Simple Log Service (SLS) のデータインポート機能を使用すると、Azure Blob からログファイルを一元管理・クエリ・分析のためにインポートできます。現在、最大 5 GB の個別の Azure Blob ファイルをインポート可能です。圧縮ファイルの場合、この制限は圧縮後のサイズに適用されます。
本ドキュメントは Alibaba Cloud の知的財産です。Alibaba Cloud サービスとサードパーティ製品との連携方法について記述しており、サードパーティ企業または製品名を参照する場合があります。
前提条件
-
ログファイルを Azure Blob コンテナにアップロード済みである。
-
Project を作成済み であり、Logstore も作成済み である。
データインポート構成の作成
Simple Log Service コンソール にログインします。
-
データインポート エリアの データインポート タブで、AzureBlob - データインポート を選択します。
-
対象の Project および Logstore を選択し、次へ をクリックします。
-
インポート構成 ステップで、以下のパラメーターを設定します:
パラメーター
説明
タスク名
データインポートタスクの固有の名前です。
表示名
タスクの表示名です。
タスクの説明
データインポートタスクの説明です。
コンテナ名
Azure Blob コンテナの名前です。
アカウント名
Azure Blob アカウントの名前です。
アカウントキー
Azure Blob アカウントへのアクセスキーです。
Azure Blob エンドポイント
Azure Blob Storage のサービスエンドポイントです。
説明パブリッククラウド以外の環境では、必ずエンドポイントを指定してください。たとえば、Azure China の場合、
https://<your_container_name>.blob.core.chinacloudapi.cnを入力します。ファイルパスプレフィックスフィルター
Azure Blob コンテナ内のファイルをパスプレフィックスでフィルタリングし、インポート対象のファイルを特定します。たとえば、インポート対象のすべてのファイルが
csv/ディレクトリ内にある場合、プレフィックスをcsv/に設定します。このパラメーターを指定しない場合、コンテナ内のすべてのファイルがスキャンされます。
説明このパラメーターを指定することを推奨します。コンテナに多数のファイルが存在する場合、フルスキャンによりインポート性能が低下します。
ファイルパス正規表現フィルター
ファイルの完全なファイルパスに一致する正規表現に基づいてファイルをフィルタリングします。一致するパスを持つファイルのみがインポートされます。デフォルトではこのパラメーターは空であり、フィルタリングは行われません。
たとえば、ファイルパスが
testdata/csv/bill.csvの場合、正規表現を(testdata/csv/)(.*)に設定できます。正規表現の詳細については、「正規表現のデバッグ方法」をご参照ください。
ファイル変更時刻フィルター
ファイルの最終変更時刻に基づいてファイルをフィルタリングし、インポート対象のファイルを特定します。
-
すべて:該当するすべてのファイルをインポートします。
-
特定の時刻以降:特定の時刻以降に変更されたファイルをインポートします。
-
特定の時刻範囲内:特定の時刻範囲内で変更されたファイルをインポートします。
データ形式
ソースファイルの解析形式です。
-
CSV:区切り文字で区切られたテキストファイルです。先頭行をフィールド名として使用するか、手動で指定できます。その後の各行はログエントリとして解析されます。
-
1 行 JSON:ファイルを 1 行ずつ読み込み、各行を JSON オブジェクトとして解析します。JSON オブジェクト内のキーがログのフィールド名になります。
-
1 行テキストログ:ファイル内の各行を 1 つのログエントリとして解析します。
-
複数行テキストログ:複数行のログエントリをサポートします。正規表現を使用してエントリの先頭行または末尾行を特定できます。
圧縮形式
ソースファイルの圧縮形式です。Simple Log Service は指定された形式でファイルを解凍・読み取ります。
エンコード形式
ソースファイルの文字コードです。UTF-8 および GBK のみがサポートされています。
新規ファイル確認間隔
対象の Azure Blob ファイルパスに継続的に新規ファイルが生成される場合、要件に応じて 新規ファイル確認間隔 を設定できます。間隔を設定後、インポートタスクはバックグラウンドで継続実行され、新規ファイルを自動かつ定期的に検出・読み取ります(バックエンドでは、同一 Azure Blob ファイルのデータが Simple Log Service に重複して書き込まれないよう保証されます)。
パスに新規ファイルが追加されない場合は、確認しない を選択します。タスクは、条件に合致する既存のすべてのファイルをインポートした後に自動停止します。
ログ時刻の構成
時刻フィールド
データ形式 を CSV または 1 行 JSON に設定した場合、データ内のフィールドをログのタイムスタンプとして指定できます。
時刻抽出正規表現
ログエントリからタイムスタンプを正規表現で抽出します。
たとえば、サンプルログが 127.0.0.1 - - [10/Sep/2018:12:36:49 0800] "GET /index.html HTTP/1.1" の場合、時刻抽出正規表現 を
[0-9]{0,2}\/[0-9a-zA-Z]+\/[0-9:,]+に設定できます。説明その他のデータ形式でも、時刻フィールドの一部を正規表現で抽出できます。
時刻フィールド形式
時刻フィールドの解析に使用する形式を指定します。
-
Java
SimpleDateFormat構文(例:yyyy-MM-dd HH:mm:ss)をサポートします。構文の詳細については、「Class SimpleDateFormat」をご参照ください。一般的な時刻形式については、「時刻形式」をご参照ください。 -
エポック形式(
epoch、epochMillis、epochMicro、epochNano)もサポートします。
タイムゾーン
時刻フィールドのタイムゾーンです。エポック形式のタイムスタンプではこのパラメーターは不要です。
タイムスタンプが夏時間を考慮する必要がある場合は、UTC 基準の形式を選択してください。それ以外の場合は、GMT 基準の形式を選択してください。
説明デフォルトのタイムゾーンは UTC + 08:00 です。
データ形式 を CSV または 複数行テキストログ に設定した場合、追加のパラメーターを構成する必要があります。
-
CSV 固有のパラメーター
パラメーター
説明
デリミタ
フィールドを区切る文字です。デフォルトはカンマ (,) です。
引用符
文字列値を囲む文字です。
エスケープ文字
特殊文字をエスケープする文字です。デフォルトはバックスラッシュ (\) です。
先頭行をフィールド名として使用
先頭行をフィールド名として使用 を有効化すると、CSV ファイルの先頭行がフィールド名として使用されます。
カスタムフィールドリスト
先頭行をフィールド名として使用 が無効な場合、出現順にフィールド名を定義する必要があります。複数の名前はカンマ (,) で区切ります。
行をスキップ
ファイル先頭からスキップする行数です。たとえば、値を 1 に設定すると、2 行目からログ収集を開始します。
-
複数行テキストログ固有のパラメーター
パラメーター
説明
正規表現マッチ位置
正規表現を用いてログエントリを特定する方法を指定します:
-
先頭行正規表現:ログエントリの先頭行にマッチします。マッチしない後続の行は、最大行数に達するまで現在のログエントリに追加されます。
-
末尾行正規表現:ログエントリの末尾行にマッチします。マッチするまで、または最大行数に達するまで行がバッファーされます。
正規表現
ログ内容に応じて正規表現を入力します。
詳細については、「正規表現のデバッグ方法」をご参照ください。
最大行数
1 つのログエントリが占める最大行数です。
-
-
-
プレビュー をクリックして、インポート結果を確認します。
-
プレビューを確認後、次へ をクリックします。
-
データをプレビューし、インデックスを構成して、次へ をクリックします。
デフォルトでは、Simple Log Service はフルテキストインデックスを有効化しています。また、収集されたログに基づき、フィールドインデックスを手動で作成 することもできます。あるいは、インデックスの自動生成 をクリックして、フィールドインデックスを自動生成することもできます。
重要ログのクエリおよび分析を行うには、フルテキストインデックスまたはフィールドインデックスのいずれかを有効化する必要があります。両方を有効化した場合、フィールドインデックスが優先されます。
インポート構成の表示
インポート構成を作成後、コンソールでその構成および統計レポートを表示できます。
-
Projects セクションで、対象の Project をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。対象の Logstore を見つけ、 を選択し、構成名をクリックします。
-
インポート構成の基本情報および統計レポートを表示します。
-
構成を変更、開始、停止、または削除することもできます。
警告削除した構成は復元できません。十分にご注意ください。
課金
Simple Log Service のデータインポート機能は無料です。ただし、データ転送および API リクエストに対して、サードパーティのサービスプロバイダーから料金が発生する場合があります。最終的な費用は、プロバイダーの請求書に基づきます。
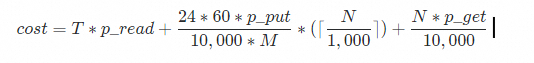
|
フィールド |
説明 |
|
|
1 日あたりのインポート総データ量(GB 単位)。 |
|
|
1 GB あたりのデータ送信料金。 |
|
|
10,000 回の PUT リクエストあたりの料金。 |
|
|
10,000 回の GET リクエストあたりの料金。 |
|
|
新規ファイルの確認間隔(分単位)。 データインポート構成の作成時に 新規ファイル確認間隔 を設定できます。 |
|
|
指定されたプレフィックスに一致するコンテナ内のファイル数。 |
よくある質問
|
問題 |
考えられる原因 |
解決策 |
|
プレビューにデータが表示されません。 |
Azure Blob コンテナにファイルが存在しない、ファイルが空である、またはフィルター条件に一致するファイルがない。 |
|
|
データに文字化けが発生しています。 |
データ形式、圧縮形式、またはエンコード形式の設定が誤っている。 |
Azure Blob ファイルの実際の形式を確認し、データ形式、圧縮形式、エンコード形式などの構成設定を調整してください。 既に文字化けしているデータを修正するには、新しい Logstore および新しいインポート構成を作成する必要があります。 |
|
SLS に表示されるタイムスタンプがソースデータのタイムスタンプと一致しません。 |
ログ時刻フィールドが指定されていない、または構成時に時刻形式またはタイムゾーンの設定が誤っている。 |
ログ時刻フィールドを指定 し、正しい時刻形式およびタイムゾーンを設定してください。 |
|
インポート後にデータをクエリまたは分析できません。 |
|
|
|
インポートされたログエントリ数が想定より少ない。 |
一部のファイルに 3 MB を超える行が含まれており、インポート時に除外されています。詳細については、「収集制限」をご参照ください。 |
Azure Blob コンテナにデータを書き込む際に、1 行が 3 MB を超えないようにしてください。 |
|
多数のファイルおよび大量のデータ量にもかかわらず、インポート速度が予想より遅い(通常は最大 80 MB/s)。 |
Logstore のシャード数が少なすぎます。詳細については、「パフォーマンス制限」をご参照ください。 |
Logstore のシャード数が少ない場合、シャード数を 10 個以上に増やしてレイテンシーを監視してみてください。詳細については、「シャードの管理」をご参照ください。 |
|
一部のファイルがインポートされませんでした。 |
フィルター条件の設定が誤っている、または一部のファイルが 5 GB を超えています。詳細については、「収集制限」をご参照ください。 |
|
|
複数行テキストログが正しく解析されません。 |
先頭行または末尾行の正規表現が誤っています。 |
先頭行または末尾行の正規表現が正しいか確認してください。 |
|
新規ファイルのインポートに高レイテンシーが発生しています。 |
ファイルパスプレフィックスフィルターに一致する既存のファイル数が多すぎます。 |
プレフィックスに一致するファイル数が 100 万を超えると、新規ファイルの検出効率が低下します。より具体的なプレフィックスを使用し、複数のインポートタスクを作成することを推奨します。 |
エラー処理
|
エラー |
説明 |
|
ファイルの読み取りに失敗しました |
ネットワーク障害またはファイルの破損によりファイルの読み取り中にエラーが発生した場合、インポートタスクは自動的に再試行します。3 回の再試行後も読み取りに失敗した場合、ファイルはスキップされます。 再試行間隔は新規ファイル確認間隔と同じです。新規ファイル確認間隔が「確認しない」に設定されている場合、再試行間隔は 5 分です。 |
|
圧縮形式の解析エラー |
ファイルの解凍時に無効な圧縮形式エラーが発生した場合、インポートタスクはファイルをスキップします。 |
|
データ形式の解析エラー |
データの解析に失敗した場合、インポートタスクは元の生テキストをログの content フィールドに格納します。 |
|
コンテナが存在しません |
インポートタスクは定期的に再試行します。コンテナが再作成されると、インポートタスクは自動的に再開します。 |
|
権限エラー |
コンテナからの読み取りまたは Logstore への書き込み時に権限エラーが発生した場合、インポートタスクは定期的に再試行し、権限問題が解決されると自動的に再開します。 権限エラーによりインポートタスクがファイルをスキップすることはありません。問題が解決された後、タスクは未処理のファイルから自動的にデータをインポートします。 |