グラフデータベースはグラフデータを格納し、ソーシャルネットワークやナレッジグラフなどの複雑な関係性を扱うのに最適です。このデータを操作するには、Cypher や Gremlin などのグラフクエリ言語を使用します。PolarDB は OpenCypher 構文をサポートし、グラフデータの作成、クエリ、更新、削除、パターンマッチング、フィルタリング、重複を回避するための MERGE、可視化ツールなどの機能を提供することで、グラフデータ管理とアプリケーション開発を簡素化します。
用語
-
グラフ:グラフは、ノードとエッジで構成されるデータ構造です。例えば、ソーシャルネットワークは典型的なグラフであり、各人物がノードであり、友人、家族、同僚などの関係がエッジです。

-
ノード:ノードは、グラフデータベースの基本要素であり、エンティティを表します。ノードには、エンティティに関する情報を格納するプロパティを持つことができます。ソーシャルネットワークでは、ノードはユーザー、企業、組織などを表す場合があります。
-
エッジ:エッジはノードを接続し、関係を表します。エッジには、関係の強さや方向を示す重みや方向などの属性を持つことができます。ソーシャルネットワークでは、エッジはフォロー、友情、ファン関係などを表す場合があります。
-
ラベル:ラベルは、ノードまたはエッジを分類するために使用されるカテゴリまたは属性です。ラベルは、データにセマンティックな意味を与え、クエリと分析を容易にします。ソーシャルネットワークでは、ノードラベルには Person や Company が含まれる場合があり、エッジラベルには Knows や WorkIn が含まれる場合があります。
-
プロパティグラフ:ノードにプロパティ (エンティティに関する詳細) が含まれている場合、またはエッジにプロパティ (関係に関する詳細) が含まれている場合、グラフはプロパティグラフと呼ばれます。次の例は、同僚関係をプロパティグラフとして示しており、ノードとエッジの両方に関連する属性があります。
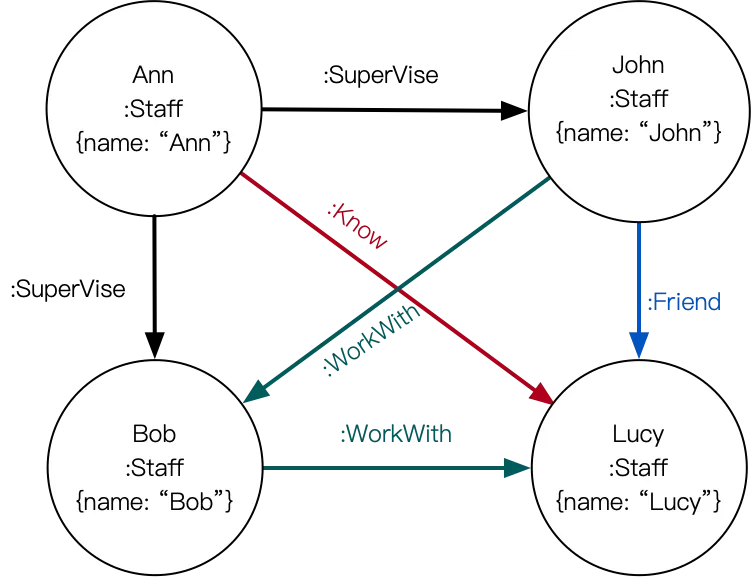
-
グラフデータベース:グラフを使用してデータを格納する特殊なデータベースです。ノードはエンティティを表し、エッジは関係を表します。ソーシャルネットワーク、信頼ネットワーク、ナレッジグラフなどの複雑な関係データの処理に優れています。
グラフデータベースは、Cypher や Gremlin などのグラフクエリ言語を使用してデータをクエリします。PolarDB は OpenCypher 構文をサポートしています。OpenCypher は Cypher のオープンソースのサブセットであり、その機能のほとんどは Cypher と同等です。
スキーマ
プロパティ
Cypher では、プロパティを定義するために中括弧 {} を使用します。プロパティは、JSON と同様に、キーと値のペアで構成されます。キーは文字列であり、値には文字列、数値、または配列を使用できます。たとえば、{name: 'Reeves'} は、名前が Reeves であることを意味します。
ノード
Cypher では、ノードは丸括弧 () で表されます。以下に例を示します。
()
(matrix)
(:Movie)
(matrix:Movie)
(matrix:Movie {title: 'The Matrix'})
(matrix:Movie {title: 'The Matrix', released: 1997})ここで:
-
最も単純な形式の
()は、匿名で特徴のないノードを表します。 -
同じステートメント内の他の場所でノードを参照するには、
(matrix)のように変数を追加します。変数は単一のステートメント内でのみ有効です。他のステートメントでは、意味が異なるか、意味を持たない場合があります。 -
:Movieはノードのラベルを宣言し、パターンがそのラベルを持つノードのみに一致するように制限します。 -
{title: 'The Matrix'}は、情報を格納したりパターンを制約したりできるノードプロパティを定義します。
エッジ
Cypher では、無向エッジには 2 つのダッシュ -- を、有向エッジには矢印 <-- または --> を使用します。角括弧表現 [...] を使用して、変数、プロパティ、または型情報などの詳細を追加します。例:
--
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ['Neo']}]->ここで:
-
--は匿名の無向エッジです。 -
-->は匿名有向エッジです。 -
変数 (たとえば、
role) を定義し、ステートメント内の他の場所で使用できます。 -
リレーションシップラベル (たとえば、
:ACTED_IN) は、ノードラベルのように機能します。 -
プロパティ (たとえば、
roles: ['Neo']) は、ノードプロパティと同様に定義されます。
例
次の例では、PolarDB でグラフ機能を使用する方法を示します。サンプルデータは、俳優と映画を含むシンプルな映画データベースです。
拡張機能の作成
特権アカウントを使用して、次のステートメントを実行してください。特権アカウントを作成するには、「」 「」をご参照ください。
age 拡張機能は、現在、手動での作成に対応していません。この機能を使用するには、弊社にて拡張機能を作成しますので、チケットを起票してご連絡ください。
CREATE EXTENSION age;データベースの設定
各接続で、クエリを簡略化するために search_path に ag_catalog を追加し、get_cypher_keywords 関数を使用して拡張機能をロードします:
データ管理 (DMS) を使用して search_path を構成すると、互換性の問題が発生する可能性があります。 そのような場合は、 を使用して関連する文を実行できます。
SET search_path = ag_catalog, "$user", public;
SELECT * FROM get_cypher_keywords() limit 0;特権アカウントでデータベースパラメータを設定し、拡張機能を永続的にロードすることを強く推奨します。これにより、接続ごとに上記の手順を繰り返す必要がなくなり、使用が簡素化されます。
ALTER DATABASE <dbname> SET search_path = "$user", public, ag_catalog;
ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';一般ユーザーに AGE アクセスを付与
一般ユーザーに、ag_catalog スキーマの USAGE 権限を付与します。
GRANT USAGE ON SCHEMA ag_catalog TO <username>;一般ユーザーが RW ユーザーの場合は、テーブル作成を許可するために CREATE 権限も付与します。
GRANT CREATE ON DATABASE <dbname> TO <username>;クエリ構造
PolarDB の Cypher クエリは、SETOF records を返す ag_catalog の cypher 関数を呼び出すことによって構築されます。一般的なクエリは次のとおりです。
SELECT * FROM cypher('graph_name', $$
/* Cypher クエリをここに記述します */
$$) AS (result1 agtype, result2 agtype);ここで、graph_name はグラフの名前を示し、/* */ ブロックを実際の Cypher クエリに置き換えます。
グラフの作成
グラフは、使用する前にまず作成する必要があります。ag_catalog 名前空間の create_graph 関数を使用します。
構文:
SELECT create_graph('<graph_name>');例:
moviedb という名前のグラフを作成します。
SELECT create_graph('moviedb');データの挿入
次の SQL 文を実行し、moviedb グラフにサンプルデータを挿入します:
SELECT * FROM cypher('moviedb', $$
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
$$) AS (result1 agtype);これにより、6 つのノード (Movie ラベルが 3 つ、Person ラベルが 3 つ) と 3 つのエッジ (ACTED_IN ラベルが 2 つ、DIRECTED ラベルが 1 つ) が作成されます。関係図を次に示します。
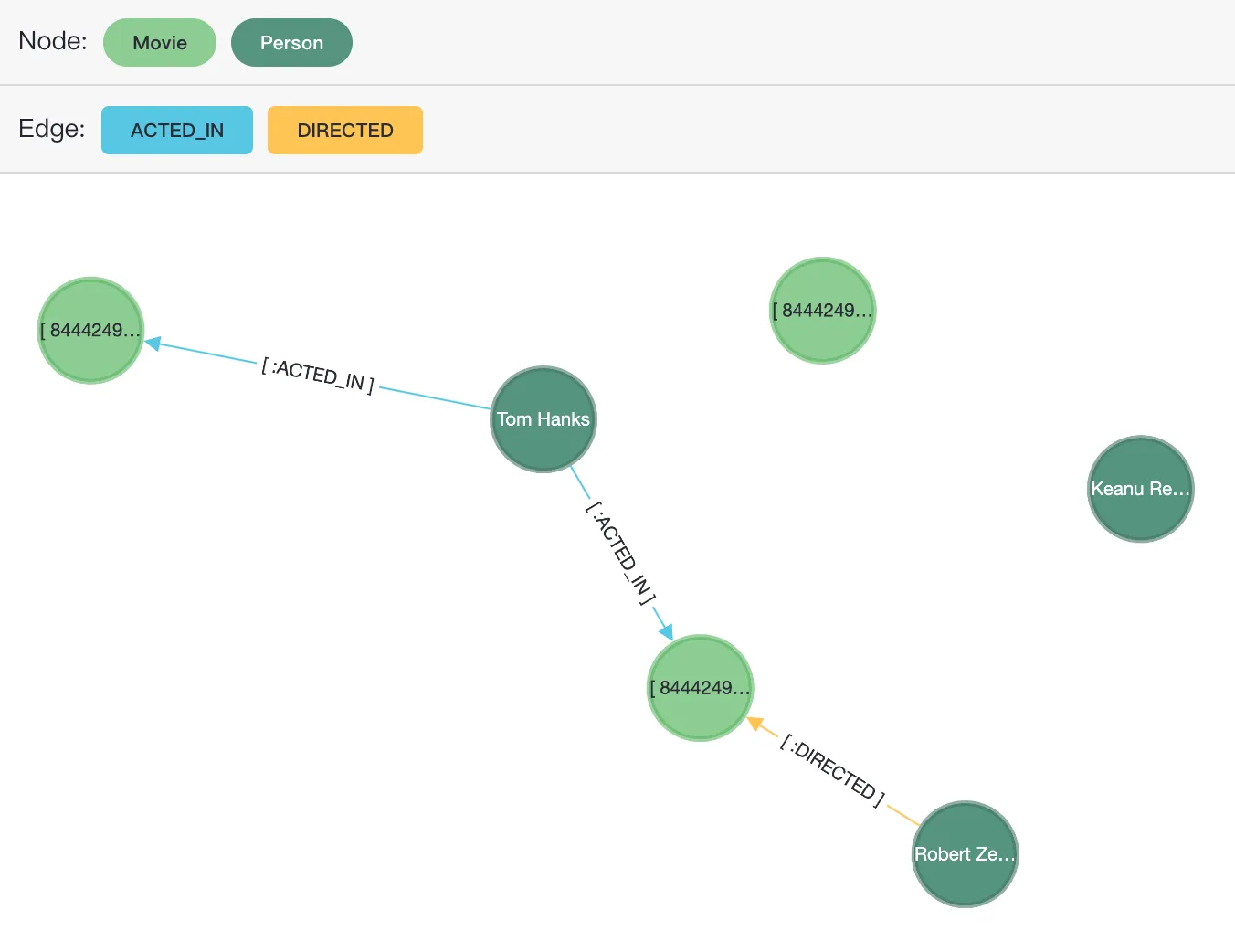
データのクエリ
データクエリ
Cypher では、MATCH および RETURN キーワードを使用してデータをクエリします:
-
MATCHは、パターンマッチングを行い、指定されたパターンに一致するコンテンツを検索します。 -
RETURNは、Cypher クエリから返す値または結果を指定します。
構文:
SELECT * FROM cypher('graph_name', $$
MATCH <patterns>
RETURN <variables>
$$) AS (result1 agtype);例:
-
Movieラベルを持つすべてのノードを検索します。SELECT * FROM cypher('moviedb', $$ MATCH (m:Movie) RETURN m $$) AS (result1 agtype); -
PersonノードとMovieノードを接続する、ACTED_INというラベルが付いたエッジを検索します。SELECT * FROM cypher('moviedb', $$ MATCH (:Person)-[r:ACTED_IN]->(:Movie) RETURN r $$) AS (result1 agtype);
データフィルタリング
WHERE 句を使用して、パターンマッチング時に結果をフィルタリングし、目的のサブセットのみを返します。この句を使用すると、ブール式を使用してデータをフィルタリングできます。
例:
-
タイトルが
The Matrixのすべての映画を見つけます。SELECT * FROM cypher('moviedb', $$ MATCH (m:Movie) WHERE m.title = 'The Matrix' RETURN m $$) AS (result1 agtype); -
映画
Forrest Gumpのすべての俳優を検索します。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person)-[:ACTED_IN]->(m) WHERE m.title = 'Forrest Gump' RETURN p $$) AS (result1 agtype); -
2000 年以降にリリースされた映画の俳優を検索します。
SELECT * FROM cypher('moviedb', $$ MATCH (p:Person)-[:ACTED_IN]->(m) WHERE m.released > 2000 RETURN p, m $$) AS (result1 agtype, result2 agtype);
ノードまたはエッジの作成
Cypher では、新しいノードまたはエッジを追加するには、CREATE キーワードを使用します。
構文:
SELECT * FROM cypher('<graph_name>', $$
CREATE <patterns>
$$) AS (result1 agtype);例:
-
名前が
Tom Tykwer、誕生年が1965のPersonノードを作成します。SELECT * FROM cypher('moviedb', $$ CREATE (:Person {name: 'Tom Tykwer', born: 1965}) $$) AS (result1 agtype); -
Tom TykwerがCloud Atlasを監督したことを示す、Tom Tykwer–Cloud Atlasエッジを作成します。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person), (m:Movie) WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas' CREATE (p)-[:DIRECTED]->(m) $$) AS (result1 agtype);
MERGE を使用した重複挿入の回避
同じ CREATE ステートメントを複数回実行すると、重複したデータが挿入されます。これを防ぐには、MERGE キーワードを使用します。MERGE は、データがすでに存在するかどうかを確認します。データが存在する場合、既存のデータを返すか、ノードまたはリレーションシップを更新します。存在しない場合は、指定されたパターンに基づいて新しいデータを作成します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MERGE <patterns>
$$) AS (result1 agtype);例:
-
名前が
Tom Cruiseで、生年が1962のPersonノードを作成します。SELECT * FROM cypher('moviedb', $$ MERGE (:Person {name: 'Tom Cruise', born: 1962}) $$) AS (result1 agtype); -
Tom HanksとTom Cruiseの間に友情エッジを作成します。SELECT * FROM cypher('moviedb', $$ MATCH (t1:Person),(t2:Person) WHERE t1.name='Tom Hanks' AND t2.name='Tom Cruise' MERGE (t1)-[:FRIEND]-(t2) $$) AS (result1 agtype);
更新
既存のノードまたは関係のプロパティを変更するには、目的のパターンに一致させ、SET キーワードを使用してプロパティを追加または更新します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
SET <property>
RETURN <variable>
$$) AS (result1 agtype);例:
-
Tom Tykwerの生年を 1970 に変更します。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person {name: 'Tom Tykwer', born: 1965}) SET p.born = 1970 RETURN p $$) AS (result1 agtype); -
Tom Tykwerに、値がmaleの gender プロパティを追加します。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person {name: 'Tom Tykwer', born: 1970}) SET p.gender = 'male' RETURN p $$) AS (result1 agtype);
削除
Cypher では、DELETE キーワードを使用してノードとエッジを削除します。
エッジの削除
エッジを削除するには、MATCH を使用してエッジを検索し、DELETE で削除します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DELETE <variable>
$$) AS (result1 agtype);例:
Tom Tykwer と映画 Cloud Atlas の間の有向エッジを削除します。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[r:DIRECTED]->(m:Movie)
WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas'
DELETE r
$$) AS (result1 agtype);ノードの削除
ノードを削除するには、MATCH でノードを見つけ、DELETE で削除します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DELETE <variable>
$$) AS (result1 agtype);例:
Tom Tykwer ノードを削除します。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Tykwer', born: 1970})
DELETE p
$$) AS (result1 agtype);ノードとそのエッジの削除
接続されたエッジがあるノードは、直接削除できません。DETACH DELETE を使用して、接続されているすべてのエッジを削除してからノードを削除します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DETACH DELETE <variable>
$$) AS (result1 agtype);例:
Tom Hanks ノードと、それに接続されているすべてのエッジを削除します。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Hanks', born: 1956})
DETACH DELETE p
$$) AS (result1 agtype);プロパティの削除
ノードまたはエッジからプロパティを削除するには、REMOVE キーワードを使用します。
構文:
SELECT * FROM cypher('<graph_name>', $$
MATCH <match_pattern>
REMOVE <property>
$$) AS (result1 agtype);例:
映画 Cloud Atlas から released プロパティを削除します。
SELECT * FROM cypher('moviedb', $$
MATCH (m:Movie {title: 'Cloud Atlas', released: 2012})
REMOVE m.released
RETURN m
$$) AS (result1 agtype);可視化ツール
は、オープンソースのグラフエンジンである Apache AGE を統合しており、同じクラスターで標準 SQL と業界標準の OpenCypher グラフクエリ言語の両方を使用できます。これにより、複雑なリレーションシップのシナリオでグラフデータを効率的に格納、クエリ、分析できます。詳細については、「グラフアプリケーション」をご参照ください。
AGE Viewer で、moviedb グラフに対して Cypher クエリ SELECT * from cypher('moviedb', $$ MATCH (V) RETURN V UNION MATCH ()-[r]->() RETURN r $$) as (V agtype); を実行します。可視化では、3 つの Movie ノードと 3 つの Person ノード (Tom Hanks、Keanu Reeves、Robert Zemeckis)、および 2 つの ACTED_IN エッジと 1 つの DIRECTED エッジが Cose-Bilkent レイアウトを使用して表示されます。