多次元インデックスは、Long、Double、Boolean、Keyword、Text、Date、GeoPoint、Vector、IP、JSON などの基本データ型に加えて、Array データ型と Nested データ型をサポートしています。Array データ型は、同じ型の値のシリーズを格納するために使用されます。Nested データ型は JSON 型に似ており、階層構造を持つデータを格納するために使用されます。
Array データ型
Array データ型は多次元インデックスでのみ使用できます。データテーブルは Array データ型をサポートしていません。
Array データ型は、Array ではないデータ型と同じように使用できます。Array フィールドを使用してデータをクエリする場合、配列内の少なくとも 1 つの値が条件を満たしていれば、データの行が返されます。
ベクターデータ型は配列では使用できません。
Array データ型は、Long、Double、Boolean、Keyword、Text、Date、IP、GeoPoint などの基本データ型と組み合わせることができる修飾子です。たとえば、Array 型を Long 型と組み合わせると、結果は複数の長整数を格納できる長整数配列になります。Array データ型は、同じ型の値のシリーズを格納するのに適しています。
Array のフォーマット
次の表では、多次元インデックスにおける Array データ型と基本データ型の組み合わせについて説明します。
Array 型 | 説明 |
Long Array | 長整数の配列です。例: |
Double Array | 浮動小数点数の配列です。例: |
Boolean Array | ブール値の配列です。例: |
Keyword Array | 文字列の配列です。フォーマットは JSON 形式のデータです。例: |
Text Array | テキストの配列です。フォーマットは JSON 配列です。例: テキスト配列は一般的には使用されません。 |
Date Array | 日付の配列です。日付型が整数の場合、フォーマットは |
IP Array | IP アドレスの配列です。フォーマットは JSON 配列です。例: |
Geopoint Array | 地理座標点の配列です。例: |
注意事項
多次元インデックスのフィールドのデータ型が、Array データ型と Long や Double などの基本データ型の組み合わせである場合、多次元インデックスが作成されるデータテーブルのフィールドは String 型である必要があり、多次元インデックスのフィールドは対応する基本データ型である必要があります。
たとえば、price フィールドが Double Array 型の場合、データテーブルの price フィールドは String 型でなければなりません。多次元インデックスでは、対応するフィールドは Double 型でなければならず、isArray=true プロパティを追加する必要があります。
例
array_search_table という名前のデータテーブルがあると仮定します。次の表にサンプルデータを示します。
データテーブルには、プライマリキー列pkと 2 つの属性列col_keyword_arrayおよびcol_long_arrayが含まれます。すべての列は String 型です。
pk | col_keyword_array | col_long_array |
03#server#07 | ["Development environment", "Test environment", "Physical server", "Linux" ] | [2020, 2023] |
4c#server#ae | ["Production environment", "Cloud server", "Linux" ] | [2021, 2024] |
検索インデックスを作成します。
array_query_table_indexという名前の多次元インデックスを作成します。インデックスには、String Array 型のcol_keyword_arrayと Long Array 型のcol_long_arrayの 2 つの列が含まれます。
多次元インデックスを使用して Array データ型のデータをクエリします。
次の Java コードは、配列データをクエリする方法を示しています。クエリ条件では、
col_keyword_array列に「Cloud server」と完全に一致する要素が含まれ、col_long_array列に 2024 と等しい要素が含まれるように指定します。説明SQL 文を実行して、多次元インデックス内の Array データ型のデータをクエリできます。詳細については、「多次元インデックスを使用したデータのクエリに SQL 文を実行」をご参照ください。
private static void query(SyncClient client) { // 条件 1: col_keyword_array 列の値に "Cloud server" と完全に一致する要素が含まれている。 TermQuery keywordTermQuery = new TermQuery(); // クエリタイプを TermQuery に設定します。 keywordTermQuery.setFieldName("col_keyword_array"); // 一致させたい列の名前を指定します。 keywordTermQuery.setTerm(ColumnValue.fromString("Cloud server")); // フィールドを一致させるために使用する値を指定します。 // 条件 2: col_long_array 列の値に 2024 と等しい要素が含まれている。 TermQuery longTermQuery = new TermQuery(); // クエリタイプを TermQuery に設定します。 longTermQuery.setFieldName("col_long_array"); // 一致させたい列の名前を指定します。 longTermQuery.setTerm(ColumnValue.fromLong(2024l)); // フィールドを一致させるために使用する値を指定します。 SearchQuery searchQuery = new SearchQuery(); // クエリ結果が条件 1 と条件 2 を同時に満たす Boolean クエリを構築します。 BoolQuery boolQuery = new BoolQuery(); boolQuery.setMustQueries(Arrays.asList(keywordTermQuery, longTermQuery)); searchQuery.setQuery(boolQuery); //searchQuery.setGetTotalCount(true); // 一致した行の総数を返すように指定します。 SearchRequest searchRequest = new SearchRequest("<TABLE_NAME>", "<SEARCH_INDEX_NAME>", searchQuery); // columnsToGet パラメーターを設定して、返したい列を指定するか、すべての列を返すように指定できます。このパラメーターを設定しない場合、プライマリキー列のみが返されます。 //SearchRequest.ColumnsToGet columnsToGet = new SearchRequest.ColumnsToGet(); //columnsToGet.setReturnAll(true); // すべての列を返すように指定します。 //columnsToGet.setColumns(Arrays.asList("ColName1","ColName2")); // 返したい列を指定します。 //searchRequest.setColumnsToGet(columnsToGet); SearchResponse resp = client.search(searchRequest); //System.out.println("TotalCount: " + resp.getTotalCount()); // 返された行数ではなく、一致した行の総数を表示するように指定します。 System.out.println("Row: " + resp.getRows()); }
Nested データ型
Nested 型のデータは、ネストされたドキュメントです。ネストされたドキュメントは、1 行のデータ (ドキュメント) に複数の子行 (子ドキュメント) が含まれる場合に使用されます。複数の子行は、ネストされたフィールドに格納されます。Nested データ型は、階層構造を持つデータを格納するのに適しています。
ネストされたフィールドの子行のスキーマを指定する必要があります。スキーマには、子行のフィールドと各フィールドのプロパティが含まれている必要があります。Nested データ型は、JSON データ型と同様に、複数の値を格納するために使用できます。
Nested のフォーマット
ネストされたフィールドは、単一レベルと複数レベルのネストされたフィールドに分類されます。次の表では、2 つのタイプについて説明します。
ネストの型 | 説明 |
単一レベルのネストされた型 | 単一レベルのネストされた型には、別のデータ構造の 1 つのレイヤーが含まれます。これにより、基本的な階層を持つ単純な構造が作成されます。この型は、単純な階層が必要で、複数レベルは必要ないシナリオに適しています。次のコードは一例です: |
複数レベルのネストされた型 | 複数レベルのネストされた型には、他のデータ構造の複数のネストされたレイヤーが含まれます。これにより、より複雑な階層が生まれます。この型は、豊富な階層と高度なモジュール性または組織化を必要とするデータモデルに使用します。次のコードは一例です: |
注意事項
多次元インデックスのフィールドが Nested 型である場合、多次元インデックスが作成されるデータテーブルのフィールドは String 型である必要があり、多次元インデックスのフィールドは Nested 型である必要があります。Nested 型のフィールドをクエリするには、ネストされたクエリを実行する必要があります。
データテーブルにデータを書き込むとき、多次元インデックスのネストされたフィールドに対応するデータテーブルフィールドは、オブジェクトの JSON 配列でなければなりません。例: [{"tagName":"tag1", "score":0.8,"time": 1730690237000 }, {"tagName":"tag2", "score":0.2,"time": 1730691557000}]。
フィールドに子行が 1 つしか含まれていない場合でも、ネストされたフィールドには JSON Array 型の文字列を書き込む必要があります。
例
単一レベルの Nested フィールドの例
Tablestore コンソールまたは Tablestore SDK を使用して、単一レベルの Nested フィールドを作成できます。
このセクションでは、Tablestore SDK for Java を使用して単一レベルの Nested フィールドを作成する方法について説明します。この例では、tags という名前の Nested フィールドが作成されます。各子行には 3 つのフィールドが含まれます。次の図に詳細を示します。
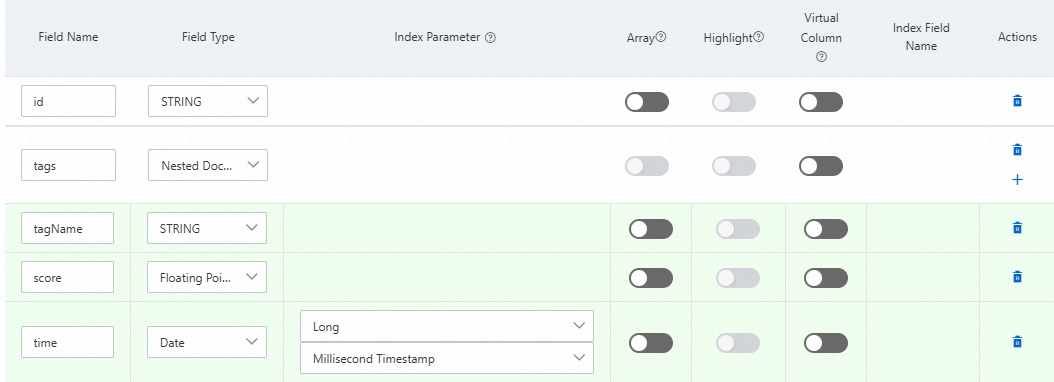
フィールド名: tagName。フィールドタイプ: Keyword。
フィールド名: score。フィールドタイプ: Double。
フィールド名: time。フィールドタイプ: Date。単位:ミリ秒。
データテーブルに書き込まれるサンプルデータは [{"tagName":"tag1", "score":0.8,"time": 1730690237000 }, {"tagName":"tag2", "score":0.2,"time": 1730691557000}] です。
// 子行のフィールドのスキーマを作成します。
List<FieldSchema> subFieldSchemas = new ArrayList<FieldSchema>();
subFieldSchemas.add(new FieldSchema("tagName", FieldType.KEYWORD)
.setIndex(true).setEnableSortAndAgg(true));
subFieldSchemas.add(new FieldSchema("score", FieldType.DOUBLE)
.setIndex(true).setEnableSortAndAgg(true));
subFieldSchemas.add(new FieldSchema("time", FieldType.DATE)
.setDateFormats(Arrays.asList("epoch_millis")));
// 子行用に作成されたスキーマを Nested フィールドの subfieldSchemas の値として使用します。
FieldSchema nestedFieldSchema = new FieldSchema("tags", FieldType.NESTED)
.setSubFieldSchemas(subFieldSchemas);複数レベルの Nested フィールドの例
Tablestore SDK を使用して、複数レベルの Nested フィールドを作成できます。
このセクションでは、Tablestore SDK for Java を使用して複数レベルの Nested フィールドを作成する方法について説明します。この例では、user という名前の Nested フィールドが作成されます。各子行には、4 つの異なる基本データ型のフィールドと 1 つの Nested フィールドが含まれます。
フィールド名: name。フィールドタイプ: Keyword。
フィールド名: age。フィールドタイプ: Long。
フィールド名: birth。フィールドタイプ: Date。フィールドの値は日付形式です。
フィールド名: phone。フィールドタイプ: Keyword。
Nested フィールド名: address。各子行のフィールド名: province、city、street。各子行のすべてのフィールドのデータ型: Keyword。
以下は、データテーブルに書き込むサンプルデータです:[ {"name":"Zhang San","age":20,"birth":"2014-10-10 12:00:00.000","phone":"1390000****","address":[{"province":"Zhejiang Province","city":"Hangzhou City","street":"No. 1201, Xingfu Community, Sunshine Avenue"}]}]
// address の Nested フィールドの子行にある 3 つのフィールドのスキーマを作成します。user.address で指定されたパスを使用して、子行のフィールドのデータをクエリできます。
List<FieldSchema> addressSubFiledSchemas = new ArrayList<>();
addressSubFiledSchemas.add(new FieldSchema("province",FieldType.KEYWORD));
addressSubFiledSchemas.add(new FieldSchema("city",FieldType.KEYWORD));
addressSubFiledSchemas.add(new FieldSchema("street",FieldType.KEYWORD));
// Nested フィールド user の各子行のスキーマを作成します。各子行には、3 つの異なる基本データ型のフィールドと、address という名前の 1 つの Nested フィールドが含まれます。Nested フィールド user で指定されたパスを使用して、子行のフィールドのデータをクエリできます。
List<FieldSchema> subFieldSchemas = new ArrayList<>();
subFieldSchemas.add(new FieldSchema("name",FieldType.KEYWORD));
subFieldSchemas.add(new FieldSchema("age",FieldType.LONG));
subFieldSchemas.add(new FieldSchema("birth",FieldType.DATE).setDateFormats(Arrays.asList("yyyy-MM-dd HH:mm:ss.SSS")));
subFieldSchemas.add(new FieldSchema("phone",FieldType.KEYWORD));
subFieldSchemas.add(new FieldSchema("address",FieldType.NESTED).setSubFieldSchemas(addressSubFiledSchemas));
// Nested フィールド user の子行用に作成されたスキーマを Nested フィールドの subfieldSchemas の値として使用します。
List<FieldSchema> fieldSchemas = new ArrayList<>();
fieldSchemas.add(new FieldSchema("user",FieldType.NESTED).setSubFieldSchemas(subFieldSchemas));制限事項
ネストされたインデックスは、さまざまなシナリオでクエリパフォーマンスを向上させるために使用できる IndexSort 機能をサポートしていません。
ネストされたフィールドを含む多次元インデックスを使用してデータをクエリし、ページングが必要な場合は、クエリ条件でソート方法を指定してデータを返す必要があります。そうしないと、Tablestore はクエリ条件を満たすデータの一部しか読み取られていない場合に nextToken を返しません。
ネストされたクエリは、他のタイプのクエリよりもパフォーマンスが低くなります。
Nested データ型は、すべてのクエリ、ソート、集約で使用できます。
関連ドキュメント
多次元インデックスを使用してデータをクエリする場合、次のクエリメソッドを使用できます: term クエリ、複数値完全一致検索、完全一致検索、一致検索、フレーズ一致検索、prefix クエリ、範囲クエリ、ワイルドカード検索、あいまい検索、Boolean クエリ、ジオクエリ、ネストされたクエリ、KNN ベクタークエリ、exists クエリ。ビジネス要件に基づいてクエリメソッドを選択し、複数のディメンションからデータをクエリできます。
ソートおよびページング機能を使用して、クエリ条件を満たす行をソートまたはページングできます。詳細については、「ソートとページングの実行」をご参照ください。
折りたたみ (distinct) 機能を使用して、特定の列に基づいて結果セットを折りたたむことができます。これにより、指定されたタイプのデータがクエリ結果に一度だけ表示されるようになります。詳細については、「折りたたみ (distinct)」をご参照ください。
データテーブル内のデータを分析する場合は、Search 操作の集約機能を使用するか、SQL 文を実行できます。たとえば、最小値と最大値、合計、および行の総数を取得できます。詳細については、「集約」および「SQL クエリ」をご参照ください。
行をソートする必要なくクエリ条件を満たすすべての行を取得したい場合は、ParallelScan および ComputeSplits 操作を呼び出して並列スキャン機能を使用できます。詳細については、「並列スキャン」をご参照ください。