このトピックでは、ビジネス要件を満たすために、E コマースシナリオの商品検索用のシンプルなプロトタイプを OpenSearch を使用して構築する方法について説明します。E コマースプラットフォームを構築する場合、重要なビジネス要件は、キーワードを使用してさまざまな商品属性を検索し、取得した商品をカテゴリに基づいてフィルタリングすることです。OpenSearch は、プロジェクトの要件を満たすこのような商品検索プロトタイプを構築するのに役立ちます。
準備
Alibaba Cloud アカウントを作成して初めてコンソールにログインすると、続行する前に AccessKey ペアを作成するように求められます。
OpenSearch アプリケーションは AccessKey ペアに基づいて作成および使用されるため、Alibaba Cloud アカウント内で AccessKey ペアを指定する必要があります。
Alibaba Cloud アカウント内で AccessKey ペアを作成した後、RAM ユーザーの AccessKey ペアを作成して、RAM ユーザーとしてアプリケーションにアクセスできるようにすることができます。RAM ユーザーに権限を付与する方法の詳細については、アクセス認証ルールを参照してください。
アーキテクチャ
次の図は、プロトタイプ全体のシステムアーキテクチャを示しています。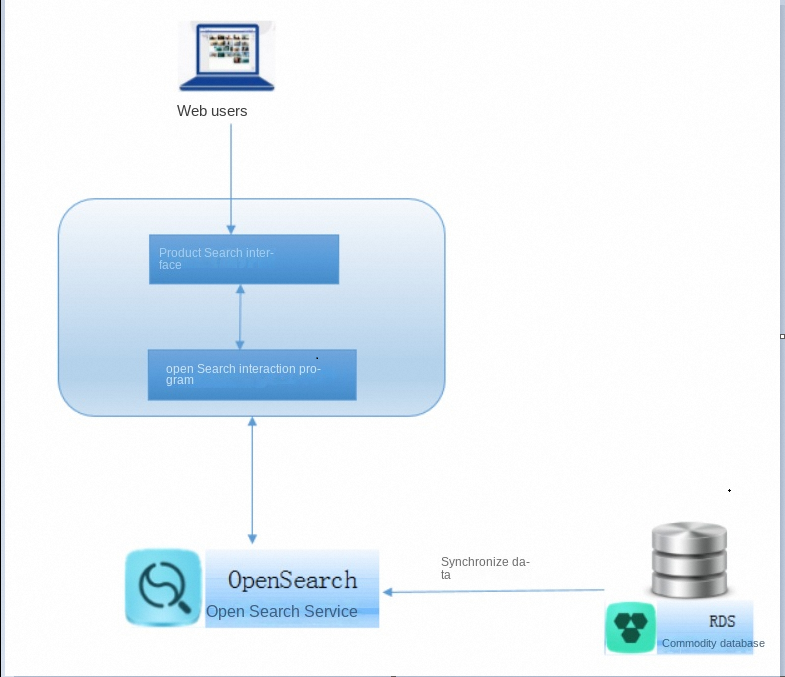
アプリケーションの作成
1. OpenSearch コンソールにログインします。左側のナビゲーションペインで、インスタンス管理をクリックします。インスタンス管理ページの左上隅にあるインスタンスの作成をクリックします。
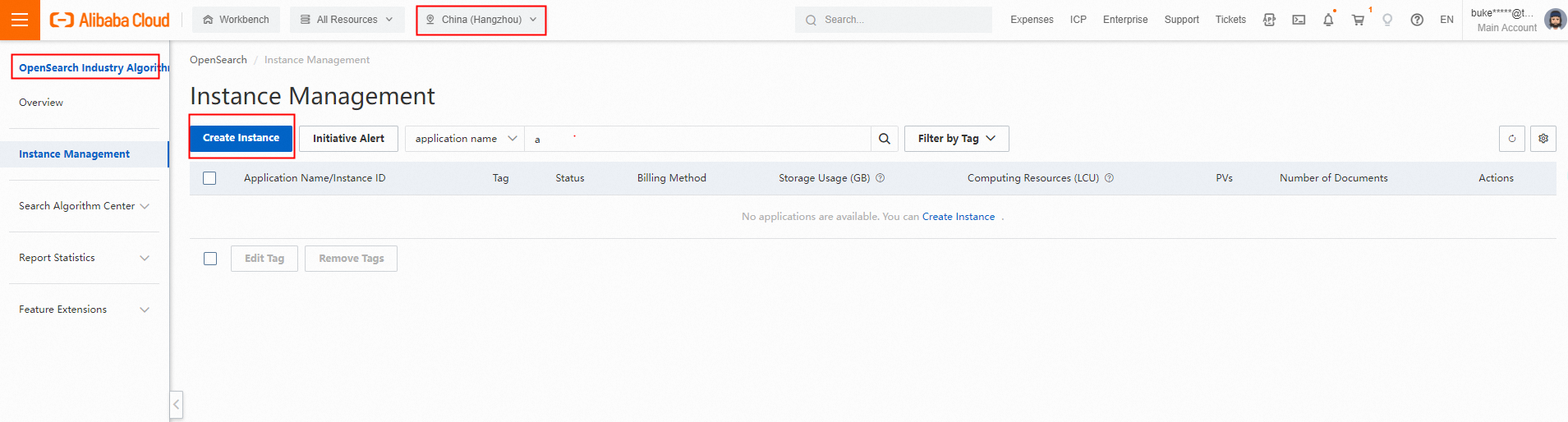
2. アプリケーションの種類を選択します。
E コマースシナリオには複数テーブルのマッピングが関係しています。したがって、複数テーブルの結合をサポートする高度なアプリケーションを選択します。アプリケーションの種類の詳細については、標準アプリケーションと高度なアプリケーションの比較を参照してください。
3. アプリケーションパラメータを設定します。
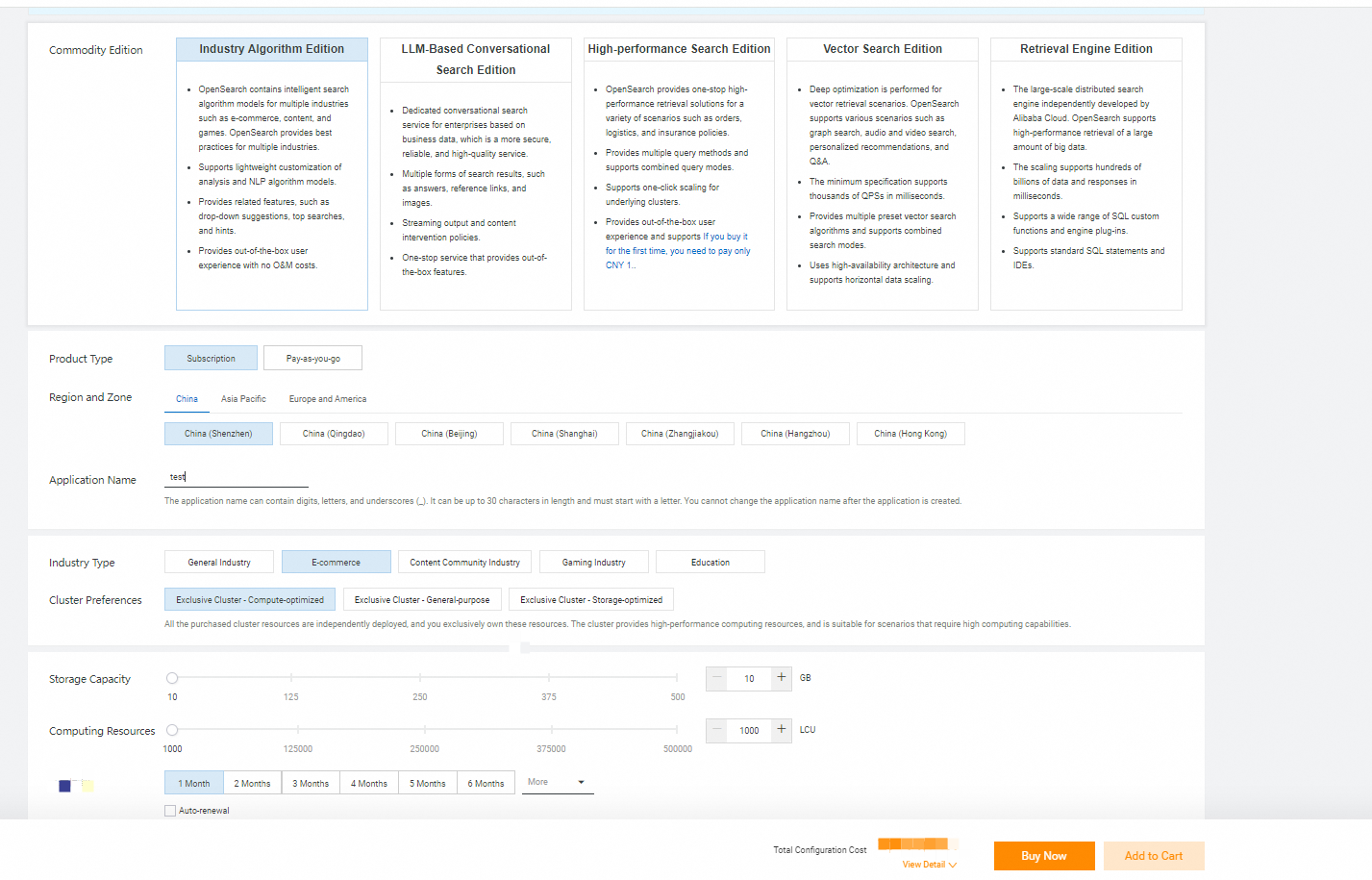
製品タイプ:OpenSearch は、サブスクリプションと従量課金制の課金方法をサポートしています。詳細については、「用語」を参照してください。リージョンとゾーン:OpenSearch は、次のリージョンとゾーンをサポートしています。
中国:中国(深圳)、中国(青島)、中国(北京)、中国(張家口)、中国(杭州)、中国(上海)、中国(香港)
アジア太平洋:シンガポール
ヨーロッパおよびアメリカ:ドイツ(フランクフルト)および米国(バージニア)
アプリケーション名:アプリケーション名には、数字、文字、アンダースコア (_) を使用できます。名前は文字で始まり、最大 30 文字まで使用できます。アプリケーションの作成後、名前を変更することはできません。アプリケーションタイプ:高度なアプリケーションまたは標準アプリケーションを選択できます。クラスタ設定:OpenSearch は、共有汎用、共有コンピューティング、共有ストレージ、専用汎用、専用コンピューティング、専用ストレージなどのタイプの仕様をサポートしています。詳細については、OpenSearch とはを参照してください。ストレージ容量とコンピューティングリソース:ニーズに基づいて、ストレージ容量とコンピューティングリソースのクォータを指定します。論理コンピューティングユニット(LCU)の数は、1 秒あたりのクエリ数(QPS)に各クエリで消費される LCU の数を掛けた値に等しくなります。共有汎用アプリケーションインスタンスを購入し、検索テストを実行して、各クエリで消費される LCU の数を確認できます。
4. アプリケーションを構成します。
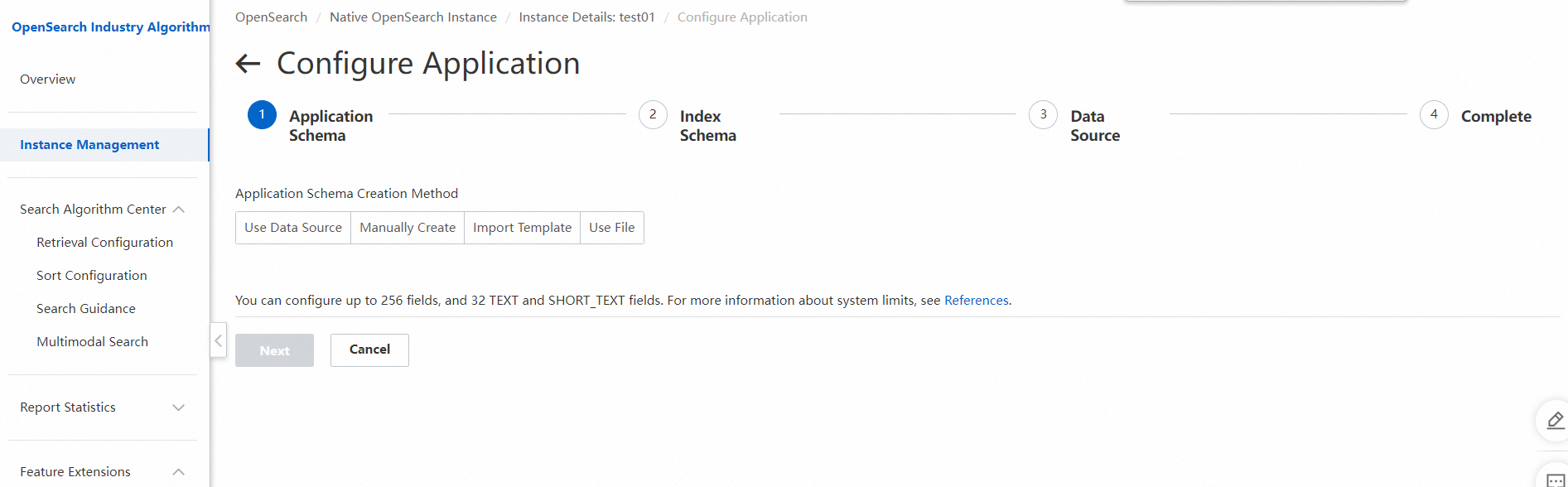
アプリケーションスキーマを手動で定義する:アプリケーションスキーマをカスタマイズしてアプリケーションを作成できます。
テンプレートを使用してアプリケーションスキーマを定義する:OpenSearch は、複数の一般的に使用されるテンプレートを提供しています。カスタムアプリケーションスキーマに基づいてテンプレートを作成し、そのテンプレートを使用して簡単にアプリケーションを作成することもできます。
ファイルをアップロードしてアプリケーションスキーマを定義する:データファイルを OpenSearch コンソールにアップロードできます。次に、OpenSearch はアップロードされたデータファイルを自動的に解決し、初期アプリケーションスキーマを生成します。データファイルは JSON 形式である必要があります。初期アプリケーションスキーマが生成された後、フィールドタイプなどの特定の属性を再定義する必要があります。
データソースを使用してアプリケーションスキーマを定義する:ApsaraDB RDS、MaxCompute、PolarDB データソースなどのデータソースからデータを同期する場合に、この方法を使用できます。ソーステーブルのスキーマを使用して、初期アプリケーションスキーマを生成できます。これにより、手動定義の作業負荷が軽減され、エラーの可能性が減少します。さまざまなデータソースへの接続手順は似ています。次の図は、ApsaraDB RDS データソースに接続する方法を示しています。詳細については、MySQL データソース用の ApsaraDB RDS の構成を参照してください。
MaxCompute、ApsaraDB RDS、PolarDB などの Alibaba Cloud ストレージサービスを使用している場合は、OpenSearch コンソールでデータソースとして指定できます。これにより、データはシンプルで便利で信頼性の高い方法で OpenSearch に自動的に同期されます。次の例は、ApsaraDB RDS データソースを使用してアプリケーションスキーマを作成する方法を示しています。
5. データソースに接続します。
次の図に示すように、データベース情報を入力します。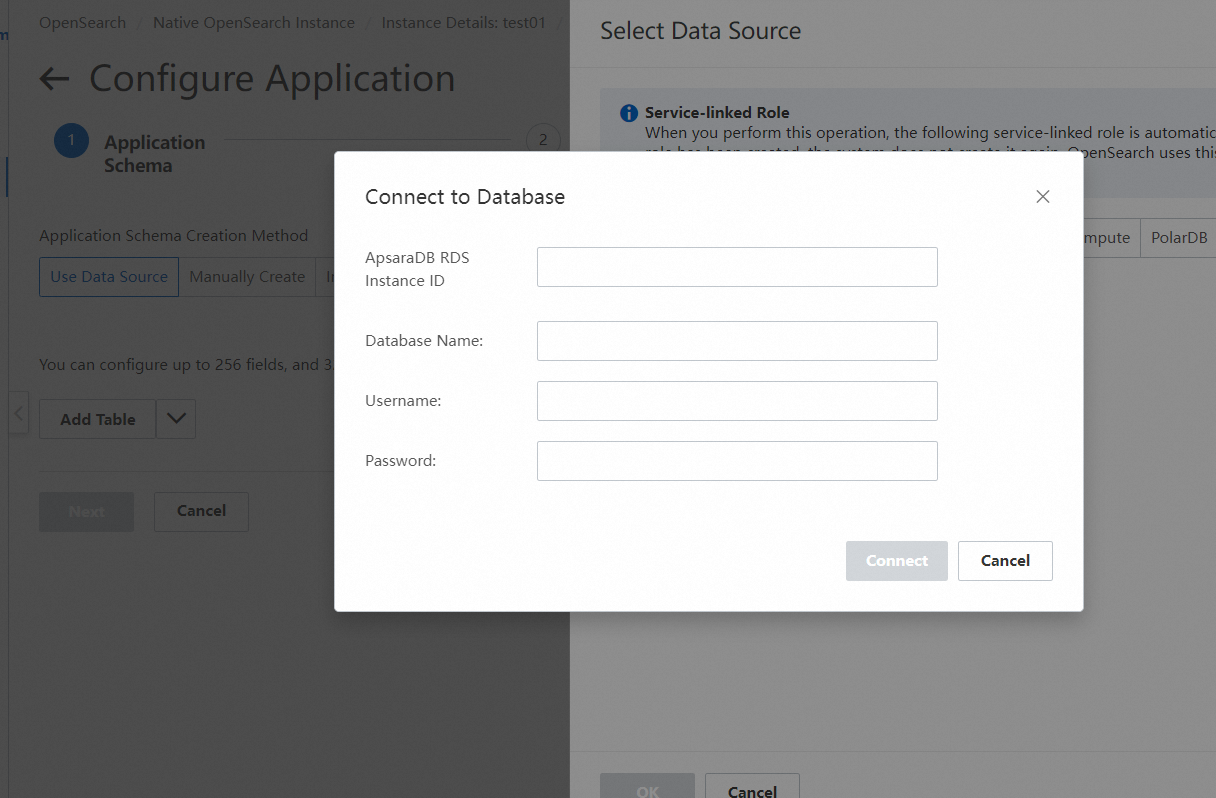
6. データソースを選択します。
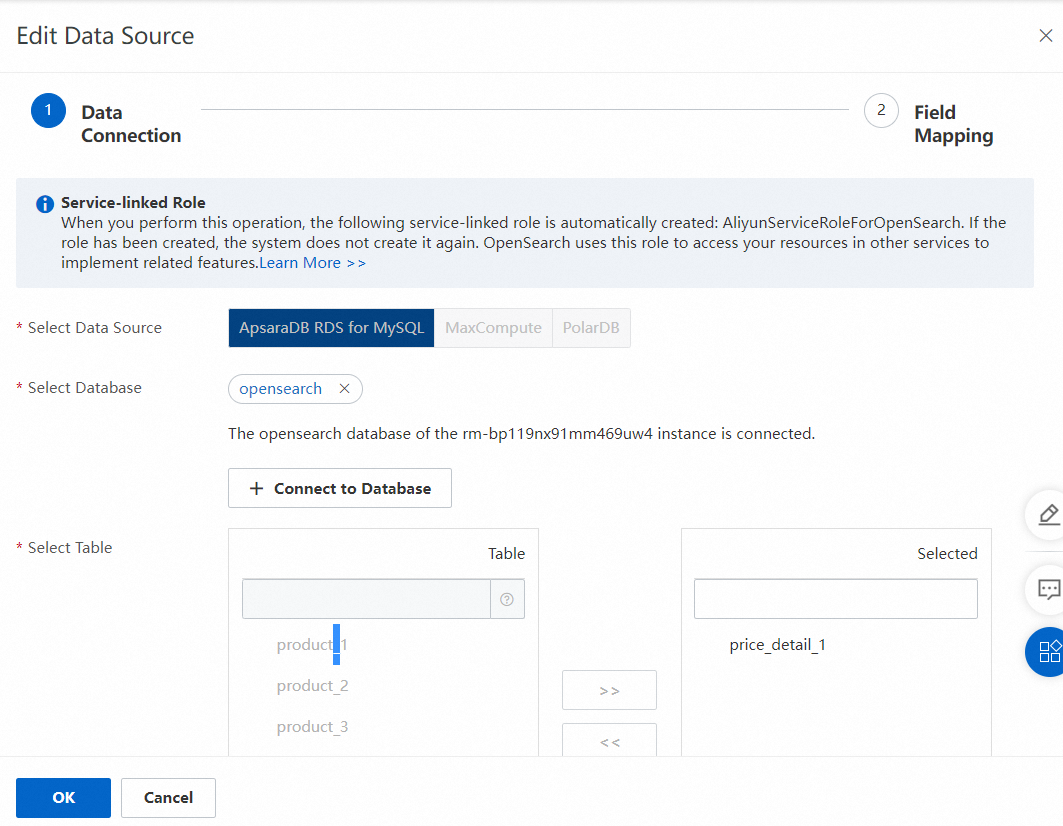
7. アプリケーションスキーマを定義します。
この例では、商品テーブルと商品価格テーブルに基づいてアプリケーションスキーマが作成されます。商品テーブルはプライマリテーブルとして使用され、商品価格テーブルはセカンダリテーブルとして使用されます。商品価格テーブルのプライマリキー ID は、商品テーブルの外部キー ID に関連付けられています。次の図は、プロトタイプのアプリケーションスキーマを作成するために使用されるプライマリテーブルとセカンダリテーブルを示しています。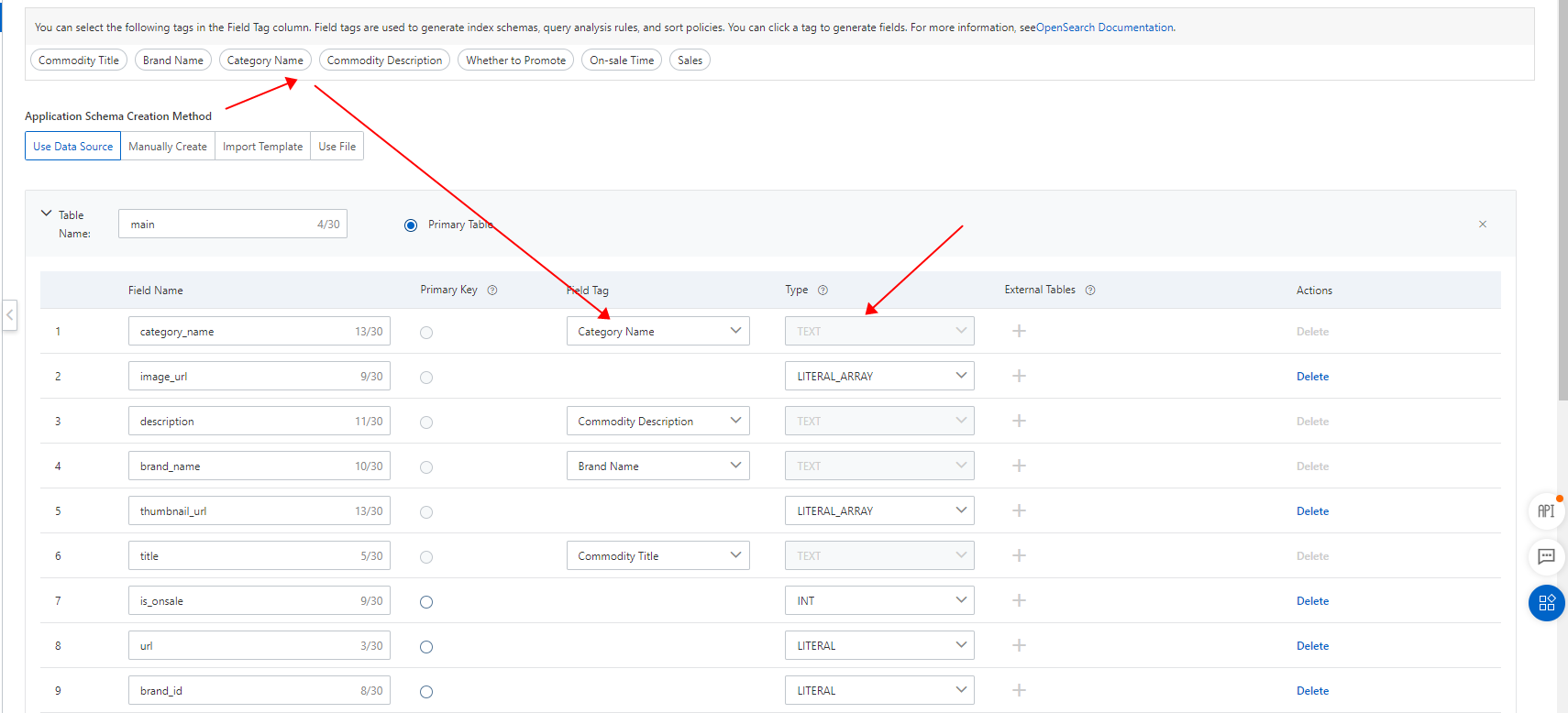
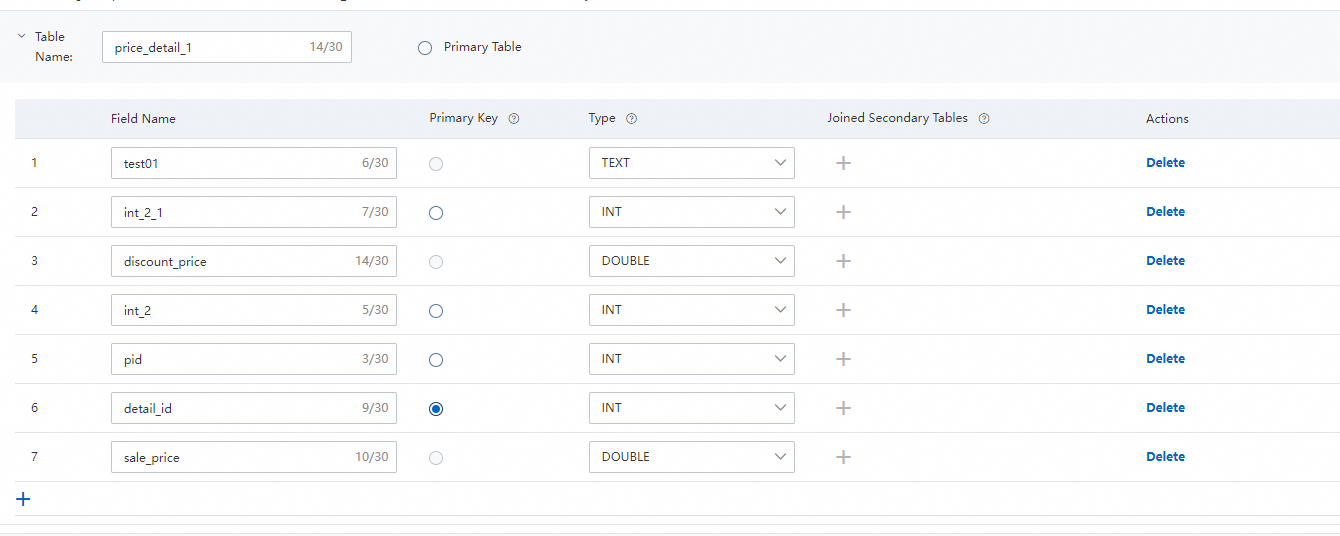 8. インデックススキーマを定義します。
8. インデックススキーマを定義します。
商品テーブルと商品価格テーブルの検索に使用されるフィールドを「default」という名前のインデックスリストに追加します。これにより、query=default:"keyword" を使用して商品を検索できます。次の図は、インデックススキーマの詳細を示しています。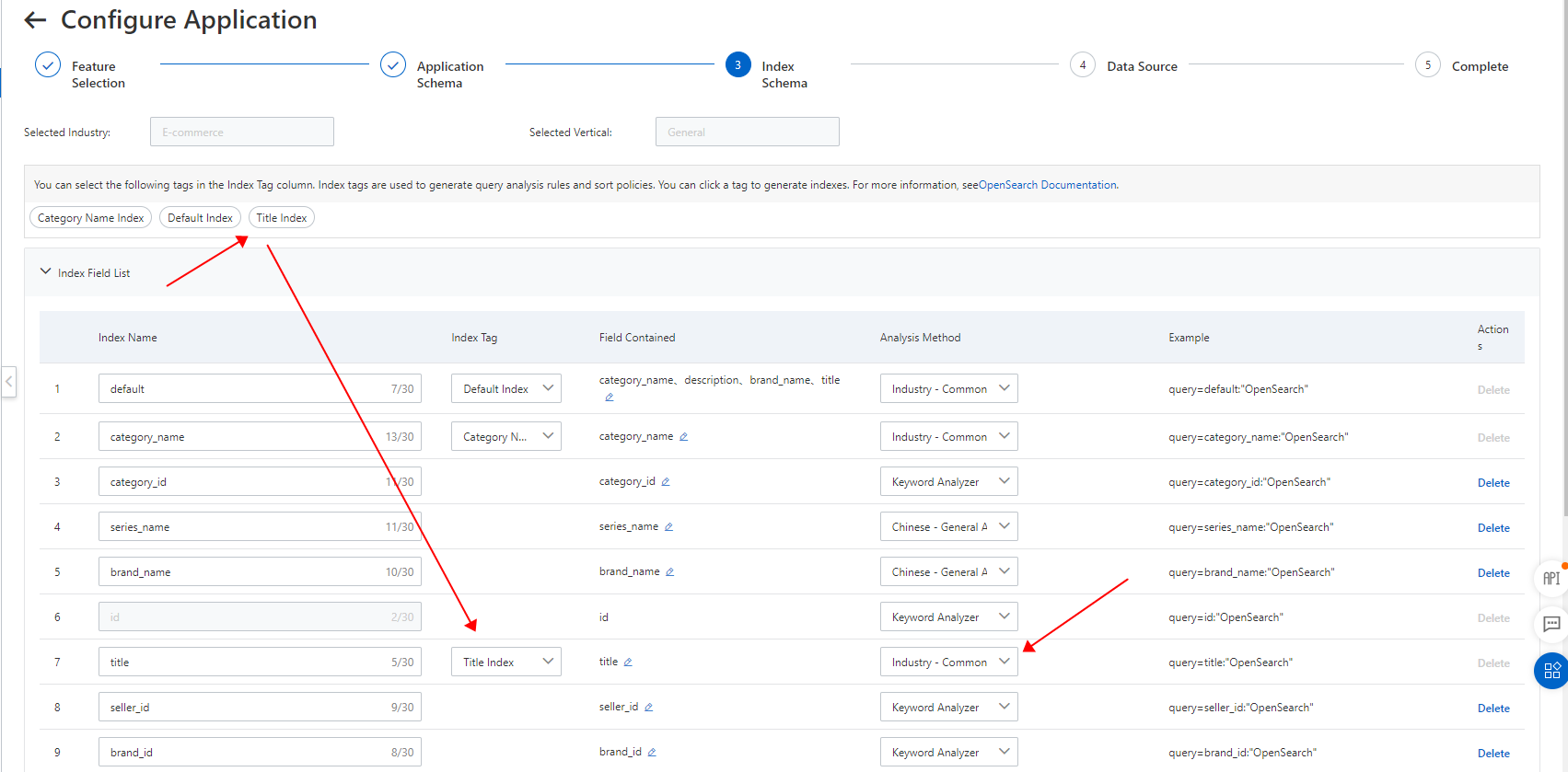
注:分析方法は検索結果に影響します。分析方法を選択する際は注意してください。詳細については、組み込みアナライザーを参照してください。
9. データソースを構成します。
この手順では、自動データ同期を有効にするかどうかを指定できます。自動データ同期を有効にすると、データソースのデータ更新は OpenSearch に自動的に同期されます。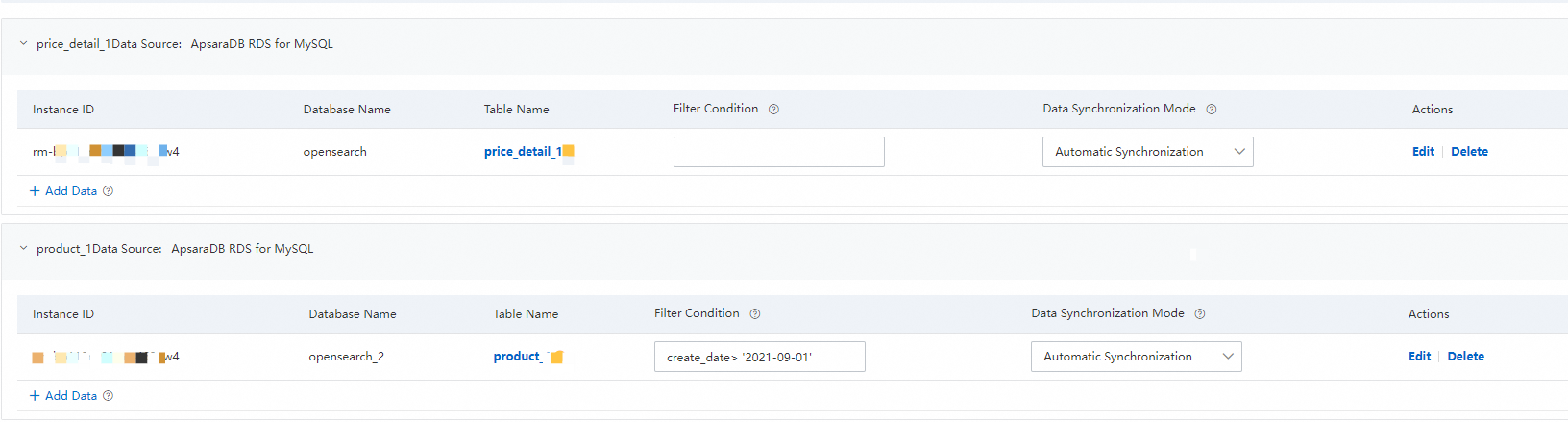
10. 構成が完了したら、完了をクリックします。アプリケーションの詳細ページで、アプリケーションが初期化されていることがわかります。
データのアップロード
前の例では、ApsaraDB RDS データソースが使用されています。この場合、インデックスが作成されると、デフォルトで完全なデータのインポートが開始されます。データのインポートの進行状況は、アプリケーションの詳細ページで確認できます。または、OpenSearch API または SDK を使用して手動でデータをアップロードすることもできます。
テスト
データがアップロードされたら、検索を開始できます。OpenSearch コンソールは、組み込みの検索サービスを提供しています。API または SDK を使用して検索を実行できます。または、検索テストページで検索を実行することもできます。詳細については、API の概要とSDK の概要を参照してください。次の図は、検索テストページで検索を実行する方法を示しています。検索構文の詳細については、検索リクエストの開始とquery 句を参照してください。次の図は、検索結果を示しています。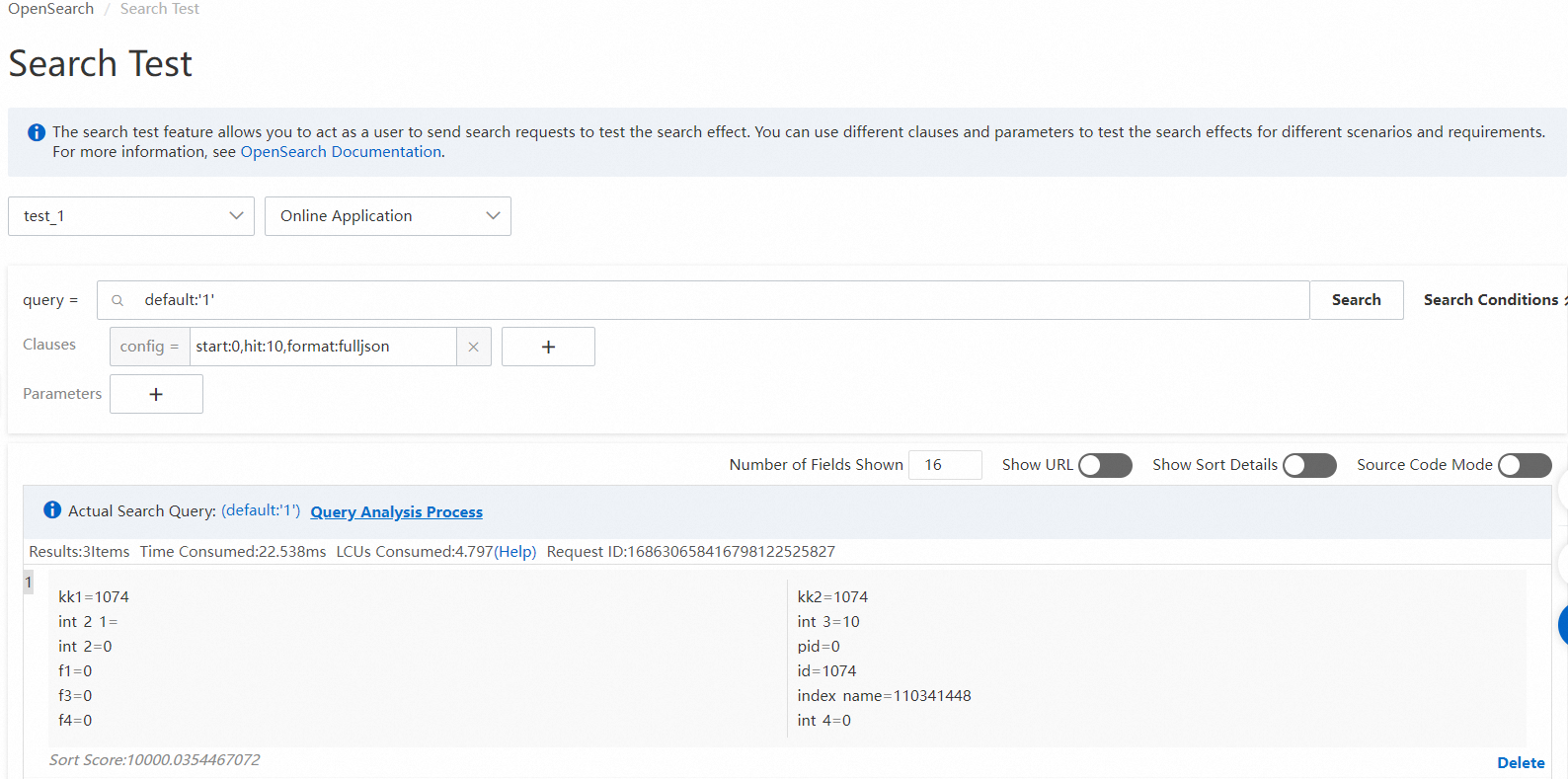
OpenSearch が提供するカスタム機能を使用して、より良い検索エクスペリエンスを得ることもできます。ロングテール検索クエリでは、検索結果が少なくなる場合があります。スペルミスや中国語ピンインを含む検索クエリでは、検索結果が得られない場合があります。このような場合は、カスタム機能を使用して問題を解決できます。詳細については、クエリ分析と関連性に基づいて検索を実行するを参照してください。
クエリ分析ルールの構成:次の例では、スペル修正機能を使用してクエリ分析ルールを構成する方法について説明します。
手順 1:クエリ分析用の介入辞書を作成します。手順 1.1:OpenSearch コンソールにログインします。左側のナビゲーションペインで、検索アルゴリズムセンター > 検索設定 を選択します。検索設定ページで、左側のペインにある辞書管理をクリックして、辞書管理ページに移動します。
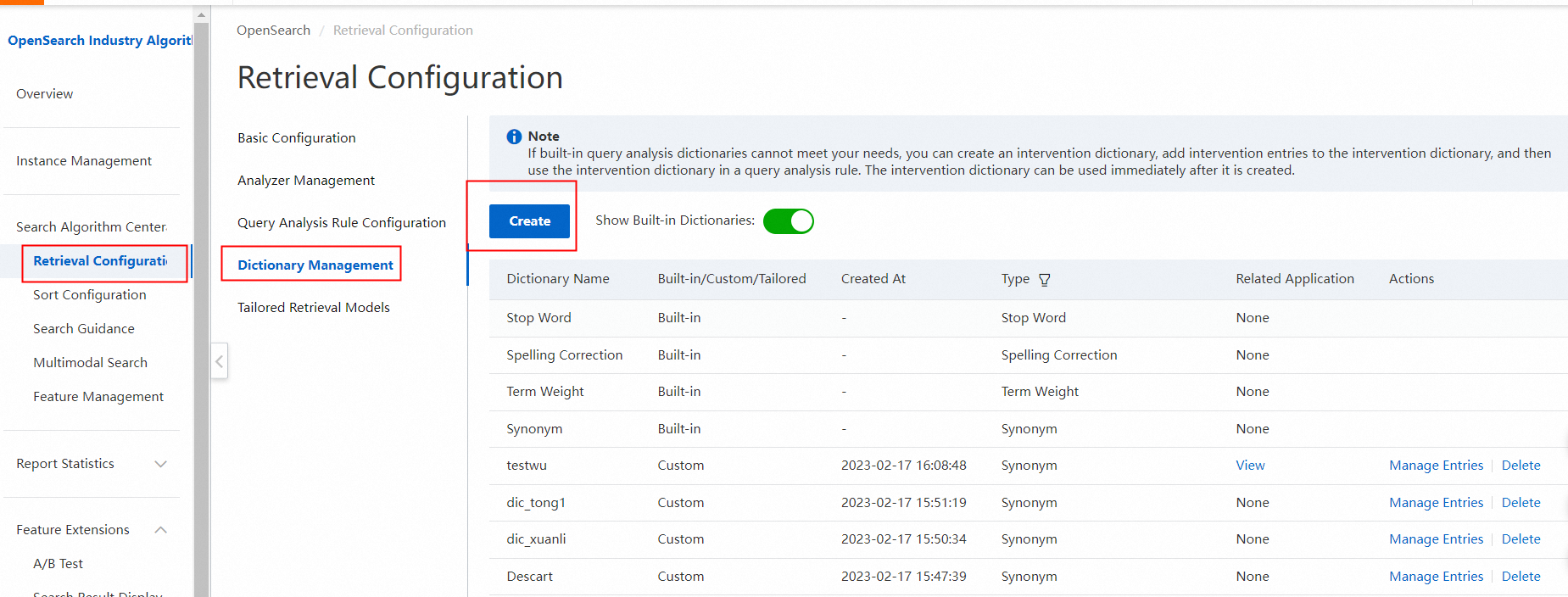 手順 1.2:右上隅にある作成をクリックします。クエリ分析辞書の作成パネルで、辞書名を指定し、辞書タイプパラメータをスペル修正に設定して、保存をクリックします。
手順 1.2:右上隅にある作成をクリックします。クエリ分析辞書の作成パネルで、辞書名を指定し、辞書タイプパラメータをスペル修正に設定して、保存をクリックします。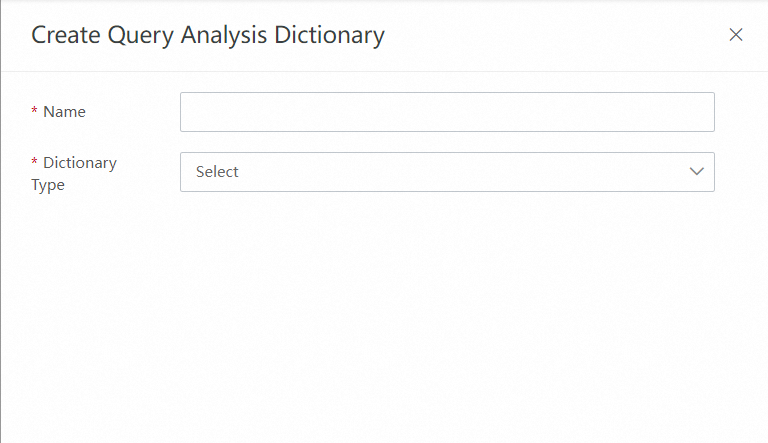 手順 1.3:辞書管理ページの辞書リストで、作成した辞書を見つけ、アクション列のエントリの管理をクリックして、エントリの管理ページに移動します。
手順 1.3:辞書管理ページの辞書リストで、作成した辞書を見つけ、アクション列のエントリの管理をクリックして、エントリの管理ページに移動します。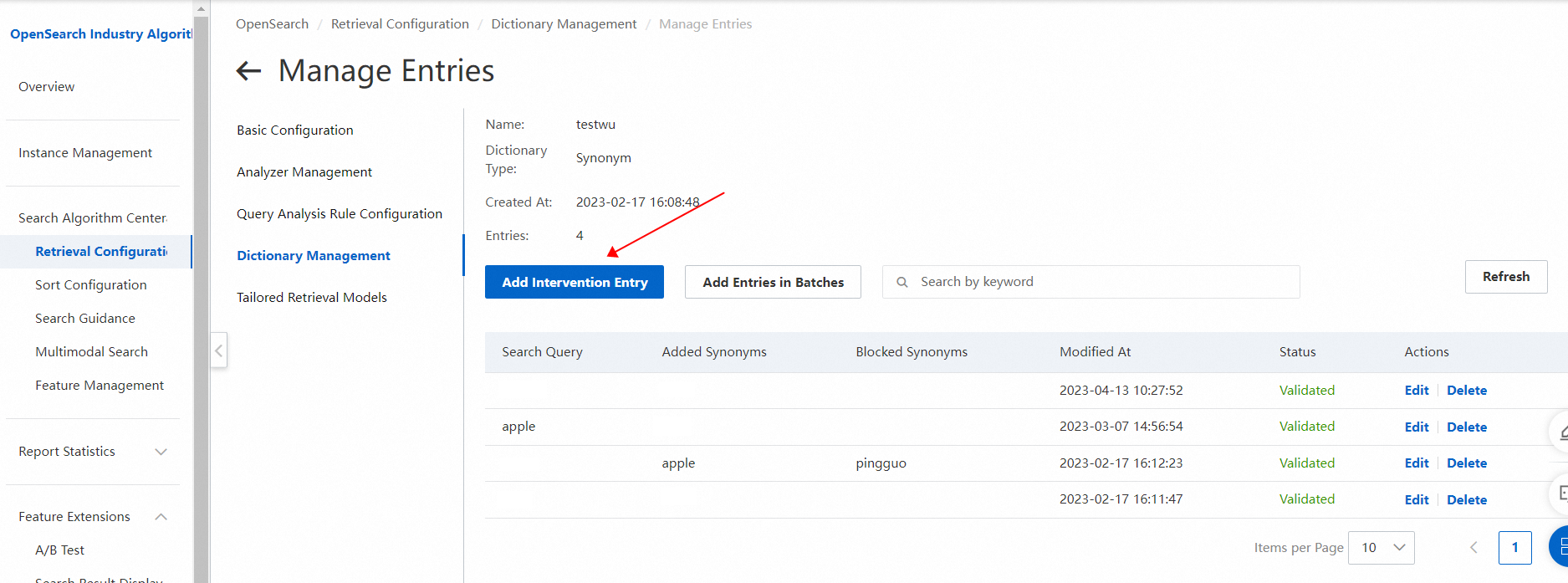 手順 1.4:介入エントリの追加をクリックして、介入エントリを作成します。
手順 1.4:介入エントリの追加をクリックして、介入エントリを作成します。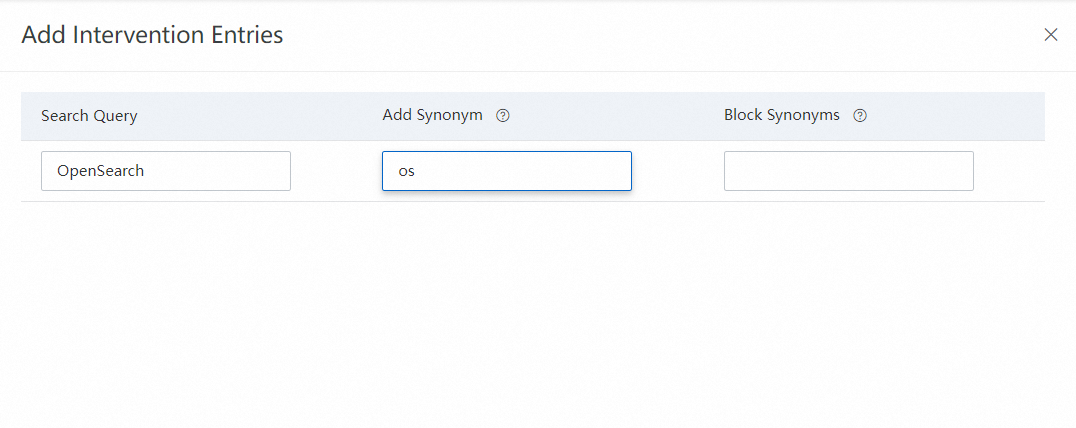 手順 1.5:保存をクリックします。介入エントリが追加されます。作成した介入エントリは、介入エントリリストで確認できます。
手順 1.5:保存をクリックします。介入エントリが追加されます。作成した介入エントリは、介入エントリリストで確認できます。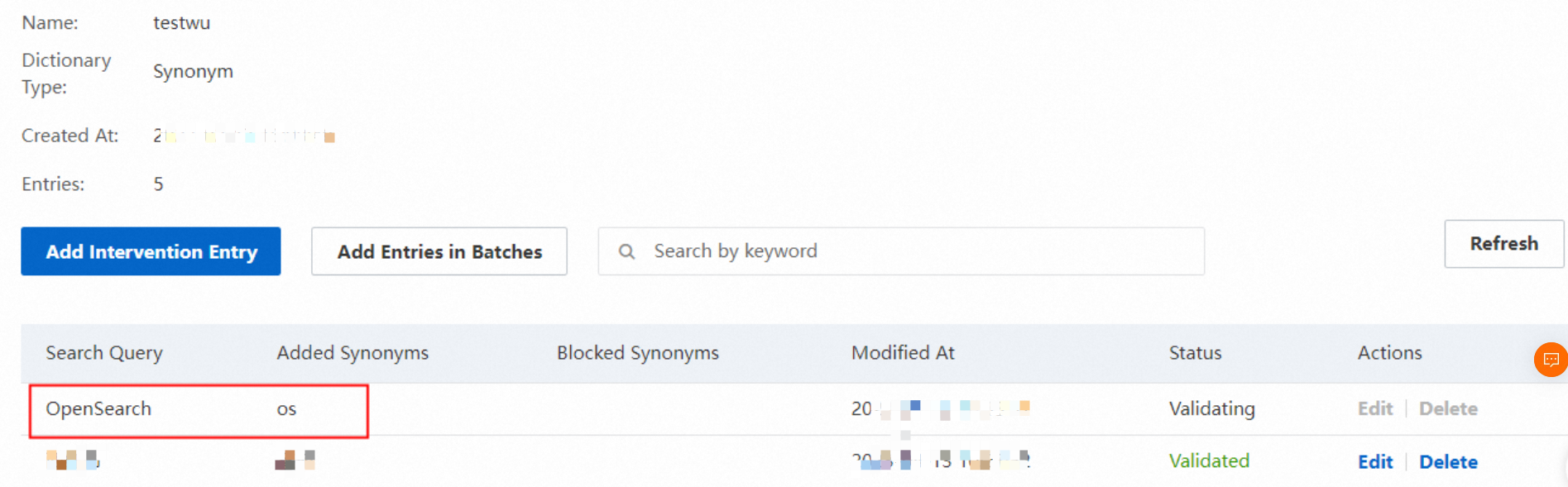 手順 2:OpenSearch コンソールの左側のナビゲーションペインで、検索アルゴリズムセンター > 検索設定 を選択します。検索設定ページで、左側のペインにあるクエリ分析ルール設定をクリックして、クエリ分析ルール設定ページに移動します。
手順 2:OpenSearch コンソールの左側のナビゲーションペインで、検索アルゴリズムセンター > 検索設定 を選択します。検索設定ページで、左側のペインにあるクエリ分析ルール設定をクリックして、クエリ分析ルール設定ページに移動します。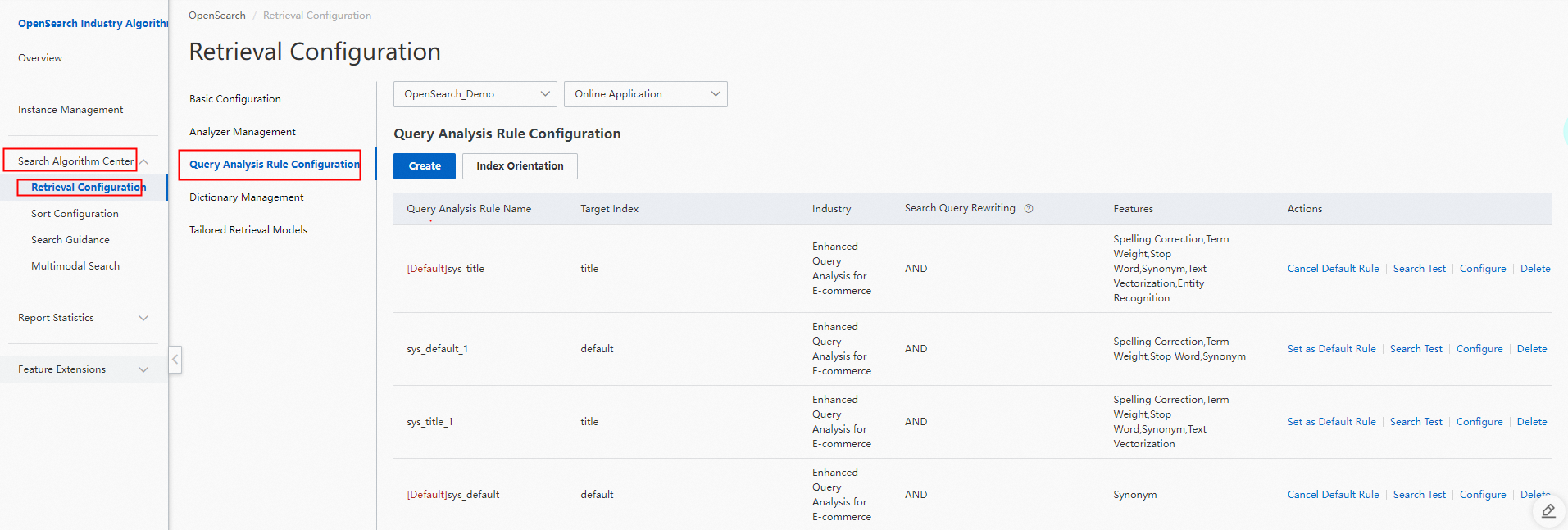 手順 3:右上隅にある作成をクリックして、公開されていないルールを追加します。ルールの作成パネルで、介入辞書パラメータを作成した dic_error 辞書に設定します。
手順 3:右上隅にある作成をクリックして、公開されていないルールを追加します。ルールの作成パネルで、介入辞書パラメータを作成した dic_error 辞書に設定します。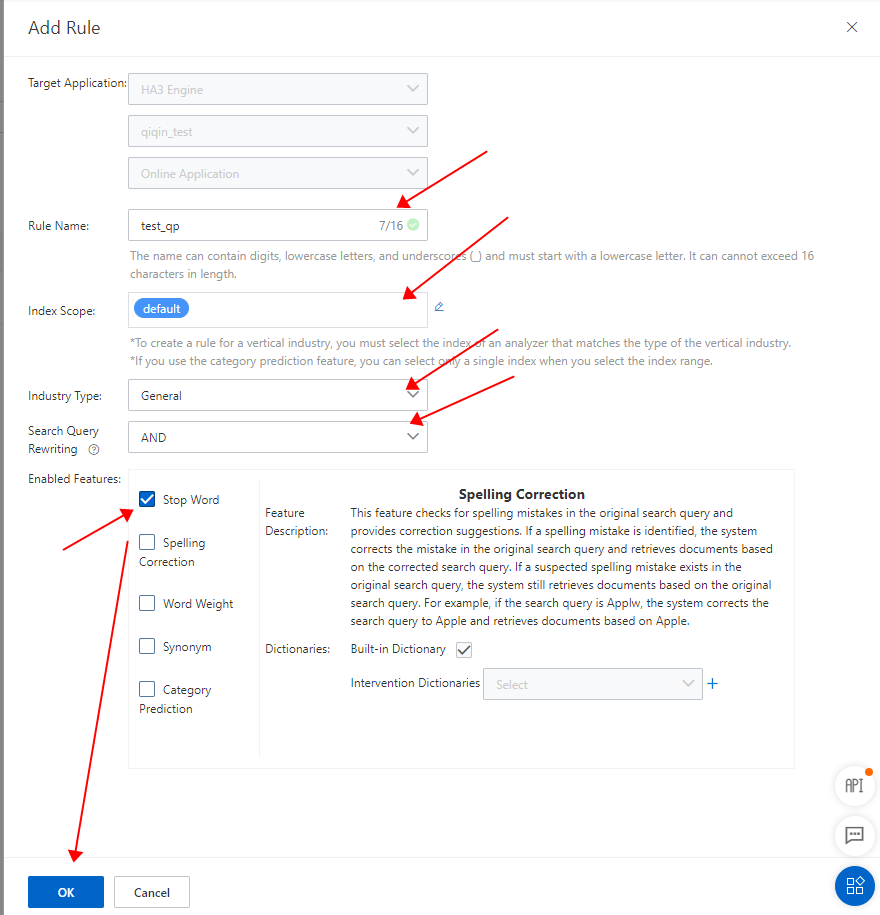
ストップワード:この機能は、組み込みのストップワード辞書に基づいて、検索クエリから無意味な単語を除外します。無意味な単語とは、頻度は高いものの検索結果に影響を与えない単語のことです(句読点、係助詞など)。たとえば、検索クエリが「Running Man!」の場合、ストップワードフィルタリングの後、感嘆符(!)は除外され、検索プロセスには関与しません。
スペル修正:この機能は、検索クエリに含まれるスペルミスを修正し、修正候補を提供します。元の検索クエリに明らかなスペルミスが含まれている場合、OpenSearch はこれらのエラーを修正し、修正された検索クエリに基づいてドキュメントを検索します。元の検索クエリにスペルミスの可能性がある場合、OpenSearch は元の検索クエリに基づいてドキュメントを検索します。たとえば、OpenSearch は検索クエリ「Alipapa」のスペルミスを修正し、修正された検索クエリ「Alibaba」を使用してドキュメントを検索します。
単語の重み:この機能は、検索クエリ内の各用語の重要度を評価し、評価された重要度を重みとして定量化します。OpenSearch は、重要度の低い用語を使用してドキュメントを検索しない場合があります。たとえば、検索クエリが「OpenSearch is good or not」の場合、用語の重み分析の後、「OpenSearch」を含むドキュメントを検索できます。
同義語:この機能は、OpenSearch が提供する一般的な同義語ライブラリと意味モデルに基づいて、検索クエリの用語に同義語を追加します。これにより、検索結果の数が増加します。たとえば、検索クエリが「KFC」の場合、同義語展開の後、「Kentucky Fried Chicken」または「KFC」を含むドキュメントが検索されます。この機能は、用語の重み分析機能と組み合わせて使用することで、パフォーマンスを向上させることができます。
エンティティ認識:OpenSearch の固有表現認識(NER)機能は、検索クエリが分析された後、要件に基づいて検索クエリ内の各意味エンティティを認識します。各意味エンティティには特定のカテゴリが割り当てられます。優先度の低い意味エンティティカテゴリは検索プロセスで無視される場合がありますが、優先度の高い意味エンティティカテゴリはカテゴリ予測モデルのトレーニングに影響を与える可能性があります。たとえば、検索クエリが「Nike Slim Dress」の場合、NER の後、「Nike」は優先度中程度のブランド名、「Slim」は優先度低スタイル要素、「Dress」は優先度高カテゴリ名として認識されます。
手順 4:ルールが作成されたら、クエリ分析ルール設定ページのアクション列にある検索テストをクリックして、検索効果を確認します。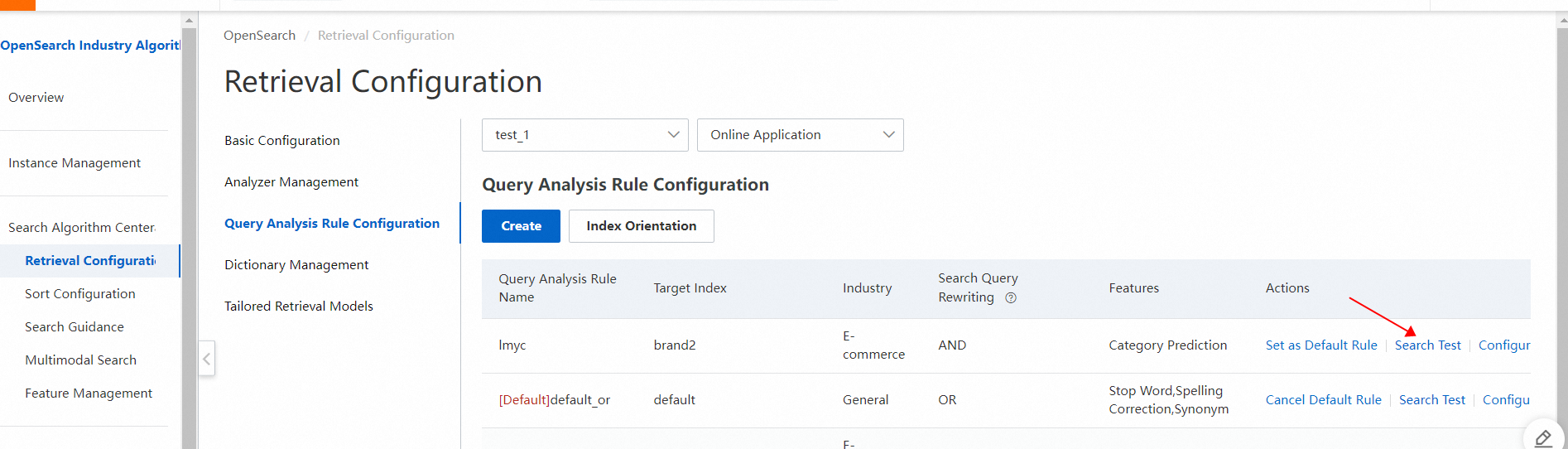 手順 5:クエリ分析のプロセスが正しいことを確認したら、クエリ分析ルール設定ページのインデックス方向をクリックします。次に、作成したクエリ分析ルールをデフォルトのクエリ分析ルールとして設定します。
手順 5:クエリ分析のプロセスが正しいことを確認したら、クエリ分析ルール設定ページのインデックス方向をクリックします。次に、作成したクエリ分析ルールをデフォルトのクエリ分析ルールとして設定します。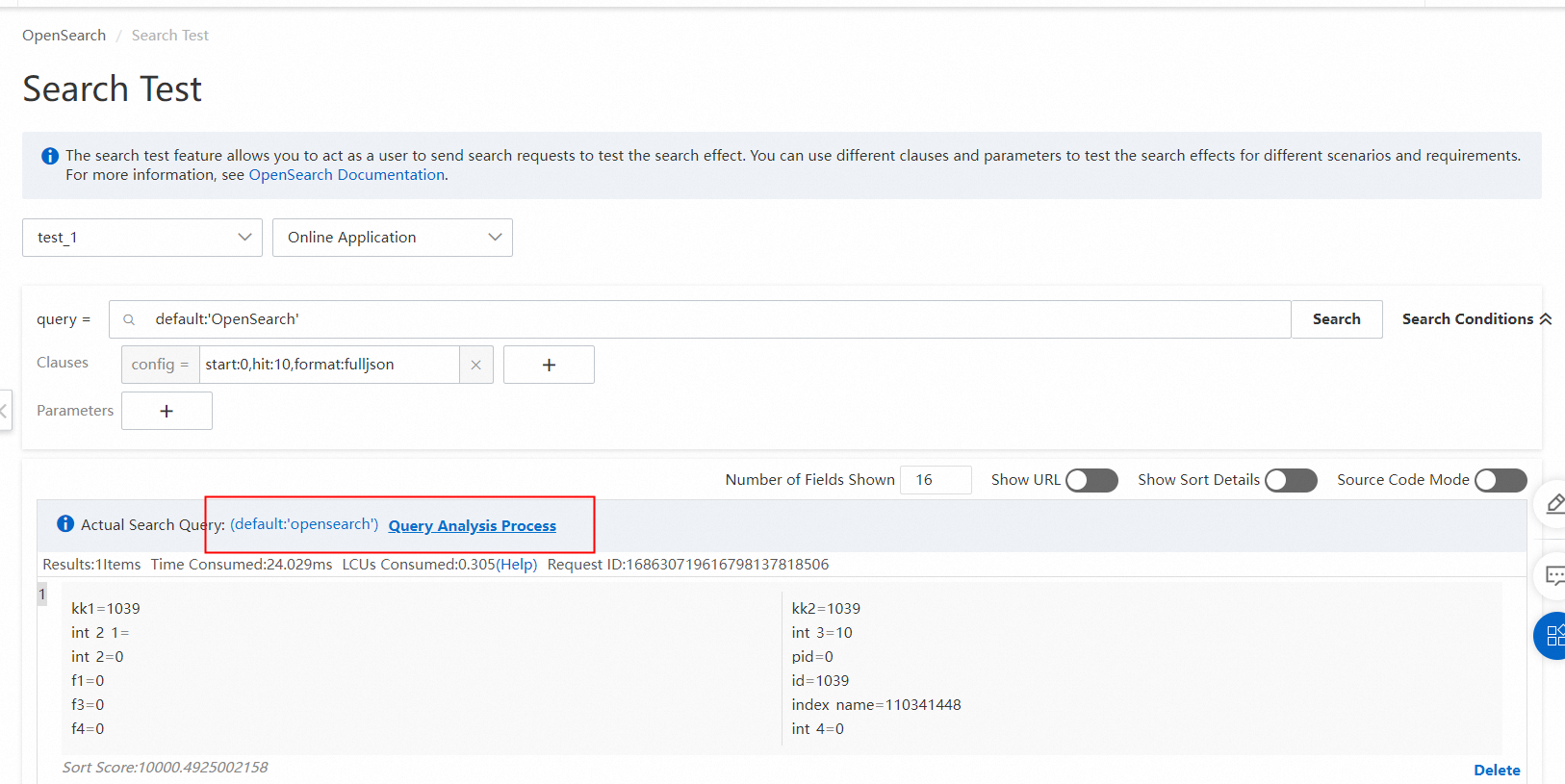

並べ替え式の構成:並べ替え式を使用すると、カスタムメソッドを使用してアプリケーションの検索結果を並べ替えることができます。クエリ句で式を指定して結果を並べ替えることができます。詳細については、並べ替え式の構成を参照してください。
手順 1:OpenSearch コンソールにログインします。左側のナビゲーションペインで、検索アルゴリズムセンター > 並べ替え設定 を選択して、ポリシー管理ページに移動します。
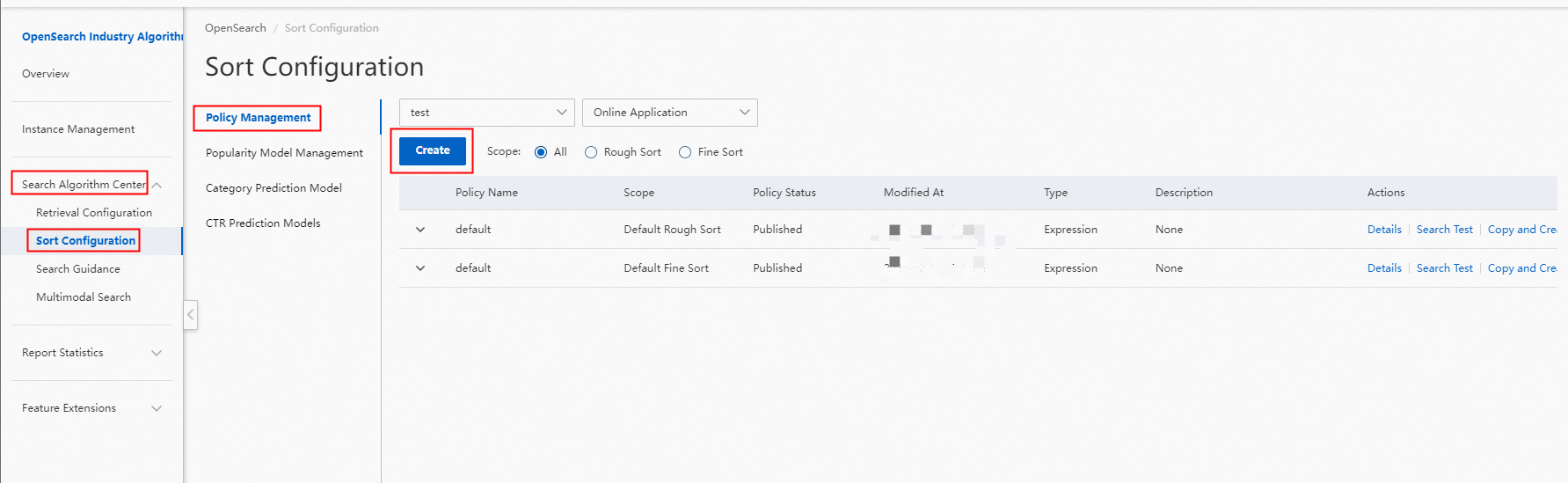 手順 2:右上隅にある作成をクリックして、大まかな並べ替え式を追加します。
手順 2:右上隅にある作成をクリックして、大まかな並べ替え式を追加します。
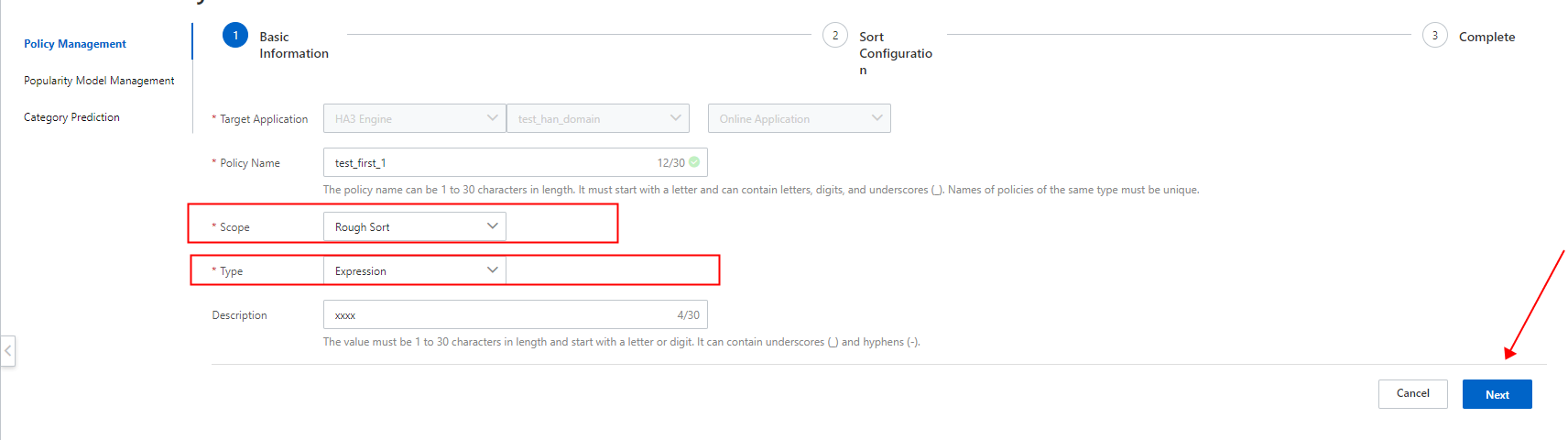
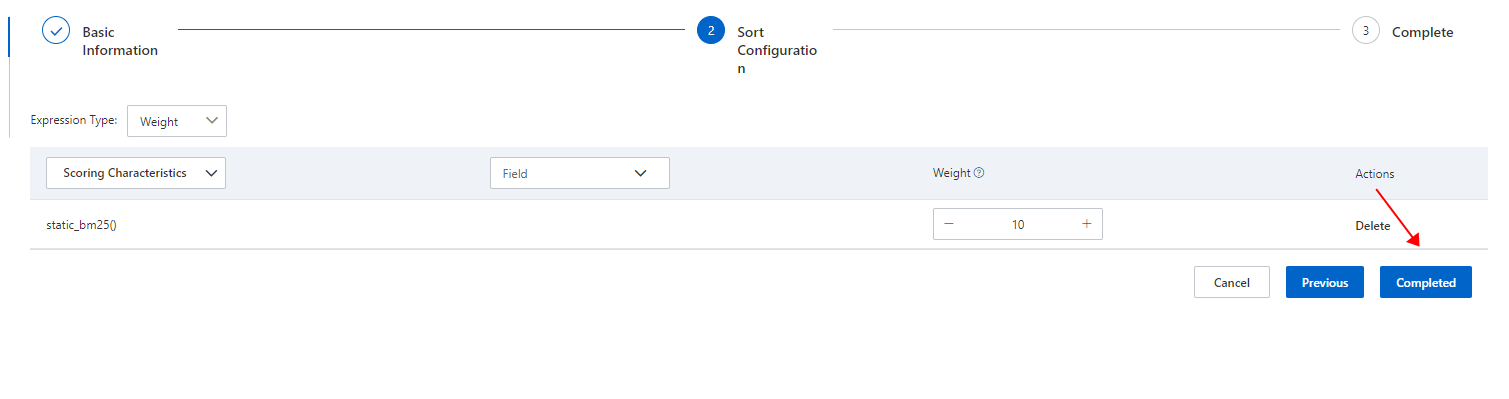 大まかな並べ替えは検索パフォーマンスに大きく影響します。したがって、並べ替え設定手順では代表的なフィールドを選択することをお勧めします。前の図は、テキストスコアとドキュメントの新しさを示す適時性スコアを計算するための式の構成方法を示しています。
大まかな並べ替えは検索パフォーマンスに大きく影響します。したがって、並べ替え設定手順では代表的なフィールドを選択することをお勧めします。前の図は、テキストスコアとドキュメントの新しさを示す適時性スコアを計算するための式の構成方法を示しています。
手順 3:細かい並べ替え式を追加します。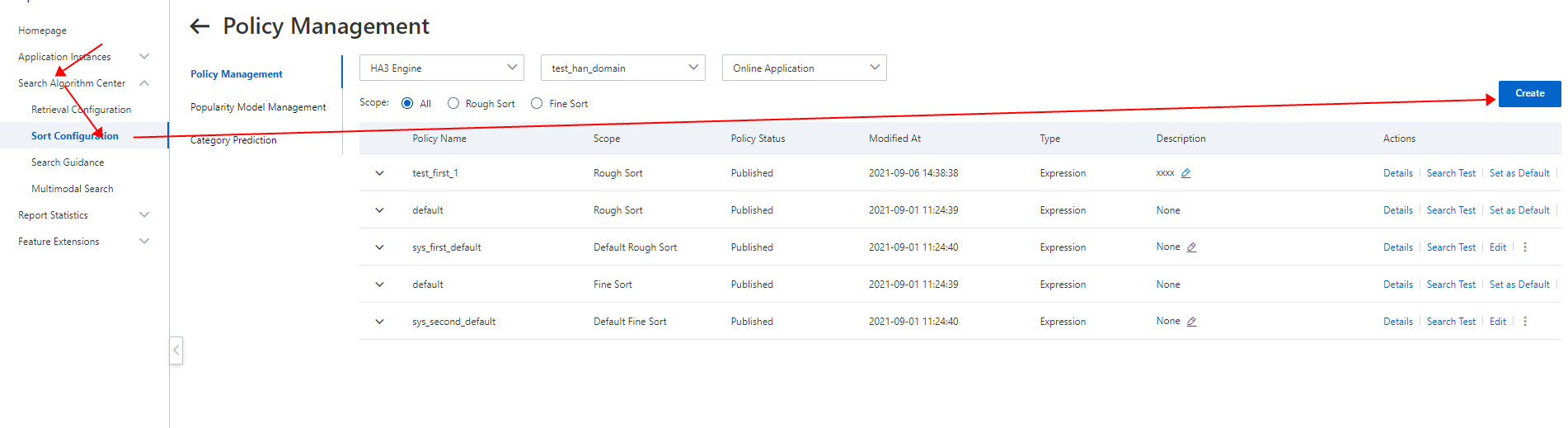
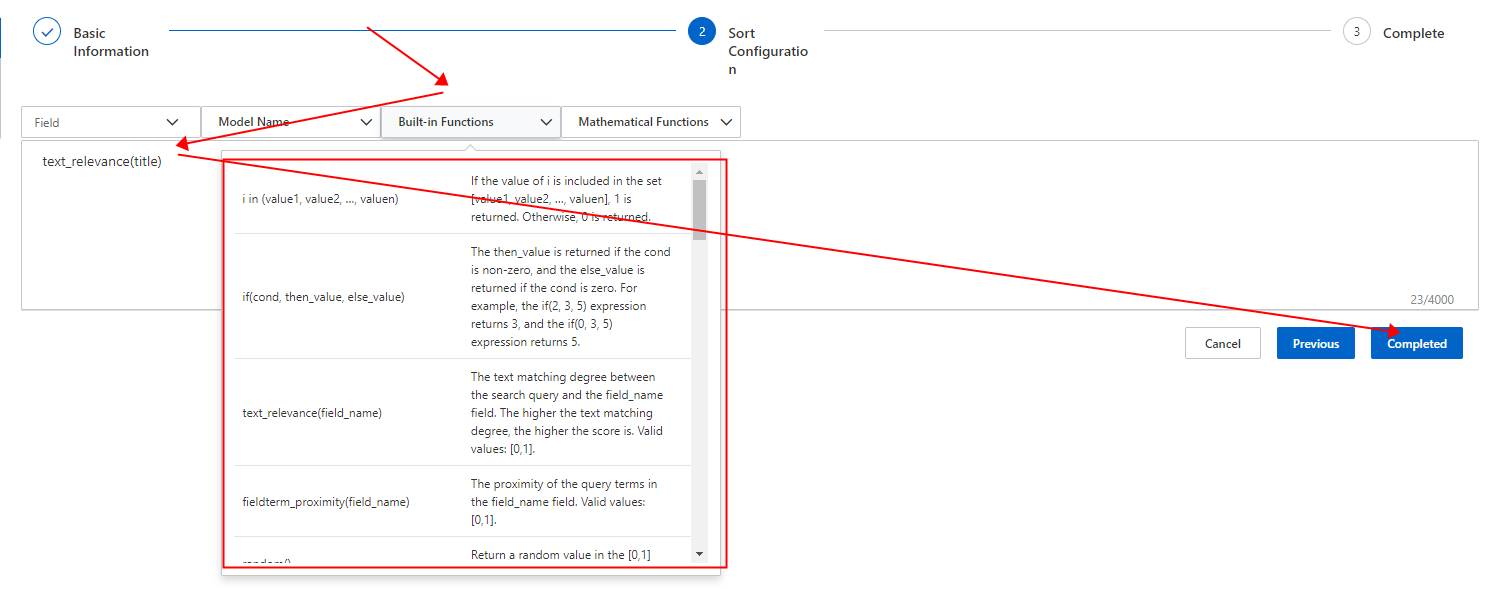 前の図は、テキスト関連性スコアを計算するための式の構成方法を示しています。
前の図は、テキスト関連性スコアを計算するための式の構成方法を示しています。
手順 4:構成を完了します。次の図は、検索テストの結果を示しています。 検索テストページでは、一般的なクエリの検索結果と並べ替え式を使用したクエリの検索結果を比較できます。
検索テストページでは、一般的なクエリの検索結果と並べ替え式を使用したクエリの検索結果を比較できます。
ドロップダウン候補:OpenSearch は、ドロップダウン候補機能を提供して、目的のクエリを見つけるのに役立ちます。これにより、E コマースシナリオで検索クエリを入力する手間が省けます。詳細については、ドロップダウン候補を参照してください。
カテゴリ予測:OpenSearch は、入力した検索クエリが属するカテゴリを予測するカテゴリ予測機能を提供します。詳細については、カテゴリ予測を参照してください。
その他の一般的な構成:
e コマースシナリオでは、特定のベンダーの複数の商品が高スコアで検索結果リストの先頭に表示される場合があります。これは、検索結果の表示効果とユーザーエクスペリエンスに影響します。この問題を解決するには、distinct 句を使用して、さまざまな検索結果が表示されるようにします。詳細については、distinct 句を参照してください。
価格帯に基づいて検索結果を表示するビジネスシナリオでは、filter 句を使用できます。詳細については、filter 句を参照してください。次のサンプルコードは、価格フィールドに基づいて filter 句を使用する方法を示しています。
if(!lowPrice.equals("")){ queryElement.addFilter("price>=" + lowPrice); } if(!highPrice.equals("")){ queryElement.addFilter("price<=" + highPrice); }
まとめ
上記の手順を完了すると、E コマースシナリオの商品検索に使用されるシンプルなプロトタイプが OpenSearch に基づいて構築されます。OpenSearch は、ビジネス要件に基づいて簡単にデータを検索するための包括的な検索サービスと API を提供します。これにより、開発作業負荷が大幅に軽減され、検索機能の開発が容易になります。さらに、複雑な検索エンジン プラットフォームを構築する必要がないため、システムの展開とメンテナンスの作業負荷とコストが削減されます。ビジネスシナリオに基づいて、OpenSearch のカスタム構成と機能を使用できます。これにより、データ検索におけるユーザーエクスペリエンスが向上します。