データセットの所有者および データセット Q Chat 構成 権限を持つワークスペース管理者は、Q Chat 構成 および Q Chat 権限構成 を実行できます。必要な権限の取得方法については、「ロール管理」をご参照ください。本トピックでは、データセットに対する Q Chat の設定および権限の構成方法について説明します。
この機能は現在、中国 (香港) リージョンおよび マレーシア (クアラルンプール) リージョンでのみ利用可能です。今後、他のリージョンへ順次展開される予定です。
Q Chat 構成
Quick BI で Q Chat 機能を使用するには、ご利用のデータセットに対して Q Chat 設定を構成する必要があります。
エントリポイント
Q Chat 構成ページには、以下の 2 つの方法でアクセスできます。
方法 1:データセット編集ページで、Q Chat 構成 を開きます。
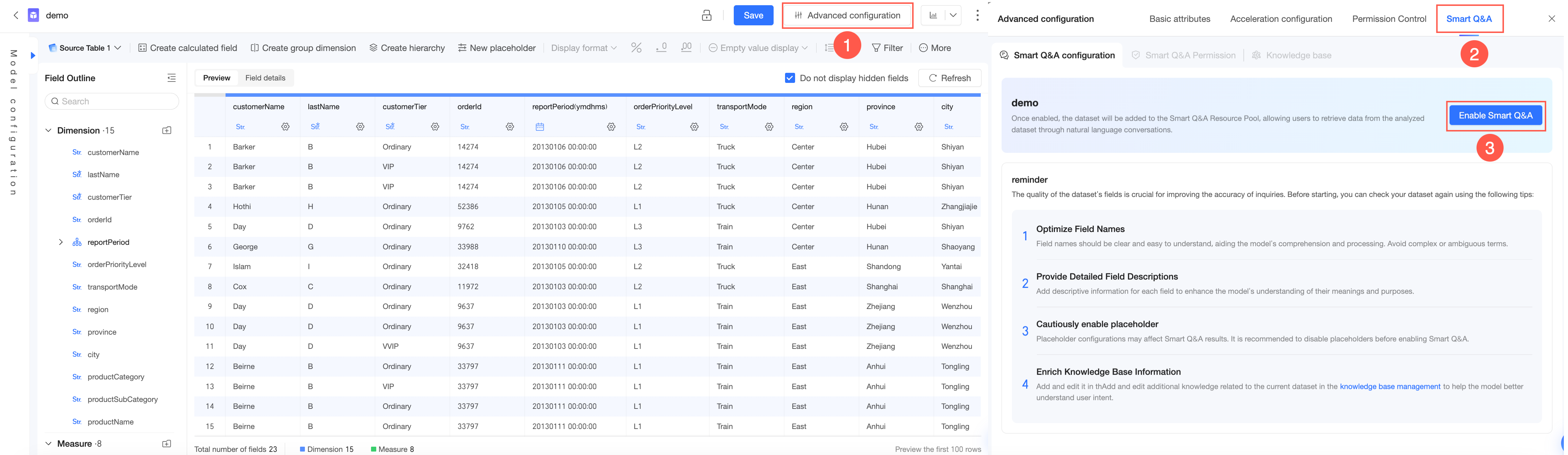
方法 2:データセットを作成する際に、Q Chat 構成 を開きます。
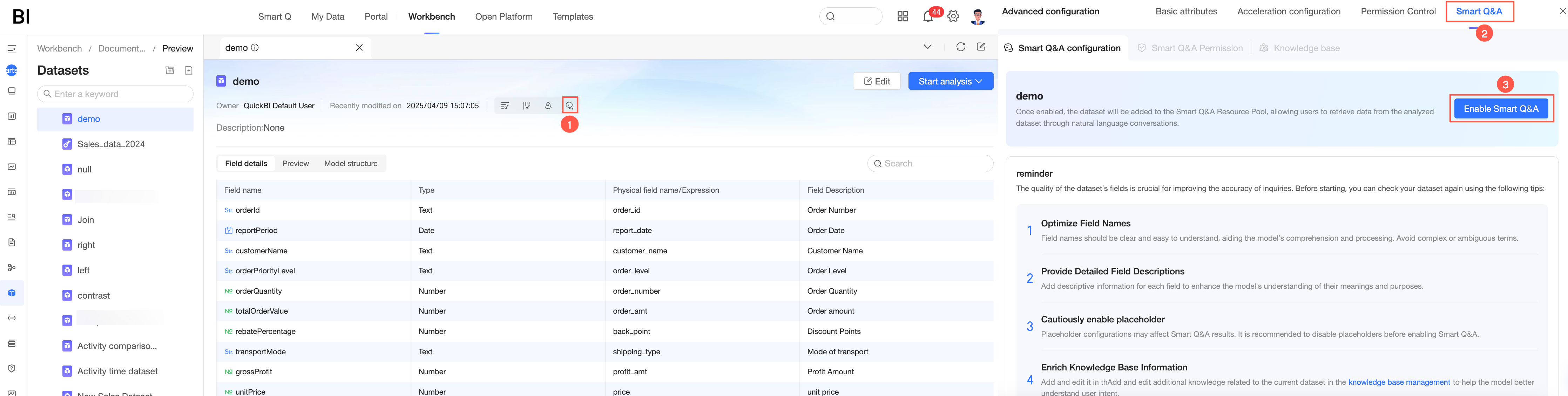
基本情報
Q Chat 構成 ページに移動し、基本情報 を構成します。
Q Chat の精度を向上させるには、データセットのフィールド品質が極めて重要です。作業を開始する前に、以下のベストプラクティスに基づいてデータセットを確認してください。
フィールド名の最適化
フィールド名は明確かつ理解しやすいものにしてください。これにより、大規模言語モデルが正しく処理できます。複雑または曖昧な名前は避けてください。
フィールドの詳細説明の提供
各フィールドに説明を追加することで、モデルがその意味と目的をより正確に理解できるようになります。
プレースホルダーの慎重な使用
プレースホルダーを設定すると、クエリ結果に影響を与える可能性があります。Q Chat 機能を有効化する前に、プレースホルダーを無効にすることを推奨します。
ナレッジベースの充実
ナレッジベース管理セクションで、現在のデータセットに関する補足情報を追加・編集し、大規模言語モデルによるユーザー意図の理解を向上させてください。
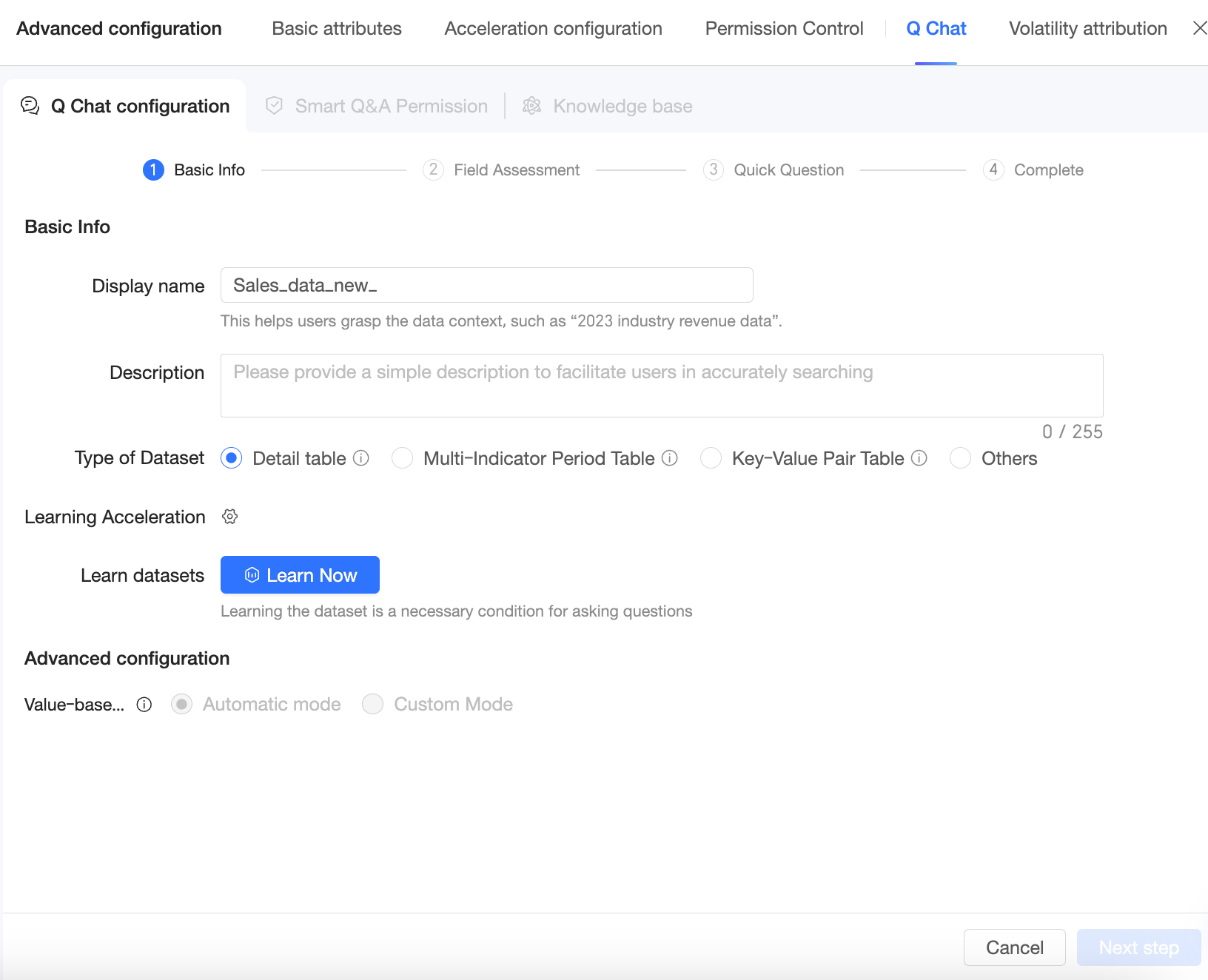
データセットの 表示名 を変更できます。
説明ユーザーに表示されるビジネスフレンドリーな表示名を設定できます。この名前は、ユーザーがデータセットの内容を把握するのに役立ちます(例:「業界別 2023 年売上データ」)。
説明
ユーザーがデータセットを簡単に見つけられるように、簡潔な説明を記述してください。
データセットタイプ
AI アシスタントがデータ構造を理解し、応答精度を向上させるために、データセットタイプを選択してください。サポートされているタイプは、詳細テーブル、マルチメトリック期間テーブル、キー・バリュー・テーブル、その他です。
詳細テーブル
各行に 1 件のレコードを含む詳細情報を表示します。各レコードには複数のディメンション値またはメジャー情報が含まれます(例:「注文 ID、ユーザー ID、注文ステータス、注文金額」)。
マルチメトリック期間テーブル
異なる期間におけるメトリックの統計値を表示します(例:「7 日間累計売上」「15 日間累計売上」「30 日間累計売上」)。
キー・バリュー・テーブル
主に日付、ディメンション、メトリック名、メトリック値のフィールドを含むキー・バリュー形式のテーブルです(例:「集計日」「KPI 名」「KPI 実績値」「KPI 目標値」)。
学習高速化
ワークスペース内のソーステーブルを選択して、各フィールドのディメンション値を提供できます。このプロセスは ディメンション値高速化 とも呼ばれます。
学習高速化の横にある
 アイコンをクリックし、学習高速化 スイッチをオンにします。
アイコンをクリックし、学習高速化 スイッチをオンにします。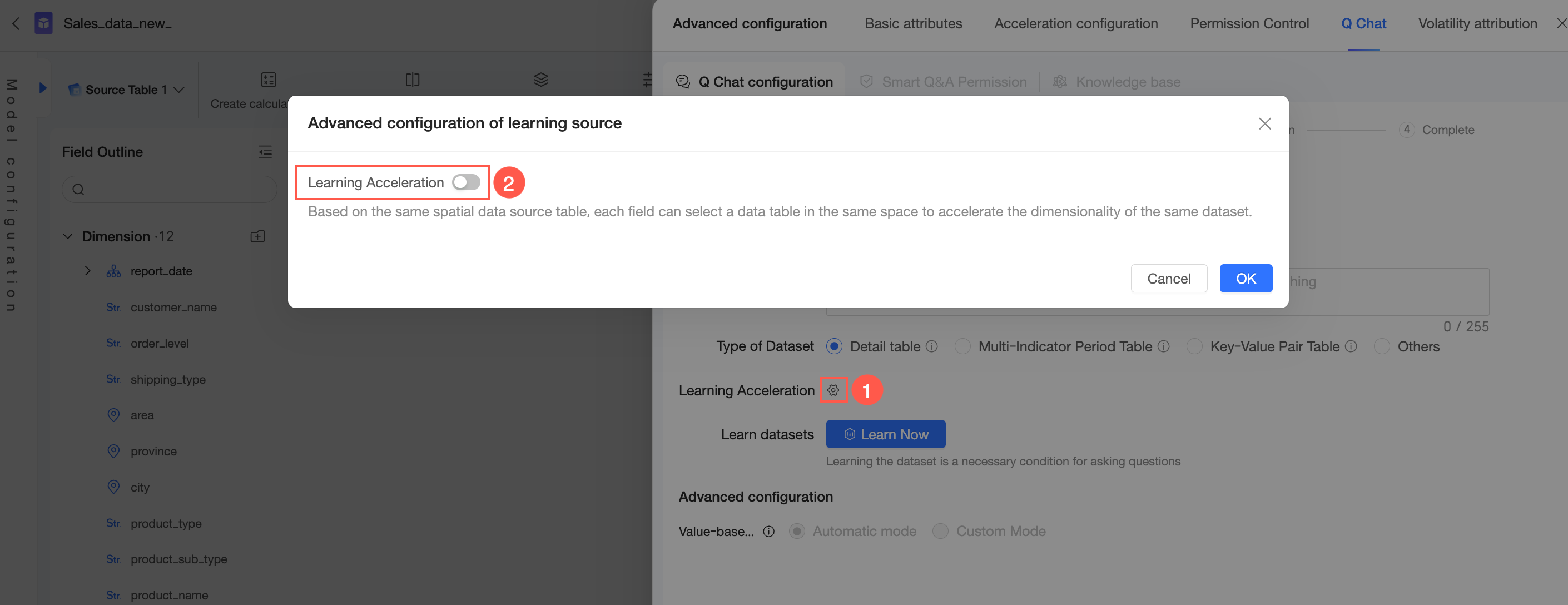
学習ソースの詳細設定ページで、データセットのディメンションフィールドとソーステーブルのフィールドをマッピングします。
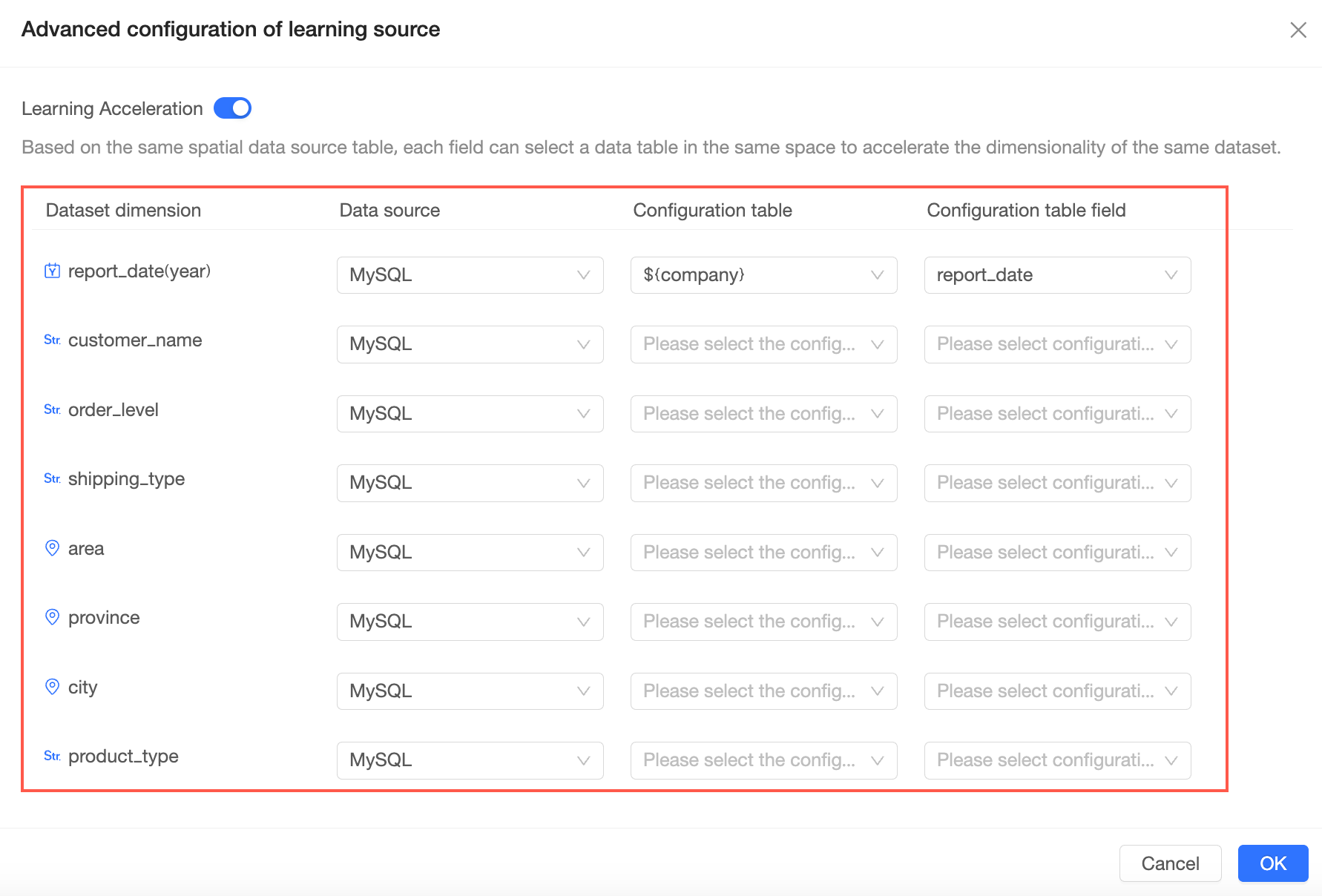
すべてのマッピングを構成したら、[OK] をクリックします。
[今すぐ学習] をクリックして、データセットの学習プロセスを開始します。
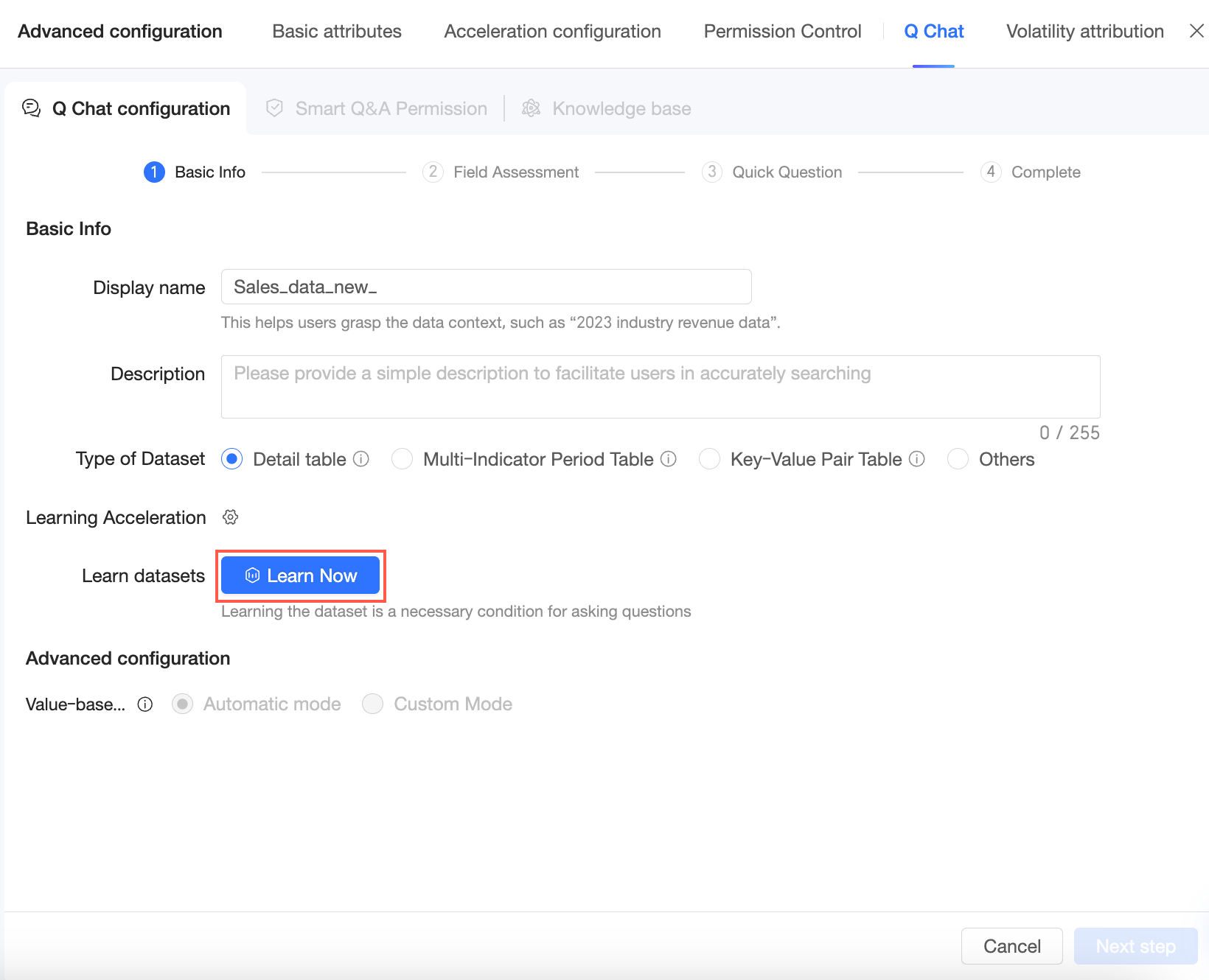
学習プロセスが完了した後、データセットに変更があった場合は [再学習] をクリックできます。
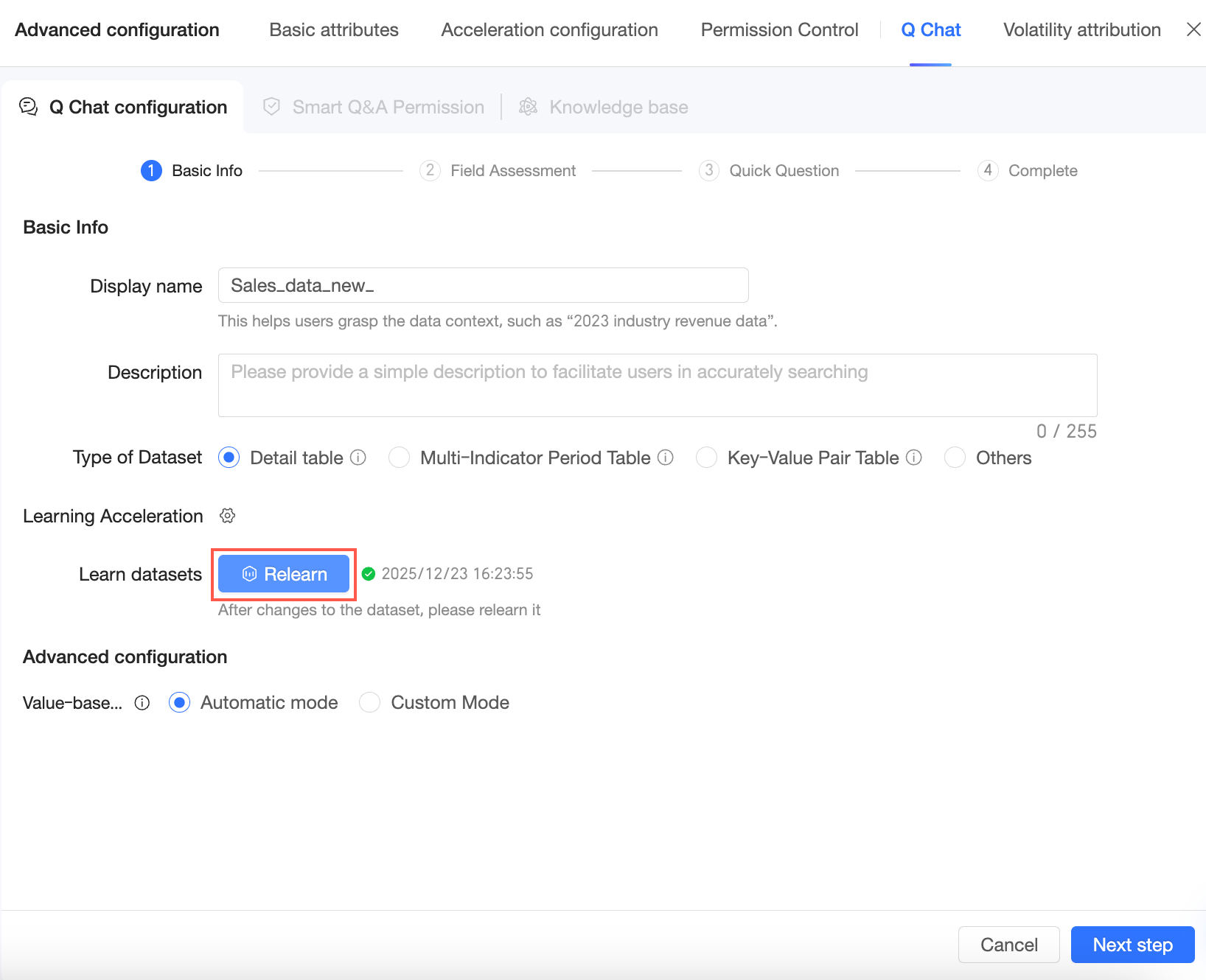
詳細設定で、ディメンション値マッチングモード を構成します。自動モード または カスタムモード を選択できます。
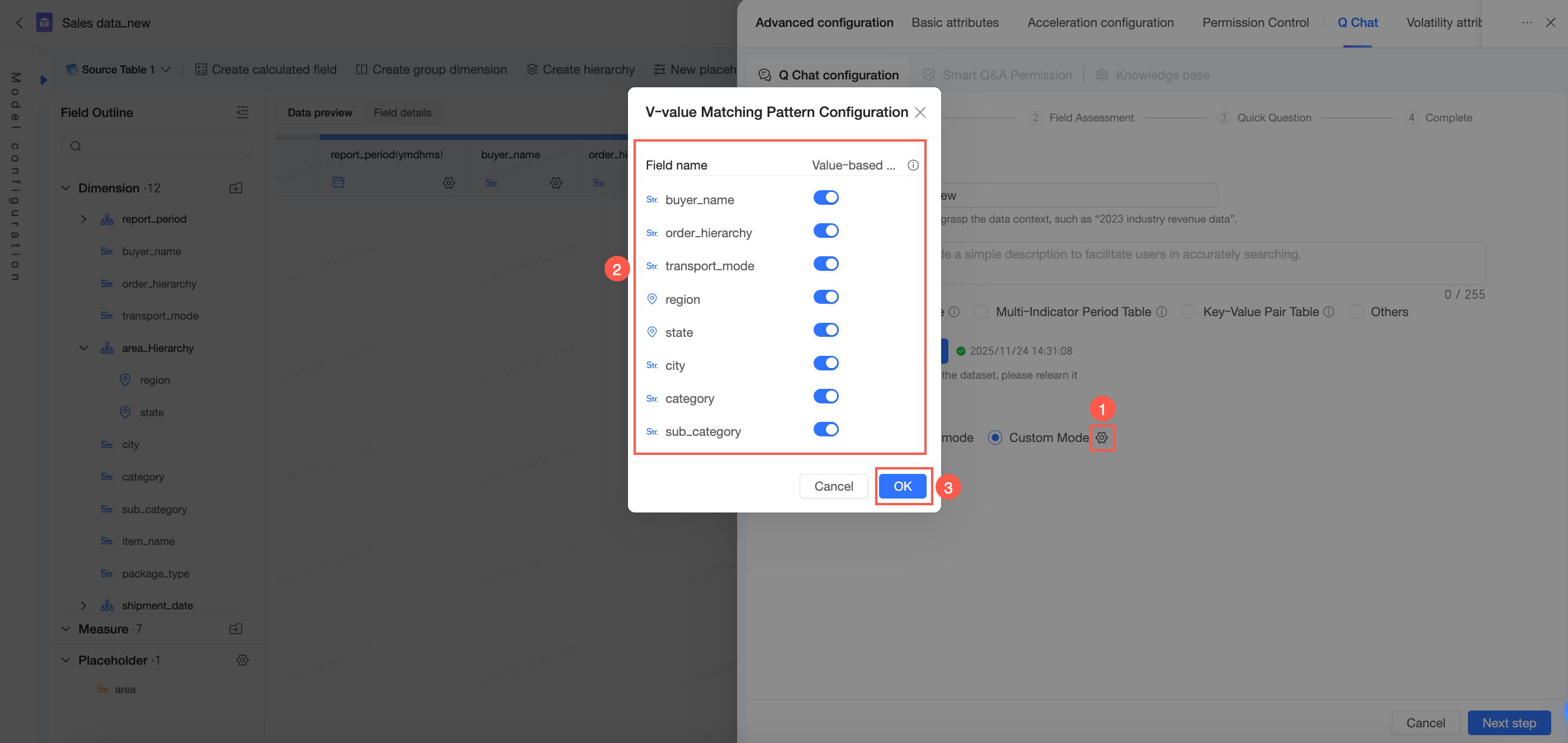
ユーザークエリに学習制限を超えて学習されていないディメンション値が含まれる場合、以下の 2 つのマッチング戦略から選択できます。
自動モード:システムが、ユーザー入力値を既知の学習済み値に書き換えるかどうかを自動的に判断します。
カスタムモード:管理者が各ディメンションごとに書き換えを有効化するかどうかを個別に設定できます。
書き換えを有効化:ユーザー入力値を学習済み値にマッピングすることを許可します。
書き換えを無効化:ユーザーの入力を書き換えずに厳密にマッチングします。
[次へ] をクリックして、フィールド品質評価 ページに進みます。
フィールド品質評価
このページでは、クエリ結果を改善するためにデータセットのフィールド品質を評価します。
[評価を開始] をクリックします。
説明フィールド品質評価には 1~2 分かかる場合があります。次のステップに進んでもかまいません。結果が準備でき次第、通知されます。
評価後、システムが修正提案を提供します。これらの提案は承認または無視できます。
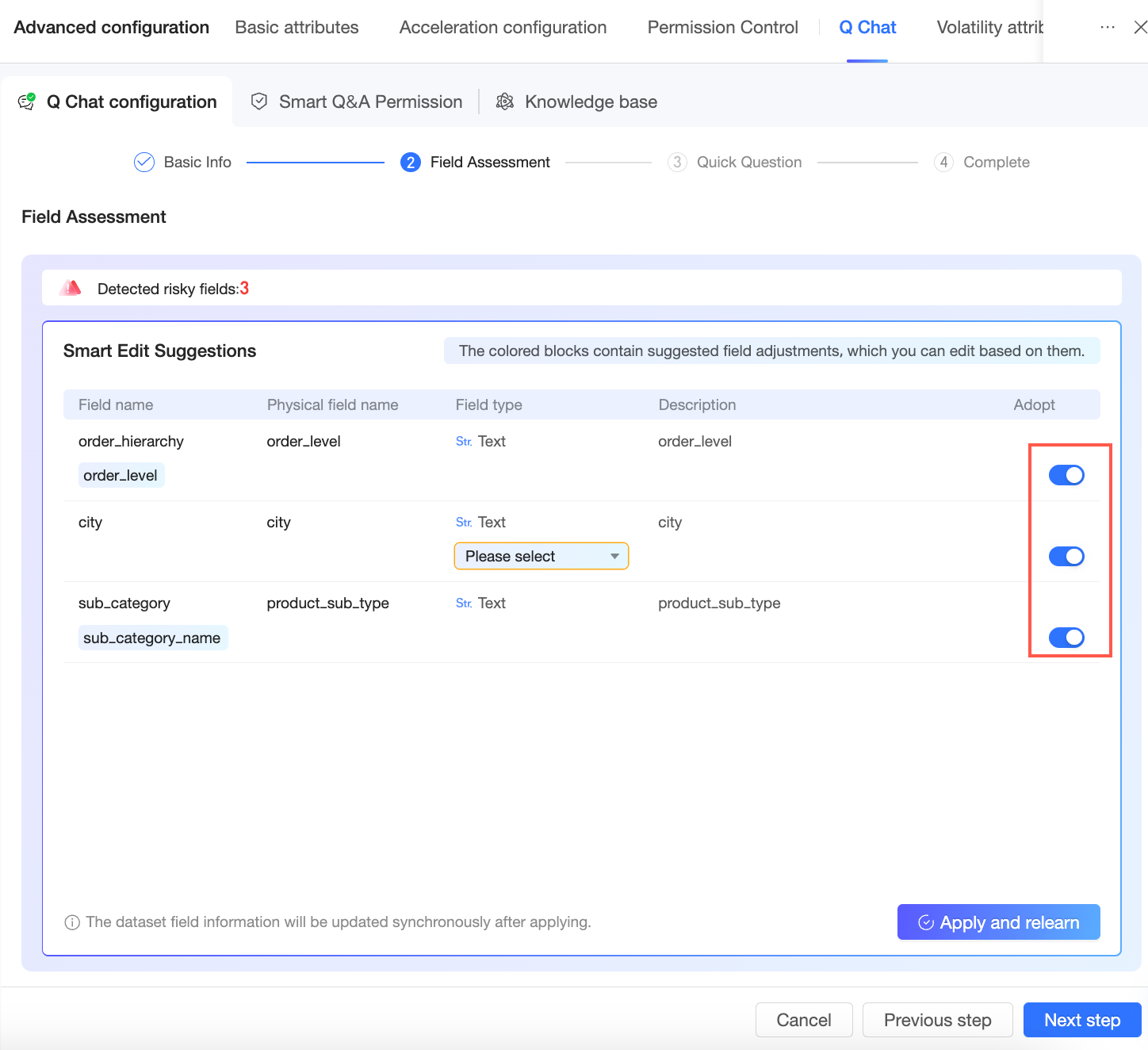
[適用して再学習] をクリックしてデータセットのフィールド情報を更新し、その後 [次へ] をクリックして クイック質問 ページに進みます。
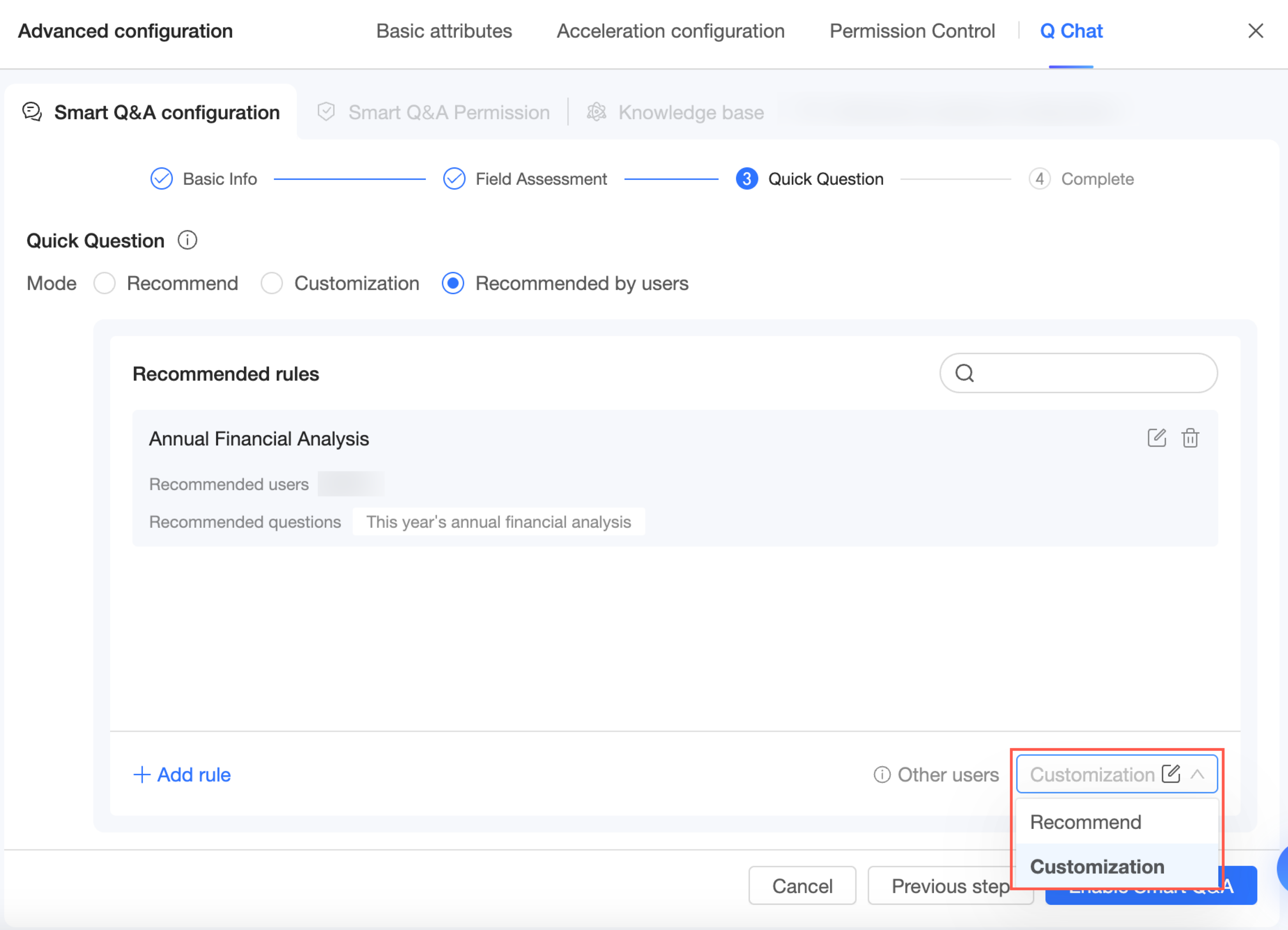
クイック質問
ユーザーがデータセットを選択した後に表示される推奨質問により、ユーザーはすぐに使い始めることができます。サポートされているモードは、システム推奨、エキスパートカスタマイズ、受信者別推奨 の 3 種類です。
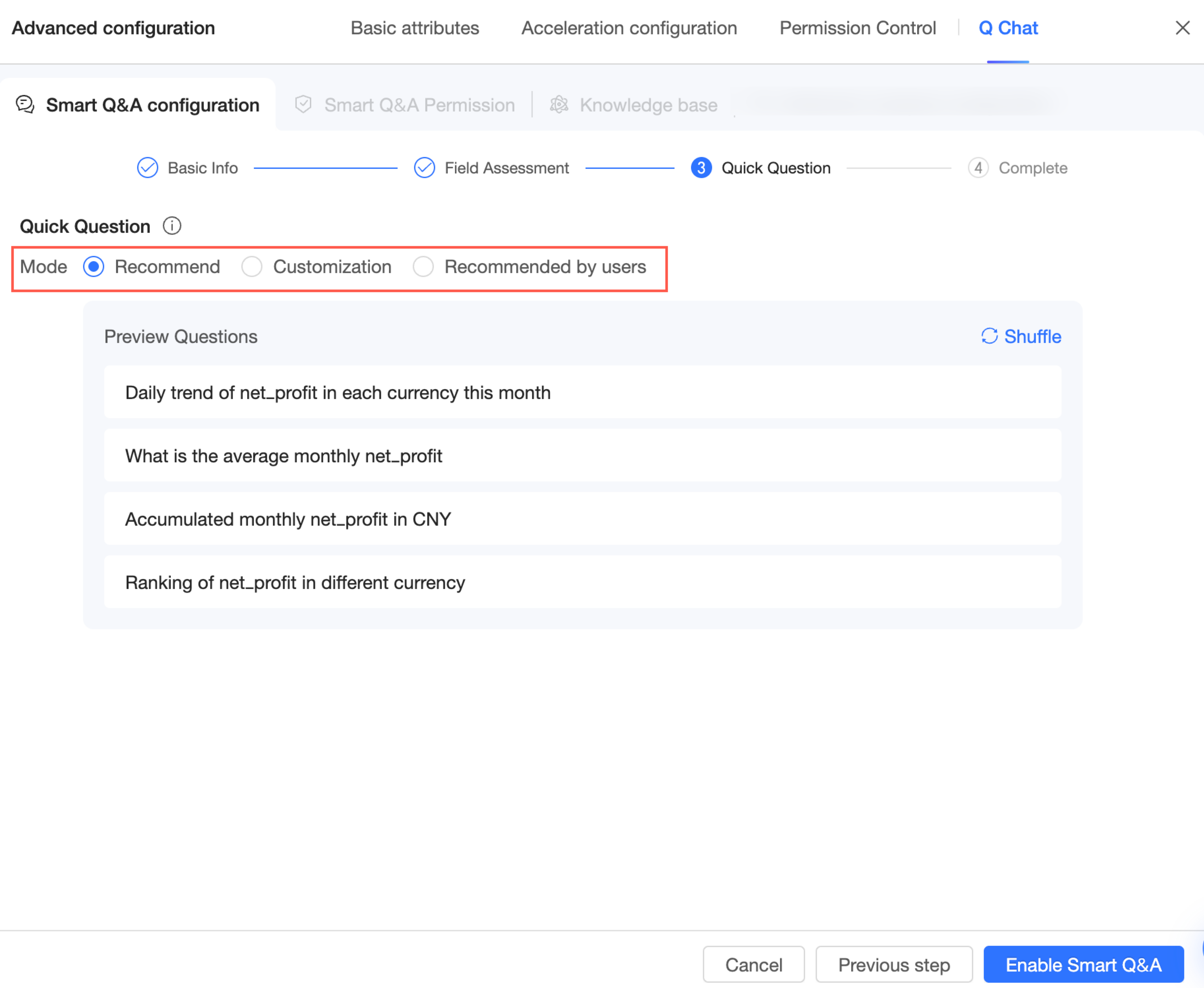
システム推奨
クイック質問をプレビューできます。[更新] をクリックすると、別の質問セットが表示されます。
エキスパートカスタマイズ
このモードでは、[質問を追加] をクリックして、ユーザーに表示させたい質問を入力できます。デフォルトで最初の 4 つの質問が表示されます。4 つを超えて追加した場合、ユーザーは [更新] をクリックして質問を切り替えることができます。
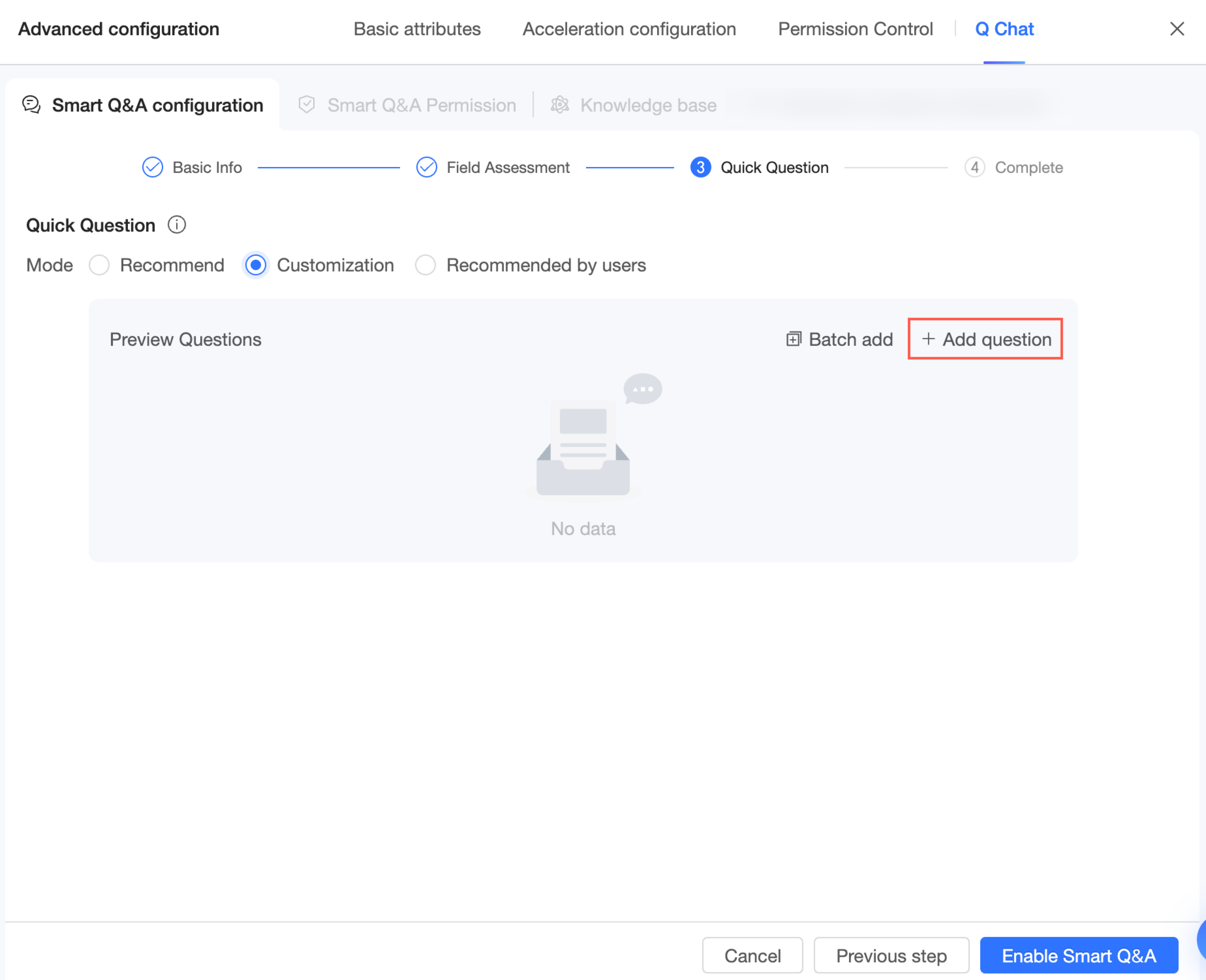
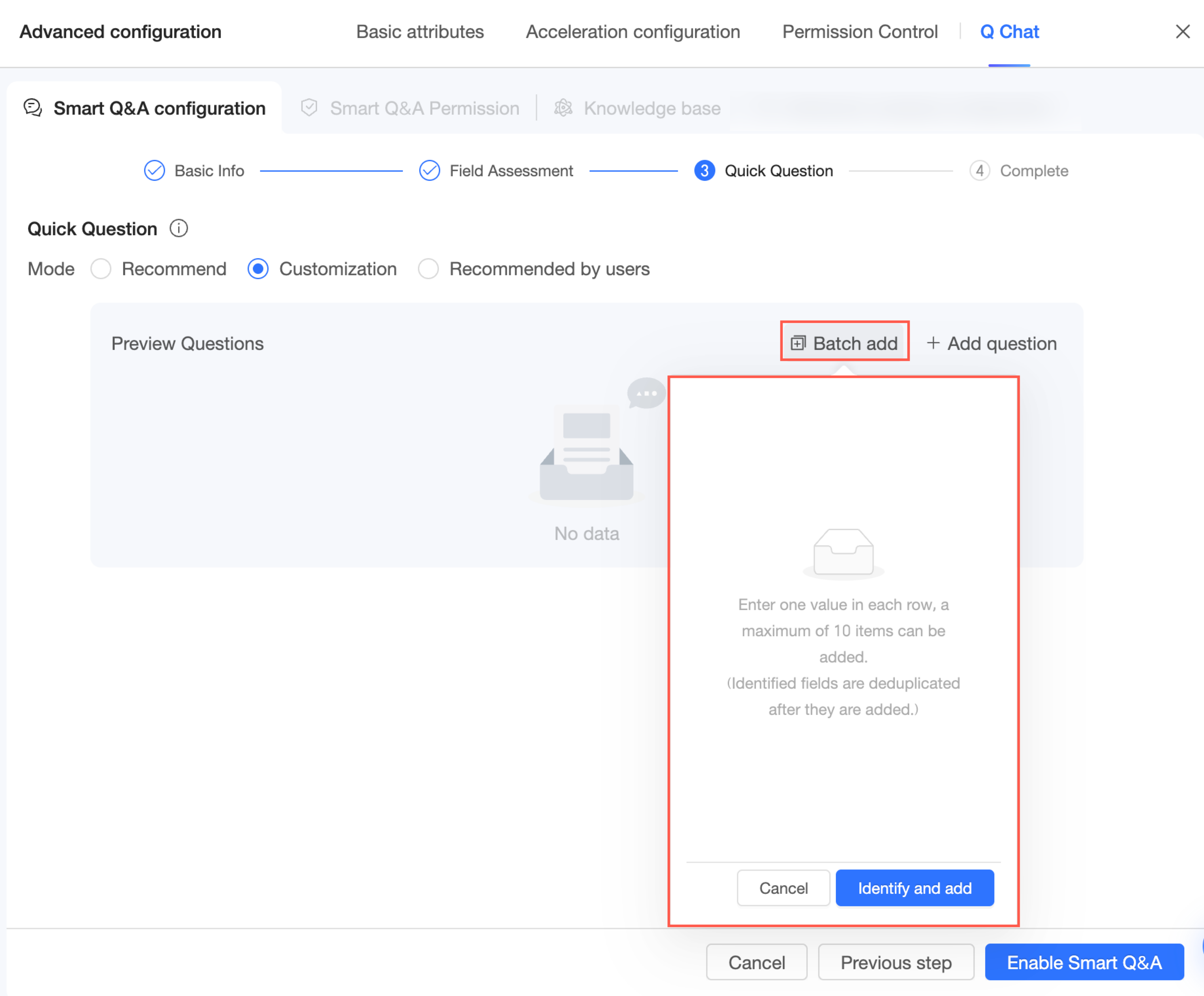
一度に複数の質問を追加する必要がある場合は、[一括追加] をクリックして入力してください。
説明1 行につき 1 つの質問を入力してください。最大 10 個の質問を追加できます。
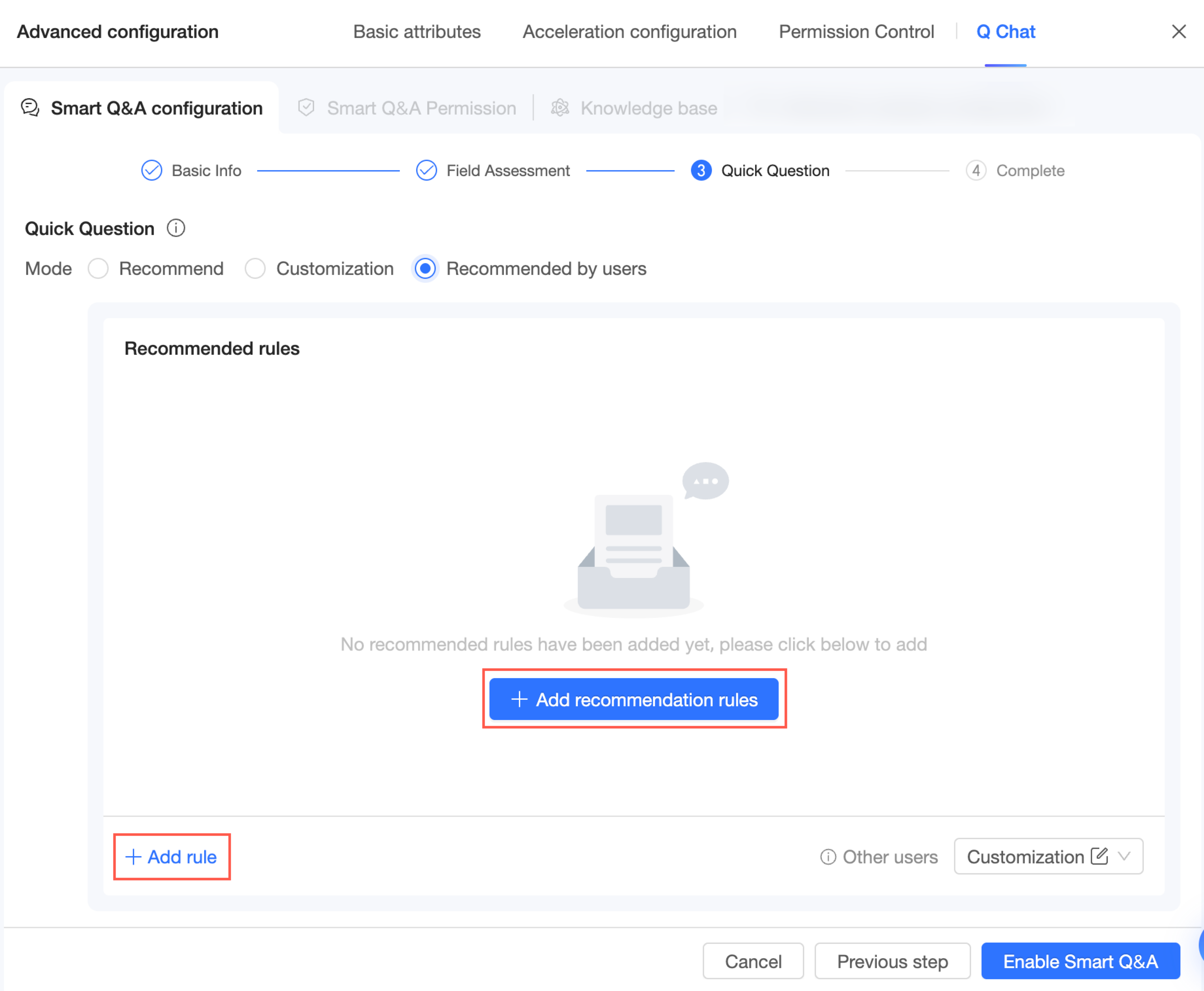
受信者による推奨
受信者別推奨 モードを選択する場合、以下の手順に従ってルールを追加します。
左下隅の [推奨ルールを追加] または [ルールを追加] をクリックします。
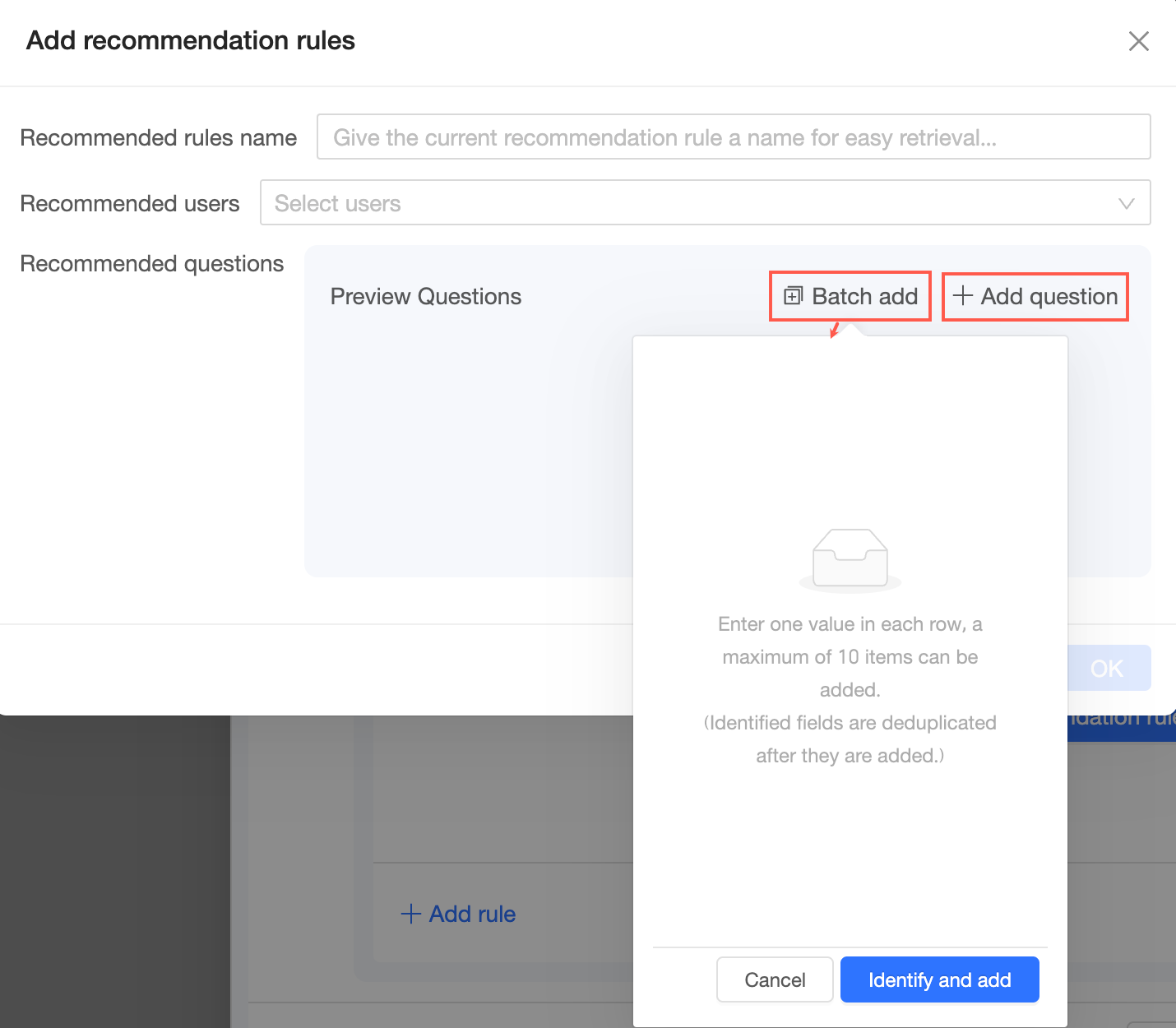
推奨ルールを追加 ページで、ルール名を入力し、推奨対象のユーザーを指定して、推奨質問を追加します。
推奨ルール名:識別しやすい名前を付けてください。
推奨対象:推奨のターゲットとなるユーザーを選択します。
推奨質問:[質問を追加] をクリックして単一の質問を追加するか、[一括追加] をクリックして複数の質問を追加します。
説明最大 10 個の質問を追加できます。
他のユーザー向けのフォールバックルールとして、システム推奨 または エキスパートカスタマイズ のいずれかを選択します。
[変更を確定] をクリックして構成を保存します。
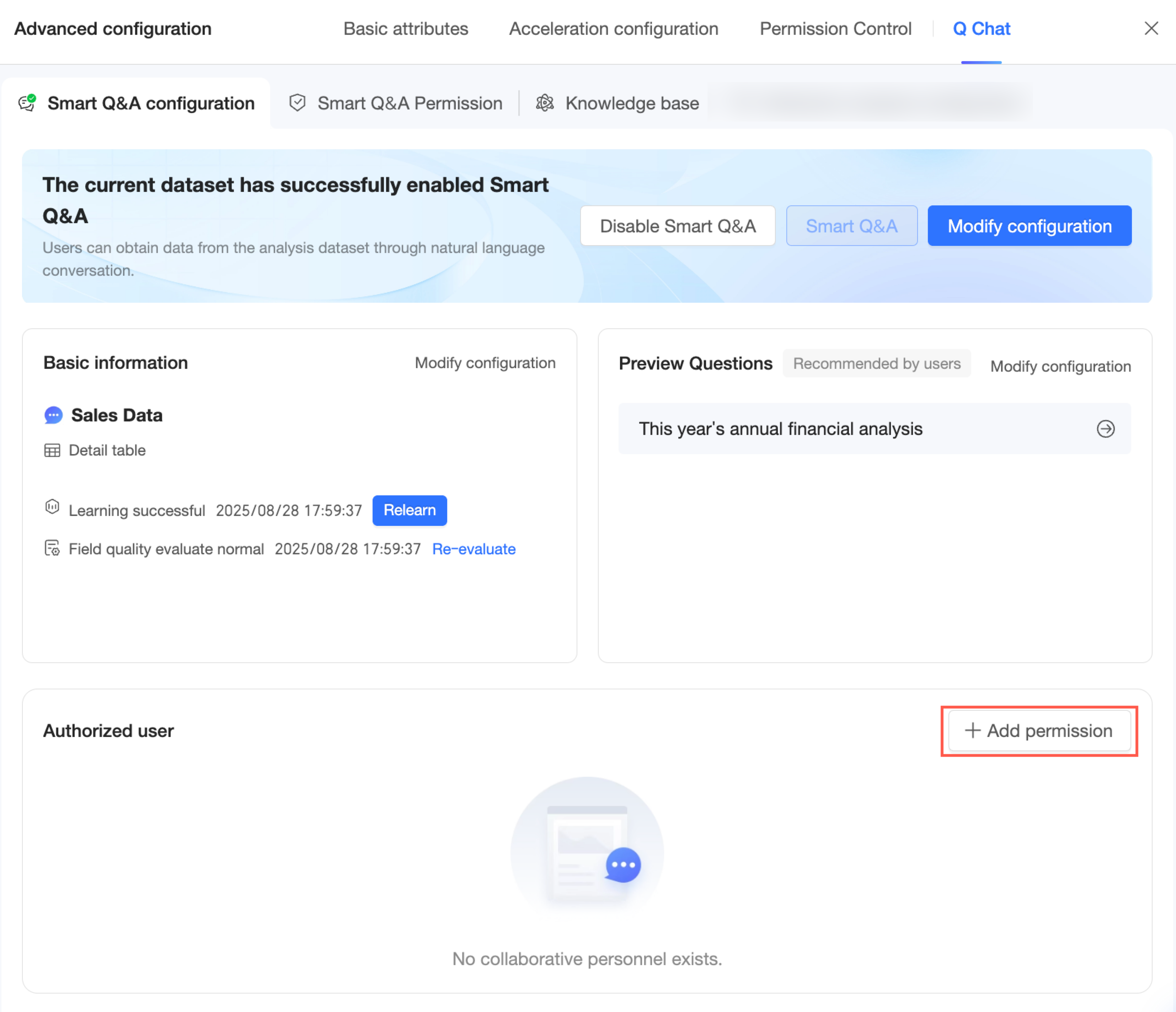
構成が完了したら、[Quick BI Q Chat 権限管理へ移動] をクリックするか、Q Chat 権限 タブをクリックして Q Chat 権限 構成ページに移動できます。このページでは、この Q Chat 対応データセットへのアクセス権限をユーザーに付与できます。詳細については、「Q Chat 権限構成」をご参照ください。
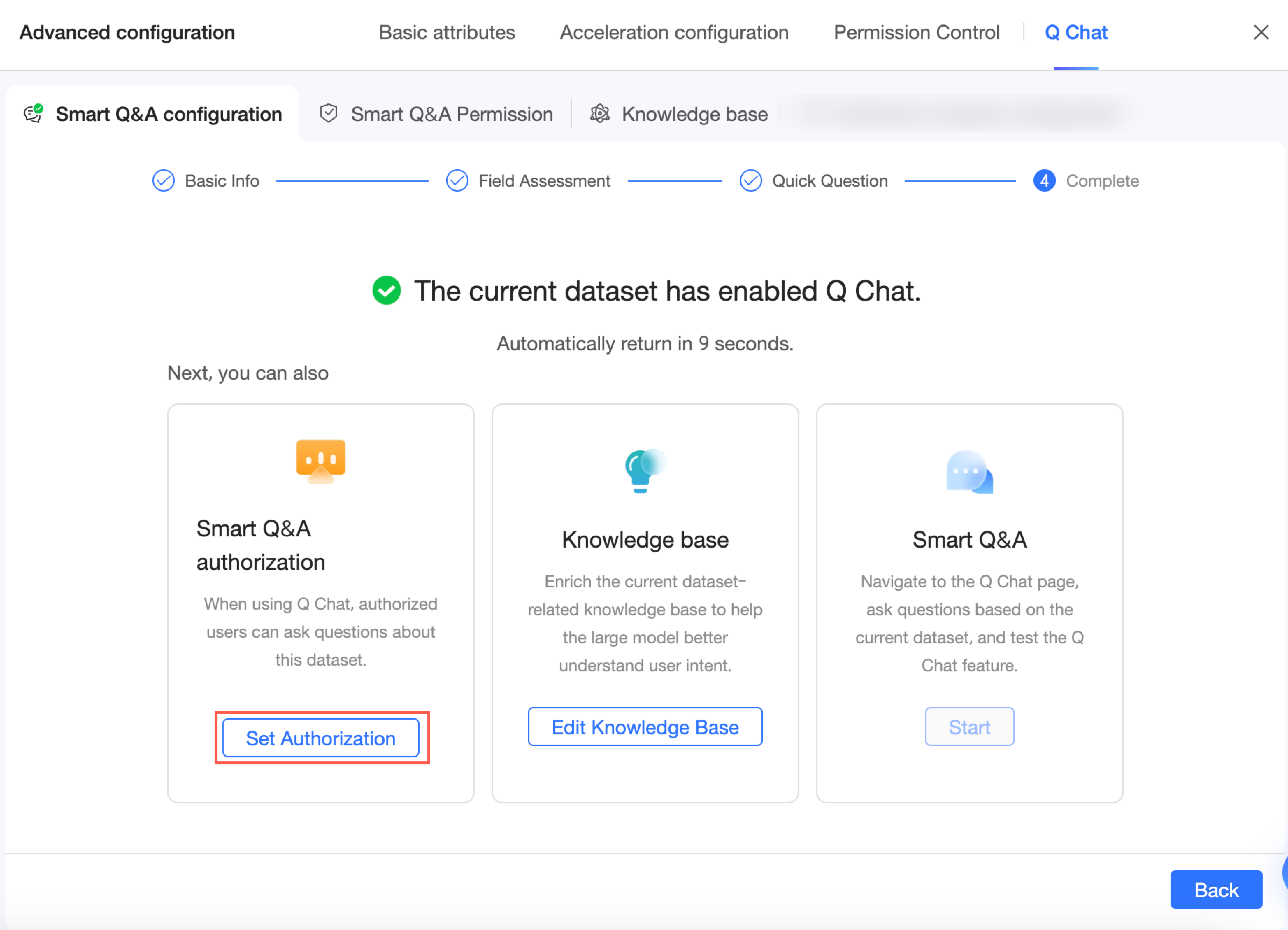
Q Chat 権限
Q Chat 設定を構成した後、アクセス権限を管理できます。
Q Chat 権限 構成ページに移動します。
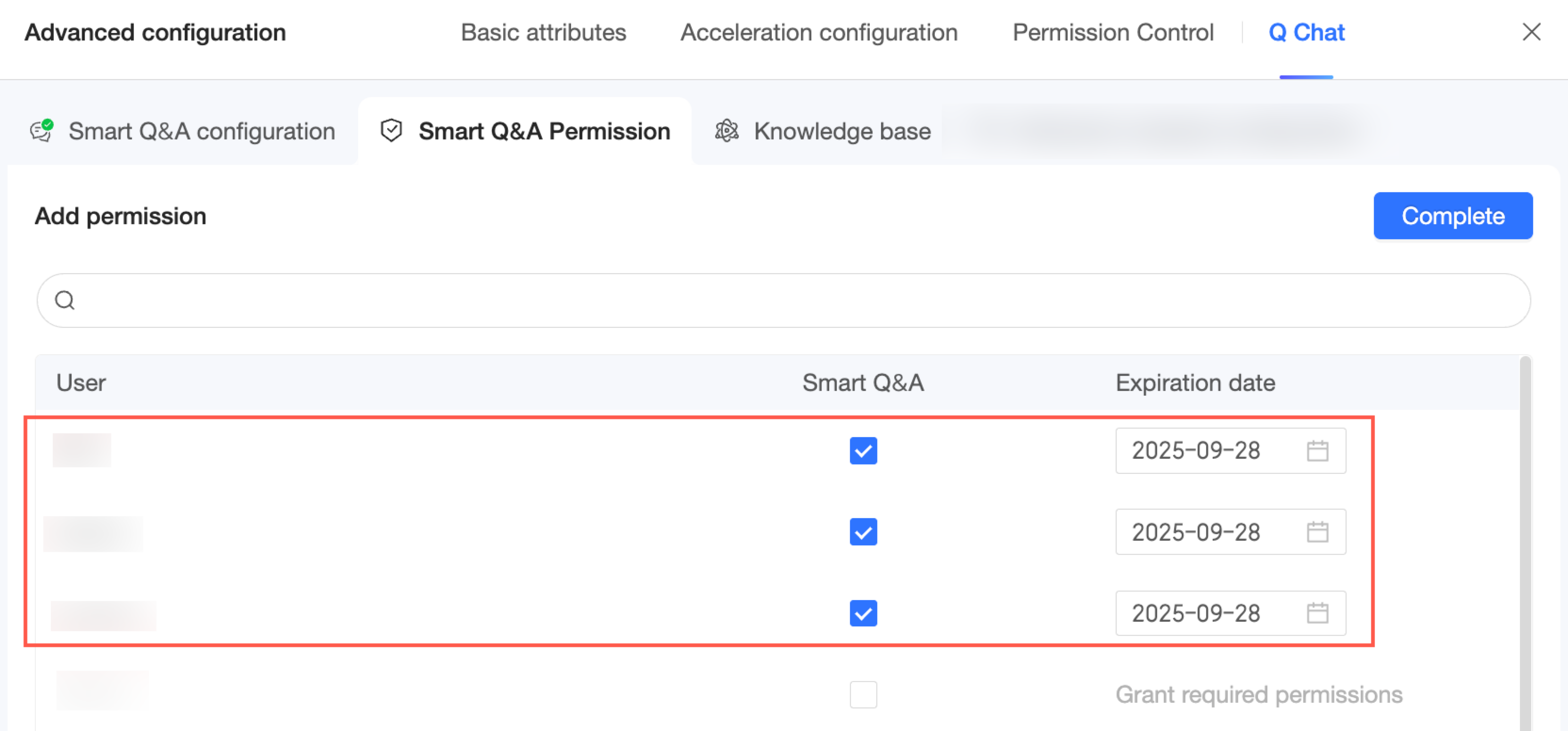
Q Chat 権限 構成ページで、[権限付与を追加] をクリックします。
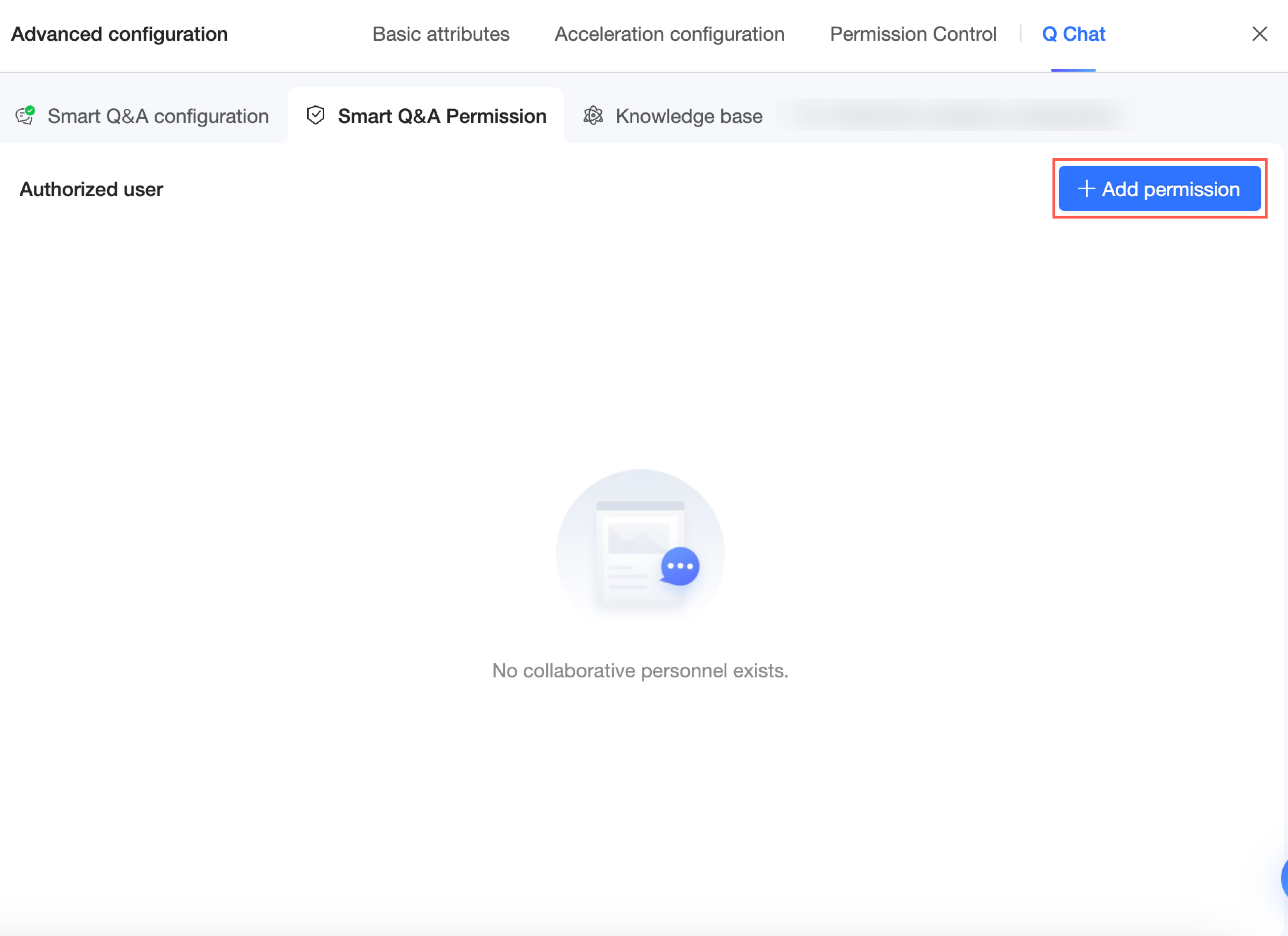
または、前の手順の Q Chat 構成ページで、[承認の追加] をクリックできます。
権限付与するユーザーを選択します。アクセスの有効期限を設定することもできます。
[完了] をクリックします。これで、この Q Chat 対応データセットに対する許可されたユーザーの一覧を表示・管理できます。
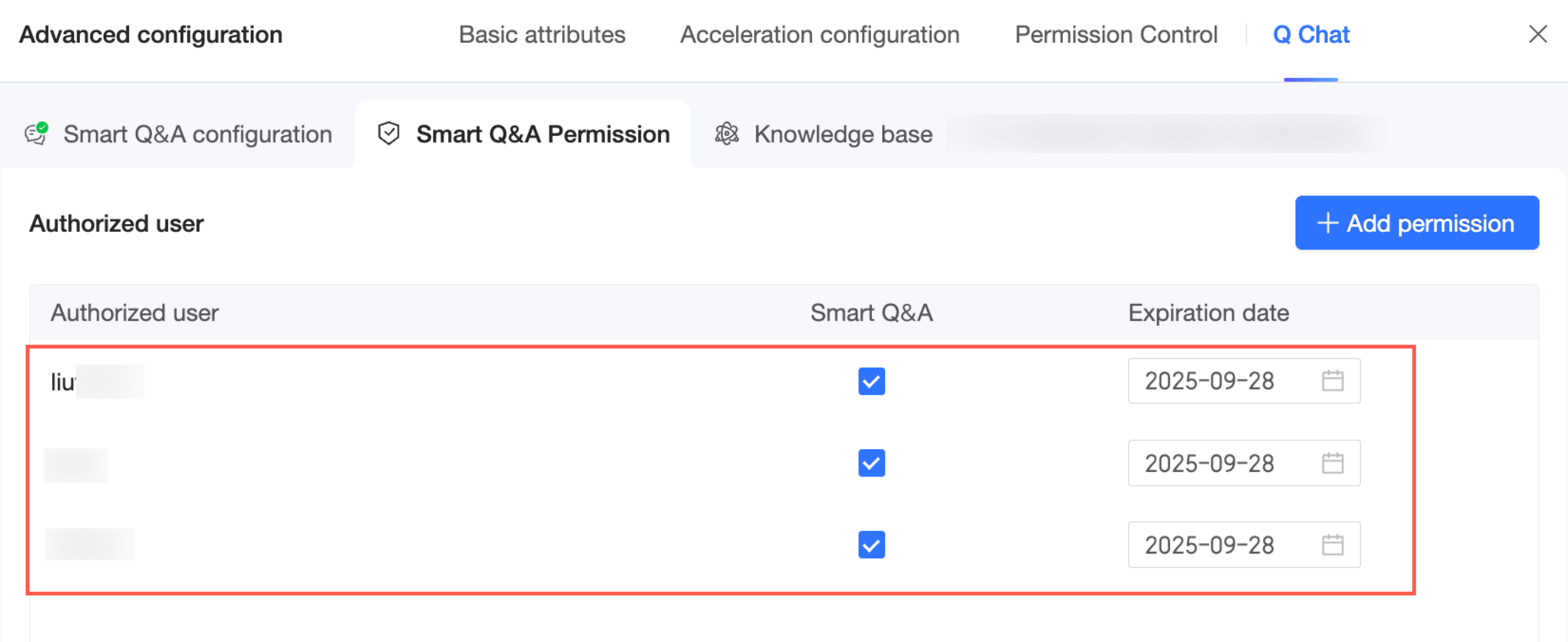
一元管理 権限をお持ちの場合は、Quick BI → 権限管理ページからも権限を管理できます。詳細については、「権限管理」をご参照ください。
ナレッジベース
ナレッジベースには、企業固有の知識や用語の好みが格納されます。構成後、モデルがこの情報を学習し、データ検索および分析に活用します。データセット編集ページからナレッジベースを管理でき、ビジネスロジック および 正規表現マッチング ルールを構成できます。
データセットのナレッジベースは、企業全体のナレッジベースよりも優先度が高くなります。企業全体のナレッジベースの管理方法については、「Q Chat ナレッジ管理」をご参照ください。
アクセス
ナレッジベース管理 ページに移動します。
ビジネスロジック
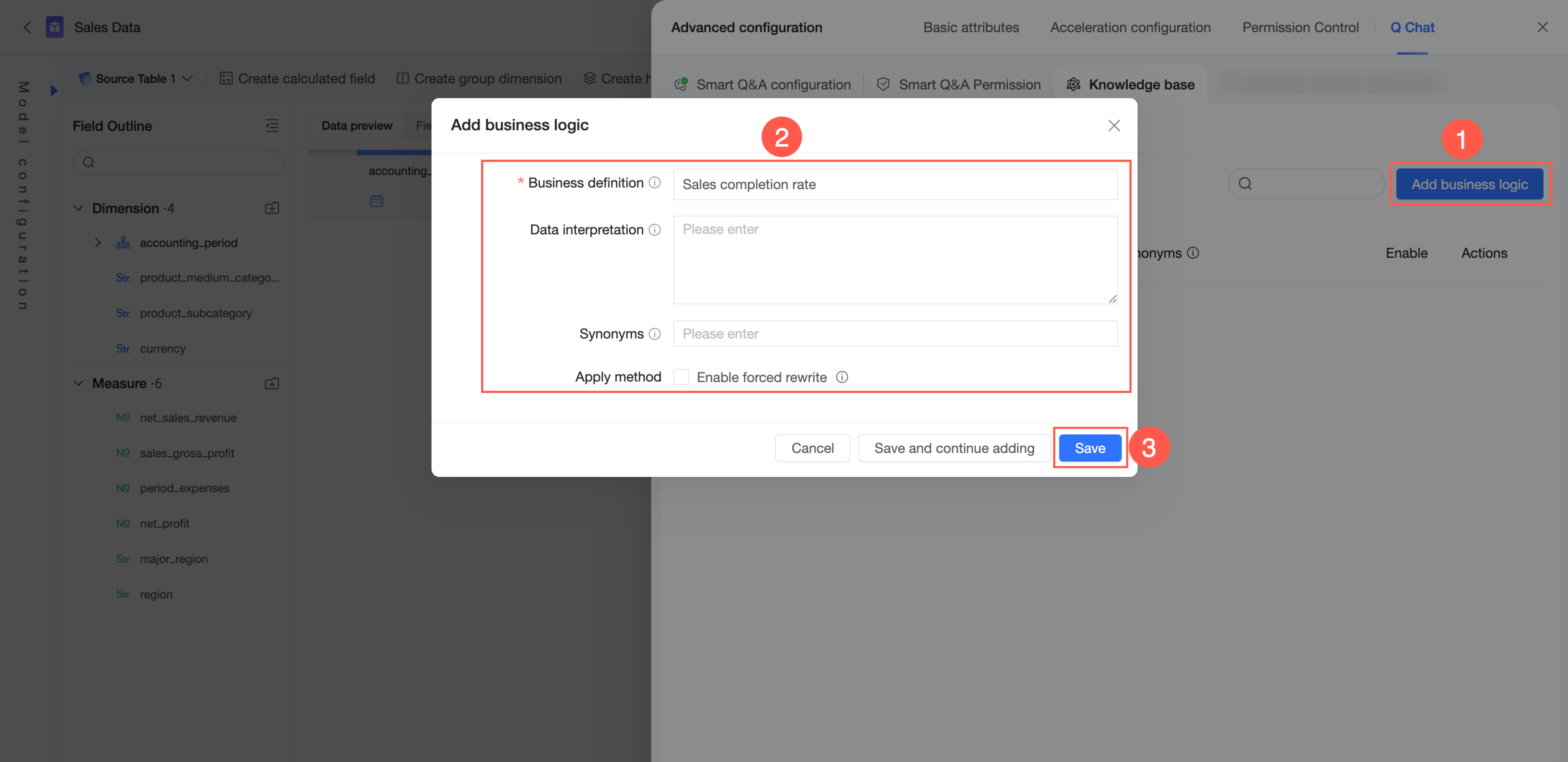
ナレッジベース管理 → 現在のデータセットから → ビジネスロジック タブで、ビジネスロジックを追加 できます。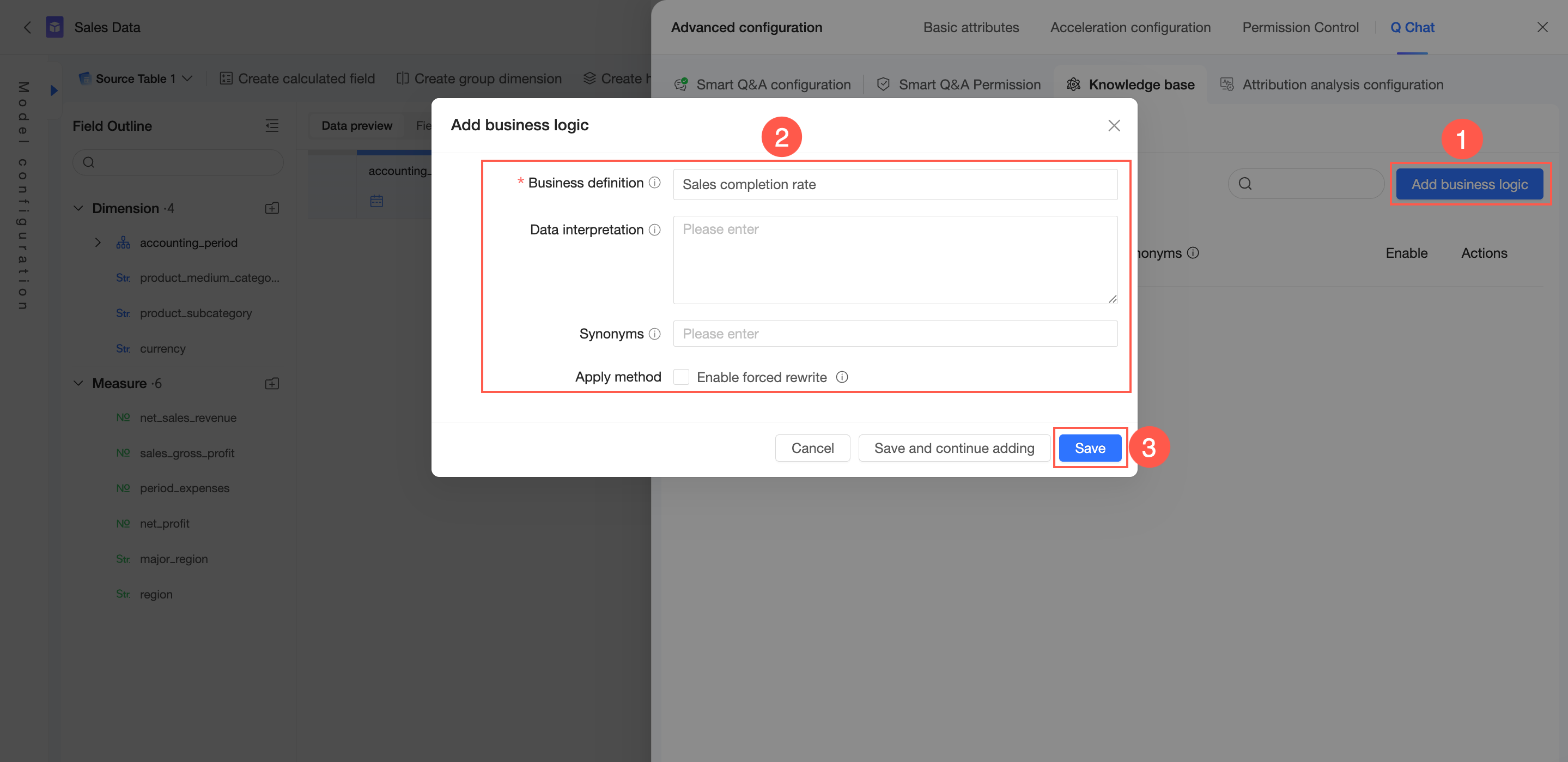
右上隅で、[ビジネスロジックを追加] をクリックします。
ビジネス定義、データ解釈、同義語 を構成します。その他の設定で、強制書き換えを有効化 するかどうかを選択します。
ビジネス定義:組織内で共通のビジネス概念(例:「売上進捗状況」や「会計年度」)を定義します。このフィールドはグローバルに一意である必要があり、最大長は 100 文字です。ここに頻繁に使用されるクエリ用語を入力できます。
データ解釈:ビジネス定義の詳細な説明を提供し、関連するメジャーと関連付けます。これにより、モデルが関連メジャーを特定・理解しやすくなります。最大長は 3,000 文字です。
同義語:企業内で使用されるビジネス用語の代替名を定義します。これにより、モデルが同じ質問の異なる言い回しを認識できるようになります。
強制書き換えを有効化:有効にすると、ビジネス定義 またはその 同義語 に一致するユーザークエリはすべて、データ解釈 フィールドの内容に書き換えられます。このオプションは慎重に使用してください。
[保存] をクリックします。
別のエントリを追加する場合は、[保存して追加を続ける] をクリックします。
正規表現マッチング
ナレッジベース管理 → 現在のデータセットから → 正規表現マッチング タブで、正規表現マッチングルールを追加 できます。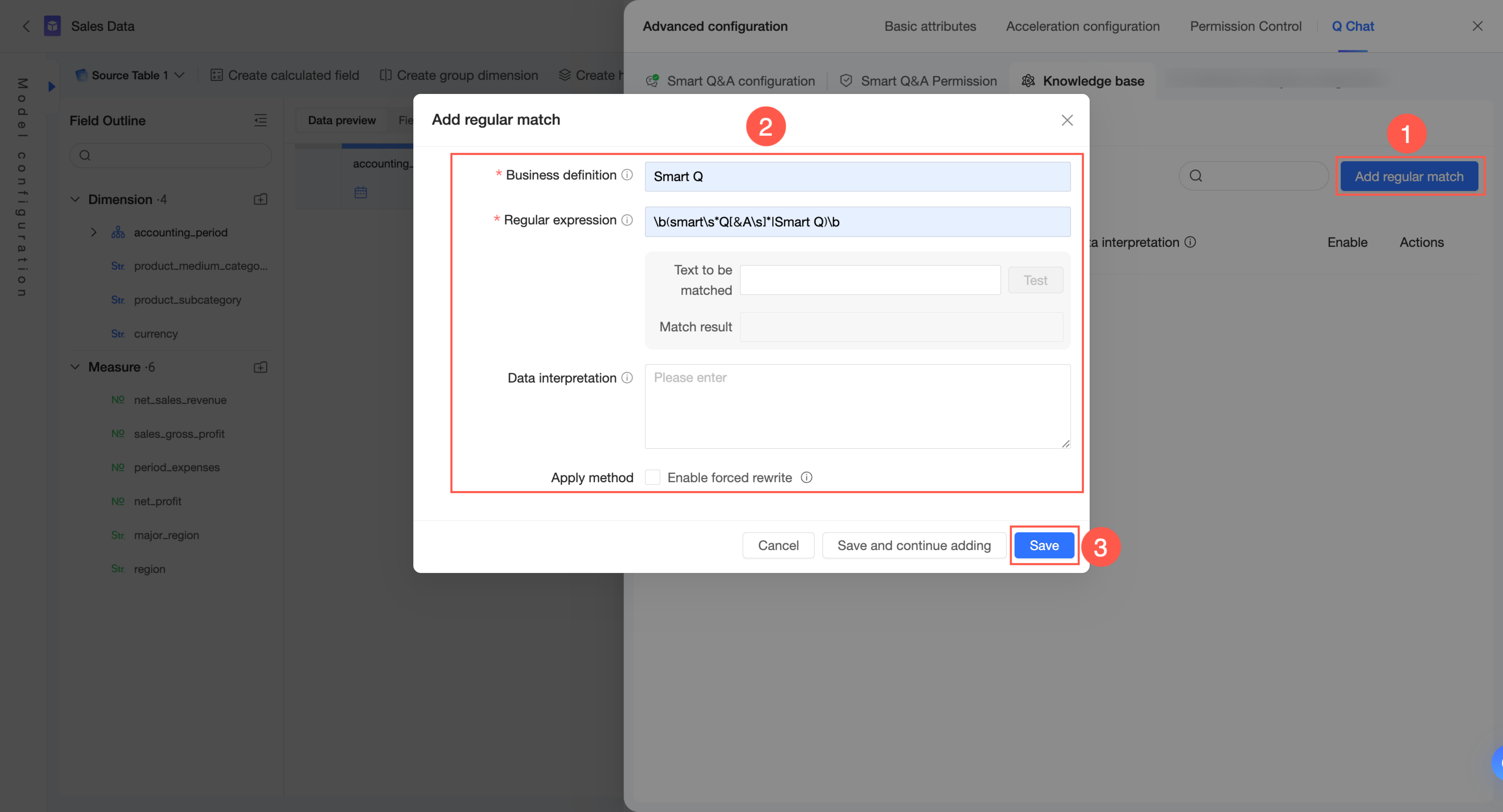
右上隅で、[正規表現マッチングを追加] をクリックします。
ビジネス定義、正規表現、データ解釈 を構成します。適用方法で、強制書き換えを有効化 するかどうかを選択します。
ビジネス定義:正規表現を識別するための名前としてのみ使用され、ユーザー質問とのマッチングには使用されません。データセット内で一意である必要があり、最大長は 100 文字です。
正規表現:ユーザー質問内のパターンを識別し、適用方法に基づいてアクションを実行します。Python スタイルで記述し、最大長は 100 文字です。
マッチさせるテキストを入力 して式をテストし、マッチ結果 を確認できます。
データ解釈:正規表現によってマッチした内容に対する具体的な説明を提供します。適用方法に応じて、マッチした内容の説明または書き換えに使用できます。
強制書き換えを有効化:有効にすると、ユーザークエリのうち 正規表現 に一致する部分はすべて、データ解釈 フィールドの内容に書き換えられます。このオプションは慎重に使用してください。
[保存] をクリックします。
別のルールを追加する場合は、[保存して追加を続ける] をクリックします。
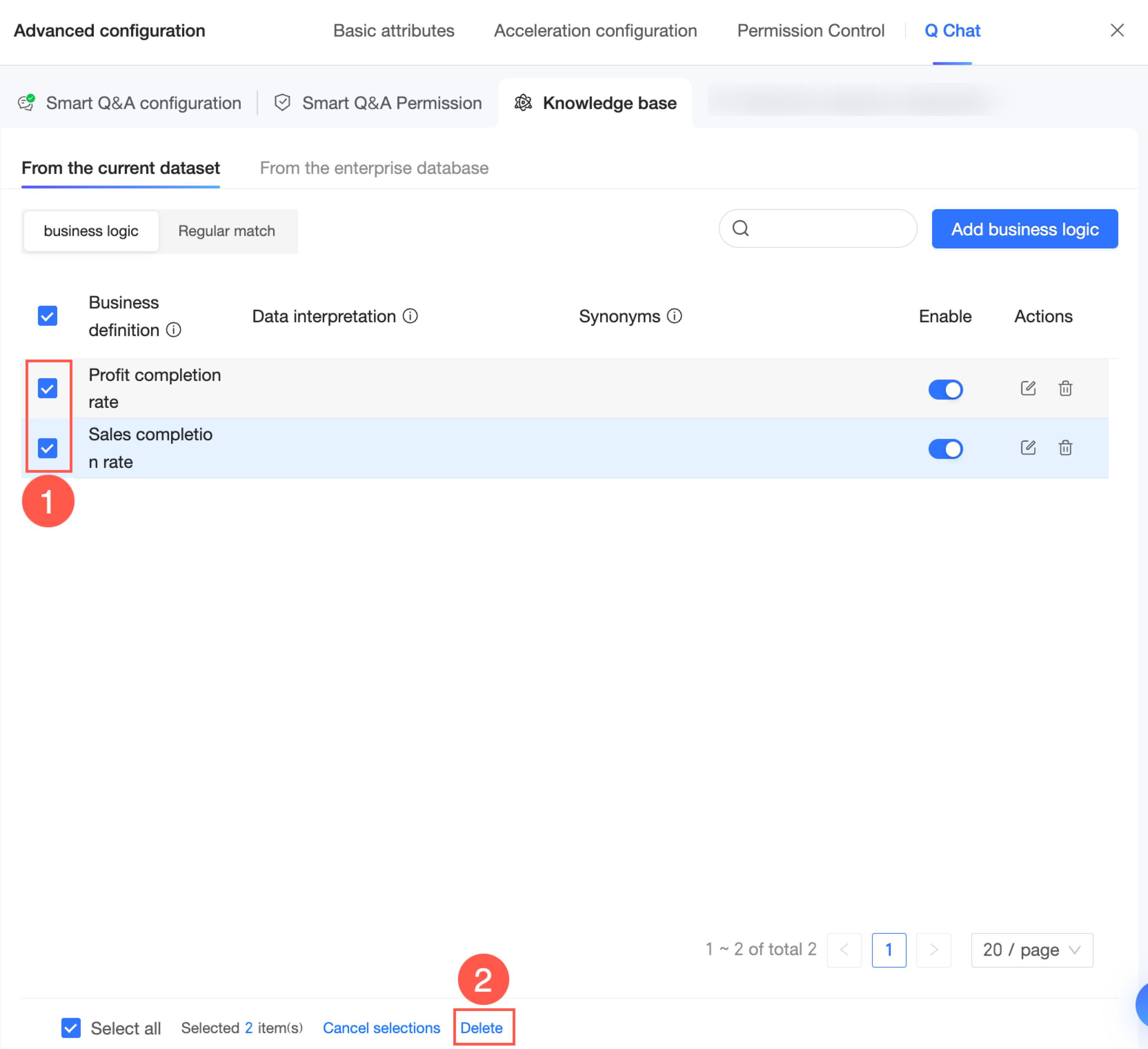
エントリ管理
ナレッジベース管理 → 現在のデータセットから ページで、ナレッジベースを管理 できます。
「有効」列で、各エントリの有効状態を確認できます。
エントリのアイコンが
 の場合、有効です。アイコンをクリックして無効にできます。
の場合、有効です。アイコンをクリックして無効にできます。エントリのアイコンが
 の場合、無効です。アイコンをクリックして有効にできます。
の場合、無効です。アイコンをクリックして有効にできます。
エントリの右側にある
 アイコンをクリックして編集します。
アイコンをクリックして編集します。エントリの右側にある
 アイコンをクリックして削除します。
アイコンをクリックして削除します。複数のエントリを選択して一括削除することもできます。
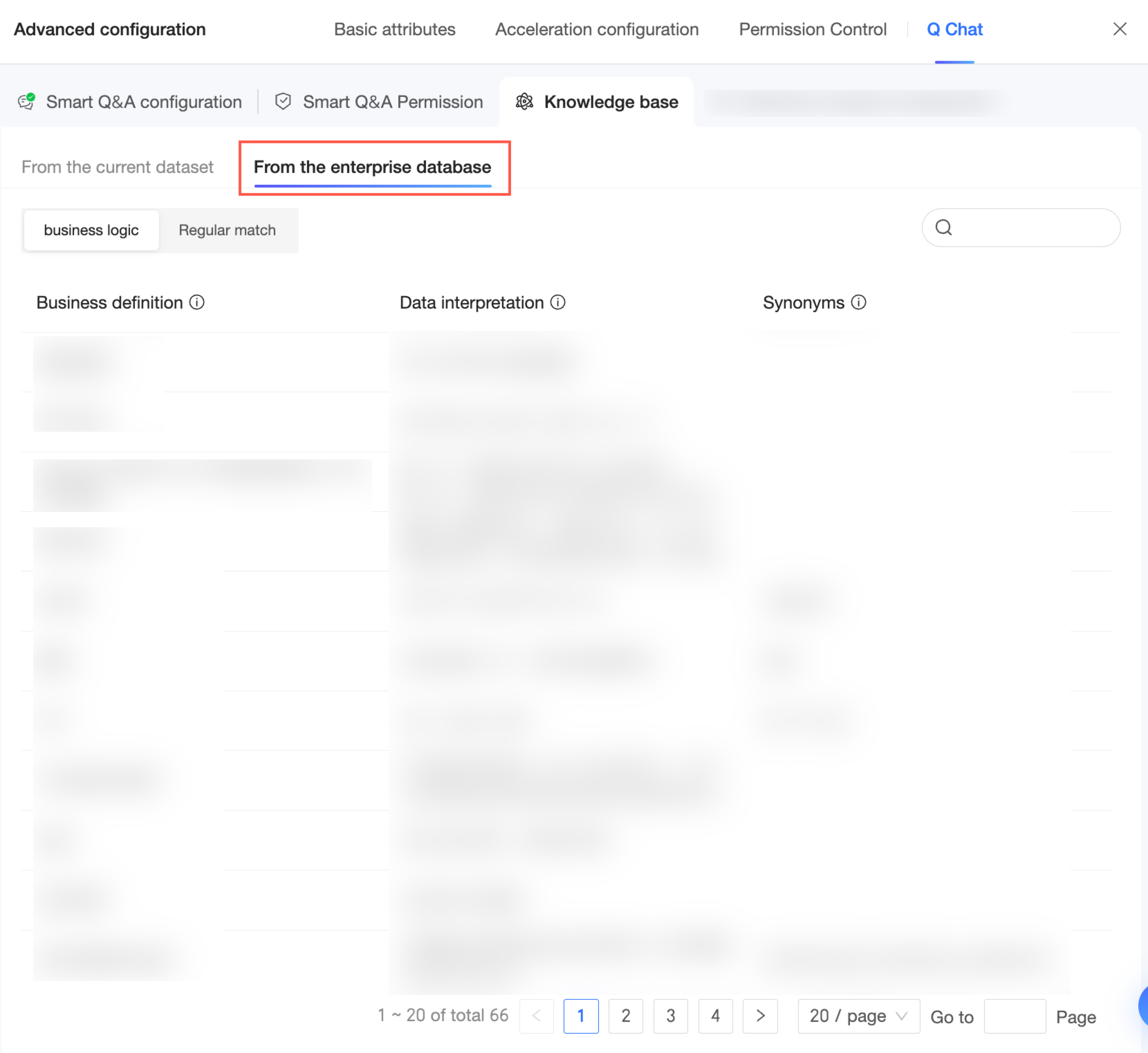
[企業ナレッジベースから] をクリックして、企業ナレッジベースで追加され、このデータセットに適用されているナレッジエントリを表示します。
Quick BI インサイト
データセット編集ページで、詳細設定 をクリックし、Quick BI インサイトを選択して Quick BI インサイト構成ページを開きます。
詳細な手順については、「Quick BI インサイト」をご参照ください。
データセット構成
集計可能なディメンション属性については、デフォルトの集計方法を平均に設定します。 これにより、後続の計算で誤りが発生するのを防げます。
車種の価格、高さ、幅などの属性は、最大値、最小値、平均値などの集計計算が行われる可能性があるため、メジャーとして扱うことを推奨します。クエリで自動的に合計されないようにするため、デフォルトの集計方法を平均に設定するのがより合理的です。例:「各ブランドで、30 万円を超える価格の車種の売上金額はいくらですか?」
正しいフィルタリングを確保するために、データフィールド名または説明に単位を含めます。
「価格が 10 万円を超えるブランドの売上はいくらですか?」 というクエリの場合、価格フィールドの単位が「万円」であれば、バックエンドの計算では >100000 ではなく >10 のフィルタが使用されます。
頻繁にカウントされるディメンションに対しては、計算フィールドを追加します。 現在のバージョンでは、ディメンションフィールドを直接メジャーとしてカウントすることはサポートされていません。
「2020 年に、各都道府県で売上が 1 万円を超えた顧客は何人いますか?」 というクエリの場合、データセット内に計算フィールドを作成することで正しい回答が得られます。システムは計算条件に基づいて自動的に distinct count を実行します。
データセットのフィールド名および説明を構成する際は、以下の基本原則に従います。
フィールド名:
フィールド名は明確かつ標準化されており、ユーザーの質問の仕方を反映している必要があります。重複するフィールド名は避けてください。
基盤データソースの生の英語名を使用せず、不要なコメントを削除してください。
「直近 1 日」などの特定の時間情報を名前に含めないでください。これは曖昧さを引き起こす可能性があります。
フィールドタイプ: 日時データについては、データセット内でフィールドタイプを日付型に変更してください。そうしないと、正しく認識されません。その他のフィールドタイプ(例:地理的ディメンション)も正しく設定する必要があります。
フィールド集計方法: メジャーについては、適切なデフォルト集計方法を選択してください。ユーザーのクエリで集計方法が指定されていない場合、モデルはこの設定を使用します(例:「コンバージョン率」の場合は、ビジネスセマンティクスに基づいてデフォルトを平均に設定できます。「累計 XX」の場合は、合計ではなく平均または最大値に設定してください)。