データを処理したり、モデルをトレーニングしたりするには、まずデータセットを準備する必要があります。AI Asset Management は、データセットを作成および管理するための強力な機能を提供します。そのバージョン管理機能により、実験を正確に再現し、データバージョンを追跡し、データリネージを記録できます。新しいバージョンで問題が発生した場合は、以前のバージョンにすばやくロールバックして、業務継続性を確保できます。
概要
AI Asset Management を使用すると、基本データセットとラベル付きデータセットを管理できます。基本データセットは通常、大量の生情報を含み、主にモデルを事前学習させて広範な特徴やパターンを捉えるために使用されます。ラベル付きデータセットには、特定のラベルが付いた人間が注釈を付けたデータが含まれており、主にモデルのファインチューニングと評価に使用され、特定のタスクにおけるモデルのパフォーマンスを向上させます。
項目 | 基本データセット | ラベル付きデータセット |
定義 | ラベル付けされていない生データ。 | 人間が注釈を付けたデータ |
データ処理 | データクリーニング、重複排除など。 | データラベリング、検証など |
利用シーン |
|
|
データセットページへの移動
PAI コンソールにログインします。
左上隅で、ワークスペースが配置されているリージョンを選択します。
左側のナビゲーションウィンドウで、[Workspaces] を選択します。開きたいワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、[AI Asset Management] > [Datasets] を選択します。
基本データセットの作成
[カスタムデータセット] タブで [データセットの作成] をクリックし、[データの型] で [基本] を選択します。Object Storage Service (OSS) またはファイルストレージ (汎用 NAS、Extreme NAS、CPFS、AI-CPFS) からデータセットを作成できます。
ストレージタイプは Object Storage Service (OSS) です
パラメーター | 説明 |
コンテンツタイプ | イメージ、テキスト、オーディオ、ビデオ、テーブル、一般など、データの型を選択します。型を指定すると、将来のラベリングタスクのためにシステムがデータセットをフィルターできます。 |
所有者 | データセットのオーナーを選択します。このパラメーターはワークスペース管理者のみが設定できます。 |
インポートフォーマット/OSS パス | |
デフォルトマウントパス | データをマウントするためのデフォルトパスです。これは DSW と DLC でよく使用されます:
|
バージョンの高速化を有効にする | [インポート形式] を [フォルダ] に設定した場合、データセットバージョンアクセラレーションを有効にできます。主な設定は次のとおりです:
|
ストレージタイプがファイルシステムの場合
パラメーター | 説明 |
コンテンツタイプ | イメージ、テキスト、オーディオ、ビデオ、テーブル、一般など、データの型を選択します。型を指定すると、将来のラベリングタスクのためにシステムがデータセットをフィルターできます。 |
所有者 | データセットのオーナーを選択します。このパラメーターはワークスペース管理者のみが設定できます。 |
ファイルシステム | [ストレージタイプ] に対応するファイルシステムを選択します。 |
マウントターゲット | ファイルシステムにアクセスするためのマウントポイントを設定します。 |
ファイルシステムパス | ファイルシステム内のデータへのパスを指定します。例: |
[デフォルトマウントパス] | データをマウントするためのデフォルトパスです。これは DSW と DLC でよく使用されます:
|
バージョン高速化の有効化 | [ストレージタイプ] が汎用 NAS、Extreme NAS、または CPFS の場合、データセットバージョンアクセラレーションを有効にできます。主なパラメーターは次のとおりです:
|
基本データセットバージョンの作成
[カスタムデータセット] タブで、対象のデータセットの [操作] 列にある [バージョンの作成] をクリックします。

注:
データセット名、ストレージタイプ、データの型は V1 バージョンから継承され、変更できません。
システムはデータセットバージョンを自動的に生成し、これは読み取り専用です。
その他のパラメーター設定については、「基本データセットの作成」セクションの説明をご参照ください。
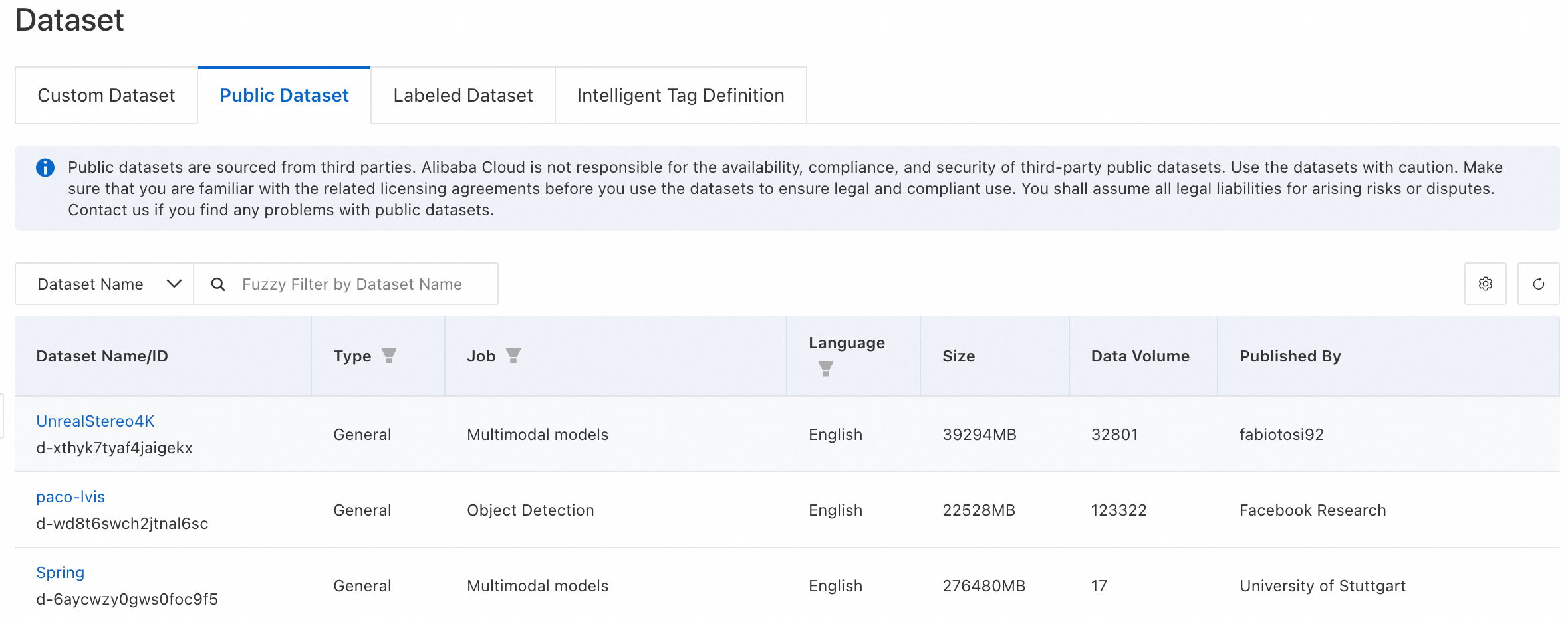
公開データセットの表示
システムは、MMLU、CMMLU、GSM8K など、さまざまな組み込みの公開データセットを提供します。[公開データセット] タブで、データセット名をクリックしてその基本情報を表示できます。
データセットの管理
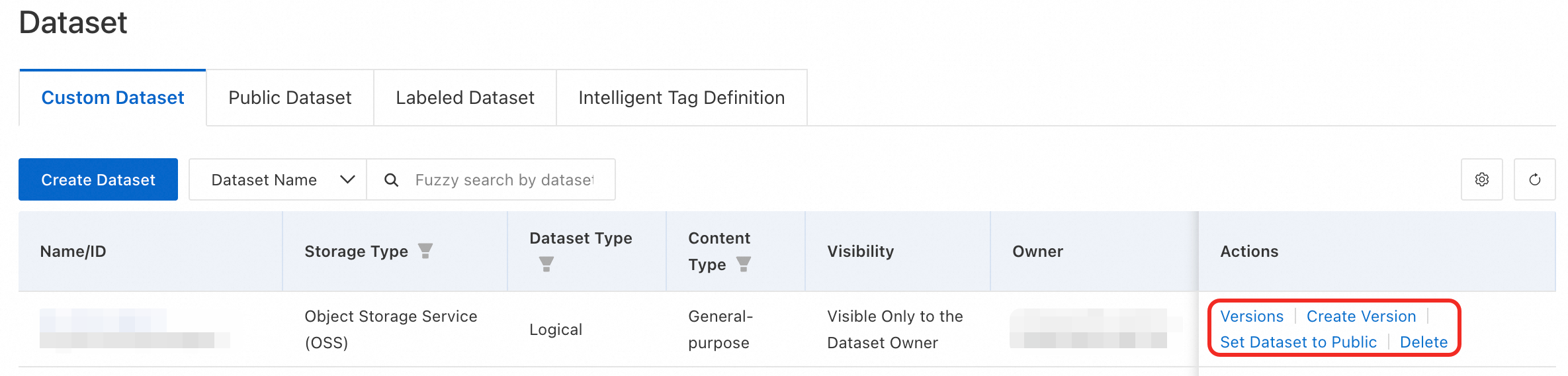
カスタムデータセットの場合、バージョンの一覧の表示、新しいバージョンの作成、データセットの公開、または削除ができます。ラベル付きデータセットの場合、データの表示、公開、または削除ができます。
注:
[可視性] が [データセットのオーナーにのみ表示] に設定されているデータセットの場合、[データセットを公開] をクリックしてワークスペース内でデータセットを共有できます。これにより、すべてのワークスペースメンバーがデータセットを表示できるようになります。一度公開すると、データセットを非公開に戻すことはできません。操作は慎重に行ってください。
RAM ユーザーがデータセットのデータを表示しようとしてアクセス拒否エラーを受け取った場合は、RAM ユーザーに権限を付与する必要があります。
データセットを削除すると、それに依存する実行中のタスクに影響を与える可能性があります。重要:データセットの削除は元に戻せません。操作は慎重に行ってください。