Simple Log Service では、SPL を用いてサーバー側の処理ルールを定義することで、ログデータをリアルタイムで消費できます。本トピックでは、この機能の基本概念、メリット、適用範囲、課金ルール、および対応するコンシューマーについて説明します。
仕組み
ルールベースのデータ消費では、サーバー側で SPL を実行して、半構造化ログデータの前処理およびクリーニングを行います。具体的には、行フィルタリング、列のプルーニング、正規表現による抽出、JSON フィールドの抽出などの操作が可能です。これにより、クライアントへはクリーンで構造化されたデータが配信されます。SPL の構文の詳細については、「SPL 構文」をご参照ください。
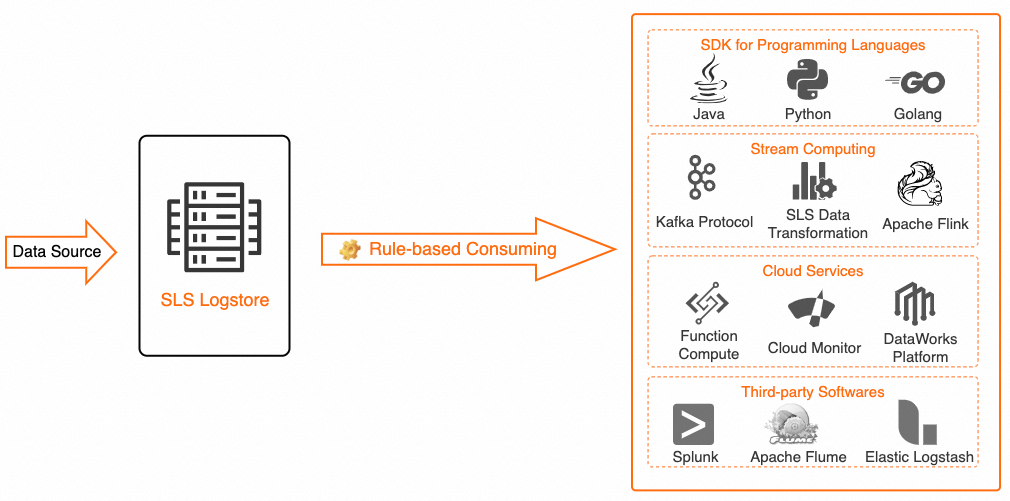
ルールベースのデータ消費とクエリと分析は、いずれもデータ読み取りに使用される機能です。両者の違いについては、「ログ消費とログクエリの違い」をご参照ください。
適用範囲
ルールベースのデータ消費は、ストリームコンピューティングやリアルタイムコンピューティングなど、データの前処理を必要とするシナリオに最適です。たとえば、ログデータを消費する前に、行フィルタリングや列のプルーニング、あるいは正規表現・JSON パスを用いたデータ抽出を行う必要があります。この機能により、通常数秒以内という低レイテンシでのデータ消費が可能です。また、カスタムのデータ保持期間を設定することもできます。
メリット
-
インターネット経由でのデータ消費により、トラフィックコストを削減できます。
-
不要な大量データの転送を防ぐため、ネットワークトラフィックコストを低減できます。
-
-
ローカル CPU リソースを節約し、処理を高速化できます。
-
たとえば、複雑なデータ計算処理をローカルマシンではなく Simple Log Service 側で実行することで、ローカルリソースの負荷を軽減し、全体のワークフローを加速できます。
-
課金
-
Logstore が「取り込みデータ量課金」モードを使用している場合、ルールベースのデータ消費は無料です。ただし、Simple Log Service のパブリックエンドポイントからデータを取得する場合は、インターネット経由の読み取りトラフィックに対して課金されます。トラフィックは圧縮後のデータサイズに基づいて計算されます。詳細については、「取り込みデータ量課金モードの課金対象項目」をご参照ください。
-
Logstore が「機能別課金」モードを使用している場合、サーバー側の計算処理に対して課金されます。また、Simple Log Service のパブリックエンドポイントを利用する場合は、インターネットトラフィックに対しても課金される可能性があります。詳細については、「機能別課金モードの課金対象項目」をご参照ください。
コンシューマー
以下の表に、ルールベースのデータ消費に対応するコンシューマーを示します。
|
タイプ |
コンシューマー |
説明 |
|
マルチ言語アプリケーション |
マルチ言語アプリケーション |
Java、Python、Go などの言語で構築されたアプリケーションは、ルールベースのコンシューマーグループを介して Simple Log Service のデータを消費できます。詳細については、「API を使用したデータ消費」および「コンシューマーグループを用いたログ消費」をご参照ください。 ベストプラクティス:「消費プロセッサ(SPL)を活用した SDK を用いたログ消費」 |
|
クラウドサービス |
Realtime Compute for Apache Flink |
Realtime Compute for Apache Flink を使用して、Simple Log Service のデータをリアルタイムで消費できます。詳細については、「Simple Log Service」をご参照ください。 ベストプラクティス: |
|
ストリームコンピューティング |
Kafka |
この連携を利用するには、チケットを起票してください。 |
注意事項
-
ルールベースのデータ消費は、複雑なサーバー側計算を伴います。SPL クエリの複雑度およびデータ特性に応じて、サーバー側の読み取りレイテンシが若干増加することがあります(例:5 MB のデータで 10 ms ~ 100 ms)。ただし、データ取得からローカルでの処理完了までのエンドツーエンドレイテンシは、通常短縮されます。
-
SPL の構文エラーが発生したり、必要なソースフィールドが欠落している場合、ルールベースのデータ消費は不完全なデータを返すか、失敗する可能性があります。エラー処理の詳細については、「エラー処理」をご参照ください。
-
SPL 文の最大長は 4 KB です。
-
シャードに対する読み取り制限は、ルールベースの消費と通常の消費で同一です。ルールベースの消費では、読み取りトラフィックは SPL 処理前の生データサイズに基づいて計算されます。制限の詳細については、「データの読み書き」をご参照ください。
よくある質問
-
ルールベースのデータ消費中に
ShardReadQuotaExceedエラーが発生した場合、どのように対応すればよいですか?-
このエラーの対応方法は以下のとおりです。
-
コンシューマークライアントを、このエラー発生時に待機・再試行するように設定します。
-
シャードを手動で分割します。これにより、新規データに対するシャード単位の読み取り速度が低下します。
-
-
-
ルールベースのデータ消費におけるトラフィックのスロットル制御はどのように行われますか?
-
ルールベースのデータ消費に対するスロットリングポリシーは、通常の消費と同一です。詳細については、「データの読み書き」をご参照ください。ルールベースのデータ消費におけるトラフィックは、SPL 処理前の生データサイズに基づいて計算されます。
-
たとえば、圧縮後の生データサイズが 100 MB の場合、SPL 文
* | where method = 'POST'を用いてデータをフィルタリングした結果、クライアントに返される圧縮データは 20 MB になったとしても、読み取りトラフィックは元の 100 MB を基準として計算されます。
-
-
-
ルールベースのデータ消費を有効化した後、プロジェクト監視 ページの「トラフィック/分」チャートにおいて、流出トラフィックの値が低いのはなぜですか?
-
「トラフィック/分」チャートにおける流出トラフィックは、SPL 処理後のデータサイズを示しており、生データサイズではありません。SPL 文に、行フィルタリングや列のプルーニングなどデータ量を削減する処理が含まれている場合、流出値は流入値よりも低くなることがあります。
-