このガイドでは、パブリックな金融取引データセットを使用して、PolarDB でグラフ分析を実行する方法を説明します。不正検知のためのグラフクエリの実行、不正行為間の関係性の発見、および不正防止に役立つトランザクション間のジャカード類似度の計算方法を学びます。
グラフエンジンについて
PolarDB for PostgreSQL は、Apache AGE 拡張機能を通じてグラフデータのストレージとクエリをサポートします。これにより、同じデータベースクラスターに対して ANSI SQL と openCypher グラフクエリ言語の両方を実行できます。
Apache AGE は、拡張機能として PolarDB for PostgreSQL に直接統合されるため、別途グラフデータベースを用意する必要はありません。

主な機能:
-
ネイティブな PostgreSQL 互換性:AGE は既存の PolarDB データベースと連携して動作します。再構築は不要です。トランザクションサポート、同時実行制御、インデックス作成など、すべての PolarDB の機能を継承します。
-
グラフクエリとリレーショナルクエリの統合:単一のクエリで SQL と Cypher を実行できます。これにより、リレーショナル構造とグラフ構造にまたがる複雑なデータモデルの取り扱いが簡素化されます。
-
Cypher クエリ言語:AGE は、グラフデータのクエリと操作に直感的な構文を提供する Cypher クエリ言語をサポートしています。
-
高性能:AGE は、PolarDB のクエリ最適化とグラフ固有のインデックスを組み合わせることで、大規模なグラフデータと複雑なトラバーサルを効率的に処理します。
ユースケース
背景情報
現代の詐欺や金融犯罪では、詐欺師は身元を変えるなどの手口でリスク管理ルールを回避することがよくあります。グラフデータベースを構築してユーザー行動のグラフ構造を追跡することで、個別の不正データをリアルタイムで分析し、詐欺グループを特定できます。これにより、不正行為を迅速かつ効果的に防止し、解決することができます。
データとモデル
このガイドでは、金融取引ドメインのパブリックデータセットを使用します。データは、e コマースプラットフォーム Vesta のトランザクションレコードで構成されており、トランザクションに関与したデバイス、住所、メールアカウントに関する情報が含まれています。このデータセットを使用して、不正なトランザクションを特定し、リスクを予測できます。
生データは CSV 形式で、トランザクション情報 (トランザクション ID、住所、メールなど) と ID 情報 (デバイス情報、デバイスタイプなど) が含まれています。このガイドでは、広範なデータセットを次の図に示すデータモデルに抽象化します。このモデルは、特定のビジネス要件に基づいて調整できます。
-
頂点
-
transaction:トランザクション。 -
product:トランザクションに関与するプロダクト。 -
addr1:トランザクションの主要な請求先住所。 -
addr2:トランザクションの副次的な請求先住所。 -
emaildomain:トランザクションに使用されるメールドメイン。 -
deviceinfo:トランザクションのデバイス情報。 -
devicetype:トランザクションに使用されるデバイスのタイプ。
-
-
エッジ
-
transaction_product:トランザクションとプロダクトの関係。 -
transaction_addr1:トランザクションと主要な住所の関係。 -
transaction_addr2:トランザクションと副次的な住所の関係。 -
transaction_emaildomain:トランザクションとメールドメインの関係。 -
transaction_deviceinfo:トランザクションとデバイス情報の関係。 -
transaction_devicetype:トランザクションとデバイスタイプの関係。
-
このモデルはトランザクションを中心に構成されており、トランザクションはトランザクション ID (transactionid) によってリンクされています。
ベストプラクティス
このソリューションでは、AGE プロジェクトのグラフデータ可視化ツールを使用して、クエリ結果をグラフィカルに表示します。
構成
最適なエクスペリエンスを得るために、ご利用の PolarDB クラスターには次の構成を推奨します。
-
プロダクト:Standard Edition
-
データベースエンジン:PostgreSQL 14
-
リビジョンバージョン:>=14.12.23.1
-
CPU:>= 4 コア
-
メモリ:>= 16 GB
-
ディスク:>= 100 GB
データベースの準備
-
特権アカウントを使用して AGE 拡張機能をインストールします。
CREATE EXTENSION age; -
必要なユーザーまたはデータベースの検索パスとプリロードライブラリに拡張機能を追加します。
-
現在のセッションに拡張機能をロードします。
説明Data Management (DMS) を使用して
search_pathを構成すると、互換性の問題が発生する場合があります。そのような場合は、PolarDB-Tools を使用して関連するステートメントを実行できます。SET search_path = ag_catalog, "$user", public; SELECT * FROM get_cypher_keywords() limit 0; -
拡張機能を永続的にロードします。
ALTER DATABASE <dbname> SET search_path = ag_catalog, "$user", public; ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';
-
データのロード
-
グラフを作成します。
ag_catalogスキーマのcreate_graph関数を使用してグラフを作成します。この例では、グラフ名はfraud_graphです。SELECT create_graph('fraud_graph'); -
頂点とエッジを挿入します。ダウンロードした CSV データは、グラフとして直接ロードすることはできません。まず、頂点とエッジの構造に変換する必要があります。データを PolarDB の頂点とエッジに変換するための Python スクリプトを入手するには、お問い合わせください。次のコードは、変換されたデータのサンプルを示しています。
-
頂点データのサンプル
SELECT * FROM cypher('fraud_graph', $$ MERGE (v:transaction {transactionid : 2990783, isfraud : 0 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:product {productid : 158945 } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr1 {addr1 : '299.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:addr2 {addr2 : '87.0' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:emaildomain {emaildomain : 'gmail.com' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:deviceinfo {deviceinfo : 'SM-G920V Build/NRD90M' } ) RETURN v $$ ) as (n agtype); SELECT * FROM cypher('fraud_graph', $$ MERGE (v:devicetype {devicetype : 'mobile' } ) RETURN v $$ ) as (n agtype); ... -
エッジデータのサンプル
SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:product) WHERE a.transactionid = 2990783 AND b.productid = 158945 MERGE (a)-[e:transaction_product]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr1) WHERE a.transactionid = 2990783 AND b.addr1 = '299.0' MERGE (a)-[e:transaction_addr1]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:addr2) WHERE a.transactionid = 2990783 AND b.addr2 = '87.0' MERGE (a)-[e:transaction_addr2]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:emaildomain) WHERE a.transactionid = 2990783 AND b.emaildomain = 'gmail.com' MERGE (a)-[e:transaction_emaildomain_p]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:deviceinfo) WHERE a.transactionid = 2999403 AND b.deviceinfo = 'SM-G920V Build/NRD90M' MERGE (a)-[e:transaction_deviceinfo]->(b) RETURN e$$) as (e agtype); SELECT * FROM cypher('fraud_graph', $$ MATCH (a:transaction), (b:devicetype) WHERE a.transactionid = 2999404 AND b.devicetype = 'mobile' MERGE (a)-[e:transaction_devicetype]->(b) RETURN e$$) as (e agtype); ...
変換結果を SQL ファイルとして保存します。その後、psql などのクライアントツールを使用してデータをインポートできます。
-
例
単純なクエリ
統計
-
ノードの総数をカウントします。
SELECT * FROM cypher('fraud_graph', $$ MATCH (n) RETURN count(*) $$) as (number_of_vertex agtype);コマンドは次の結果を返します。
number_of_vertex ---- 1076004 -
transactionノードの数をカウントします。SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) RETURN count(*) $$) as (number_of_transaction agtype);コマンドは次の結果を返します。
number_of_transaction ---- 545591 -
不正と特定されたトランザクションの数をカウントします。
SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction) WHERE n.isfraud = 1 RETURN count(*) $$) as (number_of_fraud_transaction agtype);コマンドは次の結果を返します。
number_of_fraud_transaction ---- 18919 -
エッジの総数をカウントします。
SELECT * FROM cypher('fraud_graph', $$ MATCH ()-[r]->() RETURN count(*) $$) as (number_of_edge agtype);コマンドは次の結果を返します。
number ------ 2131254
フィルターおよびソートクエリ
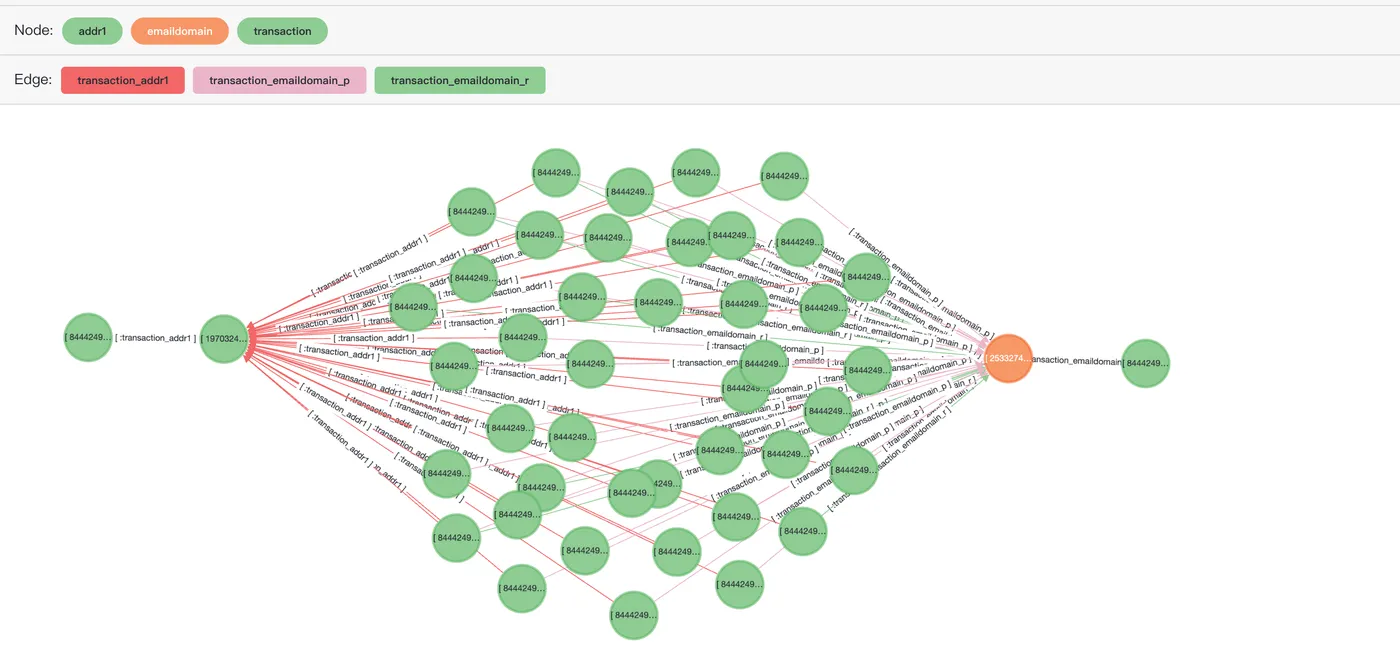
ID が 2988706 のトランザクションと、それに関連するすべての情報をクエリします。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)
WHERE n.transactionid = 2988706
RETURN v
$$) as (e agtype);コマンドは次の結果を返します。
e
---------
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 2533274790395906, "label": "emaildomain", "properties": {"emaildomain": "gmail.com"}}::vertex
{"id": 1970324836974595, "label": "addr1", "properties": {"addr1": "325.0"}}::vertex
{"id": 1125899906844295, "label": "product", "properties": {"productid": 137934}}::vertex以下は、age-viewer 可視化ツールでの SQL クエリ結果のプレビューです。
中央の transaction ノードは、[:transaction_addr1]、[:transaction_addr2]、[:transaction_emaildomain_p]、[:transaction_emaildomain_r]、[:transaction_product] の 5 つのエッジを介して、addr1、addr2、emaildomain、product の 4 つの関連ノードに接続します。
一般的なユースケース
k 近傍法 (KNN)
k 近傍法 (KNN) は、データノード間の類似性を評価することで、潜在的な不正を特定します。特定のデータノードと最も特徴が類似している K 個の隣接ノードを見つけることで、そのノードが正常かどうかを判断できます。たとえば、あるトランザクションが、金額、場所、時間などの特徴において、隣接するほとんどのトランザクションノードと著しく異なる場合、そのトランザクションは疑わしいとマークされる可能性があります。
トランザクション 2988706 と同じ住所を共有する他のトランザクション (2 ホップ隣接ノード) をクエリして、元のトランザクションが疑わしいかどうかを判断します。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN t
$$) as (e agtype);コマンドは次の結果を返します。
e
-----
{"id": 844424930131972, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987001}}::vertex
{"id": 844424930131978, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987007}}::vertex
{"id": 844424930132041, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987070}}::vertex
{"id": 844424930132053, "label": "transaction", "properties": {"isfraud": 0, "transactionid": 2987082}}::vertex
....age-viewer 可視化ツールで結果をプレビューするには、次の SQL クエリを実行します。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r:transaction_addr1]->(a:addr1)<-[r2:transaction_addr1]-(t:transaction)
WHERE n.transactionid = 2988706
RETURN [n,r,a,r2,t]::path
LIMIT 50
$$) as (e agtype);50 件のレコードのみが返されます。データ量が多すぎると、フロントエンドシステムがクラッシュする可能性があります。
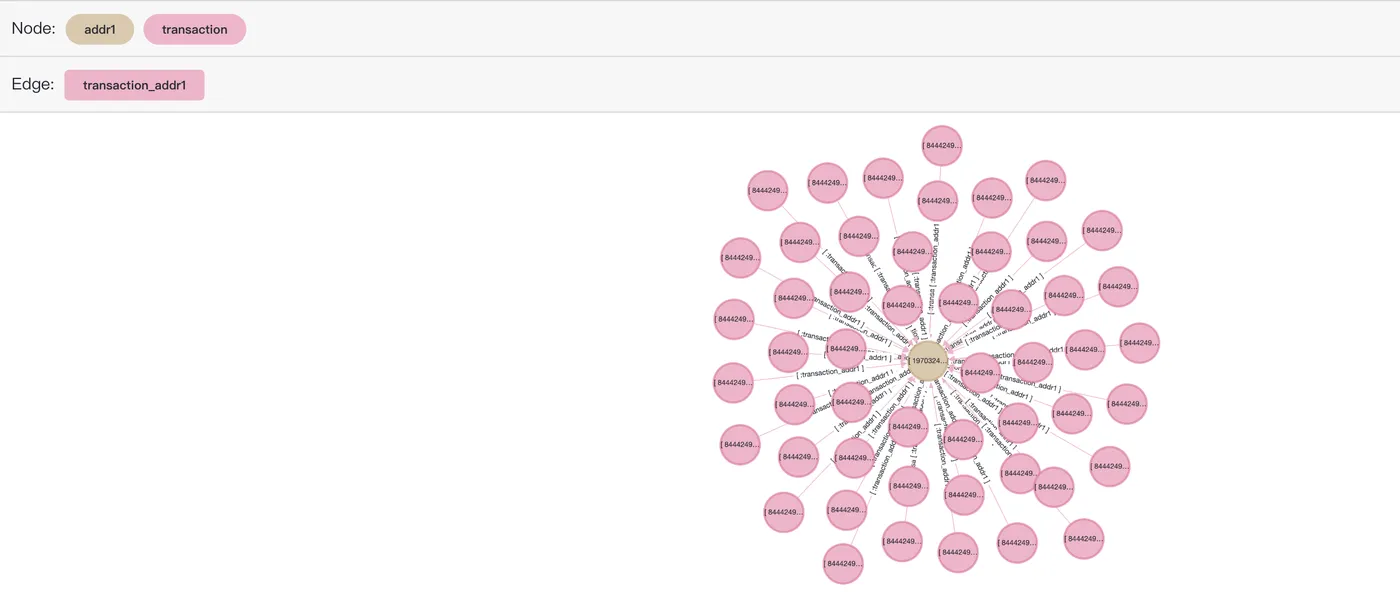
パス検索
不正検知におけるパス検索では、グラフ理論とネットワーク分析を使用して、潜在的な不正行為を特定します。金融ネットワークでは、トランザクションは、ノードがアカウントや顧客を表し、エッジがトランザクション活動を表すグラフと見なすことができます。このグラフの構造を分析することで、異常なパターンや不正な行動を発見できます。トランザクション間のパスを計算することで、疑わしいアカウントから他のアカウントへのトランザクションチェーンを迅速に特定し、一見無関係に見えるアカウント間の隠れたつながりを明らかにすることができます。
トランザクション 2987000 とトランザクション 2987172 の間のパスを不正なトランザクションを通じてクエリし、それらを結ぶすべての不正チェーンを見つけます。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN t
$$) as (e agtype);コマンドは次の結果を返します。
e
----
{"id": 844424930618281, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3473312}}::vertex
{"id": 844424930626886, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3481917}}::vertex
{"id": 844424930649640, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3504671}}::vertex
{"id": 844424930631805, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3486836}}::vertex
{"id": 844424930641980, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3497011}}::vertex
{"id": 844424930644942, "label": "transaction", "properties": {"isfraud": 1, "transactionid": 3499973}}::vertexage-viewer 可視化ツールで結果をプレビューするには、次の SQL クエリを実行します。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[r]->(v)<-[r1]-(t:transaction)-[r2]->(v2)<-[r3]-(k:transaction)
WHERE n.transactionid = 2987000
and k.transactionid=2987172
and t.isfraud = 1
RETURN [n,r,v,r1,t,r2,v2,r3,k]::path
LIMIT 50
$$) as (e agtype);50 件のレコードのみが返されます。データ量が多すぎると、フロントエンドシステムがクラッシュする可能性があります。
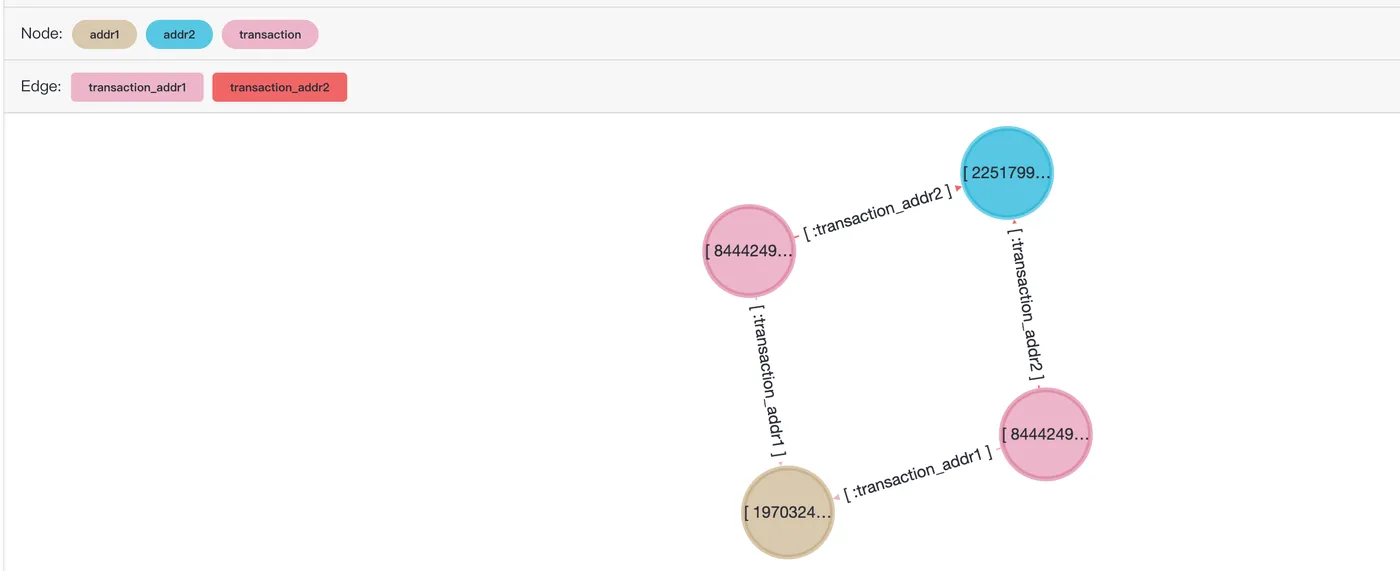
共通隣接ノード
不正検知において、共通隣接分析は、ソーシャルネットワークまたはトランザクションネットワークを分析することで、考えられる不正行為を特定するグラフベースの手法です。このメソッドは主にグラフ理論に依存して、トランザクション参加者間の関係ネットワークを分析し、疑わしいトランザクションパターンを見つけます。2 つのトランザクションが、異常な行動 (高頻度取引や異常な金額など) を示す複数の共通隣接ノードを共有している場合、これら 2 つの取引者間のトランザクションは、より高い不正リスクを伴う可能性があります。
トランザクションレコード 2987000 と 2987172 の共通隣接ノードをクエリして、住所やデバイスなど、同じ属性を持つトランザクションを見つけます。
SELECT *
FROM cypher('fraud_graph', $$
MATCH (n:transaction)-[]->(v)<-[]-(t:transaction)
WHERE n.transactionid = 2987000 and t.transactionid=2987172
RETURN v
$$) as (e agtype);コマンドは次の結果を返します。
e
-----
{"id": 2251799813685249, "label": "addr2", "properties": {"addr2": "87.0"}}::vertex
{"id": 1970324836974594, "label": "addr1", "properties": {"addr1": "315.0"}}::vertex以下は、age-viewer 可視化ツールでの SQL クエリ結果のプレビューです。
ジャカード類似度
ジャカード類似度は、2 つの集合間の類似性を測定します。数式は次のとおりです。
ここで:
-
J(A,B)は、集合 A と B のジャカード類似度です。 -
∣A∩B∣は、集合 A と B の積集合です。 -
∣A∪B∣は、集合 A と B の和集合です。
不正検知において、ジャカード類似度にはいくつかのアプリケーションがあります。
-
パターン認識:ユーザーのトランザクションや行動のジャカード類似度を計算することで、類似したパターンを特定し、潜在的な不正を示すことができます。
-
顧客グループ分析:顧客の行動を分析する際に、ジャカード類似度を使用して顧客間の類似性を比較できます。類似度スコアが高い顧客は、類似したリスクプロファイルを共有している可能性があります。
この例では、関連する住所、メール、その他の情報に基づいて、2 つのトランザクション間のジャカード類似度を計算できます。この情報の重複度が高いほど、トランザクション間の類似度が高いことを示します。
-
必要な関数を作成します。
-
特定のトランザクションに関連するすべてのノードを取得し、それらの ID の配列を返す関数を作成します。
CREATE OR REPLACE FUNCTION find_ids(transactionid integer) RETURNS bigint[] LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids bigint[]; BEGIN sql := 'SELECT array_agg(cast(e as bigint)) FROM ( SELECT * FROM cypher(''fraud_graph'', $$ MATCH (n:transaction)-[]->(v) WHERE n.transactionid = ' || text($1) || 'RETURN id(v) $$) as (e agtype)) as t;'; EXECUTE sql INTO ids; return ids; END $function$; -
配列に対して
Union(和集合) とIntersection(積集合) の操作を実行する 2 つの関数を作成します。CREATE OR REPLACE FUNCTION array_union(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(a ORDER BY a) FROM ( SELECT DISTINCT unnest($1 || $2) AS a ) s; $$; CREATE OR REPLACE FUNCTION array_intersection(anyarray, anyarray) RETURNS anyarray LANGUAGE sql immutable AS $$ SELECT array_agg(e) FROM ( SELECT unnest($1) INTERSECT SELECT unnest($2) ) AS dt(e) $$; -
2 つのトランザクション間のジャカード類似度を計算する関数を作成します。
CREATE OR REPLACE FUNCTION jaccardSimilarity(tid1 integer, tid2 integer) RETURNS float8 LANGUAGE plpgsql AS $function$ DECLARE sql VARCHAR; ids1 bigint[]; ids2 bigint[]; union_list bigint[]; intersection_list bigint[]; BEGIN ids1 = find_ids($1); ids2 = find_ids($2); union_list = array_union(ids1, ids2); -- union intersection_list = array_intersection(ids1, ids2); -- intersection RETURN CASE WHEN array_length(union_list,1) = 0 THEN 0 ELSE array_length(intersection_list,1) * 1.0/ array_length(union_list,1) END AS jaccardSimilarity; END $function$;
-
-
関数を実行してジャカード類似度を計算します。
-
2 つの特定のトランザクション ID 間の類似性を比較します。
SELECT jaccardSimilarity(2987000, 2987172);コマンドは次の結果を返します。
jaccardsimilarity ---- 0.4
-
-
すべてのトランザクションにわたって類似性を比較するには、
PolarDBのストアドプロシージャ機能を使用して、より複雑な計算を実行できます。たとえば、次の SQL ステートメントを使用して、トランザクション 2987002 と同じ主要住所、副次住所、およびメールドメインを共有するすべてのトランザクションを検索できます。結果はジャカード類似度でソートされ、最も類似した 50 件のトランザクションが特定されます。
WITH tmp AS (SELECT cast(e as integer) as transactionid FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[:transaction_addr2]->(:addr2)<-[:transaction_addr2]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_addr1]->(:addr1)<-[:transaction_addr1]-(t:transaction) WHERE n.transactionid = 2987002 MATCH (n:transaction)-[:transaction_emaildomain_p]->(:emaildomain)<-[:transaction_emaildomain_p]-(t:transaction) WHERE n.transactionid = 2987002 RETURN t.transactionid $$) as (e agtype) ) SELECT transactionid, jaccardSimilarity(2987002, transactionid) as jaccardSimilarity FROM tmp ORDER by jaccardSimilarity DESC LIMIT 50;コマンドは次の結果を返します。
transactionid | jaccardsimilarity ---------------+------------------- 3323911 | 0.6 3328911 | 0.6 3009043 | 0.6 3039416 | 0.6 3039425 | 0.6 2993652 | 0.6 3045027 | 0.6 3037644 | 0.6 3045041 | 0.6 ...age-viewer可視化ツールで結果をプレビューするには、次の SQL クエリを実行します。クエリ内のトランザクション ID は、前の計算の上位 10 件の結果です。このリストは必要に応じて調整できます。SELECT * FROM cypher('fraud_graph', $$ MATCH (n:transaction)-[r]->(v)<-[r2]-(t:transaction) WHERE n.transactionid = 2987002 AND t.transactionid IN [3323911, 3328911,3009043,3039416,3039425,2993652,3045027,3037644,3045041,3045049,3045279] RETURN [n,r,v,r2,t]::path $$) as (e agtype);
まとめ
このガイドでは、PolarDB for PostgreSQL および のグラフ分析機能を使用してグラフデータを分析する方法を説明しました。AGE 拡張機能を組み合わせることで、PolarDB は、Cypher クエリ言語を使用してグラフクエリを効率的に処理するなど、グラフデータの計算と分析のための強力な機能を提供します。この機能は、企業における統一されたデータ管理と分析を強力にサポートします。
無料トライアル
PolarDB 無料トライアルページにアクセスし、PolarDB for PostgreSQL を選択して、GanosBase のグラフコンピューティング機能を体験してください。