トレーニングタスクを迅速にサブミットするには、タスクを作成する前に、必要なリソースを準備し、ランタイムイメージ、データセット、およびコードビルドを設定する必要があります。PAI は、File Storage NAS、Cloud Parallel File Storage (CPFS)、または Object Storage Service (OSS) のデータセットをサポートしています。PAI は Git コードビルドもサポートしています。このトピックでは、トレーニングタスクをサブミットする前に必要な準備について説明します。
前提条件
OSS をストレージシステムとして使用する場合、DLC に必要な OSS アクセス権限が付与されていることを確認してください。そうでない場合、OSS をマウントした後にデータにアクセスすると I/O エラーが発生する可能性があります。詳細については、「Alibaba Cloud サービスの依存関係と権限付与:DLC」をご参照ください。
制限事項
OSS は真のファイルシステムではなく、分散オブジェクトストレージサービスです。そのため、OSS をストレージシステムとして使用する場合、一部のファイルシステム機能はサポートされていません。たとえば、OSS をマウントした後、既存のファイルにデータを追加したり、上書きしたりすることはできません。
ステップ 1:リソースの準備
トレーニングタスクをサブミットする前に、AI トレーニング用の計算リソースを準備する必要があります。次のいずれかのリソースタイプを選択できます:
パブリックリソースの準備
DLC の権限付与を完了すると、パブリック汎用計算リソースが自動的に準備されます。手動でリソースグループを追加する必要はありません。ワークスペースの Create Job ページでトレーニングタスクをサブミットする際に、パブリックリソースを選択できます。
汎用計算リソースの準備
専用リソースグループを作成し、必要な汎用計算リソースを事前に購入できます。リソースクォータを作成することで、専用リソースグループの計算リソースを割り当てることができます。その後、リソースクォータをワークスペースにアタッチします。これにより、そのリソースクォータを使用してワークスペースでトレーニングタスクをサブミットできます。詳細については、「汎用計算リソースクォータ」をご参照ください。
Lingjun リソースの準備
高性能 AI トレーニングを行うには、トレーニングタスクをサブミットする前に、必要な Lingjun リソースを準備し、ワークスペースに関連付ける必要があります。詳細については、「リソースクォータの作成」をご参照ください。
ステップ 2:ランタイムイメージの準備
トレーニングタスクをサブミットする前に、トレーニング環境用のランタイムイメージを準備する必要があります。次のいずれかのランタイムイメージタイプを選択できます:
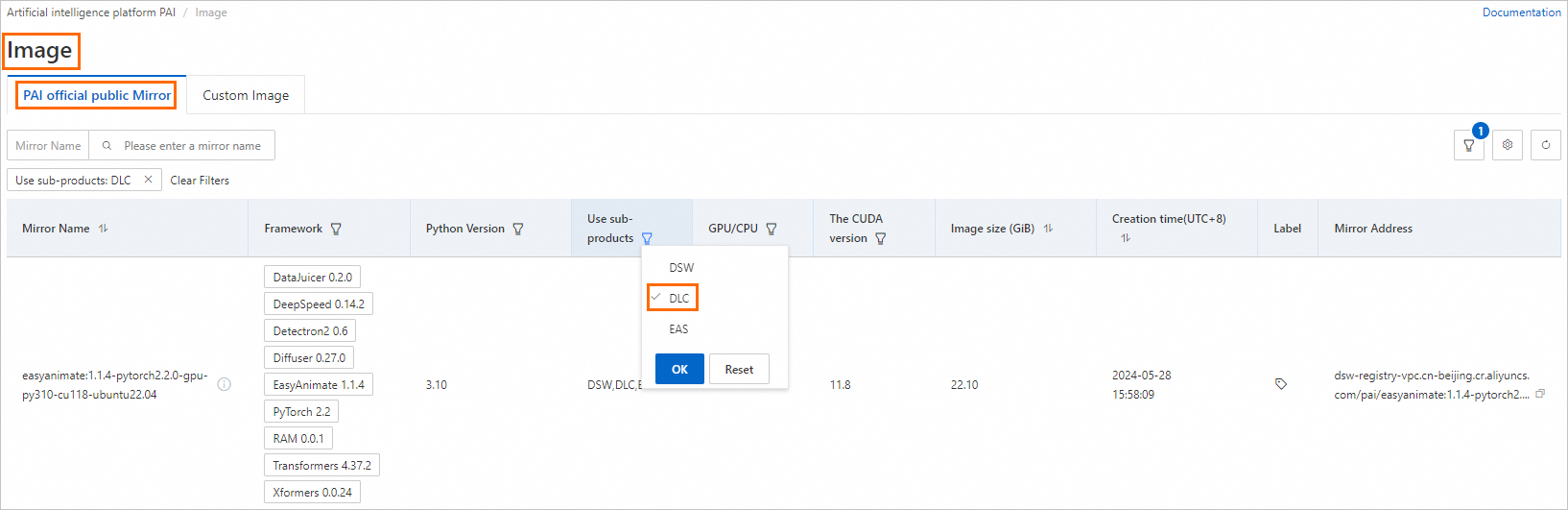
公式イメージ: PAI は、さまざまなフレームワークをベースとし、Alibaba Cloud サービス向けに最適化および統合された公式イメージを提供します。これらのイメージは互換性とパフォーマンスが向上しており、Alibaba Cloud サービスを使用するトレーニングジョブに適しています。PAI コンソールの AI アセット管理イメージページに移動します。Image: ページで、Alibaba Cloud Images タブを開き、[サブプロダクト] フィルターを DLC に設定すると、DLC ジョブの送信をサポートするイメージの詳細なリストを表示できます。
カスタムイメージ:トレーニングタスクに特別な環境や依存関係が必要な場合は、カスタムイメージを使用できます。タスクで選択する前に、イメージを PAI に追加する必要があります。管理と使用を容易にするために、ワークスペースの ページに移動して、イメージを PAI AI アセットとして追加できます。これにより、複数のトレーニングタスクがイメージを直接使用できるようになります。詳細については、「カスタムイメージ」をご参照ください。
重要Lingjun リソースを使用してカスタムイメージでトレーニングタスクをサブミットする場合は、「RDMA:分散トレーニングに高性能ネットワークを使用する」をご参照ください。
レジストリアドレス:トレーニングタスクをサブミットする際に、カスタムイメージまたは公式ランタイムイメージのレジストリアドレスを入力できます。PAI コンソールの [AI アセット管理] の [イメージ] ページに移動して、レジストリアドレスを表示できます。
ステップ 3:データセットの準備
トレーニングタスクをサブミットする前に、必要なデータを OSS、File Storage NAS、または CPFS にアップロードする必要があります。その後、トレーニングタスクで直接使用できるカスタムデータセットを作成できます。OSS やパブリックデータセットから直接データをマウントすることもできます。以下のセクションでは、カスタムデータセットの準備方法について説明します:
サポートされるデータセットタイプ
PAI は、OSS、汎用型 NAS ファイルシステム、超高速型 NAS ファイルシステム、CPFS、Lingjun CPFS の各タイプのデータセットをサポートしています。データセットアクセラレーションは、Lingjun CPFS を除くすべてのデータセットタイプでサポートされています。分散トレーニングタスクをサブミットする際に、高速化されたデータセットを使用してデータ読み取り効率を向上させることができます。
データセットの作成
操作とパラメーター設定の詳細については、「データセットの作成と管理」をご参照ください。データセットを準備する際は、次の点にご注意ください:
NAS とは異なり、OSS は真のファイルシステムではなく、分散オブジェクトストレージサービスです。そのため、OSS をストレージシステムとして使用する場合、一部のファイルシステム機能はサポートされていません。たとえば、OSS をマウントした後、既存のファイルにデータを追加したり、上書きしたりすることはできません。
CPFS データセットを作成する場合、Virtual Private Cloud (VPC) を設定し、トレーニングタスクをサブミットする際に CPFS ファイルシステムと同じ VPC を選択する必要があります。そうでない場合、サブミットされた DLC ジョブが異常終了したり、[環境準備中] の状態で長時間停止したりする可能性があります。
データセットアクセラレーションの有効化
データセットアクセラレーションを有効にすることができます。トレーニングタスクをサブミットする際に、高速化されたデータセットを使用してデータ読み取り効率を向上させることができます。詳細については、「PAI プラットフォームでデータセットアクセラレータを使用する」をご参照ください。
ステップ 4:コードビルドの準備
トレーニングタスクをサブミットする前に、タスクに使用するコードをコードビルドとして追加する必要があります。管理と使用を容易にするために、ワークスペースの ページに移動し、コードを PAI AI アセットとして追加できます。これにより、複数のトレーニングタスクがコードビルドを直接使用できるようになります。詳細については、「コード設定」をご参照ください。
参考
準備が完了したら、トレーニングタスクを作成できます。詳細については、「トレーニングタスクの作成」をご参照ください。