Simple Log Service (SLS) を使用すると、Amazon S3 からログファイルをインポートして、クエリ、分析、処理を行えます。最大 5 GB の単一 S3 オブジェクトがサポートされています (圧縮オブジェクトの場合は圧縮後のサイズが適用されます)。
前提条件
-
ログファイルを Amazon S3 にアップロードしておきます。
-
プロジェクトと Logstore を作成しておきます。詳細については、「プロジェクトの管理」、「Logstore の作成」をご参照ください。
-
カスタム権限を設定しておきます:
-
次の例に示すように、S3 リソースを管理する権限を付与するカスタムポリシーを作成します (AWS:カスタム権限セット)。
説明SLS にファイルをインポートするには、カスタム S3 権限が必要です。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::your_bucket_name", "arn:aws:s3:::your_bucket_name/*" ] } ] } -
SQS リソースを管理する権限を付与するカスタムポリシーを作成します (AWS:カスタム権限セット)。
説明これは、SQS 統合を有効にする場合にのみ必要です。
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "sqs:ReceiveMessage", "sqs:DeleteMessage", "sqs:GetQueueAttributes", "kms:Decrypt" ], "Resource": "*" } ] }
-
データインポート設定の作成
Log Serviceコンソールにログインします。
-
データのインポート > データのインポート に移動し、[S3 - データインポート] を選択します。
-
インポート先のプロジェクトと Logstore を選択し、次へ をクリックします。
-
インポート設定を設定します。
-
インポート設定 ステップで、次のパラメーターを設定します。
パラメーター
説明
[タスク名]
データインポートジョブの一意の名前です。
[S3 リージョン]
ソースバケットがあるリージョンです。
AWS アクセスキー ID
AWS アカウントへのアクセスに使用する AWS アクセスキー ID です。
重要アクセスキー ID に、関連する AWS リソースへのアクセスに必要な権限があることを確認してください。
AWS シークレットアクセスキー
アクセスキー ID に対応する AWS シークレットアクセスキーです。
SQS キュー URL
SQS キューの URL です (AWS:キューとメッセージの識別子)。
重要このパラメーターは、SQS 統合を有効にする場合にのみ必要です。
[ファイルパスプレフィックスのフィルタリング]
キープレフィックスによって S3 オブジェクトをフィルターします。たとえば、プレフィックスを
csv/に設定すると、そのディレクトリ内のオブジェクトのみをインポートします。このパラメーターを空のままにすると、S3 バケット全体をスキャンします。
説明大規模なバケットにはプレフィックスを設定してください。バケット全体をスキャンすると、インポートが遅くなります。
[ファイルパスの正規表現によるフィルタリング]
正規表現に一致する完全なオブジェクトパスで S3 オブジェクトをフィルターします。一致するオブジェクトのみをインポートします。デフォルトでは空です (フィルターなし)。
たとえば、S3 オブジェクトが
testdata/csv/bill.csvにある場合、正規表現を(testdata/csv/)(.*)に設定できます。[ファイル変更時間のフィルタリング]
最終変更時刻によって S3 オブジェクトをフィルターします。
-
すべて: 指定の条件を満たすすべてのオブジェクトをインポートする場合に選択します。
-
特定の時間に開始されます: 特定の時点以降に変更されたオブジェクトをインポートする場合に選択します。
-
指定期間内: 特定の時間範囲内に変更されたオブジェクトをインポートする場合に選択します。
[データフォーマット]
ログファイルを解析するための形式です:
-
[CSV]: 区切り文字で区切られたテキスト。ファイルの最初の行をフィールド名として使用するか、手動でフィールド名を指定できます。後続の各行は、ログエントリの値として解析します。
-
シングルライン JSON: S3 オブジェクトを 1 行ずつ読み取り、各行を JSON オブジェクトとして解析します。JSON オブジェクトのキーがログのフィールド名になります。
-
シングルラインテキスト: S3 オブジェクトの各行を個別のログエントリとして解析します。
-
マルチラインテキスト: 複数行を単一のログエントリとして解析します。ログエントリの開始または終了に一致する正規表現を指定する必要があります。
[圧縮フォーマット]
ソース S3 オブジェクトの圧縮形式です。SLS は、データを読み取る前に、選択した形式でオブジェクトを解凍します。
[エンコード形式]
ソース S3 オブジェクトのエンコーディング形式です。UTF-8 と GBK のみがサポートされています。
[新しいファイルのチェックサイクル]
新しいオブジェクトがソース S3 パスに継続的に追加される場合は、必要に応じて 新しいファイルのチェックサイクル を設定します。インポートジョブは、定期的に新しいオブジェクトを検出して読み取ります。各 S3 オブジェクトは最大 1 回インポートします。
新しいオブジェクトが追加されない場合は、今後はチェックしない を選択します。ジョブは、一致するすべてのオブジェクトをインポートした後に停止します。
[ログタイムの設定]
[時間]
データフォーマット で [CSV] または シングルライン JSON を選択した場合、タイムスタンプを含むフィールドを指定できます。SLS はこのフィールドをログのタイムスタンプとして使用します。
[時間フィールド抽出の正規表現]
正規表現を使用して、ログコンテンツからタイムスタンプを抽出できます。
たとえば、サンプルログエントリが
127.0.0.1 - - [10/Sep/2018:12:36:49 0800] "GET /index.html HTTP/1.1"の場合、時間フィールド抽出の正規表現 を[0-9]{0,2}\/[0-9a-zA-Z]+\/[0-9:,]+に設定できます。説明他のデータ形式の場合も、正規表現を使用して時間フィールドの一部のみを抽出できます。
[時刻フィールドの形式]
時間フィールドの値を解析するために使用する形式です。
-
yyyy-MM-dd HH:mm:ssなどの Java SimpleDateFormat 構文をサポートします。詳細については、「時間形式」をご参照ください。 -
epoch、epochMillis、epochMicro、epochNano などのエポック形式をサポートします。
[タイムゾーン]
時間フィールドのタイムゾーンを選択します。エポック形式にはタイムゾーンは必要ありません。
夏時間を考慮するには、UTC 形式を選択します。それ以外の場合は、GMT 形式を選択します。
説明デフォルトのタイムゾーンは UTC+8 です。
[データ形式] で データフォーマット を選択した場合は、次の表に示す追加のパラメーターを設定する必要があります。
-
CSV 固有のパラメーター
パラメーター
説明
[区切りモード]
フィールドを区切るために使用する区切り文字です。デフォルト値はカンマ (,) です。
[引用符]
CSV 文字列に使用する引用符です。
[クォート]
特殊文字をエスケープするために使用するエスケープ文字です。デフォルト値はバックスラッシュ (\) です。
[ログがまたぐ行の最大数]
最初の行フィールド名として使用 を有効にすると、CSV ファイルの最初の行がフィールド名になります。
[カスタムフィールド]
最初の行フィールド名として使用 を無効にした場合は、ログのカスタムフィールド名を指定する必要があります。複数のフィールド名はカンマ (,) で区切ります。
[スキップ行数]
ファイルの先頭からスキップするログ行の数です。たとえば、これを 1 に設定すると、データ収集は CSV ファイルの 2 行目から開始します。
-
複数行テキストログ固有のパラメーター
パラメーター
説明
[正規表現と一致する位置]
正規表現を照合する位置です。次のオプションが利用可能です:
-
最初の行のみに一致する正規表現: 正規表現を使用してログエントリの最初の行を照合します。一致しない行は、最大行数に達するまで現在のログエントリの一部と見なします。
-
最終行のみに一致する正規表現: 正規表現を使用してログエントリの最後の行を照合します。一致しない行は、最大行数に達するまで次のログエントリの一部と見なします。
[正規表現]
ログエントリの開始または終了を定義する正規表現です。
[最大ライン]
1 つのログエントリの最大行数です。
-
-
-
プレビュー をクリックしてインポート結果を確認します。
-
設定を確認した後、次へ をクリックします。
-
-
データをプレビューし、インデックスを作成してから、次へ をクリックします。
SLS は、デフォルトでフルテキストインデックスを有効にします。フィールドインデックスを手動で作成するか、自動インデックスの生成 をクリックして自動的に生成することもできます。詳細については、「インデックスの作成」をご参照ください。
重要ログのクエリと分析を行うには、フルテキストインデックスまたはフィールドインデックスのいずれかを有効にする必要があります。両方が有効な場合、フィールドインデックスが優先されます。
インポート設定の表示
コンソールで設定の詳細と統計レポートを表示できます。
-
プロジェクトリストで、インポート先のプロジェクトをクリックします。
-
セクションで、インポート先の Logstore を見つけ、 を選択し、設定名をクリックします。
-
インポート設定の基本情報と統計レポートが表示されます。
-
インポート設定を変更、開始、停止、または削除することもできます。
警告この操作は元に戻せません。慎重に実行してください。
課金
SLS はデータインポート機能に対して課金しません。ただし、クラウドプロバイダーからのデータ転送および API リクエスト料金が適用される場合があります。次のモデルは、見込まれるコストの概要を示しています。実際の料金については、プロバイダーの請求書をご参照ください。
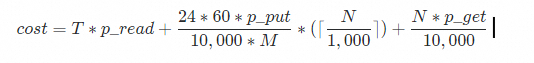
|
フィールド |
説明 |
|
|
1 日あたりの総データインポート量 (GB) です。 |
|
|
アウトバウンドインターネットトラフィックの GB あたりのコストです。 |
|
|
10,000 PUT リクエストあたりのコストです。 |
|
|
10,000 GET リクエストあたりのコストです。 |
|
|
新規ファイルチェック間隔 (分) です。 データインポート設定の作成時に、[新規ファイルチェック周期] を設定できます。 |
|
|
指定のプレフィックスに一致するバケット内のリスト可能なオブジェクトの数です。 |
よくある質問
|
問題 |
考えられる原因 |
解決策 |
|
プレビューにデータが表示されません。 |
S3 バケットにオブジェクトがない、オブジェクトにデータが含まれていない、またはフィルター条件に一致するオブジェクトがありません。 |
|
|
インポートされたデータに文字化けが含まれています。 |
[データ形式]、[圧縮形式]、または [エンコーディング形式] の設定がソースファイルと一致しません。 |
S3 オブジェクトの実際の形式を確認し、それに応じて [データ形式]、[圧縮形式]、または [エンコーディング形式] の設定を調整してください。 既存の文字化けデータを修正するには、新しい Logstore と新しいインポート設定を作成する必要があります。 |
|
SLS のログタイムスタンプがソースデータのタイムスタンプと一致しません。 |
ログ時間フィールドが指定されていないか、インポート設定で時間形式またはタイムゾーンが正しく設定されていません。 |
ログ時間フィールドを指定し、正しい時間形式とタイムゾーンを設定してください。詳細については、「ログ時間設定」をご参照ください。 |
|
インポート後にデータをクエリまたは分析できません。 |
|
|
|
インポートされたログエントリの数が想定より少ないです。 |
3 MB を超える単一のログエントリは、インポート中に破棄されます (データ収集の制限)。 |
S3 ファイルにデータを書き込む際は、1 行のデータが 3 MB を超えないようにしてください。 |
|
一部のファイルがインポートされません。 |
フィルター条件が正しく設定されていないか、一部のファイルが 5 GB のサイズ制限を超えています (データ収集の制限)。 |
|
|
複数行テキストログが正しく解析されません。 |
最初の行または最後の行に一致する正規表現が正しくありません。 |
最初の行または最後の行に一致する正規表現が正しいことを確認してください。 |
|
新しいファイルのインポートで高いレイテンシーが発生します。 |
ファイルパスプレフィックスフィルターに一致する既存のオブジェクトが多すぎます。 |
ファイルパスプレフィックスフィルターに一致するオブジェクトの数が多すぎる場合 (たとえば、100 万以上)、より具体的なプレフィックスを設定し、複数のインポートジョブを作成してください。そうしないと、新しいファイルの検出が大幅に遅くなります。 |
エラー処理
|
エラー |
説明 |
|
ファイルの読み取り失敗 |
ネットワークの問題、破損、またはその他のエラーが原因でファイルの読み取りに失敗した場合、インポートジョブは最大 3 回再試行した後にファイルをスキップします。 再試行間隔は、[新規ファイルチェック周期] と同じです。[新規ファイルチェック周期] が [チェックしない] に設定されている場合、再試行間隔は 5 分です。 |
|
圧縮形式の解析エラー |
ファイルの解凍中に無効な圧縮形式エラーが発生した場合、インポートジョブはそのファイルをスキップします。 |
|
データ形式の解析エラー |
データ解析に失敗した場合、インポートジョブは元のテキストコンテンツをログの |
|
S3 バケットが存在しません |
インポートジョブは定期的に再試行します。バケットが再作成されると、インポートジョブは自動的に再開されます。 |
|
権限エラー |
S3 からの読み取りまたは Logstore への書き込み時に権限エラーが発生した場合、インポートジョブは定期的に再試行し、権限が修正された後に再開されます。 権限エラー中にファイルがスキップされることはありません。問題が修正されると、ジョブは未処理のすべてのオブジェクトをインポートします。 |