このトピックでは、Simple Log Service (SLS) 処理言語 (SPL) について、その実装、構文、命令式などを説明します。
SPL の概要
SLS は SPL 文を使用して、生データから構造化された情報を抽出し、フィールドを操作し、データをフィルターします。また、複数レベルのパイプライン機能も提供しており、最初のパイプラインはインデックスフィルター条件用で、後続のパイプラインは SPL 命令用です。最終的な出力は、SPL によって処理されたデータです。SQL に精通している場合は、「SPL と SQL のユースケースの比較」を参照して、さまざまなデータ処理タスクで SPL を使用する方法を学習してください。
仕組み
SLS SPL は、Logtail データ収集、インジェストプロセッサ、ルールベースのデータ消費、データ変換 (新バージョン)、スキャンベースのクエリと分析などの機能と連携して動作します。次の図にその仕組みを示します。
説明
各ユースケースの SPL 関数についての詳細については、「一般的なリファレンス」をご参照ください。
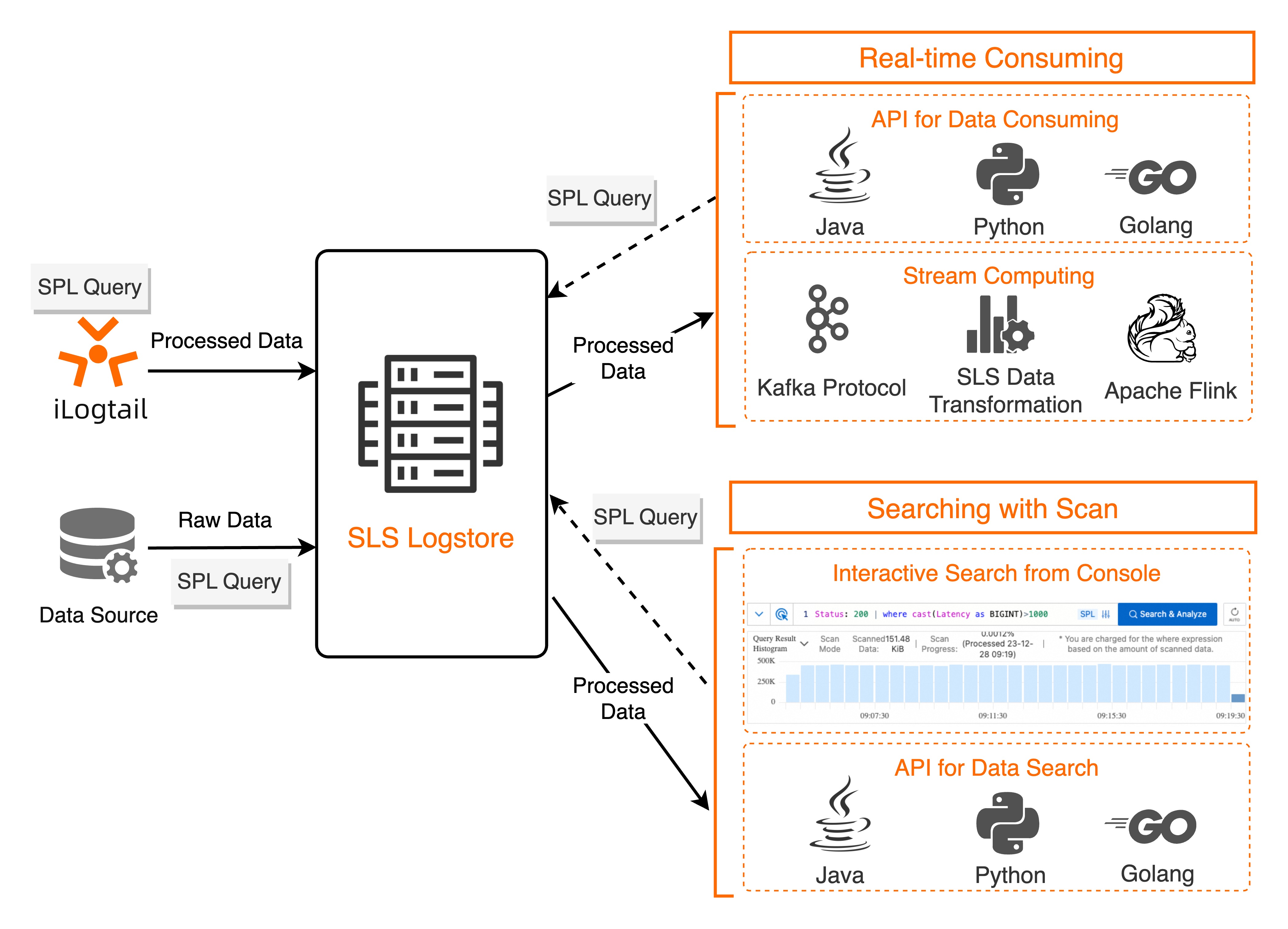
制限事項
カテゴリ | 制限 | Logtail データ収集 | 書き込みプロセッサ | リアルタイム消費 | データ変換 (新規) | スキャンクエリ |
SPL の複雑さ | スクリプトパイプラインレベルの数 | 16 | 16 | 16 | 16 | 16 |
スクリプトの長さ | 64 KB | 64 KB | 10 KB | 10 KB | 64 KB | |
SPL ランタイム | ランタイムメモリサイズ 重要 ソリューションについては、「障害処理」をご参照ください。 | 50 MB | 1 GB | 1 GB | 1 GB | 2 GB |
ランタイムタイムアウト 重要 ソリューションについては、「障害処理」をご参照ください。 | 1 秒 | 5 秒 | 5 秒 | 5 秒 | 2 秒 |