従来の SQL は、ソーシャルネットワーク、不正検知、知識グラフなど、複雑な関係を持つデータのモデリングやクエリには、手間がかかり非効率です。PolarDB for PostgreSQL は、オープンソースのグラフエンジンである Apache AGE を統合しています。この統合により、同じクラスター内で標準 SQL と業界標準の openCypher グラフクエリ言語の両方を使用して、複雑な関係を含むシナリオのグラフデータを効率的に保存、クエリ、分析できます。
互換性
以下の PolarDB for PostgreSQL バージョンと互換性があります。
-
PostgreSQL 16 (マイナーエンジンバージョン 2.0.16.8.3.0 以降)
-
PostgreSQL 15 (マイナーエンジンバージョン 2.0.15.12.4.0 以降)
-
PostgreSQL 14 (マイナーエンジンバージョン 2.0.14.12.24.0 以降)
コンソールでクラスターのマイナーエンジンバージョンを表示するか、SHOW polardb_version; 文を実行して確認できます。ご利用のクラスターが要件を満たしていない場合は、マイナーエンジンバージョンをアップグレードしてください。
可視化ツール
コンソールで可視化グラフ管理ツール (Apache AGE Viewer ベース) を作成し、Web インターフェイスを通じてグラフデータを操作できます。
ステップ 1:グラフアプリケーションの作成
-
次の 2 つの方法のいずれかでアプリケーションを作成できます。
-
PolarDB コンソールに移動し、左側のナビゲーションウィンドウで PolarDB AI をクリックし、次に AI アプリケーションの作成 をクリックします。
-
PolarDB コンソールに移動します。左側のナビゲーションウィンドウで クラスター をクリックします。要件を満たすターゲットクラスターを見つけ、クラスター詳細ページに移動します。左側のナビゲーションウィンドウで をクリックし、次に AI アプリケーションの作成 をクリックします。
-
-
アプリケーション購入ページで、要件に基づいて適切な構成を選択します。
パラメーター
説明
課金方法
-
サブスクリプション:一定期間のリソース料金を前払いする課金方法です。この方法は、長期的で安定したビジネスシナリオに適しています。サブスクリプション期間が長いほど、割引率が高くなります。
-
従量課金:実際の使用量に基づいて請求される後払いの課金方法です。この方法は、柔軟なリソース要件を持つシナリオに最適です。
エンジン
Apsara PolarDB に固定されています。
リージョン
アプリケーションの地理的な場所を選択します。
説明-
アプリケーションの購入後にリージョンを変更することはできません。
-
アプリケーションは PolarDB for PostgreSQL クラスターと同じリージョンにある必要があります。したがって、ご利用の PolarDB for PostgreSQL クラスターと同じリージョンを選択してください。
-
最適なパフォーマンスを得るには、接続先の ECS インスタンスと同じリージョンにアプリケーションを作成してください。そうしない場合、プライベートネットワークの代わりに低速なパブリックネットワークを介して通信する必要があります。
アーキテクチャ
AI アプリケーション を選択します。
エコシステム
システムは、ソース PolarDB クラスターのデータベースエコシステムをこのフィールドに自動的に入力します。設定する必要はありません。
ソース PolarDB クラスター
アプリケーションを作成する PolarDB クラスターを選択します。
エディション
システムは、ソース PolarDB クラスターのデータベースバージョンをこのフィールドに自動的に入力します。設定する必要はありません。
AI アプリケーション
[グラフ管理] を選択します。
コンポーネントセット
ビジネス要件に基づいて、バックエンドコンポーネントの数と仕様をカスタマイズします。
AI アプリケーション名
アプリケーションのカスタム名を入力します。
説明名前は http:// または https:// で始めることはできず、長さは 2~256 文字である必要があります。
ネットワークタイプ
VPC に固定されています。
VPC
システムは、ソース PolarDB クラスターの VPC をこのフィールドに自動的に入力します。設定する必要はありません。
ゾーンと vSwitch
最適なネットワークパフォーマンスを得るには、PolarDB for PostgreSQL クラスターと同じプライマリゾーンにある vSwitch を選択してください。
既存の vSwitch が要件を満たさない場合は、vSwitch を作成できます。
セキュリティグループ
アプリケーションのセキュリティグループを設定します。
購入数
購入するアプリケーションの数を選択します。
説明-
各 PolarDB for PostgreSQL クラスターに対して、同じタイプの AI アプリケーションを 1 つだけ購入できます。
-
このパラメーターは、課金方法 が サブスクリプションに設定されている場合にのみ使用できます。
購入期間
アプリケーションのサブスクリプション期間を選択します。
説明このパラメーターは、課金方法 が サブスクリプションに設定されている場合にのみ使用できます。
自動更新
自動更新を有効にするかどうかを指定します。支払い遅延によるサービス中断を防ぐため、この機能を有効にすることを推奨します。
説明このパラメーターは、課金方法 が サブスクリプションに設定されている場合にのみ使用できます。
-
-
購入後、クラスターの AI アプリケーションページに戻り、新しいアプリケーションを表示します。
説明アプリケーションの作成には 3~5 分かかります。
ステップ 2:グラフアプリケーションへの接続
-
アプリケーションのホワイトリストの設定:AI アプリケーションのリストページで、アプリケーションの [アプリケーション ID] をクリックしてアプリケーション詳細ページに移動します。ホワイトリスト タブで、IP ホワイトリストの追加、セキュリティグループを選択、または既存のホワイトリストグループを 変更 します。
説明-
アプリケーションのホワイトリストはクラスターのホワイトリストとは独立しており、別途設定する必要があります。
-
ECS インスタンスがアプリケーションにアクセスする必要がある場合は、ECS インスタンスの [インスタンス詳細] ページに移動して IP アドレスを表示し、その IP アドレスを IP ホワイトリストに追加します。
-
ECS インスタンスとアプリケーションが同じ VPC にある場合は、ECS インスタンスのプライベート IP アドレスまたはその VPC の CIDR ブロックを追加できます。
-
ECS インスタンスとアプリケーションが同じ VPC にない場合は、ECS インスタンスのパブリック IP アドレスまたは ECS インスタンスが属するセキュリティグループを追加できます。
-
-
オンプレミスサーバー、コンピューター、または他のクラウドサーバーがアプリケーションにアクセスする必要がある場合は、そのパブリック IP アドレスを IP ホワイトリストに追加します。
-
-
エンドポイントの取得:AI アプリケーションのリストページで、アプリケーションの [アプリケーション ID] をクリックしてアプリケーション詳細ページに移動します。基本情報 タブの トポロジー図 セクションで プライベート IP アドレス を表示します。
説明-
パブリックエンドポイントは別途リクエストする必要があります。申請 ボタンをクリックして申請します。
-
パブリックエンドポイントは IP アドレスとポートのみを提供し、ドメイン名は提供しません。ドメイン名が必要な場合は、ご自身でバインドする必要があります。
-
ステップ 3:拡張機能の作成とデータベースの設定
-
拡張機能の作成:特権アカウントで次の文を実行します。
説明age拡張機能は手動で作成できません。この機能を使用するには、チケットを送信してください。CREATE EXTENSION age; -
データベースの設定:クエリを簡素化するために、接続ごとに
ag_catalogをsearch_pathに追加し、get_cypher_keywords関数を使用して拡張機能をロードする必要があります。説明Data Management Service (DMS) クライアントを使用して
search_pathを設定すると、互換性の問題が発生する場合があります。PolarDB-Tools を使用して文を実行できます。SET search_path = ag_catalog, "$user", public;ワークフローを簡素化するために、特権アカウントとしてデータベースパラメーターを設定して拡張機能を永続的にロードします。これにより、新しい接続ごとに SET コマンドを実行する必要がなくなります。
ALTER DATABASE <dbname> SET search_path = "$user", public, ag_catalog; ALTER DATABASE <dbname> SET session_preload_libraries TO 'age'; -
(オプション) 一般ユーザーに AGE の使用を許可する:
ag_catalogスキーマのUSAGE権限を一般ユーザーに付与します。GRANT USAGE ON SCHEMA ag_catalog TO <username>;一般ユーザーが読み取りおよび書き込み権限しか持たない場合は、テーブルを作成するための
CREATE権限も付与する必要があります。GRANT CREATE ON DATABASE <dbname> TO <username>;
ステップ 4:グラフの作成とデータの挿入
-
グラフを使用する前に、グラフを作成する必要があります。これを行うには、
ag_catalog名前空間のcreate_graph関数を使用します。構文:
SELECT create_graph('<graph_name>');例:
SELECT ag_catalog.create_graph('moviedb'); -
データの挿入:次の SQL ステートメントを使用して、サンプルデータを
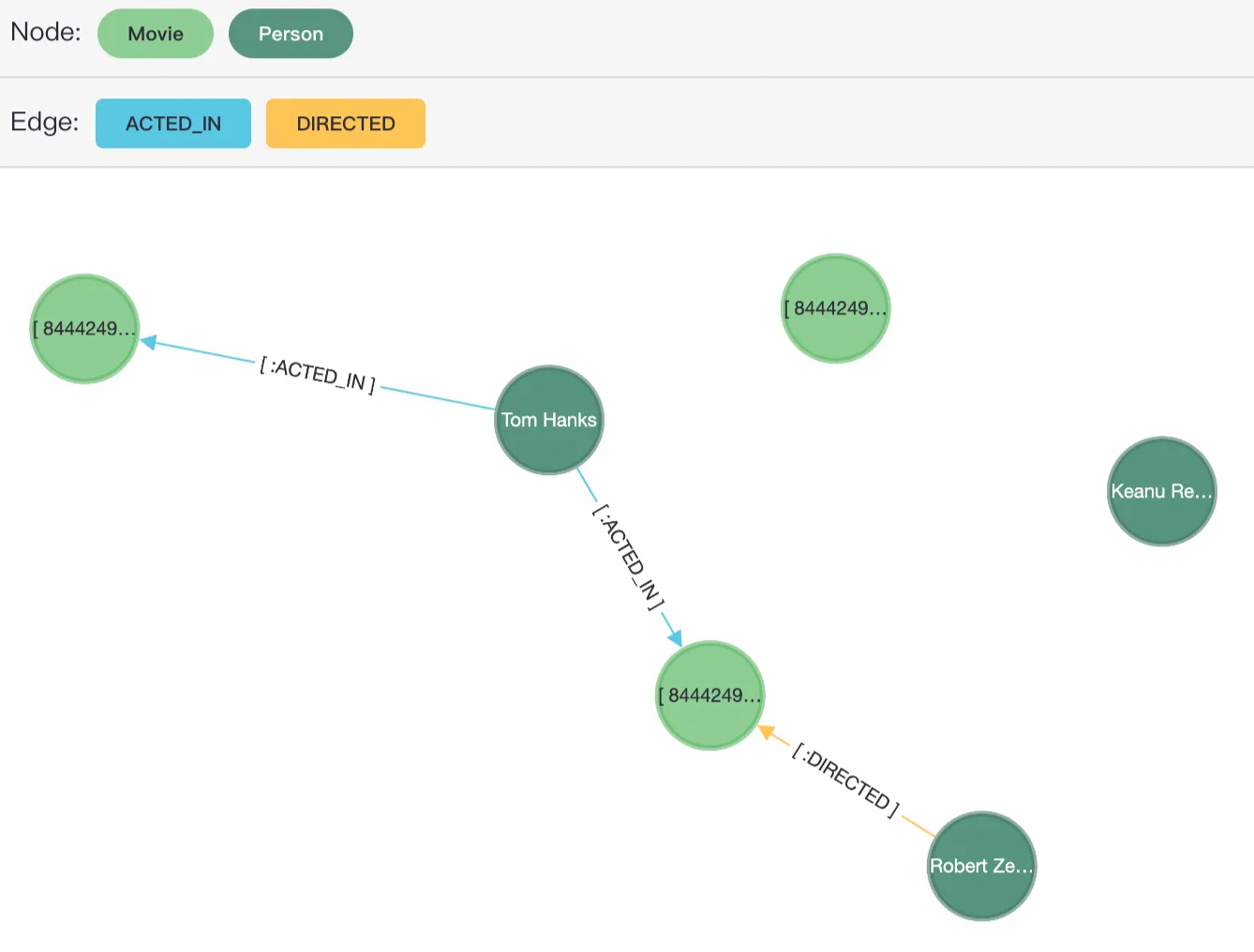
moviedbグラフに挿入します。SELECT * FROM cypher('moviedb', $$ CREATE (matrix:Movie {title: 'The Matrix', released: 1997}) CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012}) CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994}) CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964}) CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951}) CREATE (tom:Person {name: 'Tom Hanks', born: 1956}) CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump) CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas) CREATE (robert)-[:DIRECTED]->(forrestGump) $$) AS (result1 agtype);このデータセットには 6 つのノード (3 つは `Movie` ラベル、3 つは `Person` ラベル) と 3 つのエッジ (2 つは `ACTED_IN` ラベル、1 つは `DIRECTED` ラベル) が含まれています。関係グラフを次の図に示します。
ステップ 5:アプリケーションの開発
-
アプリケーションの開発:パブリックネットワーク経由でアプリケーションに直接アクセスできます。AI アプリケーションのリストページで アプリケーションを開発 をクリックして、可視化ツールのパブリック URL に移動します。または、ブラウザにアプリケーションのパブリック IP アドレスとポートを入力します。
説明続行する前に、パブリック IP アドレスをアプリケーションのホワイトリストに追加していることを確認してください。
-
可視化ツールのログインページで、次の情報を入力します。
-
ホスト:ご利用の PolarDB クラスターのエンドポイントを選択します。
-
データベース名:クラスター内のデータベースの名前を入力します。適切なデータベースがない場合は、クラスター詳細ページに戻り、データベースを作成します。
-
ユーザー名:クラスター内のデータベースアカウントを入力します。アカウントがデータベースに対する必要なアクセス権限を持っていることを確認してください。
-
パスワード:データベースアカウントのパスワードを入力します。
-
-
データのクエリ:Cypher では、
MATCHとRETURNキーワードを使用してデータをクエリします。-
MATCHはパターンマッチングに使用され、指定されたパターンに一致するコンテンツを検索します。 -
RETURNキーワードは、Cypher クエリから返す値または結果を指定します。
構文:
SELECT * FROM cypher('graph_name', $$ MATCH <patterns>RETURN <variables> $$) AS (result1 agtype);例:可視化ツールの最上部に次の Cypher クエリ文を入力します。
SELECT * FROM cypher('moviedb', $$ MATCH (m:Person) RETURN m $$) AS (result1 agtype);クエリを入力した後、エディターの右上隅にある [実行] ボタンをクリックします。クエリが成功すると、下の結果エリアに次のように表示されます。[ノードラベル] には *(6)、Movie(3)、Person(3) が表示され、[エッジラベル] には *(3)、ACTED_IN(2)、DIRECTED(1) が表示され、[プロパティ] は空です。右側のパネルで、[現在のグラフ] ドロップダウンリストが
moviedbに設定されます。 -
-
検証:操作が成功すると、下の可視化エリアに
moviedbからの 3 つの Person ノードが表示されます。クエリを実行すると、結果は [グラフ] ビューにグラフィカルに表示されます。返された Tom Hanks や Keanu Reeves などの Person ノードは、円形のノードとして表示されます。
ステップ 6:(オプション) グラフアプリケーションのリリース
コストを節約するために、不要になった可視化ツールはリリースしてください。AI アプリケーションのリストで、ターゲットのグラフアプリケーションを見つけ、操作 列で アプリケーションをリリース をクリックします。
グラフアプリケーションをリリースすると、Web インターフェイス用の可視化ツールのみが削除され、PolarDB クラスターに保存されているグラフデータは削除されません。アプリケーションがリリースされると、パブリックネットワークアドレスなどの構成は失われ、回復できません。
仕組み
-
コアエンジン:PolarDB のグラフデータベース機能は、PostgreSQL の
age拡張機能に基づいて構築されています。これは Apache AGE プロジェクトによって提供され、OpenCypher クエリ構文と互換性があります。 -
ハイブリッドクエリ:
age拡張機能を使用すると、同じデータベース内でリレーショナルデータ (標準テーブル) とグラフデータの両方を管理できます。これらのデータ型は個別にクエリできます。 -
クエリ実行:Cypher クエリを直接実行するのではなく、
cypher()という名前の PostgreSQL 関数に文字列パラメーターとして渡します。PolarDB はこの文字列を解析し、指定されたグラフで Cypher コマンドを実行し、結果を標準の SQL 行セットとして返します。 -
データ型:クエリは通常、
agtype型の結果列を返します。これは、ノード、エッジ、パスなどのグラフ要素に関する構造化情報をカプセル化する JSONB に似たカスタムデータ型です。アプリケーションでは、通常、JSON 文字列として処理できます。
課金
-
コンポーネント料金:グラフアプリケーションの バックエンドコンポーネントは、選択したコンポーネント仕様 (CPU とメモリ) とサブスクリプション期間に基づいて課金されます。
-
ストレージ料金:グラフアプリケーションによって生成されたデータとファイルは、ご利用の PolarDB for PostgreSQL クラスターに保存されます。
-
トラフィックと帯域幅:無料。
関連ドキュメント
-
Graph Database のクイックスタート:psql などの SQL クライアントで Cypher 文を実行して、グラフデータベースを操作します。この方法は、バックエンド開発や自動化スクリプトのシナリオに最適です。
-
SQL リファレンス:SQL 構文は Apache AGE に基づいており、Alibaba Cloud の Graph Database 用に変更が加えられています。