モデルギャラリーには、複数の事前学習済み大規模言語モデル (LLM) が含まれており、LLMの機能を評価するのに役立つ包括的なモデル評価機能を提供します。
機能概要
モデル評価機能は、LLMを次の2つの側面から評価します。
カスタムデータセットを使用した評価
ルールベース評価:ROUGEおよびBLEUメトリックを使用して、モデルの予測と正解の回答との類似性を測定します。
LLM-as-a-Judge 評価:PAI Qwen2ベースのジャッジモデルを使用して、各モデルの出力を個別にスコアリングします。この方法は、オープンエンドで複雑なQ&Aシナリオで特に効果的です。
公開データセットを使用した評価
MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQAなどの業界標準の公開データセットでモデルを評価します。
業界の評価標準に合わせたベンチマークスコアを提供します。
サポートされているモデル:すべてのHuggingFace AutoModelForCausalLMモデルタイプ。
新機能:LLM-as-a-Judge スコアリングが利用可能です。Qwen2ベースの大規模言語モデル (LLM) がジャッジとして機能し、モデルの出力をスコアリングします。これは、オープンエンドで複雑なQ&Aシナリオに最適です。モデル評価の[エキスパートモード]で無料で試すことができます。[2024.09.01]
シナリオ
モデル評価は、モデル開発の重要な部分です。一般的なユースケースを次に示します。
モデルベンチマーク
公開データセットを使用して、一般的なモデル機能を評価します。
モデルを業界ベンチマークや他のモデルと比較します。
ドメイン固有の機能評価
モデルを特定のドメインに適用します。
事前学習済みモデルとファインチューニング済みモデルのドメイン全体でのパフォーマンスを比較します。
モデルがドメイン知識をどの程度適用できるかを評価します。
モデル回帰テスト
回帰テストセットを構築します。
実際のビジネスシナリオでモデルのパフォーマンスを評価します。
モデルが本番環境の標準を満たしているかどうかを判断します。
課金情報
データ準備
モデル評価機能は、カスタムデータセットまたはC-Evalなどの公開データセットを使用した評価をサポートしています。
公開データセット:
PAIは現在、次の公開データセットを維持しています。MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、およびTruthfulQA。これらは直接使用できます。今後、さらに多くの公開データセットが追加される予定です。
カスタムデータセット:
JSONL形式の評価ファイルを提供できます。OSSにアップロードしてカスタムデータセットを作成します。詳細については、「OSSファイルのアップロード」および「データセットの作成と管理」をご参照ください。ファイル形式は次のとおりです。
questionを使用して質問列をラベル付けし、answerを使用して回答列をラベル付けします。または、評価ページで特定の列を選択することもできます。カスタムデータセットのLLM-as-a-Judge評価のみを実行する必要がある場合、answer列はオプションです。{"question": "Did China invent papermaking? Is this correct?", "answer": "Correct"} {"question": "Did China invent gunpowder? Is this correct?", "answer": "Correct"}サンプルファイル:eval.jsonl
ワークフロー

ステップ1: モデルの選択
モデルギャラリーページに移動できます。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、Workspaces をクリックします。その後、対象のワークスペースを選択して入ります。
左側のナビゲーションウィンドウで、QuickStart>[モデルギャラリー] を選択して、モデルギャラリーページに移動します。
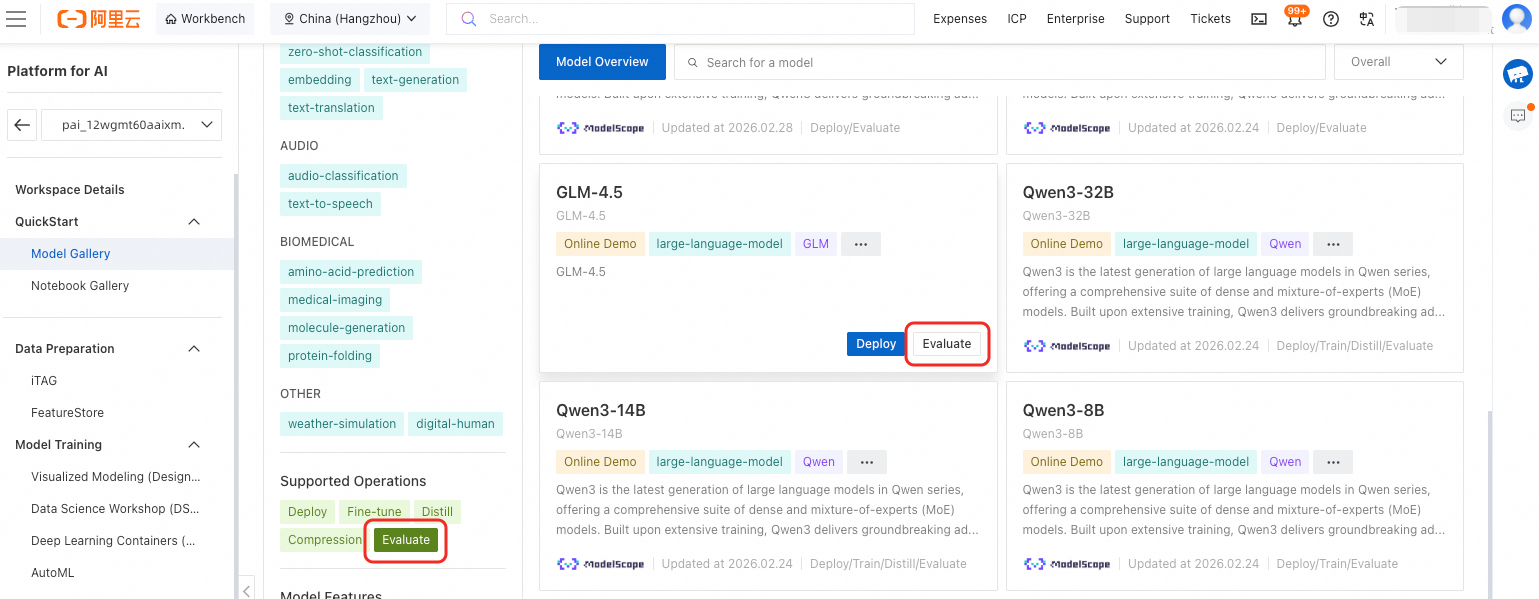
評価をサポートするモデルを見つけることができます。
モデルギャラリーで評価可能なモデルをフィルターできます。Supported Operations フィルターセクションで、Evaluate を選択すると、評価に対応したモデルのみが表示されます。
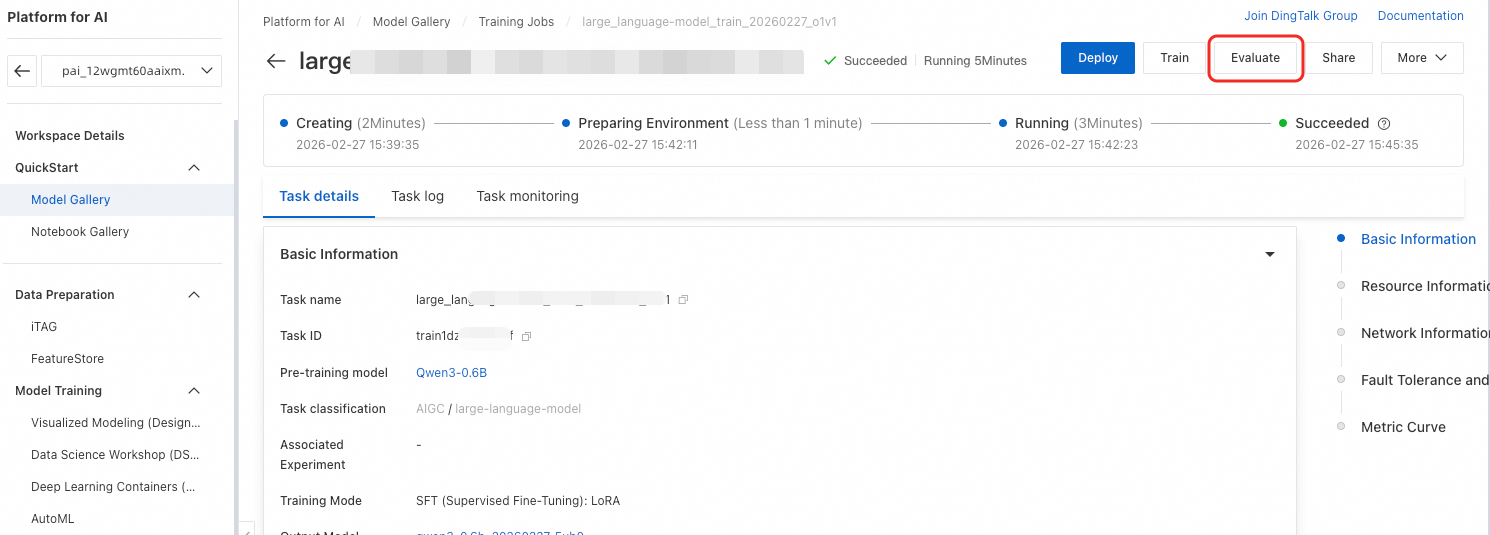
ファインチューニング済みモデルを評価できます。モデルが評価をサポートしている場合、そのファインチューニング済みバージョンも評価をサポートします。モデルギャラリーページで、左上隅の Job Management > Training Jobs をクリックします。次に、対象のジョブ名をクリックして、その詳細ページを開きます。右上隅の Evaluate ボタンをクリックします。
ステップ2: 評価タスクの設定
公開データセットとカスタムデータセットの両方を使用して評価できます。また、ハイパーパラメーターを設定したり、LLM-as-a-Judge評価を使用したり、複数の公開データセットを選択したりすることもできます。
基本パラメーターを設定できます。
Job Name: 自動生成された一意の名前。
Result Output Path: 評価結果が保存される OSS パスです。
Label: タグを使用して、検索、特定、バッチ操作の実行、および複数のディメンションにわたりコストを割り当てることができます。
評価方法を設定できます。
Evaluation Method:以下のいずれかを選択できます。
Set Dataset to Public: 複数のデータセットを選択できます。
Custom Dataset: 質問列と参照回答列を指定できます。LLM-as-a-Judge 評価のみが必要な場合、参照回答列は任意です。
Dataset Source: 以下のいずれかを選択できます。Select OSS File または Select an existing dataset.
Evaluation Method: Judge Model Evaluation または General Metric Evaluation を選択できます。
PAI-Judge Model Service Token: このパラメーターは、LLM-as-a-Judge 評価を使用する際に自動設定されます。また、LLM-as-a-Judge ページから取得することもできます。
計算リソースを設定します。
Resource Group Type: 従量課金のパブリックリソースグループ、または作成したサブスクリプションリソースクォータを選択します。
パラメーターの設定が完了したら、OK をクリックしてタスクを送信します。ページは自動的にタスク詳細ページにリダイレクトされます。タスクが完了するまで待ちます。次に、Evaluation Report をクリックしてレポートを表示します。
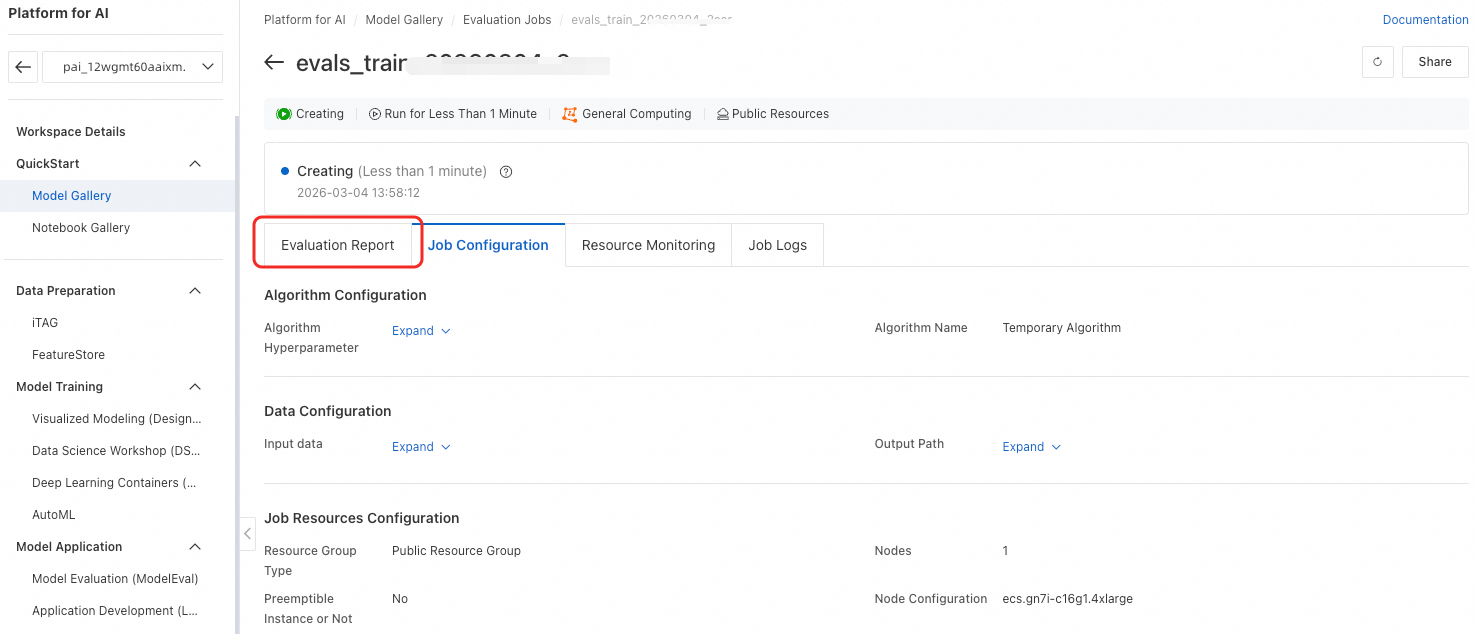
評価結果の表示
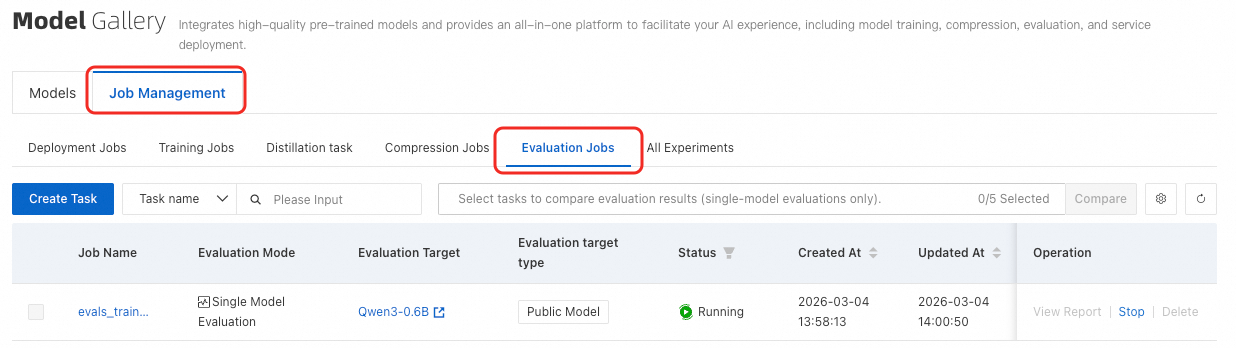
評価タスクリスト
モデルギャラリーページで、Job Management をクリックします。次に、Evaluation Jobs タブに切り替えます。
単一タスクの結果
評価タスクリストページで、対象の評価タスクの「操作」列にあるView Reportをクリックします。 タスク詳細ページが開きます。 「評価レポート」セクションで、カスタムデータセットとパブリックデータセットの両方のスコアを確認できます。
カスタムデータセット評価結果ページ
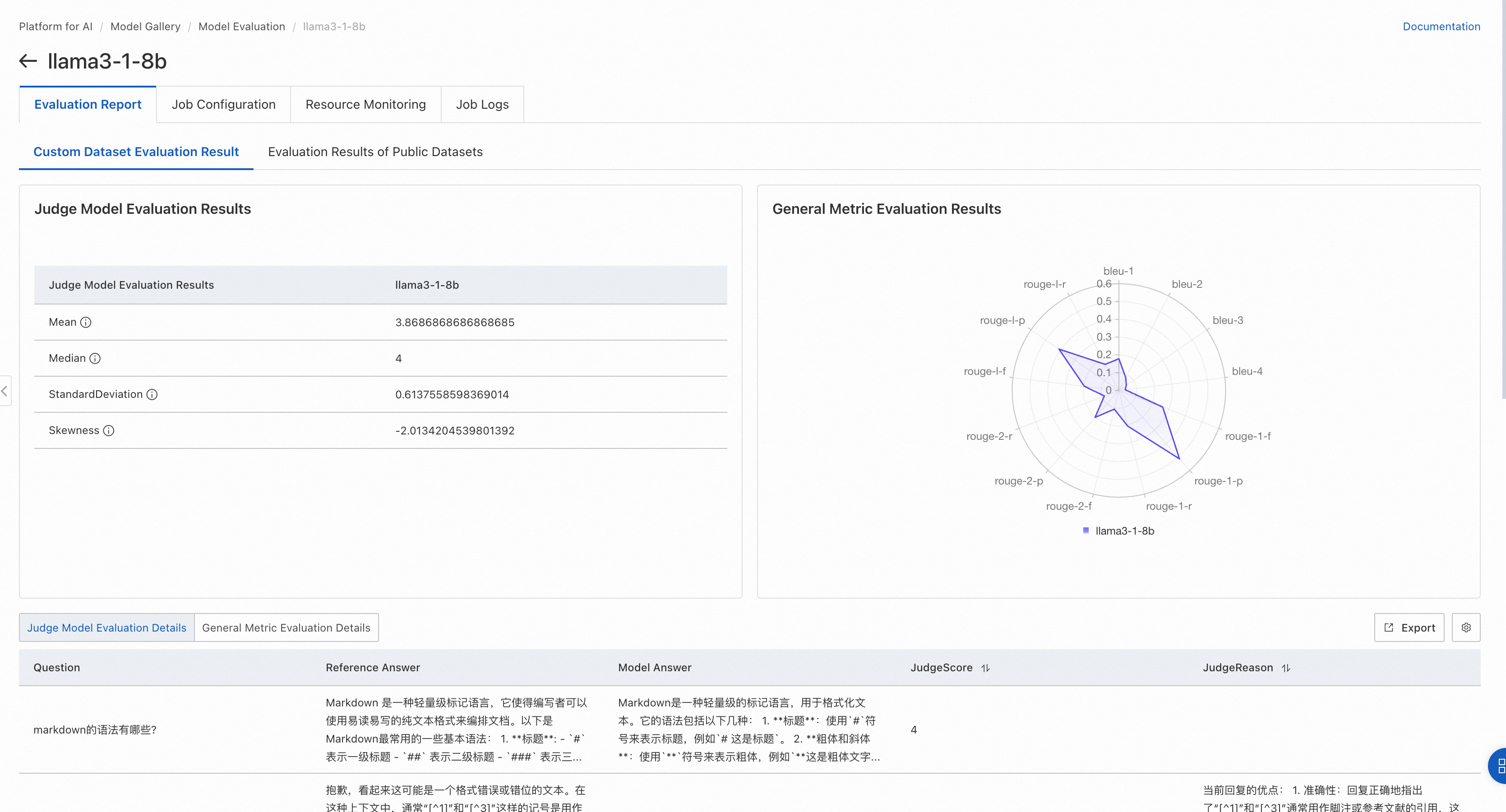
汎用メトリック評価を選択した場合、レーダーチャートにはROUGEおよびBLEUメトリックのスコアが表示されます。カスタムデータセットのデフォルトメトリックには、rouge-1-f、rouge-1-p、rouge-1-r、rouge-2-f、rouge-2-p、rouge-2-r、rouge-l-f、rouge-l-p、rouge-l-r、bleu-1、bleu-2、bleu-3、およびbleu-4が含まれます。
ROUGEメトリック:
ROUGE-nメトリックはN-gramの重複を測定します。ROUGE-1とROUGE-2が最も一般的です。これらはそれぞれユニグラムとバイグラムに対応します。
rouge-1-p (精度):システム要約内のユニグラムと参照要約内のユニグラムが一致する比率。
rouge-1-r (再現率):参照要約内のユニグラムがシステム要約に表示される比率。
rouge-1-f (Fスコア):精度と再現率の調和平均。
rouge-2-p (精度):システム要約内のバイグラムと参照要約内のバイグラムが一致する比率。
rouge-2-r (再現率):参照要約内のバイグラムがシステム要約に表示される比率。
rouge-2-f (Fスコア):精度と再現率の調和平均。
ROUGE-Lは最長共通部分列 (LCS) を使用します。
rouge-l-p (精度):システム要約と参照要約間のLCS一致に基づく精度。
rouge-l-r (再現率):システム要約と参照要約間のLCS一致に基づく再現率。
rouge-l-f (Fスコア):システム要約と参照要約間のLCS一致に基づくFスコア。
BLEUメトリック:
BLEU (Bilingual Evaluation Understudy) は、機械翻訳の品質を評価するためのもう1つの一般的なメトリックです。参照翻訳のセットとのN-gramの重複を測定することで出力をスコアリングします。
bleu-1:ユニグラムの重複を測定します。
bleu-2:バイグラムの重複を測定します。
bleu-3:トライグラム (3つの連続する単語) の重複を測定します。
bleu-4:4-グラムの重複を測定します。
LLM-as-a-Judge評価を選択した場合、ページにはジャッジモデルスコアの統計メトリックがリストされます。
ジャッジモデルは、PAIによってファインチューニングされたQwen2ベースのLLMです。そのパフォーマンスは、AlighbenchなどのオープンソースベンチマークでGPT-4と一致します。一部のシナリオでは、GPT-4を上回ります。
ページには、ジャッジモデルスコアの4つの統計メトリックが表示されます。
平均:ジャッジLLMによって与えられた平均スコア (無効なスコアを除く)。スコアは1から5の範囲です。値が高いほど、モデルの応答が優れていることを示します。
中央値:ジャッジLLMによって与えられた中央値スコア (無効なスコアを除く)。スコアは1から5の範囲です。値が高いほど、モデルの応答が優れていることを示します。
標準偏差:ジャッジLLMによって与えられたスコアの標準偏差 (無効なスコアを除く)。平均と中央値が等しい場合、標準偏差が小さいほどモデルのパフォーマンスが優れていることを示します。
歪度:ジャッジLLMスコア分布の歪度 (無効なスコアを除く)。正の歪度は右側 (高スコア側) に長い裾があることを意味します。負の歪度は左側 (低スコア側) に長い裾があることを意味します。
ページの下部には、評価ファイル内の各行の評価詳細も表示されます。
公開データセット評価結果ページ
評価タスクで公開データセットを使用した場合は、レーダーチャートにそれらのデータセット全体のスコアが表示されます。
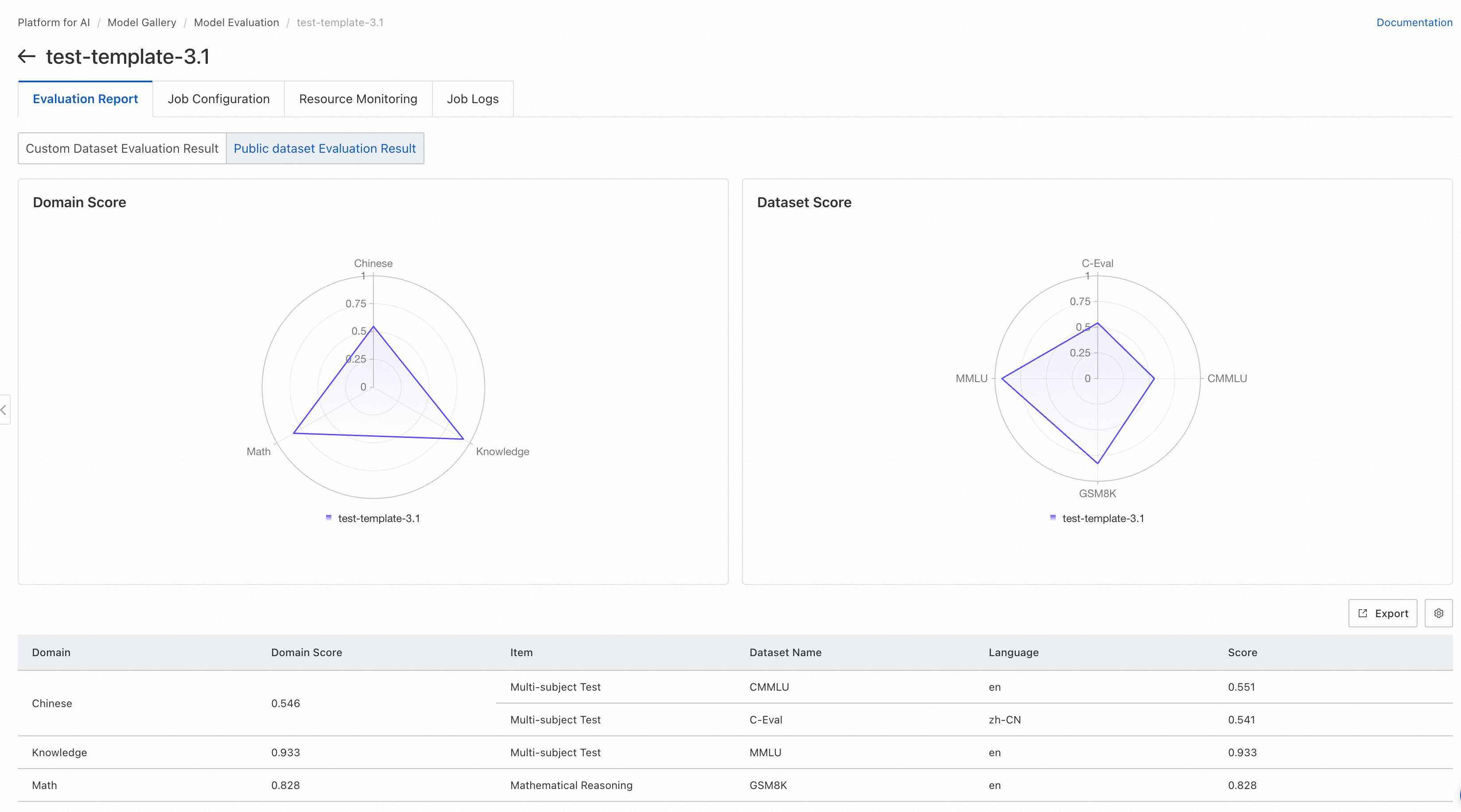
左側のチャートは、ドメイン全体のスコアを示します。各ドメインには複数の関連データセットがある場合があります。同じドメイン内のデータセットについては、モデルスコアを平均して単一のドメインスコアを取得します。
右側のチャートは、各公開データセットのスコアを示します。各データセットの公式ドキュメントで評価範囲を確認できます。
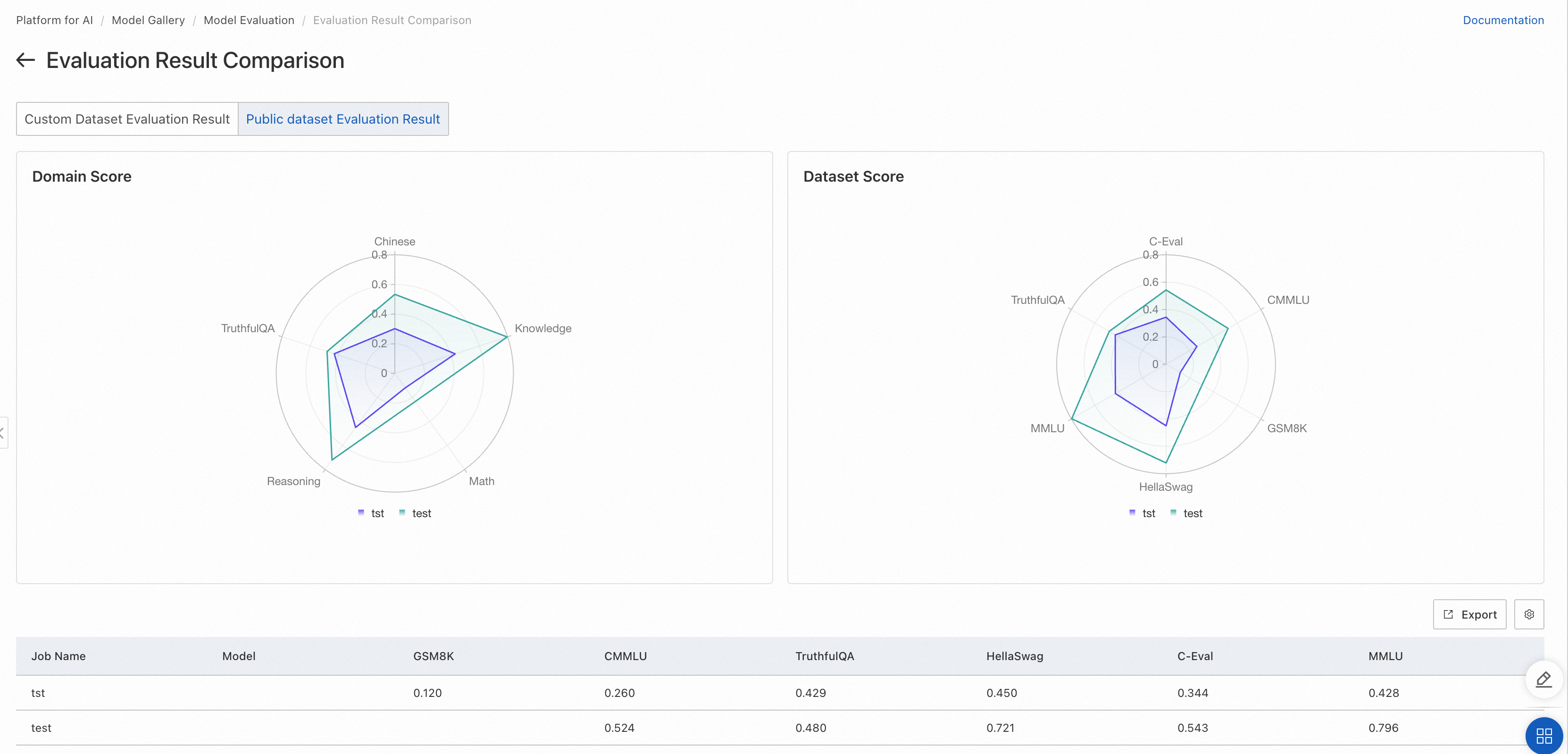
複数の評価タスクの比較
複数のモデルの結果を比較するには、それらを単一のページにグループ化できます。評価タスクリストページで、比較するタスクを左側で選択します。次に、右上隅の[比較] をクリックして比較ページを開きます。

カスタムデータセット比較結果

公開データセット比較結果
結果分析
カスタムデータセット評価
汎用メトリック評価:標準的なNLPテキストマッチング手法を使用して、モデルの出力とグラウンドトゥルース間の類似性を計算します。スコアが高いほど、モデルのパフォーマンスが優れていることを意味します。特定のシナリオにドメイン固有のデータを使用してモデルがどの程度適合するかを評価するのに最適です。
LLM-as-a-Judge 評価:LLMの強みを活用して、セマンティックレベルで出力品質を評価します。平均と中央値のスコアが高く、標準偏差が低いほど、モデルのパフォーマンスが優れていることを示します。単純なテキストマッチングと比較して、この方法は出力品質のより正確な評価を提供します。
公開データセット評価
これは最も一般的なLLM評価方法です。数学やコーディングなど、多くのドメインをカバーするオープンソースの評価データセットを使用して、包括的な機能評価を提供します。スコアが高いほど、モデルのパフォーマンスが優れていることを意味します。
リファレンス
モデル評価は、コンソールだけでなくPAI Python SDKを介しても使用できます。詳細については、次のノートブックをご参照ください。