在生產環境中LLM推理服務的可觀測性是至關重要的,可以監控LLM推理服務、推理服務Pod及相關GPU的效能指標,有效發現效能瓶頸,協助定位故障。本文介紹如何為LLM推理服務配置監控。
前提條件
已為ACK開啟阿里雲Prometheus監控。具體操作,請參考使用阿里雲Prometheus監控。
計費說明
LLM推理服務將監控資料接入阿里雲Prometheus監控功能後,相關組件會自動將監控指標發送至阿里雲Prometheus服務,這些指標將被視為自訂指標。
使用自訂指標會產生額外的費用。這些費用將根據您的叢集規模、應用數量和資料量等因素產生變動,您可以通過用量查詢,監控和管理您的資源使用方式。
步驟一:接入LLM推理服務監控大盤
登入ARMS控制台。
在左側導覽列單擊接入中心,然後在人工智慧地區單擊雲原生AI套件-LLM推理服務卡片。
在雲原生AI套件-LLM推理服務頁面的選擇Container Service叢集地區,選擇目的地組群。
若顯示已經安裝該組件,則無需再重複安裝。
在配置資訊地區配置參數,然後單擊確定,完成組件接入。
配置項
說明
接入名稱
當前LLM推理服務監控唯一名稱。非必填,可留空。
命名空間
當前LLM推理服務監控僅採集哪些命名空間下的指標。非必填,留空時表示採集所有命名空間下滿足條件。
Pod 連接埠名
LLM推理服務Pod上標識的連接埠名,將嘗試從該連接埠上採集推理服務監控指標。預設值為"http"。
指標採集路徑
LLM推理服務Pod暴露Prometheus格式指標的HTTP服務路徑。預設值為“/metrics”。
metrics採集間隔
監控資料擷取時間間隔(秒)。
已接入的組件可在ARMS控制台的接入管理頁面查看。
接入中心的更多資訊,請參見接入指南。
步驟二:部署推理服務並開啟指標採集
在需要採集指標的LLM推理服務Pod上增加以下標籤,將該推理服務Pod加入到ARMS指標採集目標列表中:
...
spec:
template:
metadata:
labels:
alibabacloud.com/inference-workload: <workload_name>
alibabacloud.com/inference-backend: <backend>變數 | 用途 | 說明 |
<workload_name> | 用於唯一標識一個命名空間下的一個推理服務。 | 推薦選擇部署推理服務時使用的工作負載(例如:StatefulSet、LeaderWorkerSet、RoleBasedGroup)的名字作為<workload_name>。當Pod包含 |
<backend> | 用於標識推理引擎。 | 需要根據實際使用的推理引擎填寫。目前該欄位支援的值包括:
|
上述樣本僅展示了為LLM推理服務Pod開啟指標採集時的部分程式碼片段,如果需要瞭解如何部署不同的LLM推理服務的完整樣本,請參見:
步驟三:查看推理服務監控大盤
登入Container Service管理主控台,在左側導覽列單擊叢集。
在叢集列表頁面,單擊已接入雲原生AI套件-LLM推理服務元件的ACK叢集或ACS叢集,然後在左側導覽列,選擇營運管理 > Prometheus 監控。
在Prometheus監控頁面,選擇其他 > LLM Inference Dashboard,查看LLM推理服務監控大盤的詳情資料。在LLM推理服務監控大盤中,您可以查看有關叢集中啟動並執行LLM推理服務的詳情資料。
調整監控大盤的變數,可以選擇需要查看的LLM推理服務的命名空間(
namespace)、負載名稱(workload_name)和該推理服務使用的模型名稱(model_name)。如果需要瞭解大盤中各個Panel的含義,請參考監控面板說明。
監控指標說明
LLM推理服務採集的指標主要包括:
監控面板說明
LLM推理服務監控大盤假設使用者使用一個Kubernetes工作負載(workload)部署一個推理服務,一個推理服務中包含多個推理服務執行個體(一個執行個體可能由一個Pod或多個Pod構成),一個推理服務執行個體同時可對外提供一個模型或多個模型(例如:基於基本模型+Lora的組合模型)的LLM推理能力。
因此,如果需要對某個推理服務上特定模型的推理表現進行監控,需要選擇推理服務所在的命名空間(namespace),接著選擇工作負載名字(workload_name),最後選擇模型名(model_name)。選擇完成後,監控大盤資料將會自動更新,展示指定時間段內推理服務的效能指標。
LLM推理服務監控大盤包含3個Panel組:
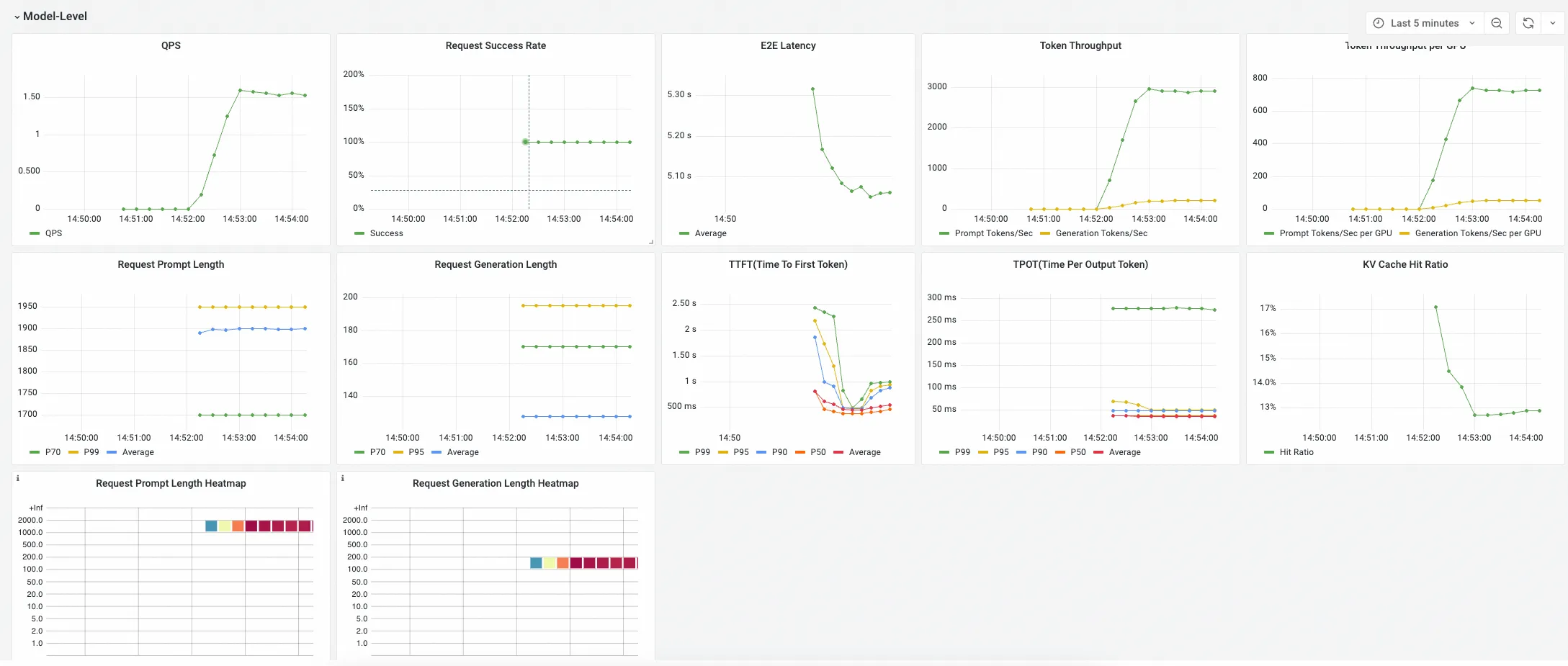
Model-Level Panel
該組下Panel展示某個模型對應的推理服務彙總指標,這些指標用於從整體上判斷一個推理服務的效能是否滿足業務預期。
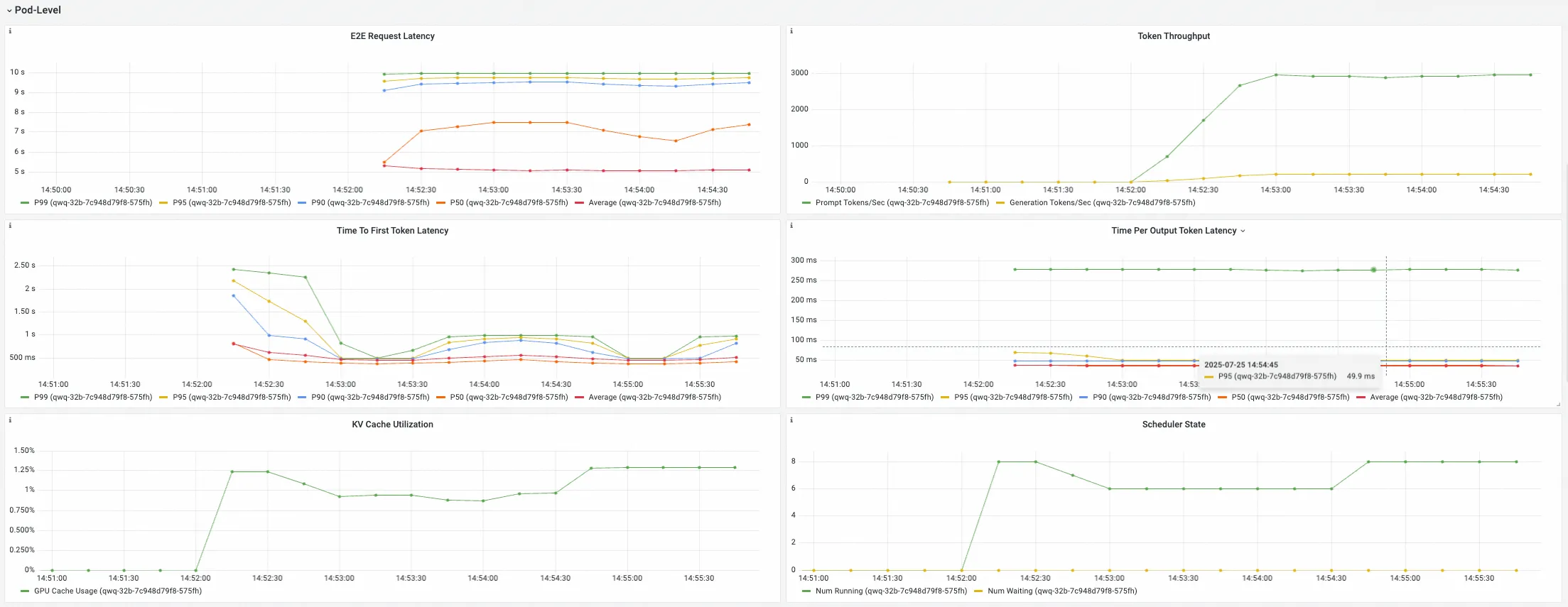
Pod-Level Pane
該組下Panel展示選擇的推理服務下各個Pod的推理服務指標,這些指標用於細化瞭解不同推理服務執行個體的負載平衡情況。
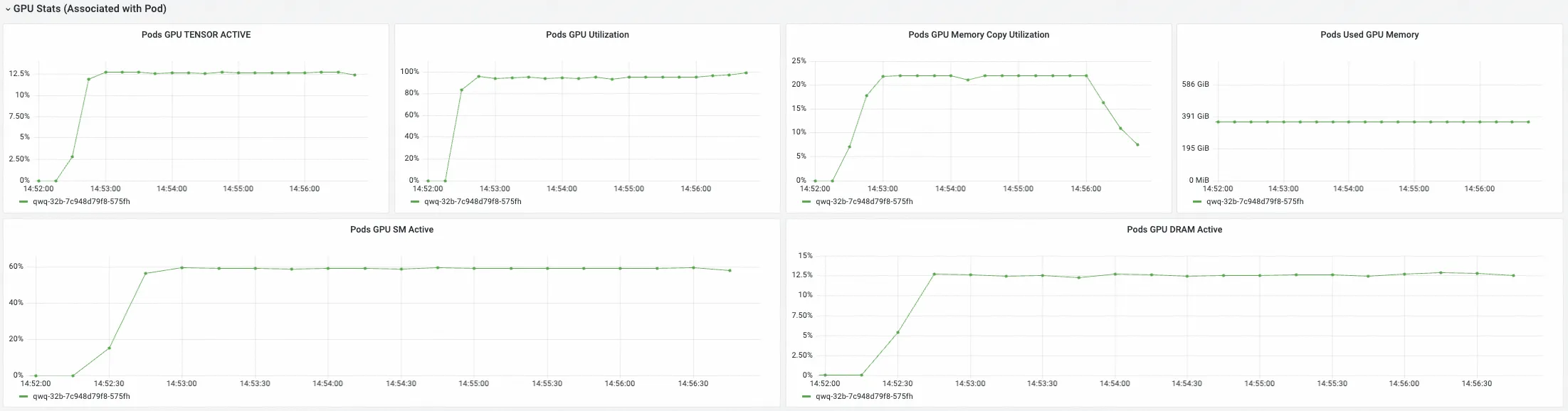
GPU Stats (Associated with Pod)
該組下Panel展示選擇的推理服務下各個Pod的GPU指標,這些指標用於瞭解各個推理服務Pod對GPU資源的使用方式。