モデル圧縮は、予測性能の損失を最小限に抑えながら、モデルサイズと計算コストを削減します。
仕組み
PAI モデルギャラリーは、重みのみの量子化 (Weight-only Quantization) に基づくモデル量子化をサポートしています。MinMax-8Bit および MinMax-4Bit 戦略は、浮動小数点数の重みパラメーターを 8 ビットまたは 4 ビットの整数表現に変換します。これにより、モデルサイズと GPU メモリ使用量が削減され、精度への影響を最小限に抑えながら、リソースに制約のある環境でもディープラーニングモデルをデプロイできるようになります。
モデルの圧縮
-
モデルをトレーニングします。
圧縮できるのはトレーニング済みのモデルのみです。まず、事前学習済みモデルをトレーニングします。詳細については、「モデルのデプロイとトレーニング」をご参照ください。
-
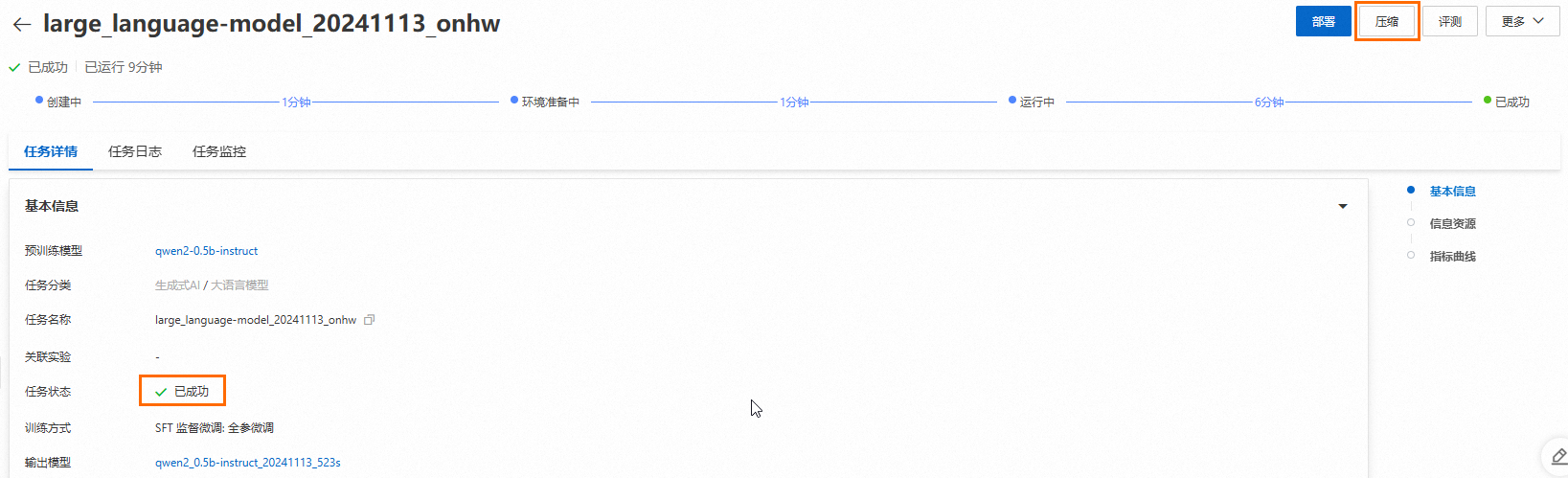
モデルトレーニングが完了したら、Task details ページの右上隅にある Compression をクリックします。
-
圧縮パラメーターを設定します。
次の表に、主要なパラメーターを示します。
パラメーター
説明
圧縮メソッド
モデル量子化 (重みのみの量子化) のみがサポートされています。これは、重みパラメーターをより低いビット幅に変換して、推論中の GPU メモリ使用量を削減します。
圧縮戦略
-
MinMax-8Bit:min-max スケーリングを使用して、モデルの重みを 8 ビット整数に量子化します。
-
MinMax-4Bit:min-max スケーリングを使用して、モデルの重みを 4 ビット整数に量子化します。
その他のパラメーターについては、「モデルのデプロイとトレーニング」をご参照ください。
-
-
Compression をクリックします。
圧縮タスクのステータスとログが表示されるTask details ページにリダイレクトされます。
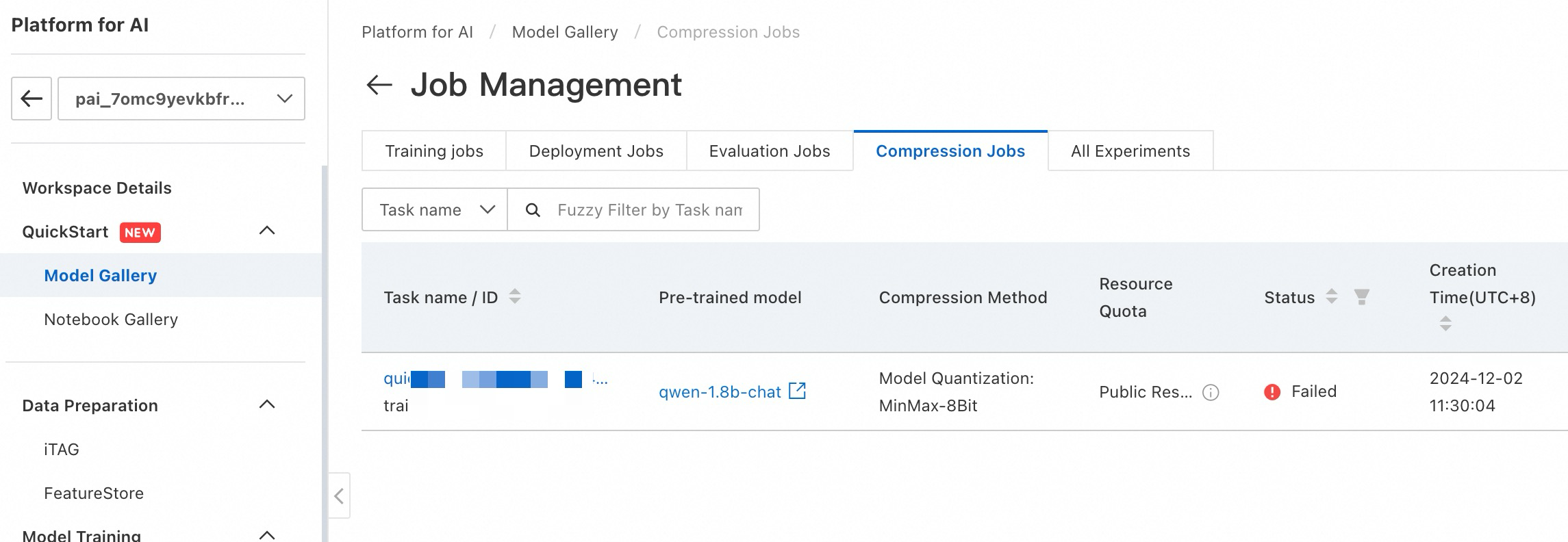
圧縮ジョブの表示
圧縮ジョブを表示するには、PAI モデルギャラリー > Job Management > Compression Jobs に移動します。