オンラインナレッジベースの Q&A シナリオ向けに、AI Search Open Platform は完全な RAG 開発パイプラインを提供します。このパイプラインには、データ前処理、検索サービス、Q&A 要約生成の 3 つの主要モジュールが含まれます。AI Search Open Platform では、各モジュールで利用可能なアルゴリズムサービスがコンポーネント化されています。ドキュメント解析、ソート、Q&A 要約などのサービスを各モジュールごとに柔軟に選択することで、開発コードを迅速に生成できます。AI Search Open Platform はこれらのサービスを API として公開しています。開発者はコードをローカル環境にダウンロードし、本トピックの手順に従って API キー、API エンドポイント、ローカルナレッジベースなどの情報を置き換えます。これにより、RAG 開発パイプラインに基づくナレッジベース Q&A アプリケーションを迅速に構築できます。
技術原理
検索拡張生成(Retrieval-Augmented Generation:RAG)は、検索技術と生成技術を統合した人工知能手法です。モデルが生成するコンテンツの関連性、精度、多様性を向上させることを目的としています。生成タスクを処理する際、RAG はまず大量の外部データまたはナレッジベースから入力に対して最も関連性の高いセグメントを検索します。その後、検索された情報と元の入力を、大規模言語モデル(LLM)へのプロンプトまたはコンテキストとして与えます。これにより、モデルはより正確で豊かな回答を生成できるようになります。この手法では、モデルが応答を生成する際に内部パラメーターおよび学習データのみに依存するのではなく、外部の最新情報やドメイン固有の情報を活用して回答精度を高めることができます。
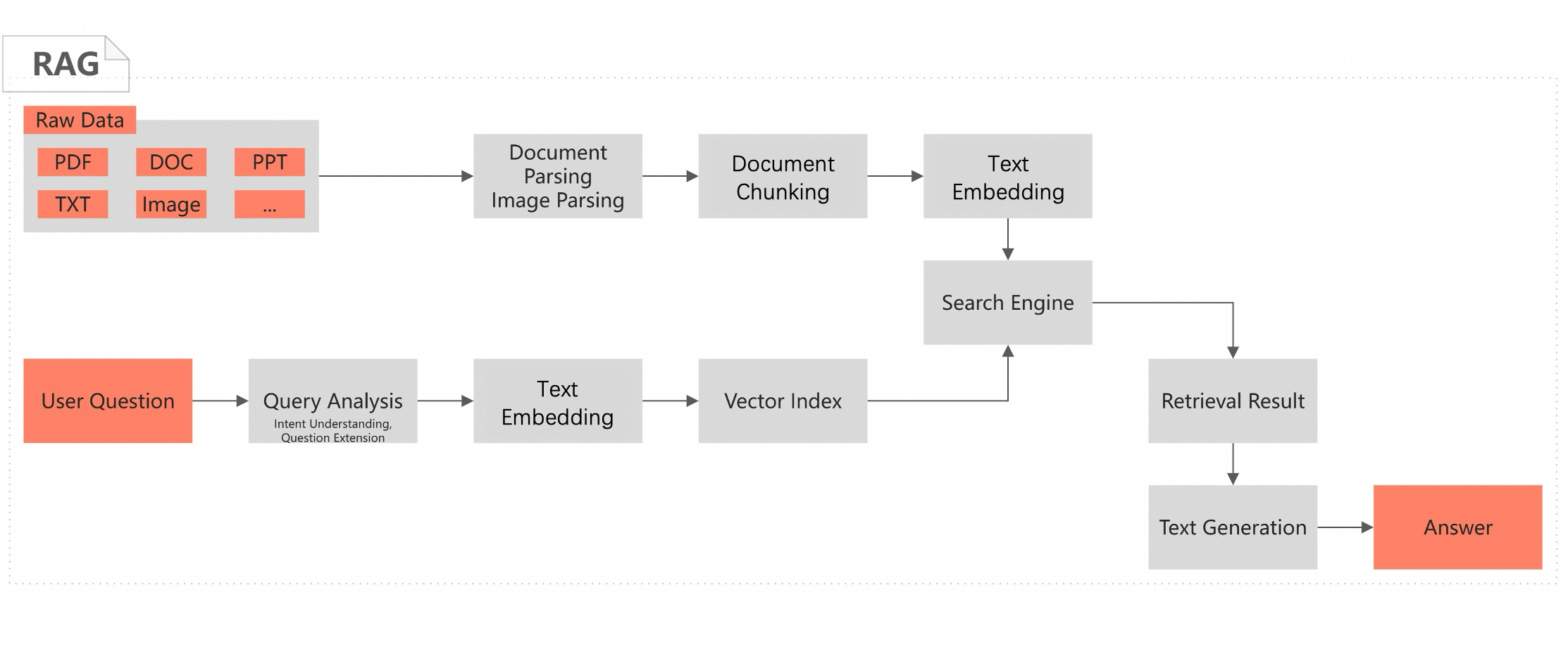
シナリオ
ナレッジベースのオンライン Q&A は、企業内ナレッジベースの検索・要約、および特定ドメインにおけるオンライン Q&A などのビジネスシナリオでよく使用されます。顧客が保有する専門的なナレッジベース文書を活用し、検索拡張生成(RAG)技術および大規模言語モデル(LLM)を用いることで、複雑な自然言語クエリを理解・応答できます。これにより、企業のお客様は PDF、Word、表、画像などのドキュメントから、自然言語を用いて素早く情報を検索できます。
前提条件
-
AI Search Open Platform の有効化を行います。詳細については、「サービスの有効化」をご参照ください。
-
サービスエンドポイントおよび認証情報を取得します。詳細については、「サービスエンドポイントの取得」および「API キーの取得」をご参照ください。
AI Search Open Platform は、パブリックネットワークおよび VPC エンドポイントによるサービス呼び出しをサポートしています。VPC を使用すると、クロスリージョンでのサービス呼び出しが可能です。現在、中国 (上海)、中国 (杭州)、中国 (深セン)、中国 (北京)、中国 (張家口)、および中国 (青島) リージョンのユーザーは、VPC エンドポイントを介して AI Search Open Platform のサービスを呼び出すことができます。

-
Alibaba Cloud Elasticsearch(ES)インスタンスを作成します。ES 8.5 以降が必要です。詳細については、「Alibaba Cloud Elasticsearch インスタンスの作成」をご参照ください。パブリックネットワークまたはプライベートネットワーク経由で Alibaba Cloud ES インスタンスにアクセスする場合、アクセス先デバイスの IP アドレスをインスタンスの IP ホワイトリストに追加してください。詳細については、「インスタンスのパブリック/プライベートネットワークアクセスホワイトリストの設定」をご参照ください。
-
Python 3.7 以降を使用します。開発環境で、Python パッケージ依存関係 `aiohttp 3.8.6` および `elasticsearch 8.14` をインストールします。
RAG 開発パイプラインの構築
使いやすさを考慮し、AI Search Open Platform では以下の 4 種類の開発フレームワークを提供しています。
-
Java SDK
-
Python SDK
-
既に LangChain 開発フレームワークを使用している場合は、LangChain を選択します。
-
既に LlamaIndex 開発フレームワークを使用している場合は、LlamaIndex を選択します。
ステップ 1:サービスの選択とコードのダウンロード
ご利用のナレッジベースおよびビジネス要件に基づき、RAG パイプラインで必要なアルゴリズムサービスおよび開発フレームワークを選択します。本トピックでは、Python SDK 開発フレームワークを例として、RAG パイプラインの構築方法を説明します。
-
AI Search Open Platform コンソール にログインします。
-
左側のナビゲーションウィンドウで、リージョンを中国 (上海) に選択し、AI Search Open Platform に切り替え、対象のワークスペースに移動します。
説明-
現在、AI Search Open Platform は中国 (上海) およびドイツ (フランクフルト) リージョンでのみご利用いただけます。
-
中国 (杭州)、中国 (深セン)、中国 (北京)、中国 (張家口)、および中国 (青島) リージョンのユーザーは、VPC エンドポイントを用いてクロスリージョンで AI Search Open Platform のサービスを呼び出すことができます。
-
-
左側のナビゲーションウィンドウで シナリオセンター を選択し、RAG シナリオ - ナレッジベースのオンライン Q&A の右側にある 開始 をクリックします。
-
サービス情報およびビジネス要件に基づき、ドロップダウンリストから必要なサービスを選択します。サービスの詳細 ページには、該当サービスの詳細情報が表示されます。
説明-
RAG パイプライン内のアルゴリズムサービスを API 経由で呼び出す場合、サービス ID(service_id)を指定する必要があります。たとえば、ドキュメント内容解析サービスの ID は `ops-document-analyze-001` です。
-
サービス一覧からサービスを切り替えると、生成されるコード内の `service_id` が自動的に更新されます。コードをローカル環境にダウンロードした後でも、`service_id` を変更して対応するサービスを呼び出すことができます。
フェーズ
サービス概要
ドキュメント内容解析
ドキュメント分析サービス(ops-document-analyze-001):汎用的なドキュメント解析サービスを提供します。非構造化ドキュメント(テキスト、表、画像など)から見出しや段落といった論理的階層構造を抽出し、構造化された形式で出力します。
画像内容解析
-
画像内容理解サービス(ops-image-analyze-vlm-001):マルチモーダル大規模言語モデルを活用して画像内容を解析・理解し、画像内のテキストを認識します。認識されたテキストは、画像検索 Q&A シナリオで使用できます。
-
画像文字認識サービス(ops-image-analyze-ocr-001):OCR 機能を用いた画像内の文字認識を行います。認識されたテキストは、画像検索 Q&A シナリオで使用できます。
ドキュメント分割
ドキュメント分割サービス(ops-document-split-001):汎用的なテキスト分割サービスを提供します。HTML、Markdown、TXT 形式の構造化データを、ドキュメントの段落、テキストのセマンティクス、および指定されたルールに基づいて分割します。また、ドキュメントからコード、画像、表をリッチテキストとして抽出することも可能です。
テキスト埋め込み
-
OpenSearch テキスト埋め込みサービス-001(ops-text-embedding-001):40 言語以上に対応したテキスト埋め込みサービスを提供します。最大入力テキスト長は 300 文字、出力ベクトル次元数は 1536 です。
-
OpenSearch 一般テキスト埋め込みサービス-002(ops-text-embedding-002):100 言語以上に対応したテキスト埋め込みサービスを提供します。最大入力テキスト長は 8192 文字、出力ベクトル次元数は 1024 です。
-
OpenSearch テキスト埋め込みサービス-中国語-001(ops-text-embedding-zh-001):中国語テキスト埋め込みサービスを提供します。最大入力テキスト長は 1024 文字、出力ベクトル次元数は 768 です。
-
OpenSearch テキスト埋め込みサービス-英語-001(ops-text-embedding-en-001):英語テキスト埋め込みサービスを提供します。最大入力テキスト長は 512 文字、出力ベクトル次元数は 768 です。
テキスト疎埋め込み
テキストデータを疎ベクトル表現に変換するサービスを提供します。疎ベクトルはストレージ容量が少なく、キーワードや語彙頻度情報を表現するのに適しています。密ベクトルと組み合わせてハイブリッド検索を行うことで、検索効果を向上させられます。
OpenSearch テキスト疎埋め込みサービス(ops-text-sparse-embedding-001):100 言語以上に対応したテキスト埋め込みサービスを提供します。最大入力テキスト長は 8192 文字です。
クエリ分析
クエリ分析サービス 001(ops-query-analyze-001):汎用的なクエリ分析サービスを提供します。大規模言語モデルを用いてユーザークエリの意図を理解し、類似質問を展開します。
検索エンジン
-
Alibaba Cloud Elasticsearch:オープンソースの Elasticsearch を基盤とするフルマネージドクラウドサービスです。オープンソース機能と 100% 互換であり、すぐに使える状態で提供され、従量課金方式で利用できます。
説明検索エンジンサービスとして Alibaba Cloud Elasticsearch を選択する場合、互換性の問題によりテキスト疎埋め込みサービスは利用できません。代わりにテキスト埋め込み関連サービスをご利用ください。
-
OpenSearch Vector Search Edition:Alibaba が独自に開発した大規模分散型ベクトル検索エンジンです。さまざまなベクトル検索アルゴリズムをサポートし、高精度かつ優れたパフォーマンスを実現します。また、コスト効率の良い大規模インデックス構築および検索が可能です。さらに、インデックスは水平スケーリングおよびマージ、ストリームベースのインデックス構築、リアルタイムインデックスおよびクエリ、動的データ更新をサポートします。
説明OpenSearch Vector Search Edition エンジンソリューションを利用するには、RAG パイプライン内のエンジン構成およびコードを置き換えてください。
ソートサービス
BGE Rerank モデル(ops-bge-reranker-larger):汎用的なドキュメントスコアリングサービスです。クエリに対する関連性に基づいてドキュメントをスコア順(高→低)に並べ替え、スコアリング結果を出力します。
大規模言語モデル
-
OpenSearch-Qwen-Turbo(ops-qwen-turbo):Qwen-Turbo 大規模言語モデルをベースとし、教師ありモデルファインチューニングを実施して検索拡張性能を向上させ、有害性を低減しています。
-
Qwen-Turbo(qwen-turbo):中国語および英語を含む多言語入力に対応した Qwen 超大規模言語モデルです。詳細については、「Qwen 大規模言語モデルの概要」をご参照ください。
-
Qwen-Plus(qwen-plus):中国語および英語を含む多言語入力に対応した Qwen 超大規模言語モデルの強化版です。詳細については、「Qwen 大規模言語モデルの概要」をご参照ください。
-
Qwen-Max(qwen-max):中国語および英語を含む多言語入力に対応した Qwen 百億パラメーター超大規模言語モデルです。詳細については、「Qwen 大規模言語モデルの概要」をご参照ください。
-
-
構成完了、コードの表示 をクリックして、コードを表示およびダウンロードします。
コードは、オフラインドキュメント処理とオンラインユーザー Q&A 処理の 2 つの部分に分かれています。この分割は、RAG パイプラインを呼び出すアプリケーションのランタイムフローに準拠しています。
プロセス
機能
説明
オフラインドキュメント処理
ドキュメント処理(ドキュメント解析、画像抽出、分割、埋め込み)を行い、処理結果を ES インデックスに書き込みます。
メイン関数 `document_pipeline_execute` を使用して以下の処理を完了します。処理対象のドキュメントは、ドキュメント URL または Base64 エンコーディングで入力できます。
-
ドキュメント解析。サービス呼び出しについては、「ドキュメント解析 API」をご参照ください。
-
非同期ドキュメント解析 API を呼び出して、ドキュメント URL からドキュメント内容を抽出するか、Base64 エンコードされたファイルをデコードします。
-
`create_async_extraction_task` 関数を用いて解析タスクを作成し、`poll_task_result` 関数でタスク完了状態をポーリングします。
-
-
画像抽出。サービス呼び出しについては、「画像内容抽出 API」をご参照ください。
-
非同期画像解析 API を呼び出して、画像 URL から画像内容を抽出するか、Base64 エンコードされたファイルをデコードします。
-
`create_image_analyze_task` 関数を用いて画像解析タスクを作成し、`get_image_analyze_task_status` 関数で画像解析タスクの状態を取得します。
-
-
ドキュメント分割。サービス呼び出しについては、「ドキュメント分割 API」をご参照ください。
-
ドキュメント分割 API を呼び出して、指定された戦略に従って解析済みドキュメントを分割します。
-
`document_split` 関数を用いてドキュメント分割を実行します。この関数はドキュメント分割およびリッチテキスト内容解析を含みます。
-
-
テキスト埋め込み。サービス呼び出しについては、「テキスト埋め込み API」をご参照ください。
-
テキスト密ベクトル表現 API を呼び出して、分割済みテキストを埋め込みます。
-
`text_embedding` 関数を用いて、各セグメントの埋め込みベクトルを計算します。
-
-
ES への書き込み。サービス呼び出しについては、「Elasticsearch の kNN 機能を用いたベクトル近傍検索」をご参照ください。
-
ES インデックス構成を作成します。ベクトルフィールド `embedding` およびドキュメント内容フィールド `content` を指定します。
重要ES インデックスを作成する際、同名の既存インデックスは削除されます。誤って同名のインデックスを削除しないよう、コード内のインデックス名を変更してください。
-
`helpers.async_bulk` 関数を用いて、埋め込み結果を ES インデックスにバッチ書き込みします。
-
オンライン Q&A 処理
ユーザーのオンラインクエリを処理します。クエリベクトルの生成、クエリ分析、関連ドキュメントセグメントの取得、検索結果のソート、検索結果に基づく回答生成を含みます。
メイン関数 `query_pipeline_execute` を使用して以下の処理を完了します。この処理はユーザークエリを受信し、回答を出力します。
-
クエリ埋め込み。サービス呼び出しについては、「テキスト埋め込み API」をご参照ください。
-
テキスト密ベクトル表現 API を呼び出して、ユーザークエリをベクトルに変換します。
-
`text_embedding` 関数を用いてクエリベクトルを生成します。
-
-
クエリ分析サービスの呼び出し。詳細については、「クエリ分析 API」をご参照ください。
クエリ分析 API を呼び出して、ユーザークエリの意図を特定し、過去のメッセージ履歴を分析して類似質問を生成します。
-
埋め込みセグメントの検索。サービス呼び出しについては、「Elasticsearch の kNN 機能を用いたベクトル近傍検索」をご参照ください。
-
ES を用いて、クエリベクトルと類似するインデックス内のドキュメントセグメントを検索します。
-
kNN クエリと併用した `AsyncElasticsearch` 検索 API を用いて類似性検索を実行します。
-
-
ソートサービスの呼び出し。詳細については、「ソート API」をご参照ください。
-
ソートサービス API を呼び出して、取得した関連セグメントのスコア付けおよびソートを行います。
-
`documents_ranking` 関数を用いて、ユーザークエリに基づいてドキュメント内容のスコア付けおよびソートを行います。
-
-
大規模言語モデルを呼び出して回答を生成します。サービス呼び出しについては、「回答生成 API」をご参照ください。
`llm_call` 関数を用いて、大規模言語モデルサービスを呼び出し、検索結果およびユーザークエリを基に最終的な回答を生成します。
ドキュメント処理フロー および オンライン Q&A フロー を コードの照会 下で選択し、コードのコピー または ファイルのダウンロード をクリックして、コードをローカルマシンにダウンロードします。
-
ステップ 2:ローカル環境への適合および RAG 開発パイプラインのテスト
コードを `online.py` および `offline.py` のような 2 つのローカルファイルにダウンロードした後、コード内の主要パラメーターを設定します。
|
カテゴリ |
パラメーター |
説明 |
|
AI Search Open Platform |
api_key |
API キーです。詳細については、「API キーの管理」をご参照ください。 |
|
aisearch_endpoint |
API エンドポイントです。詳細については、「サービスエンドポイントの取得」をご参照ください。 説明
「http://」を削除してください。 パブリックネットワークおよび VPC を通じた API 呼び出しが可能です。 |
|
|
workspace_name |
AISearch オープンプラットフォーム |
|
|
service_id |
サービス ID です。利便性のため、オフラインドキュメント処理(`offline.py`)およびオンライン Q&A 処理(`online.py`)のコード内で、`service_id_config` を用いてサービスおよびその ID を設定します。
|
|
|
ES 検索エンジン |
es_host |
Elasticsearch(ES)インスタンスのエンドポイントです。パブリックネットワークまたはプライベートネットワーク経由で Alibaba Cloud ES インスタンスにアクセスする場合、アクセス対象デバイスの IP アドレスをインスタンスのアクセスホワイトリストに追加してください。詳細については、「インスタンスのパブリック/プライベートネットワークアクセスホワイトリストの設定」をご参照ください。 |
|
es_auth |
Elasticsearch インスタンスへのアクセスに使用するユーザー名およびパスワードです。ユーザー名は `elastic` で、パスワードはインスタンス作成時に設定したものです。パスワードを忘れた場合は、再設定してください。具体的な操作については、「インスタンスアクセスパスワードの再設定」をご参照ください。 |
|
|
その他のパラメーター |
サンプルデータを使用する場合は、変更の必要はありません。 |
|

パラメーターの設定が完了したら、Python 3.7 以降の環境で、まず `offline.py`(オフラインドキュメント処理)ファイルを実行し、次に `online.py`(オンライン Q&A 処理)ファイルを実行して、結果が正しいかどうかをテストします。
たとえば、ナレッジベースドキュメントが「AI Search Open Platform の概要」である場合、ドキュメントに対して「AI Search Open Platform はどのようなことができますか?」と質問します。
実行結果は以下のとおりです。
-
オフラインドキュメント処理の結果
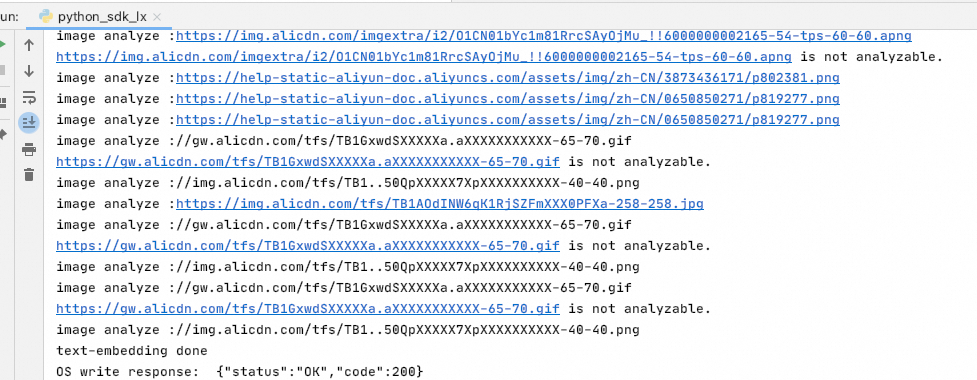
-
オンライン Q&A 処理の結果

-
ソースファイルの表示
よくある質問
コード実行中に、「Unclosed connector」警告が表示される場合があります。これはリソースが適切に解放されていないためですが、特に対応する必要はありません。