型,易於擴充新模型。更多關於SGLang推理引擎的資訊,請參見SGLang GitHub。
PD分離
Prefill/Decode分離架構,是當前主流的LLM推理最佳化技術,旨在解決推理過程中兩個核心階段的資源需求衝突問題。LLM的推理過程可分為兩個階段:
Prefill (提示詞處理) 階段:此階段一次性處理使用者輸入的全部提示詞(Prompt),並行計算所有輸入Token的注意力,並產生初始的KV緩衝。這個過程是計算密集型(Compute-Bound)的,需要強大的並行計算能力,但只在請求開始時執行一次。
Decode (解碼產生) 階段:此階段是自迴歸過程,模型根據已有的KV緩衝,逐個產生新的Token。每一步的計算量很小,但需要反覆、快速地從顯存中載入巨大的模型權重和KV緩衝,因此是記憶體頻寬密集型(Memory-Bound)的。
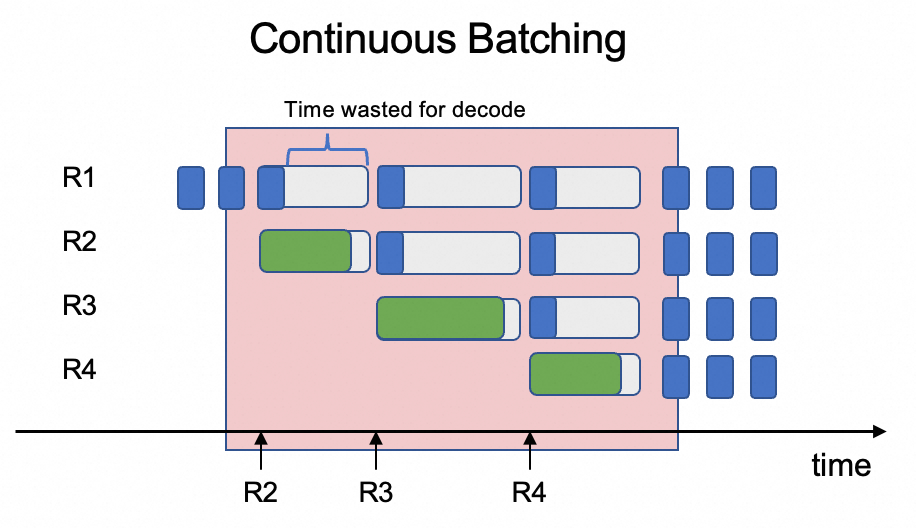
核心矛盾在於將這兩種特性迥異的任務混合在同一GPU上調度,效率極低。推理引擎在處理多個使用者請求時往往會採用連續批處理(Continuous Batching)的方式,將不同請求的Prefill階段和Decode階段放在一個批次裡調度。由於Prefill階段需處理完整提示詞(計算複雜度高),而Decode階段僅需產生單token(計算複雜度低),若在同一批次中調度,Decode階段會因序列長度差異與資源競爭導致時延增加,進而增加系統整體延遲並降低輸送量。

PD分離架構的解決方案就是將這兩個階段解耦,將Prefill和Decode階段分開部署在不同GPU上。通過這種分離,系統可以針對Prefill和Decode不同特徵進行最佳化,避免資源爭搶,從而顯著降低產生每個輸出 token 的平均時間(TPOT),提升系統吞吐。
RoleBasedGroup
RoleBasedGroup(RBG)是阿里雲Container Service團隊設計的一種新的工作負載,為瞭解決PD分離架構在Kubernetes叢集中大規模部署及營運的難題。該專案已開源,更多資訊請查看RBG Github。
RBG API設計如下圖所示,它由一組Role構成一個Group整體,每個Role可以基於StatefulSet/Deployment/LWS構建。其核心特性如下:
靈活的多角色定義:RBG支援定義任意數量任意名稱的Role;支援定義Role間的依賴關係,可以按指定順序啟動Role;可以按照Role維度彈性擴縮容。
Runtime:具備Group內部的自動服務發現能力;支援多種重啟策略;支援變換;支援Gang調度。

前提條件
已建立ACK叢集且叢集版本為1.22及以上,並且已經為叢集添加GPU節點。具體操作,請參見建立ACK託管叢集和為叢集添加GPU節點。
本文要求叢集中GPU卡>=6, 單個GPU卡顯存>=32GB。由於SGLang PD分離架構依賴GPU Direct RDMA(GDR)進行資料轉送,所選擇節點規格需支援彈性RDMA(eRDMA),推薦使用ecs.ebmgn8is.32xlarge規格,更多規格資訊可參考ECS Bare Metal Instance規格。
節點作業系統鏡像選擇:彈性RDMA的使用需要相關軟體棧支援,因此在建立節點池時,推薦在作業系統-雲市場鏡像中選擇Alibaba Cloud Linux 3 64位 (預裝eRDMA軟體棧)作業系統鏡像。具體操作,請參見在ACK中添加eRDMA節點。
已安裝ack eRDMA Controller組件,具體操作參見使用eRDMA加速容器網路,在叢集中安裝並配置ACK eRDMA Controller組件。
已安裝ack-rbgs組件。組件安裝步驟如下。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。單擊目的地組群名稱,進入叢集詳情頁面,使用Helm為目的地組群安裝ack-rbgs組件。您無需為組件配置應用程式名稱和命名空間,單擊下一步後會出現一個請確認的彈框,單擊是,即可使用預設的應用程式名稱(ack-rbgs)和命名空間(rbgs-system)。然後選擇Chart 版本為最新版本,單擊確定即可完成ack-rbgs組件的安裝。
模型部署
部署PD分離架構推理服務。SGLang Prefill Server和Decode Server互動時序圖如下所示。
收到使用者推理請求後,Prefill Server將會建立一個Sender對象而Decode Server會建立一個Receiver對象。
Prefill和Decode通過Handshake建立串連,Decode首先分配一塊顯存地址用於接收KVCache,Prefill Server完成計算後將KVCache傳送給Decode Server,Decode Server收到KVCache後繼續計算後續Token,直到完成使用者的推理請求。

步驟一:準備Qwen3-32B模型檔案
執行以下命令從ModelScope下載Qwen-32B模型。
請確認是否已安裝git-lfs外掛程式,如未安裝可執行
yum install git-lfs或者apt-get install git-lfs安裝。更多的安裝方式,請參見安裝git-lfs。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pull登入OSS控制台,查看並記錄已建立的Bucket名稱。如何建立Bucket,請參見建立儲存空間。在OSS中建立目錄,將模型上傳至OSS。
關於ossutil工具的安裝和使用方法,請參見安裝ossutil。
ossutil mkdir oss://<your-bucket-name>/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://<your-bucket-name>/Qwen3-32B建立PV和PVC。為目的地組群配置名為
llm-model的儲存卷PV和儲存聲明PVC。具體操作,請參見建立PV和PVC。控制台操作樣本
建立PV。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在儲存卷頁面,單擊右上方的建立。
在建立儲存卷對話方塊中配置參數。
以下為樣本PV的基本配置資訊:
配置項
說明
儲存卷類型
OSS
名稱
llm-model
訪問認證
配置用於訪問OSS的AccessKey ID和AccessKey Secret。
Bucket ID
選擇上一步所建立的OSS Bucket。
OSS Path
選擇模型所在的路徑,如
/Qwen3-32B。
建立PVC。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在儲存聲明頁面,單擊右上方的建立。
在建立儲存聲明頁面中,填寫介面參數。
以下為樣本PVC的基本配置資訊:
配置項
說明
儲存宣告類型
OSS
名稱
llm-model
分配模式
選擇已有儲存卷。
已有儲存卷
單擊選擇已有儲存卷連結,選擇已建立的儲存卷PV。
kubectl操作樣本
建立
llm-model.yaml檔案,該YAML檔案包含Secret、靜態卷PV、靜態卷PVC等配置,樣本YAML檔案如下所示。apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # 配置用於訪問OSS的AccessKey ID akSecret: <your-oss-sk> # 配置用於訪問OSS的AccessKey Secret --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # bucket名稱 url: <your-bucket-endpoint> # Endpoint資訊,如oss-cn-hangzhou-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # 本樣本中為/Qwen3-32B/ --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model建立Secret、建立靜態卷PV、建立靜態卷PVC。
kubectl create -f llm-model.yaml
步驟二:部署SGLang PD分離架構的推理服務
本文使用RBG部署2P1D SGLang推理服務,部署架構圖如下所示。

建立
sglang_pd.yaml檔案。部署SGLang PD分離推理服務。
kubectl create -f sglang_pd.yaml
步驟三:驗證推理服務
執行以下命令,在推理服務與本地環境之間建立連接埠轉寄。
重要kubectl port-forward建立的連接埠轉寄不具備生產層級的可靠性、安全性和擴充性,因此僅適用於開發和調試目的,不適合在生產環境使用。更多關於Kubernetes叢集內生產可用的網路方案的資訊,請參見Ingress管理。kubectl port-forward svc/sglang-pd 8000:8000預期輸出:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000執行以下命令,向模型推理服務發送了一條樣本的模型推理請求。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "測試一下"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'預期輸出:
{"id":"29f3fdac693540bfa7808fc1a8701758","object":"chat.completion","created":1753695366,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n好的,使用者讓我測試一下,我需要先確認他們的具體需求。可能他們想測試我的功能,比如回答問題、產生內容","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"length","matched_stop":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null}}輸出結果表明模型可以根據給定的輸入(在這個例子中是一條測試訊息)產生相應的回複。
相關文檔
為LLM推理服務配置Prometheus Dashboard監控
在生產環境中,LLM推理服務的可觀測性是系統穩定性的核心保障,開源推理引擎通過整合Prometheus Dashboard實現故障的主動發現與精準定位。
LLM 模型通常包含超過10GB的權重檔案,從儲存服務(如 OSS、NAS 等)拉取這些大檔案時,容易因長時間延遲和冷啟動問題影響效能。Fluid 通過在 Kubernetes 叢集節點上構建分布式檔案快取系統,整合多個節點的儲存與頻寬資源;同時,它從應用程式端最佳化模型檔案的讀取機制,從而顯著加速模型載入過程。
配置ACK Gateway with Inference Extension網關實現智能路由
ACK Gateway with Inference Extension 是基於 Kubernetes 社區 Gateway API 及其 Inference Extension 規範構建的增強型組件,支援 Kubernetes 四層和七層路由服務,同時針對產生式 AI 推理情境提供了一系列最佳化能力。該組件能夠簡化 AI 推理服務的管理流程,並提升多推理服務工作負載間的負載平衡效能。其關鍵特性包括:
模型感知的推理負載平衡:提供最佳化的負載平衡策略,確保推理請求高效分發。
基於 OpenAI API 規範的模型路由:根據模型名稱對推理請求進行智能路由,支援對同一基本模型的不同 LoRA 模型進行流量灰階管理。
模型關鍵性優先順序配置:通過為不同模型設定關鍵性等級,實現請求的差異化優先順序處理,確保高優先順序模型的服務品質。