SLS は、複数の Logstore にまたがるデータの正規化、抽出、クレンジング、フィルタリング、および配信を行う、フルマネージドでスケーラブル、かつ可用性の高いデータ変換 (新バージョン) サービスを提供します。
仕組み
データ変換 (新バージョン) は、ホスト型消費ジョブと SPL ルールを通じてログデータをリアルタイムで処理します。詳細については、「SPL 構文」および「標準消費の概要」をご参照ください。
データ変換は、SLS のリアルタイム消費 API を使用するため、ソース Logstore のインデックス設定には依存しません。
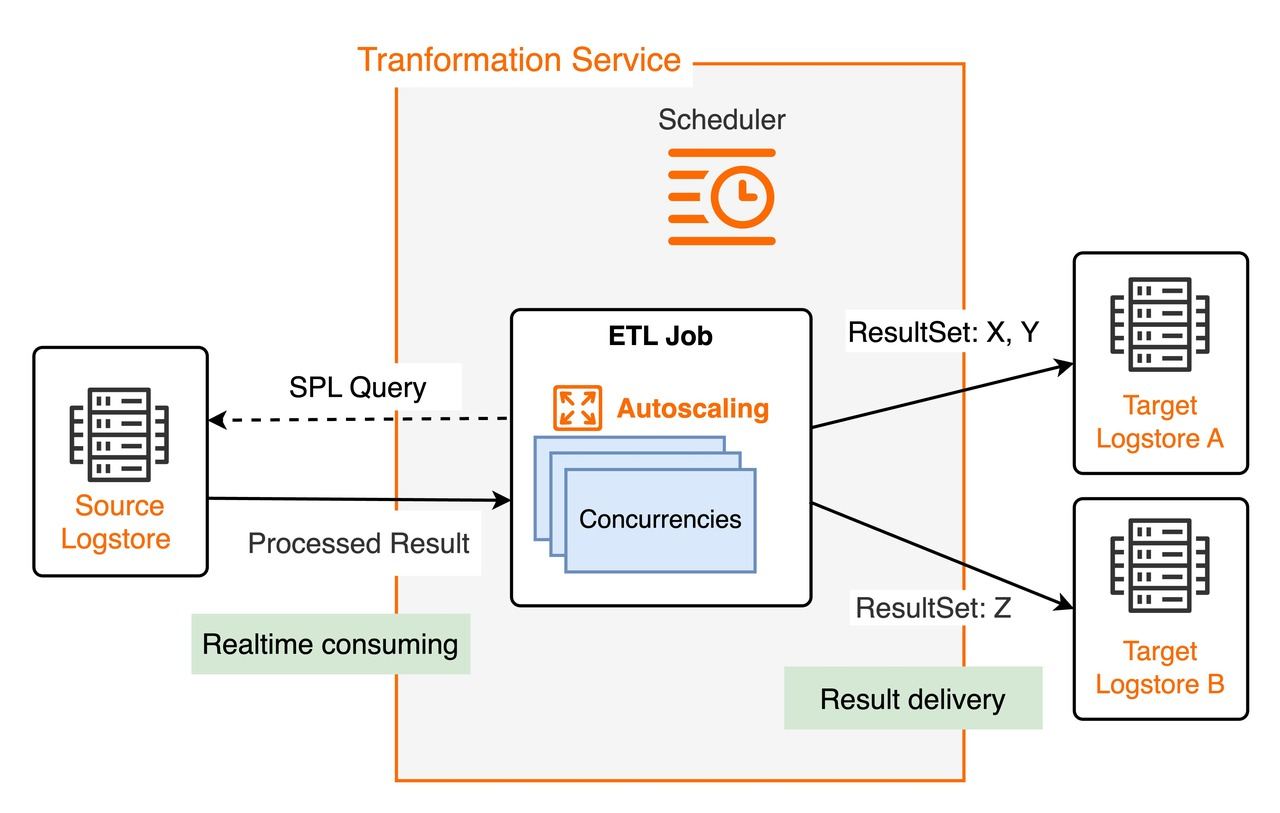
スケジューリングメカニズム
スケジューラは、ジョブごとに 1 つ以上のインスタンスを起動して、データを並行して処理します。各インスタンスは、ソース Logstore の 1 つ以上のシャードからデータを消費します。インスタンス数は、リソース使用量と処理の進捗状況に基づいて調整され、弾性スケーリングを実現します。ジョブあたりの最大同時実行数は、ソース Logstore のシャード数と同じです。
実行中のインスタンス
各インスタンスは、ジョブの SPL ルールと送信先 Logstore の設定に基づいて、割り当てられたシャードからソースログデータを消費し、その結果を送信先 Logstore に配信し、書き込みます。インスタンスはシャードのチェックポイントを自動的に保存するため、再起動されたジョブは最後のチェックポイントから再開されます。
ジョブの停止と再開
-
自動停止:終了時刻が設定されているジョブは、その時刻以前のすべてのログを処理した後に停止します。終了時刻が設定されていない場合、ジョブは継続的に実行されます。詳細については、「ETL」をご参照ください。
-
再開可能な処理:予期せず停止した後、ジョブを再起動すると、デフォルトで最後に保存されたシャードのチェックポイントから処理を再開し、データの一貫性を確保します。
ジョブ実行ステータスの表示
SLS は、データ変換 (新バージョン) ジョブのモニタリングをサポートしています。詳細については、「データ変換 (新バージョン) ジョブの監視とモニタリング」をご参照ください。
シナリオ
データ変換は、以下のシナリオに対応しています:
-
データ正規化と情報抽出:形式が不統一なログからフィールドを抽出し、フォーマットを正規化して、ストリーム処理やデータウェアハウス分析用の構造化データを生成します。
-
データ転送と配信:
-
さまざまな種類のログを単一の Logstore に収集し、特性 (ソースモジュール、ビジネスコンポーネントなど) に応じてダウンストリームの Logstore に配信し、データ分離とシナリオ固有のコンピューティングを実現します。
-
複数リージョンにまたがるデプロイメントの場合、各リージョンのログをクロスリージョンアクセラレーションを利用して中央リージョンに集約し、一元管理を実現します。
-
-
データクレンジングとフィルタリング:無効なエントリや未使用のフィールドを削除し、フィルタリングされた主要な情報をダウンストリームの Logstore に書き込むことで、焦点を絞った分析を行います。
-
データマスキング:パスワード、電話番号、住所などの機密データをマスキングします。
機能
-
SPL は、データ収集、クエリ、処理のための統一言語を提供し、複数の構文を学習する必要がなくなります。
-
行ごとのデバッグとコードヒント機能により、IDE のように SPL のコーディングができます。
-
数秒以内のデータ可視性、弾性スケーリング、高スループットを備えたリアルタイム処理。
-
ログ分析のための組み込みのデータ処理命令と SQL 関数。
-
リアルタイムの可観測性メトリクス、ダッシュボード、およびランタイムメトリクスに基づくカスタムモニタリングルール。
-
フルマネージドかつメンテナンスフリーで、Alibaba Cloud のビッグデータおよびオープンソースエコシステムとの統合が可能です。
課金
-
pay-by-ingested-dataLogstore:データ変換 (新バージョン) は無料です。SLS のパブリックエンドポイント経由でデータをプルまたは書き込む際のアウトバウンドトラフィックは、圧縮後のデータ量に基づいて課金されます。詳細については、「取り込みデータ量課金モードの課金項目」をご参照ください。 -
pay-by-featureLogstore:データ変換 (新バージョン) によって消費されたコンピューティングリソースとネットワークリソースに対して課金されます。詳細については、「機能別課金モードの課金項目」をご参照ください。