インテリジェント検査機能は、サービスログ内のアノマリーを自動的に検出します。インテリジェント検査ジョブを作成し、SQL を使用してリアルタイム検出用のメトリックデータを集計できます。
前提条件
インテリジェント検査ジョブの作成
ジョブ作成ページへの移動
Log Serviceコンソールにログインします。
-
ジョブ作成ページに移動します。
-
ログアプリケーション セクションで、インテリジェントな異常分析 をクリックします。
-
インスタンスリストで、対象のインスタンスをクリックします。
-
左側のナビゲーションペインで、インテリジェント検査 をクリックします。
-
[リアルタイム検出] をクリックします。
-
[検査ジョブ] セクションで、ログデータを処理するために をクリックします。
-
基本情報
インテリジェント検査ジョブの作成 ウィザードの 基本情報 セクションで、次の設定を完了し、次へ をクリックします。
|
パラメータ |
説明 |
|
[タスク名] |
インテリジェント検査ジョブの名前を入力します。 |
|
プロジェクト |
ソース Logstore または Metricstore が含まれるプロジェクトを選択します。 |
|
[リージョン] |
選択したプロジェクトのリージョンが表示されます。 |
|
[ログストアのタイプ] |
データストアのタイプを選択します。
|
|
[ソースログストア] |
ログストアのタイプ を ログストア に設定した場合、ソースログストア を設定する必要があります。これはソースデータが格納されているログストアです。 |
|
[Metricstores] |
ログストアのタイプ が Metricstores に設定されている場合、Metricstores をソースデータが含まれるメトリックストアに設定する必要があります。 |
|
[ロール] |
インスタンスの作成時に権限付与が完了している場合、 |
|
[ターゲットデータベース] |
宛先 Logstore。これは |
データ特徴量設定
[データ特徴量設定] ステップで、[データタイプ] に [SQLでデータをフォーマット] を選択します。クエリおよび分析ステートメントを入力し、以下の表の説明に従ってパラメータを設定します。詳細については、「クエリの概要」および「クエリと分析の概要」をご参照ください。
-
クエリステートメントの例
* | select __time__ - __time__ % 60 as time, domain, sum(request_size) as request_size from log group by time, domain limit 100000 -
エンティティ:
domain -
機能:
request_size
|
パラメータ |
説明 |
|
時間 |
ソースデータ内の時間を表すフィールド。デフォルトでは、Log Service は Logstore の |
|
粒度 |
データが観測される間隔 (秒) です。値は 5~3600 の間である必要があります。60 以上の値を推奨します。 |
|
エンティティ |
ソースデータ内の特定のエンティティを識別するフィールドです。このエンティティによってデータが集計され、時系列が生成されます。 |
|
特徴量 |
ソースデータ内の特徴量データを識別するフィールドです。 |
アルゴリズム設定
-
[アルゴリズム設定] ステップで、[アルゴリズム] を選択します。利用可能なオプションは、[ストリームグラフアルゴリズム] と [ストリーム分解アルゴリズム] です。パラメータは、選択したアルゴリズムによって異なります。
ストリームグラフアルゴリズム
|
パラメータ |
サブパラメータ |
説明 |
|
詳細パラメータ (必須) |
時系列セグメント |
時系列の値をその大きさに基づいて分割するセグメント数です。これは、時系列を離散化し、時系列の進化グラフを構築するために使用されます。
|
|
観測長 |
アノマリー検出のために観測する履歴データポイントの数です。
|
|
|
周期比較長 |
周期比較分析の期間 (日数) です。アノマリー検出は、検出対象メトリックの周期比較特徴量の分析に重点を置きます。このパラメータを 0 に設定した場合、アルゴリズムは周期比較分析を実行しません。 |
|
|
主要なキャプチャタイプ |
重点的に検出する時系列アノマリーのタイプです。有効な値は以下のとおりです。
|
|
|
ツリー |
補助検出に使用される決定木の数です。 |
|
|
ツリーあたりのサンプルサイズ |
アノマリー検出のための決定木を構築する際に、観測データから使用するデータサンプルの数です。 |
|
|
全体的なアノマリー率 |
時系列におけるアノマリーデータの割合の推定値です。妥当な範囲は [0.001, 0.01] です。 |
|
|
アノマリータイプチェックの最小ウィンドウ |
時系列のアノマリーパターンをキャプチャするために使用される観測シーケンスの最小長です。 |
|
|
アノマリータイプチェックの最大ウィンドウ |
時系列のアノマリーパターンをキャプチャするために使用される観測シーケンスの最大長です。 |
|
|
アノマリー確認の最小ウィンドウ |
時系列のアノマリーパターンをキャプチャする際に検出されるシーケンスの最小長です。 |
|
|
アノマリー確認の最大ウィンドウ |
時系列のアノマリーパターンをキャプチャする際に検出されるシーケンスの最大長です。 |
|
|
単一次元特徴量設定 |
- |
検出対象の時系列の各特徴量を設定します。設定項目は以下のとおりです。
|
|
通知感度設定 |
- |
異なる期間に検出されたアノマリーに対して、異なる通知しきい値を設定します。たとえば、毎週の定期メンテナンス中に発生するアノマリーを無視することが可能です。 |
ストリーム分解アルゴリズム
-
アルゴリズムを設定します。
パラメータ
サブパラメータ
説明
自動周期検出
-
時系列の周期の自動検出を有効にします。これは季節性のある時系列データに適しています。季節性が一定である場合は、この機能を無効にして周期長を手動で設定することを推奨します。
周期検出頻度
-
[自動周期検出] が有効な場合に有効です。アルゴリズムは、指定された頻度で時系列の周期を定期的に更新します。たとえば、頻度が 12 時間の場合、アルゴリズムは 12 時間ごとに周期を検出して更新します。
周期長
-
[自動周期検出] が無効な場合に有効です。シーケンス周期の期間を設定します。シーケンスに周期がない場合は、これを 0 に設定します。
観測長
-
アノマリー検出に使用される履歴データの長さです。シーケンスに季節性が含まれる場合、観測長をシーケンス周期長の 3 倍にすることを推奨します。たとえば、シーケンス周期が 1 日の場合、観測長を 3 日に設定します。
感度
-
感度が高いほど、より多くのアノマリーが検出され、アノマリースコアが高くなります。これにより再現率は向上しますが、適合率が低下する可能性があります。
詳細パラメータ
トレンド成分の感度
アルゴリズムは、シーケンスをトレンド、季節性、ノイズの成分に分解します。トレンド成分の感度が高いほど、トレンド成分のアノマリー検出時により多くのアノマリーが検出され、アノマリースコアが高くなります。これにより再現率は向上しますが、適合率が低下する可能性があります。
ノイズ成分の感度
アルゴリズムは、シーケンスをトレンド、季節性、ノイズの成分に分解します。ノイズ成分の感度が高いほど、ノイズ成分のアノマリー検出時により多くのアノマリーが検出され、アノマリースコアが高くなります。これにより再現率は向上しますが、適合率が低下する可能性があります。
トレンド成分のサンプリングステップ
アルゴリズムは、シーケンスをトレンド、季節性、ノイズの成分に分解します。シーケンスの観測長が長すぎると、トレンド成分の分析が遅くなる可能性があります。トレンド成分のサンプリングステップを大きくすると、分析は高速化されますが、検出精度が低下する可能性があります。たとえば、トレンド成分のサンプリングステップを 8 に設定すると、元のシーケンスの 8 ポイントごとに 1 つのデータポイントがサンプリングされて、トレンド分析が行われます。
季節性成分のサンプリングステップ
アルゴリズムは、シーケンスをトレンド、季節性、ノイズの成分に分解します。シーケンスの観測長が長すぎると、季節性成分の分析が遅くなる可能性があります。季節性成分のサンプリングステップを大きくすると、分析は高速化されますが、検出精度が低下する可能性があります。たとえば、季節性成分のサンプリングステップを 8 に設定すると、元のシーケンスの 8 ポイントごとに 1 つのデータポイントがサンプリングされて、季節性分析が行われます。この値は 5 以下に設定することを推奨します。
ウィンドウ長
シーケンスの観測長が長すぎると、アノマリー検出が遅くなる可能性があります。ウィンドウ長を設定することで、検出アルゴリズムはスライディングウィンドウを使用してデータシーケンスをセグメント単位で検出し、検出速度を向上させます。この値は 5,000 以下に設定することを推奨します。スライディングウィンドウを使用したくない場合は、これを 0 に設定します。
-
プレビューセクションで、アルゴリズムをテストし、現在のパラメータ設定に基づいて結果を表示します。
-
時間範囲を設定して、検出対象の時系列の開始時刻と終了時刻を定義します。データのクエリ をクリックすると、システムは データ機能の設定 ステップのクエリ文を使用してこの範囲内のデータを処理し、時系列データを生成します。
-
[エンティティ] と 機能 を選択して、検出対象の特徴系列を定義します。プレビュー をクリックすると、検出アルゴリズムが指定された特徴系列を処理し、その結果が下に表示されます。[パラメーターの表示] をクリックすると、現在のアルゴリズム設定を表示できます。
-
検出結果には、[トレンド成分プレビュー]、[季節成分プレビュー]、および [ノイズ成分プレビュー] が含まれます。[トレンド成分プレビュー] および [ノイズ成分プレビュー] セクションで、異常しきい値を調整できます。異常スコアが対応するしきい値を超えた場合にのみ、アラートがトリガーされます。
-
-
スケジュール設定 ステップでは、以下のパラメーターを設定します。
|
パラメータ |
説明 |
|
開始時刻 |
ジョブがデータの読み取りと検出を開始する時刻です。 |
|
データ遅延 |
データが SLS に書き込まれる際の最大予想遅延です。ジョブはこの期間待機し、完全な時系列データが利用可能になることを保証します。 |
|
モデル学習開始時刻 |
任意。設定した場合、バックグラウンドタスクはこの時刻にモデルの構築を開始します。この時刻は、ジョブのスケジュールされた開始時刻と一致させる必要があります。 |
|
モデル学習終了時刻 |
任意。設定しない場合、モデルは継続的に学習し、ジョブの開始時刻後に検出を開始します。設定した場合、バックグラウンドタスクはこの時刻にモデルの更新を停止し、直ちに検出を開始します。 |
アラート設定
-
インテリジェント検査ジョブの作成 設定ウィザードの アラートの設定 エリアで、以下の設定を完了し、完成 をクリックします。
パラメータ
説明
アラートポリシー
アラートポリシーは、生成されたアラートをグループ化、抑制、サイレンスします。
-
シンプルモード または [標準モード] を選択した場合、アラートポリシーを設定する必要はありません。Log Service は、デフォルトの動的アラートポリシー (sls.builtin.dynamic) を使用してアラートを管理します。
-
上級モード を選択すると、組み込みまたはカスタムのアラートポリシーを選択してアラートを管理できます。 アラートポリシーの作成方法の詳細については、「アラートポリシーの作成」をご参照ください。
アクションポリシー
アクションポリシーは、通知チャネルや頻度など、アラート通知の送信方法とタイミングを制御します。
-
アラートポリシー が シンプルモード に設定されている場合、アクション グループを設定するだけです。
-
アラートポリシー が [標準モード] または 上級モード に設定されている場合、組み込みまたはカスタムのアクションポリシーを選択して、アラート通知を管理できます。 アクションポリシーの作成方法の詳細については、「アクションポリシー」をご参照ください。
アラートポリシー を 上級モード に設定した場合、[カスタムアクションポリシー] を有効化または無効化することもできます。 詳細については、「動的アクションポリシーメカニズム」をご参照ください。
-
インテリジェント検査ジョブの管理
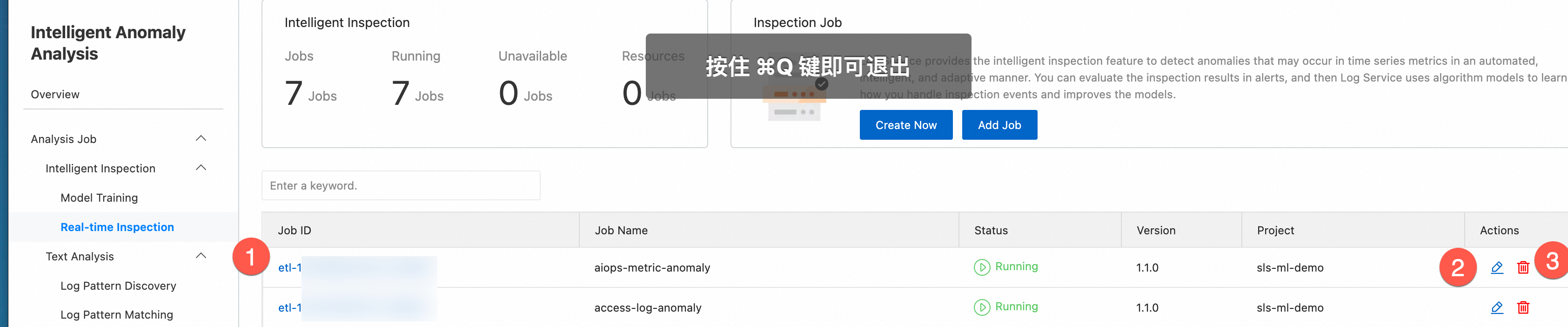
-
ジョブの表示: ジョブリストでジョブを見つけ、その ID をクリックして詳細を表示します。
-
ジョブの編集: ジョブを編集するには、リストでジョブを見つけ、[操作] 列で [編集] をクリックします。
-
ジョブの削除: ジョブを削除するには、リストでジョブを見つけ、[操作] 列で [削除] をクリックします。
重要削除したインテリジェント検査ジョブは復元できません。慎重に操作してください。