Logstore に収集されたログをクエリおよび分析するには、インデックスを作成する必要があります。このトピックでは、Simple Log Service のインデックスに関する基本概念と種類について説明し、インデックスの作成・更新・無効化方法を紹介します。また、構成例や課金情報も提供します。
インデックスを作成する理由
通常、生ログからコンテンツを取得する際はキーワードを使用します。たとえば、エントリ curl/7.74.0 内に含まれる curl を含むログを検索する場合などが該当します。ログエントリが解析されていない場合、そのエントリは単一の単位として扱われ、キーワード curl と完全に一致しないため、Simple Log Service では検索できません。
ログを検索可能にするには、ログを個別の検索可能な語(term)に分割する必要があります。ログはデリミタを使用して分割されます。これらの文字により、ログテキストの分割位置が決定されます。たとえば、デリミタとして \n\t\r,;[]{}()&^*#@~=<>/\?:'" を使用してログを分割すると、結果として curl および 7.74.0 という語が得られます。Simple Log Service は抽出された語に基づいてインデックスを構築します。インデックスを作成した後でのみ、ログのクエリおよび分析が可能になります。
Simple Log Service は、フルテキストインデックスとフィールドインデックスの両方をサポートしています。同じ Logstore に対して両方を構成した場合、フィールドインデックスの構成が優先されます。
インデックスの種類
フルテキストインデックス
フルテキストインデックスは、トークン を使用して、ログ全体を複数の text 型の語に直接分割します。フルテキストインデックスを作成すると、キーワードを使用してログをクエリできます。たとえば、クエリ文 Chrome or Safari は、Chrome または Safari を含むログを検索します。
トークン は中国語の文字を分割できません。中国語テキストを処理するには、中国語を含む オプションを有効にしてください。これにより、Log Service は中国語の文法に基づいて自動的にトークン化を行います。
フルテキストインデックスのみを構成した場合、フルテキスト検索構文を使用できます。詳細については、「クエリ構文と関数」をご参照ください。
フィールドインデックス
フィールドインデックスは、フィールド名 (KEY) に基づいてログを分離し、その後デリミタを使用してフィールド内のコンテンツを分割します。フィールドインデックスは、text、long、double、JSON の 4 種類のデータ型をサポートしています。詳細については、「データの型」をご参照ください。フィールドインデックスを作成すると、フィールド名とフィールド値 (Key:Value) を指定するか、SELECT 文を使用してデータをクエリできます。詳細については、「クエリ構文と機能」をご参照ください。
SELECT 文を使用して特定のフィールドをクエリまたは分析するには、そのフィールドに対してフィールドインデックスを作成する必要があります。フィールドインデックスはフルテキストインデックスより優先度が高くなります。両方がフィールドに対して構成されている場合、フィールドインデックスの設定が優先されます。
text データ型のフィールドでは、フルテキストクエリ、フィールド固有のクエリ、分析文 (SELECT) を使用できます。
フルテキストインデックスを有効にしない場合、フルテキストクエリは text 型のすべてのフィールドに対してのみ検索を行います。
フルテキストインデックスを有効にした場合、フルテキストクエリはすべてのログに対して検索を行います。
long および double データ型のフィールドでは、フィールド固有のクエリおよび分析文 (SELECT) を使用してデータをクエリおよび分析できます。
インデックスの作成
インデックスの構成内容によって、クエリおよび分析結果が異なります。要件に基づいて慎重にインデックスを構成してください。新しいインデックスが有効になるまでに約 1 分かかります。
インデックスは新しく取り込まれたデータにのみ適用されます。既存データをクエリするには、インデックスの再作成 を実行する必要があります。
Log Service は一部の予約済みフィールドに対して自動的にインデックスを作成します。詳細については、「予約済みフィールド」をご参照ください。
__topic__および__source__のインデックスデリミタは空であるため、これらのフィールドをクエリする際はキーワードが完全に一致している必要があります。__tag__で始まるフィールドはフルテキストインデックスをサポートしません。*| select "__tag__:__receive_time__"のような検索および分析操作を実行するには、text 型のフィールドインデックスを作成する必要があります。ログに同じ名前のフィールドが複数含まれている場合(例:
request_time)、Log Service はコンソール上ではそのうちの 1 つをrequest_time_0として表示します。ただし、基盤となるフィールド名はrequest_timeのままです。そのため、インデックスの作成、クエリ、分析、転送、変換を行う際は、元のフィールド名request_timeを使用する必要があります。
コンソール
Simple Log Service コンソール にログインします。
[Projects] セクションで、目的のプロジェクトをクリックします。
タブで、目的の Logstore をクリックします。
Logstore の 検索と分析 ページで、インデックスの有効化 をクリックします。
説明インデックスを有効化した後、最新のデータを約 1 分後にクエリできます。

(オプション)自動更新をオフにします。
他の Alibaba Cloud サービス専用または内部利用の Logstore では、インデックスの 自動アップデート スイッチがデフォルトでオンになっています。これにより、サービスのアップデート時に組み込みインデックスが最新バージョンにアップグレードされます。カスタムインデックスを作成するには、Query and Analysis パネルで 自動アップデート スイッチをオフにしてください。
警告他のクラウドサービス専用の Logstore のインデックスを削除すると、レポートやアラートなどの関連機能に影響が出る可能性があります。
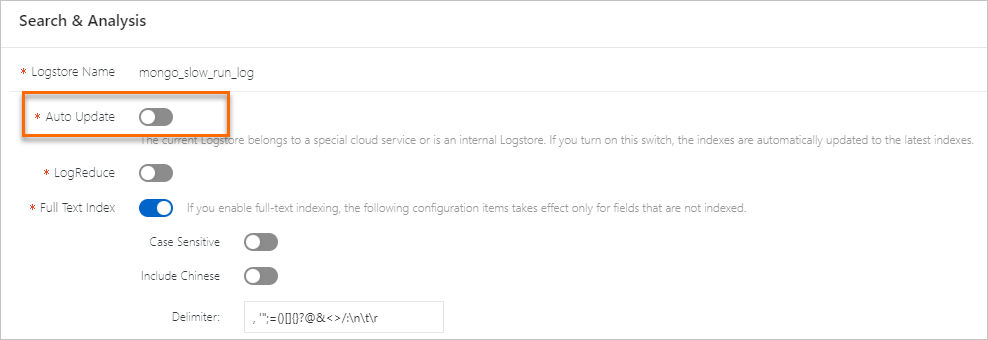
インデックスを作成します。
フルテキストインデックス
インデックスの有効化 をクリックすると、フルテキストインデックス スイッチがデフォルトでオンになります。ビジネス要件に基づき、LogReduce、大文字と小文字を区別、および 中国語を含む 機能を有効または無効にできます。トークン を指定するか、トークン をカスタマイズすることもできます。
構成ページは次のようになります:
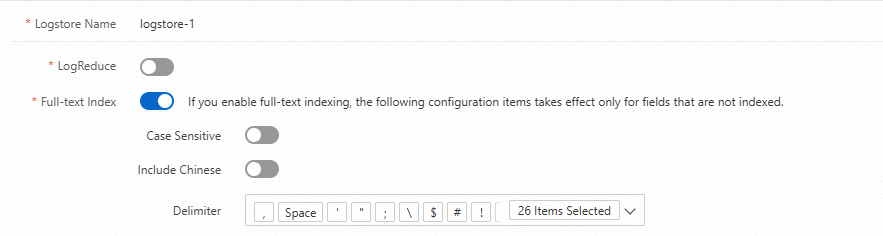
パラメーター
フィールドインデックス
インデックスの有効化 をクリックすると、Query and Analysis ページで 自動インデックスの生成 をクリックできます。これにより、Log Service はプレビューデータの最初のエントリに基づいてフィールドインデックスを自動生成します。カスタムフィールドインデックスを作成するには、ページ下部の
+アイコンをクリックします。フィールドの詳細な説明については、「パラメーターの説明」をご参照ください。初回アクセス時のページは次のようになります:
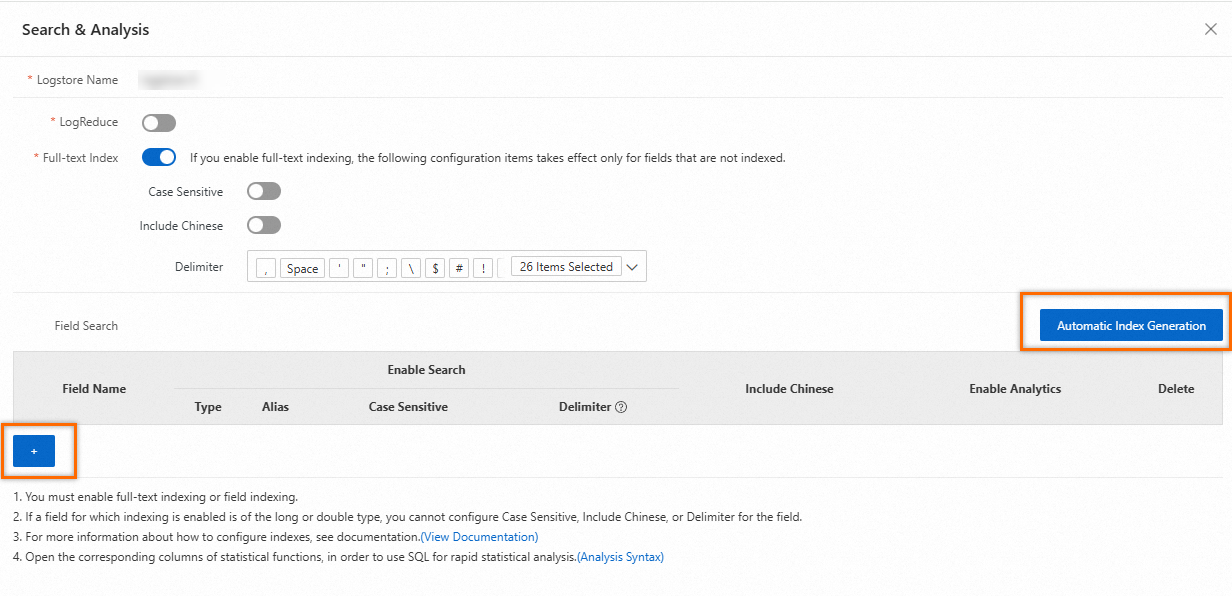
フィールドインデックスの構成設定は以下のとおりです:

パラメーター
(オプション)最大フィールド長を設定します
SQL 分析中に、Simple Log Service はデフォルトでフィールド値を切り捨てます。デフォルトの最大長は
2048バイト (2 KB) です。この最大長を変更する必要がある場合は、Query and Analysis ページの下部にある 統計フィールドの最大長 を設定できます。値の範囲は 64 ~ 16384 バイトです。重要インデックス構成の更新は、新しく取り込まれたデータにのみ適用されます。
単一のフィールド値が最大長を超える場合、超過部分は切り捨てられ、分析に含まれません。

API
SDK
CLI
インデックスの更新
操作手順
対象の Logstore の 検索と分析 ページで、 を選択します。インデックスの構成内容によって、クエリおよび分析結果が異なります。要件に基づいて慎重にインデックスを更新してください。更新が有効になるまでに約 1 分かかります。

インデックスの無効化
無効化 を実行すると、Log Service は Logstore の保持期間が終了した時点で、履歴インデックスデータのストレージを自動的に解放します。
操作手順
対象の Logstore の 検索と分析 ページで、 を選択します。

インデックス構成例
例 1
ログコンテンツに request_time フィールドが含まれています。request_time>100 というクエリを実行できます。
フルテキストインデックスのみの場合、
request_time、>(デリミタではない)、および100の 3 つの語を含むログが検索結果として返されます。double 型および long 型に対してのみフィールドインデックスを作成した場合、
request_timeが 100 を超えるログが返されます。フルテキストインデックスと double 型および long 型のフィールドインデックスの両方を作成した場合、
request_timeのフルテキストインデックスは無視され、request_timeが 100 を超えるログが返されます。
例 2
ログコンテンツに request_time フィールドが含まれているため、フルテキストクエリ request_time を実行できます。
double型またはlongデータ型のフィールドインデックスのみを作成した場合、関連するログは返されません。ログテキスト全体から
request_timeを含むログをクエリするには、フルテキストインデックスのみを作成できます。text型のフィールドインデックスを持つフィールドからrequest_timeを含むログをクエリできます。
例 3
ログコンテンツに status フィールドが含まれています。分析文 * | SELECT status, count(*) AS PV GROUP BY status を実行します。
フルテキストインデックスのみを作成した場合、関連するログは返されません。
statusに対してフィールドインデックスを作成すると、異なるステータスコードとそれに対応する合計 PV が返されます。
インデックストラフィック
フルテキストインデックス
すべてのフィールド名と値は、 index traffic に含まれます。
フィールド インデックス
インデックストラフィックの計算は、フィールドのdata typeに基づいて異なります。
text 型:フィールド名と値の両方が
インデックストラフィックにカウントされます。long 型および double 型:フィールド名は
インデックストラフィックにカウントされません。各フィールド値は、インデックストラフィックに固定で 8 バイトを加算します。たとえば、
statusフィールド(long 型)に対してインデックスを作成し、その値が200の場合、文字列statusはインデックストラフィックに含まれません。200の値に対するインデックストラフィックは、固定で 8 バイトです。JSON 型:明示的にインデックスされていないサブキーを含め、フィールド名と値の両方が
インデックストラフィックにカウントされます。詳細については、「JSON フィールドのインデックストラフィックはどのように計算されますか?」をご参照ください。サブキーがインデックスされていない場合、その
インデックストラフィックは text 型であるかのように計算されます。サブキーがインデックスされている場合、その
インデックストラフィックは指定されたデータの型(text、long、または double)に基づいて計算されます。
課金
取り込みデータ量課金モードの Logstore
インデックスはストレージ領域を占有します。ストレージタイプの詳細については、「インテリジェント階層型ストレージの管理」をご参照ください。
データのインデックス再作成には料金は発生しません。
インデックストラフィックの料金の詳細については、「取り込みデータ量課金モードの課金項目」をご参照ください。
機能別課金モードの Logstore
インデックスはストレージ領域を占有します。ストレージタイプの詳細については、「インテリジェント階層型ストレージの管理」をご参照ください。
インデックスを作成するとトラフィックが発生します。この
インデックストラフィックには料金が発生します。詳細については、「機能別課金モードの課金項目」をご参照ください。インデックストラフィック料金を削減するための提案については、「インデックストラフィック料金を削減する方法」をご参照ください。データのインデックス再作成には料金が発生します。課金項目および価格は、インデックス作成時と同じです。
次のステップ
クエリおよび分析の例については、以下のトピックをご参照ください:
クエリパフォーマンスを最適化するには、「ログクエリおよび分析速度を向上させる方法」をご参照ください。
JSON 形式の Web サイトログをクエリおよび分析するには、「JSON ログのクエリおよび分析」をご参照ください。