検索候補は、ユーザーが入力する際に候補となるクエリをインテリジェントに推奨する基本的な検索サービス機能です。これにより、入力効率が向上し、ユーザーはより迅速にコンテンツを見つけることができます。
機能紹介
検索候補機能は、ドキュメントのコンテンツからクエリをインテリジェントに抽出します。中国語のプレフィックス、完全なピンインのプレフィックス、ピンインの頭字語のプレフィックス、漢字とピンインの組み合わせ、トークン化後のプレフィックス、および中国語の同音異義語に基づいて候補クエリを取得できます。
たとえば、クエリ ロングドレス は、次のいずれかを検索することで取得できます。
中国語のプレフィックスの例:
连, 连衣, …完全なピンインのプレフィックス:
l, li, lian, lianyi, lianyiqun, …ピンインの頭字語のプレフィックス:
l, ly, lyq, …漢字とピンインの組み合わせ:
dress yi, one-piece dress qun, …トークン化後のプレフィックス:
long style, long style one-piece dress, one-piece dress long, …中国語の同音異義語:
one-piece dress group, social group, …
さらに、介入エントリを使用して検索候補データを管理できます。また、検索候補の複数のビジネスメトリックを表示することもできます。詳細については、「検索候補レポート」をご参照ください。
注意事項
データソース
検索候補データは、主にアプリケーションドキュメントから取得されます。各検索候補モデルについて、1 つのアプリケーションから最大 3 つのフィールドをデータソースとして選択できます。処理中、システムはアプリケーションから数百万に及ぶドキュメントの一部を選択します。その後、システムは指定されたルールに従ってこれらのドキュメント内の選択されたフィールドを処理し、候補データの候補を生成します。最後に、他のルールに基づいて一定量のデータを候補クエリとして保持します。
クエリ生成ルール
システムは、過去 N 日間 (デフォルトは 7) の履歴クエリから候補クエリを生成します。クエリの term の重み、取得された結果の数、過去の検索頻度、および前日にクエリが結果を返したかどうかなどの要因を考慮します。このプロセスにより、人気のある過去の検索クエリが候補として選択されます。システムは、候補クエリを生成するための 2 つのルール、抽出と生成および元の値を保持をサポートしています。
抽出と生成:このルールは、Alibaba Cloud の NLP チームが提供する、大量の自然言語データでトレーニングされたアナライザを使用します。アナライザはフィールドのコンテンツをトークン化し、意味のある term を抽出し、それらを組み合わせて候補クエリを作成します。この方法により、生成されたクエリで対応するドキュメントを取得できるようになります。
元の値を保持:このルールは、トークン化せずにフィールドのコンテンツを直接候補クエリとして使用します。フィールドのコンテンツが 30 文字の制限を超えた場合、フィールドは切り捨てられ、最初の 30 文字が候補クエリとして使用されます。この方法は、店舗名、ユーザー名、曲名など、トークン化を必要としないアプリケーションフィールドに適しています。また、独自の候補クエリを生成し、そのまま表示したい場合にも役立ちます。短く明確なフィールドを使用することを推奨します。
注:抽出された候補クエリは、過去 N 日間 (デフォルトは 7 日間) の履歴検索リクエストと、`raw_query` パラメーターを含むリクエストからのものです。
手動介入
検索候補は、次の介入方法をサポートしています。
ブラックリストとホワイトリストを使用して、候補クエリの結果に介入できます。
データソースアプリケーションドキュメントのフィルター条件を設定できます。フィルター条件を設定すると、これらの条件を満たすアプリケーションドキュメントのみが検索候補の候補クエリの生成に使用されます。
パラメーター | 説明 |
フィルター条件 | OpenSearch アプリケーションのテーブルスキーマからフィールドを入力します。このフィルター条件は、現在のアプリケーションのすべてのドキュメントデータに適用されます。注:
例:フィルター条件が status=1,level=1 の場合、この条件を満たすレコードのみが選択されます。 |
コンソールの設定は次の図のとおりです。
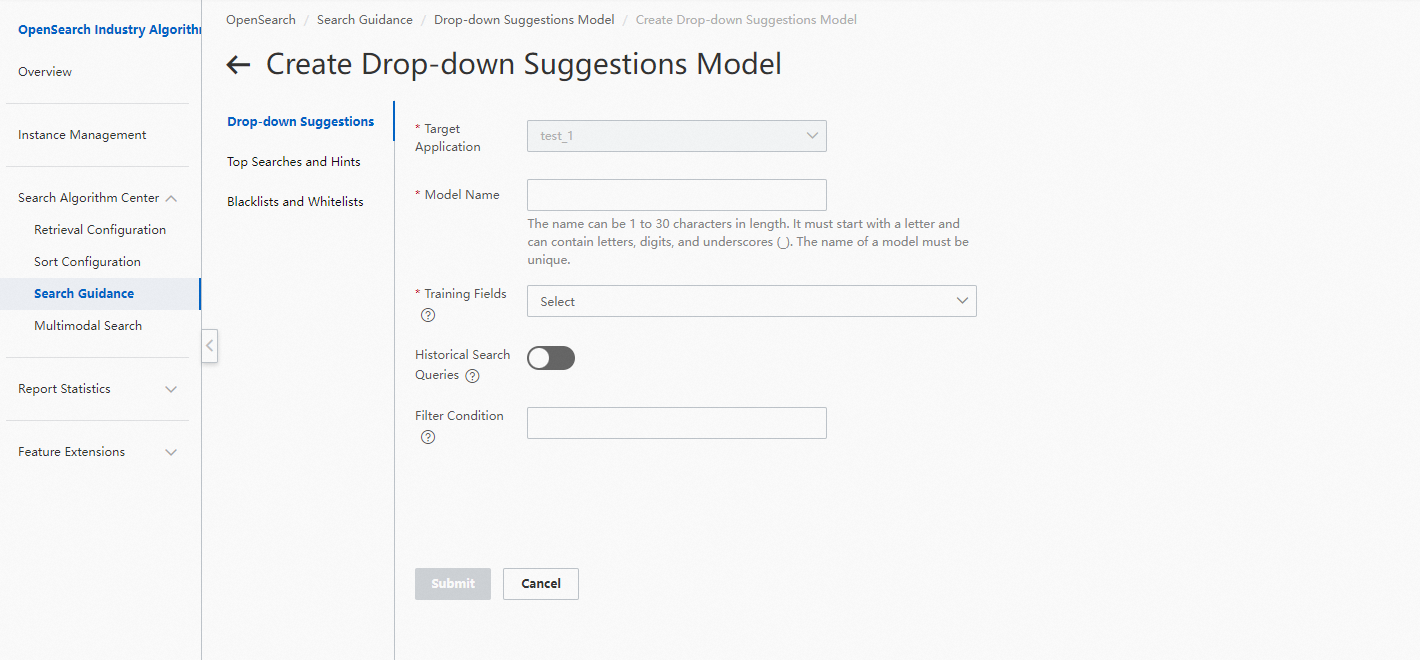
候補クエリ結果の介入
ブラックリスト:ブラックリスト内のキーワードは「含む」マッチングをサポートします。ブラックリストに登録されたキーワードを含むクエリは、検索候補の結果に表示されません。候補に不要な結果が表示される場合は、キーワードをブラックリストに追加してブロックできます。
ホワイトリスト:ホワイトリストのクエリが推奨基準を満たすと、検索候補で優先的に表示されます。質の高いクエリが認識されない、またはランクが低い場合は、ホワイトリストに追加して、より良い候補結果を得ることができます。ブラックリストとホワイトリストの設定方法の詳細については、こちらをご参照ください。
Standard Edition のアプリケーションは検索候補をサポートしていません。この機能は Premium Edition のアプリケーションでのみ利用可能です。
1 つのアプリケーションに対して最大 10 個の検索候補モデルを作成できます。
モデル名は、各ユーザーに対して一意である必要があります。これは、検索候補、人気モデル、カテゴリ予測、ホットクエリ、およびヒントワードモデルに適用されます。
データソースとして、検索候補はインデックスが作成された TEXT、SHORT_TEXT、LITERAL、INT 型のフィールドのみをサポートします。
同じモデルに対して最大 3 つのトレーニングフィールドを選択できます。
アプリケーションスキーマを変更する場合、検索候補のデータソースとして使用されるフィールドは変更できません。
検索候補モデルをトレーニングする際は、アプリケーションテーブルに 1,000 件以上のデータエントリ (`raw_query` とアプリケーションに保存されているデータの合計) があることを確認してください。そうでない場合、データ整合性の問題によりモデルのトレーニングが失敗する可能性があります。
アプリケーションを削除すると、対応する検索候補モデルも削除されます。
検索候補の検索では、`query` パラメーターは UTF-8 エンコーディングで最大 30 バイト (漢字 10 文字に相当) の長さをサポートします。クエリがこの制限を超えると、エラーが報告され、結果は返されません。
検索候補の検索では、`hit` パラメーターの値は (0, 30] の範囲の整数である必要があります。それ以外の場合、デフォルト値の 30 が使用され、エラーが返されます。例えば、`hit` パラメーターを 0、-1、または 31 に設定すると、システムはその値を 30 として処理し、エラーを返します。
ブラックリストには最大 500 個のキーワードを含めることができます。
ホワイトリストには最大 500 個のクエリを含めることができます。
ブラックリストとホワイトリストのデータ間で競合が発生した場合、ブラックリストが優先されます。
ブラックリストとホワイトリストへの変更はリアルタイムで有効になります。
検索候補モデルを作成すると、システムはデフォルトで毎日のスケジュールされたモデルトレーニングを有効にします。検索候補データは、スケジュールされたトレーニングごとに定期的に更新されます。
検索候補モデルのトレーニング時間は、アプリケーションのデータ量とシステムの負荷によって異なります。トレーニングに 30 分以上かかる場合は、お問い合わせください。
中国語の同音異義語補完および取得機能はデフォルトで有効になっています。リクエストにパラメーター
re_search="disable"を追加して、この機能を無効にすることができます。検索候補の基本機能は現在無料です。そのため、計算リソースとストレージリソースはシステムによって一律に設定されます。各検索候補モデルには、約 100 QPS の計算リソースと約 200 万の候補クエリ用のストレージが割り当てられます。
検索リクエストに `raw_query` パラメーターを設定します。これにより、データ処理システムがエンドユーザーによって入力された元の検索クエリを識別するのに役立ちます。詳細については、「検索処理ドキュメント」をご参照ください。
過去の検索クエリ機能を有効にすると、各トレーニングセッションで消費される課金時間に基づいてトレーニング料金が請求されます。詳細については、「課金の概要」をご参照ください。
`raw_query`、`user_id`、および `from_request_id` パラメーターの詳細については、こちらをご参照ください。
高頻度検索クエリ機能は、検索リクエストに `raw_query` パラメーターが含まれているか、クエリ句にデフォルトのインデックスが含まれている場合にデフォルトで有効になります。
トレーニングに使用される `raw_query` は検索リクエストに含まれている必要があります。それは、取得結果を返す、独立した、重複しない検索クエリでなければなりません。
プロンプトモデルのトレーニングデータは毎日 (T+1) 更新されます。当日にアップロードされたデータは、翌日のトレーニングが完了した後に有効になります。
推奨事項
検索候補の効果をさらに向上させるため、例えば、候補によって誘導される検索量を増やしたり、検索結果のクリック率を向上させたりするために、検索候補リクエストと検索リクエストを関連付けることを強く推奨します。関連付け方法については、このトピックの最後にある「検索候補リクエストと検索リクエストの関連付け」セクションをご参照ください。
簡潔なコンテンツで、ドキュメントの主題に関連するフィールドを選択してください。
「抽出と生成」ルールと「元の値を保持」ルールを適切に使用してください。
クエリ結果では、`suggestions` には現在のクエリの結果が含まれ、`errors` はエラーが発生したかどうかを示します。`errors` フィールドが空でないからといって、`suggestions` が空であるとは限りません。したがって、結果を解析する際には、`suggestions` が空かどうかを確認して、表示するデータがないかどうかを判断してください。
操作手順
1. 検索アルゴリズムセンターで、[検索ガイダンス] > [検索候補] に移動し、[作成] をクリックします。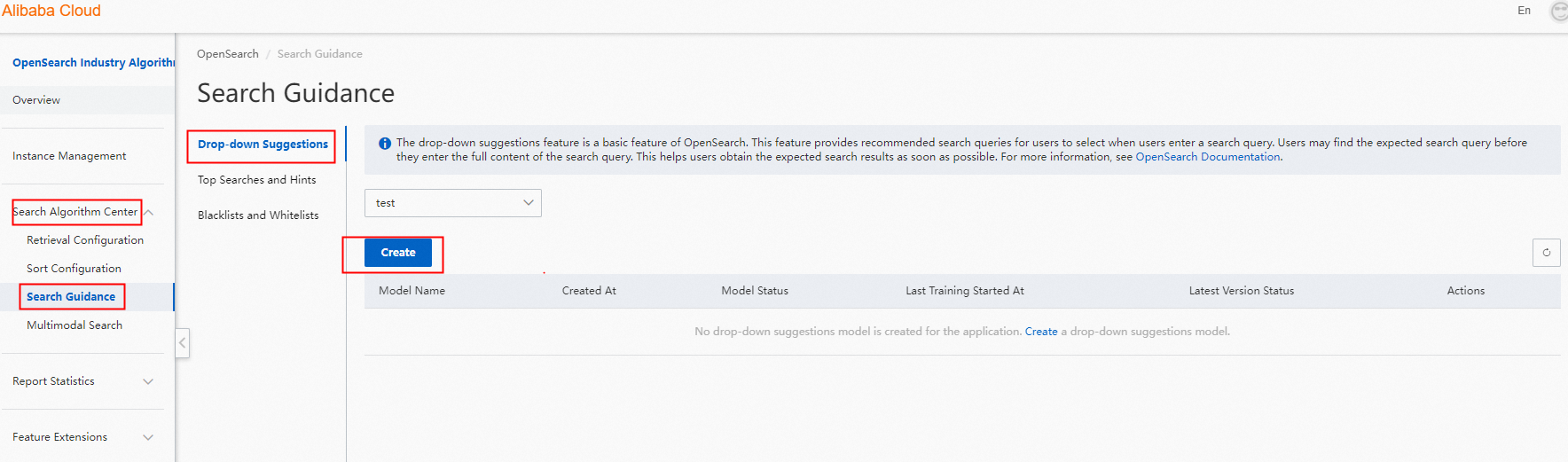
2. [モデル名] を入力し、[トレーニングフィールド] と抽出方法を選択し、[過去の検索クエリ] (オプション) を有効にし、[フィルター条件] (オプション) を入力して、[完了] をクリックします。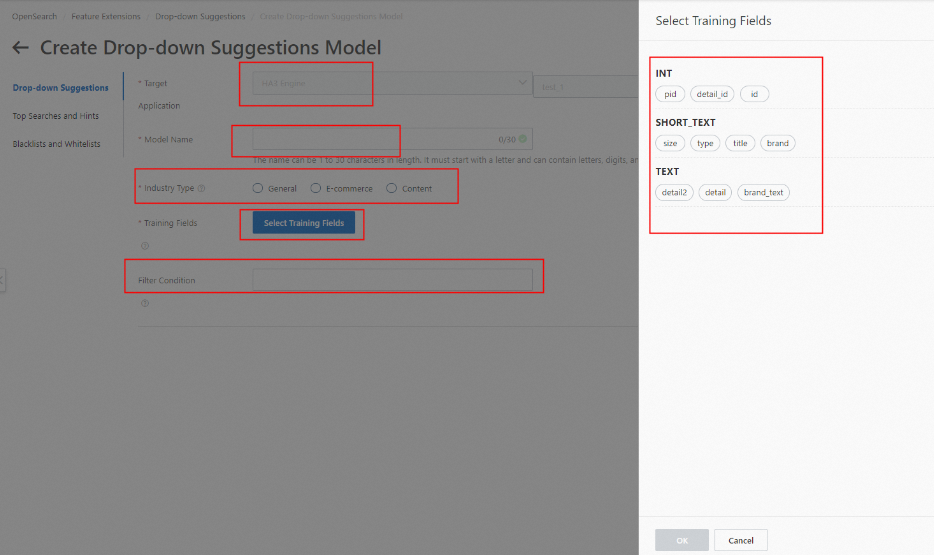
3. 検索候補リストページで、[モデルのトレーニング] をクリックして、作成したモデルをトレーニングします。
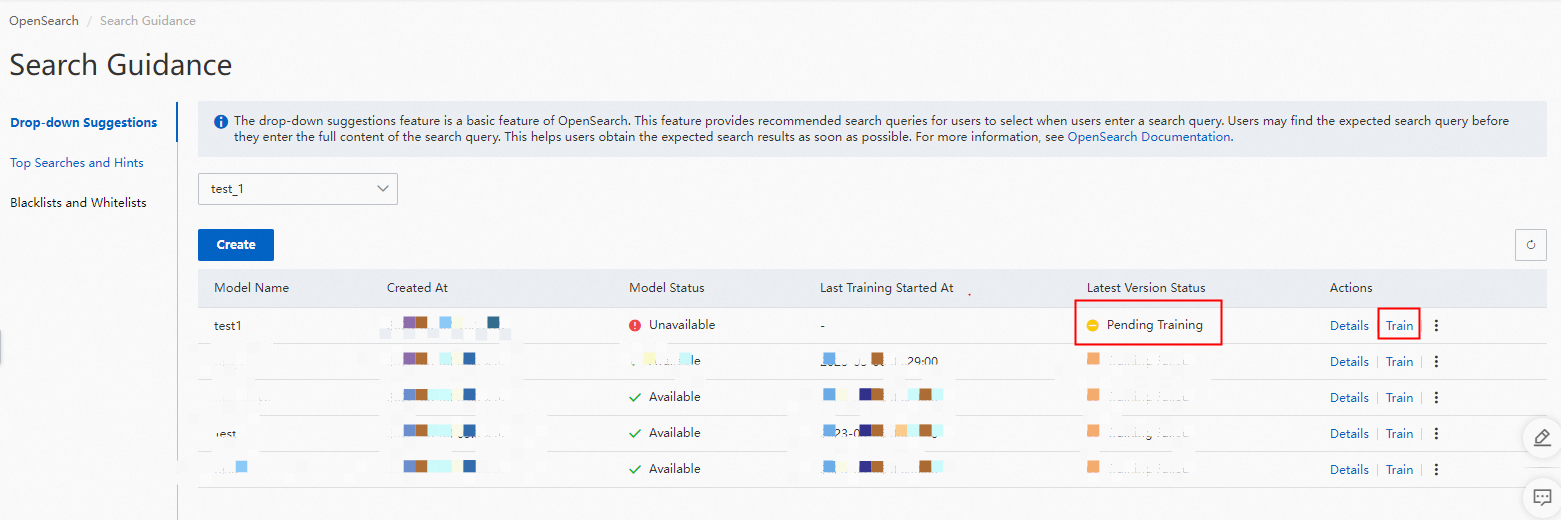
4. 検索候補モデルのトレーニングには、完了まで約 20〜30 分かかります。
5. モデルのトレーニングが完了したら、検索候補の効果をテストできます。次の図は、「抽出」と「元の値を保持」の抽出方法のテスト結果を示しています。
元の値を保持: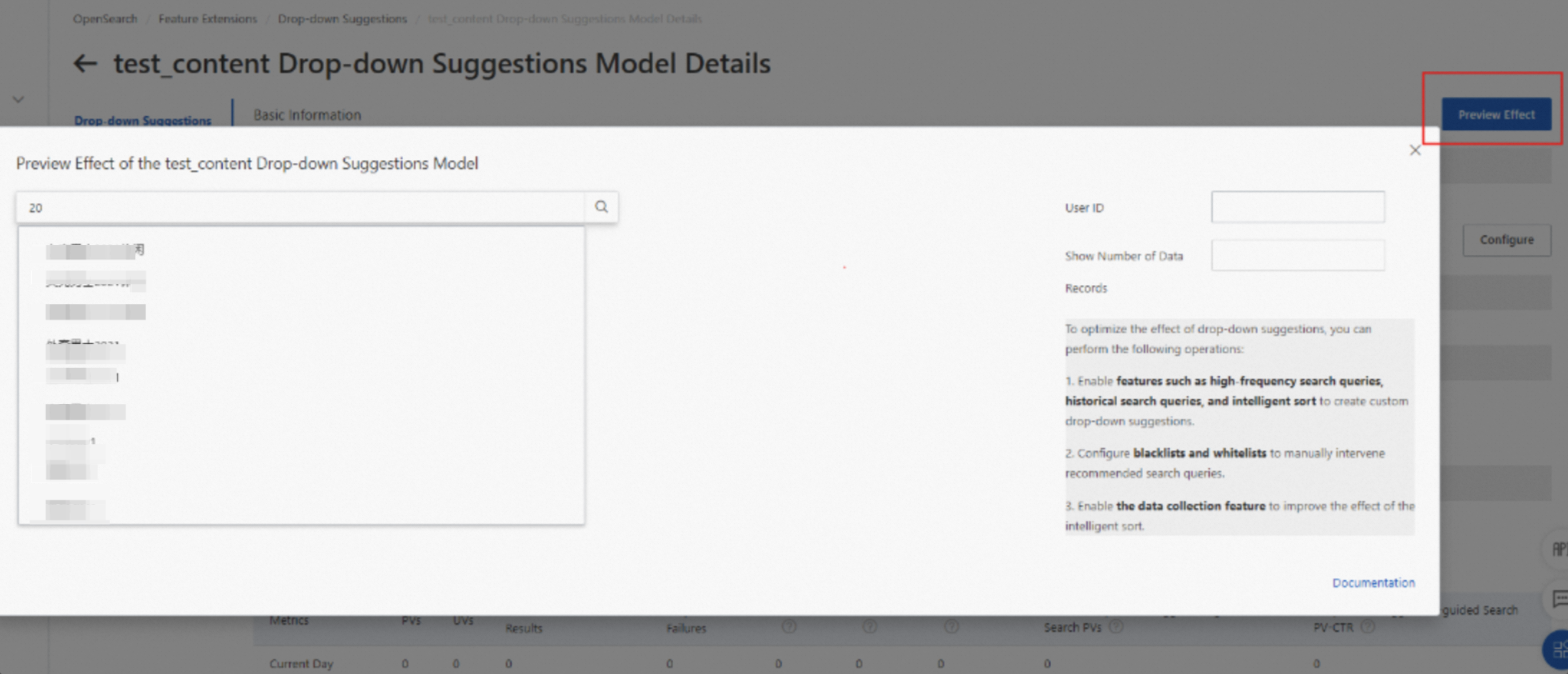
抽出: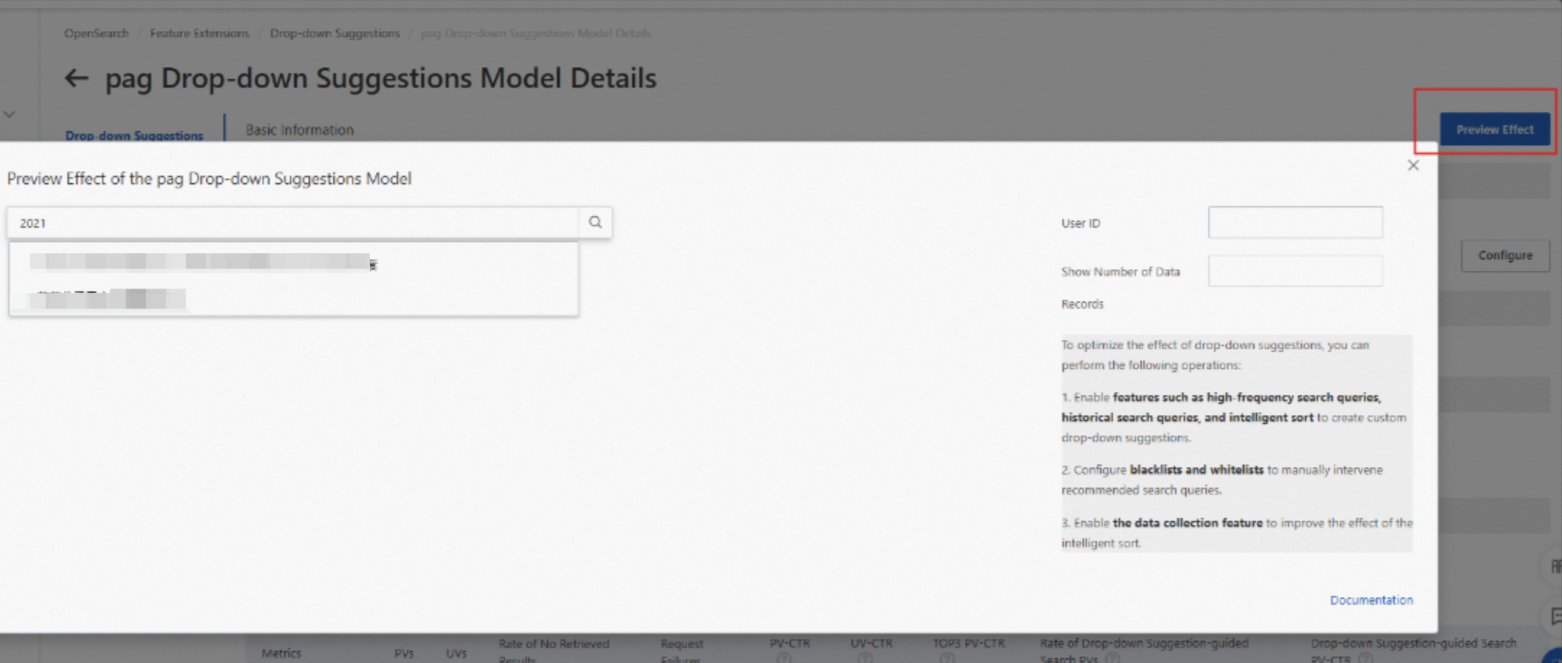
6. オンラインで候補単語をクエリします。次のデモに示されています。詳細な API 命令については、「検索候補開発ガイド」をご参照ください。
検索候補ページの詳細
検索候補リストページ
OpenSearch コンソールで、[検索アルゴリズムセンター] > [検索ガイダンス] > [検索候補] に移動して、検索候補リストページを開きます。次の図に示されています。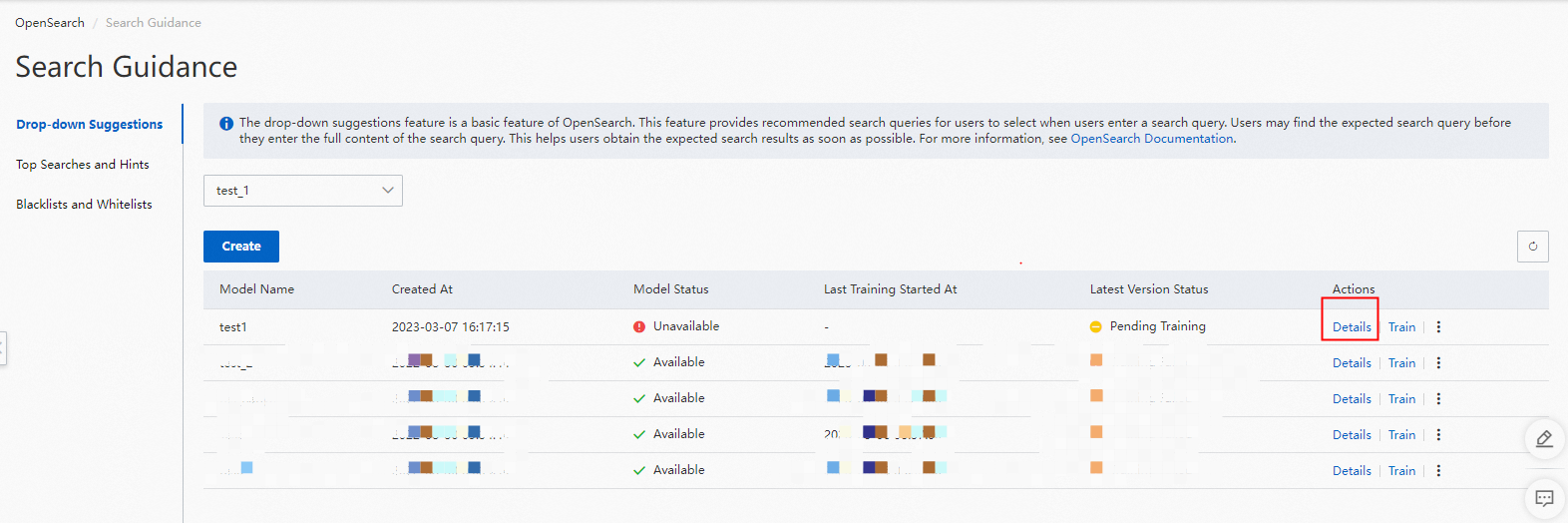
リストページには、モデル名、作成時間、モデルステータス、最終トレーニングステータスなど、検索候補モデルに関する情報が表示されます。ステータスは、トレーニング待ち、トレーニング中、トレーニング完了、またはデータ異常のいずれかです。[操作] 列では、モデルの詳細の表示、トレーニング、削除が可能です。
検索候補モデル詳細ページ
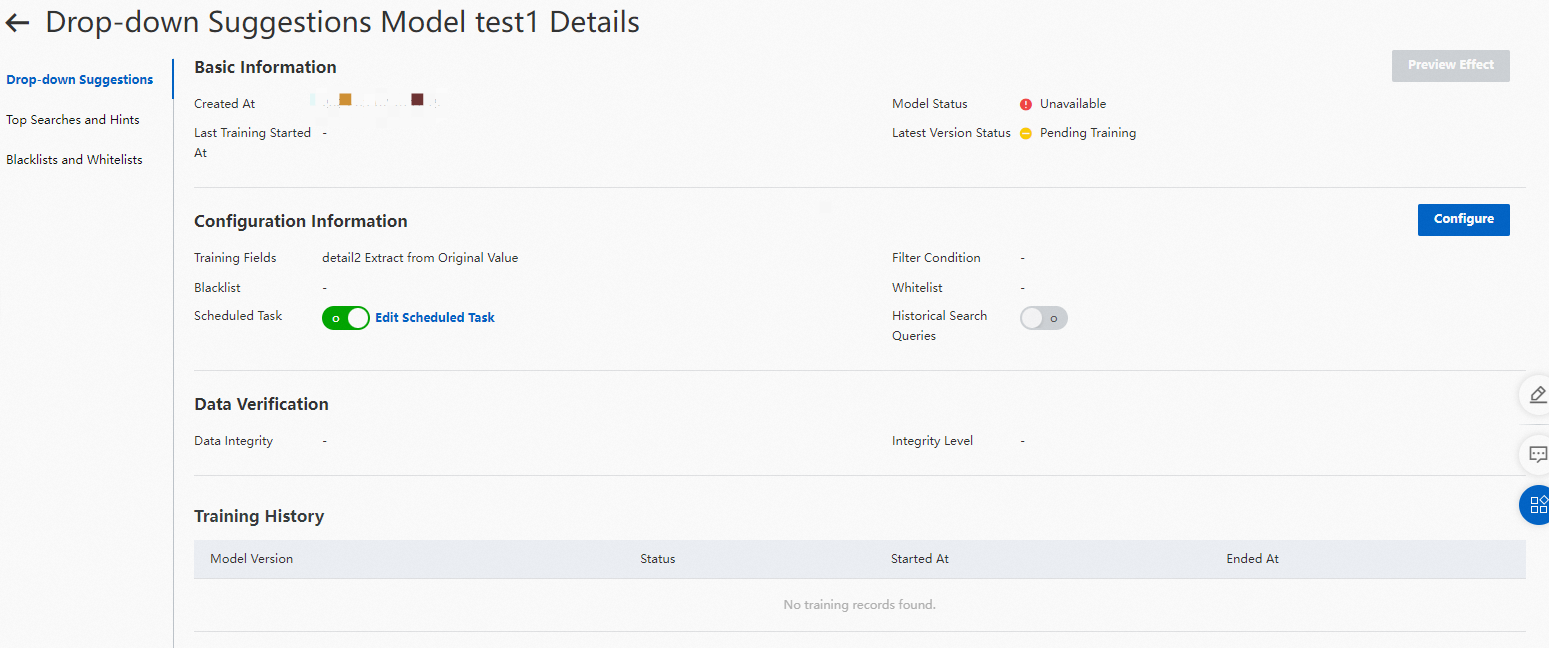 基本情報:モデルの作成時間、ステータス、最終トレーニング開始時刻、および最新バージョンのステータスを表示します。ステータスが「データ異常」の場合、テーブルの下に「異常レポート」ポップアップウィンドウが表示されます。
基本情報:モデルの作成時間、ステータス、最終トレーニング開始時刻、および最新バージョンのステータスを表示します。ステータスが「データ異常」の場合、テーブルの下に「異常レポート」ポップアップウィンドウが表示されます。
構成情報:モデルの構成済みトレーニングフィールド、フィルター条件、ブラックリスト/ホワイトリスト、スケジュールされたトレーニング、および過去の検索クエリを表示します。
データ検証:モデルトレーニングのデータ整合性と整合性レベルを表示します。
トレーニング履歴:モデルのトレーニングレコードを表示します。
コアメトリックデータ
異なる時間範囲を選択して、検索候補モデルのコアメトリックデータをテーブルと折れ線グラフで表示できます。
注:特定のメトリックの意味については、「検索候補レポート」をご参照ください。
検索候補の SDK デモ
API:
GET v3/openapi/suggestions/{suggestion_name}/actions/search?hit=10&query={your_query}&re_search=homonym&user_id=xxxJava SDK の Maven 依存関係:
<dependency>
<groupId>com.aliyun.opensearch</groupId>
<artifactId>aliyun-sdk-opensearch</artifactId>
<version>4.0.0</version>
</dependency>関連リンク:バージョンガイド
コードデモ:
package com.example.opensearch;
import com.aliyun.opensearch.OpenSearchClient;
import com.aliyun.opensearch.SuggestionClient;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.nio.charset.Charset;
public class SuggestDemo {
static private final String accesskey = "ご利用の AccessKey 情報を入力します";
static private final String secret = "ご利用のシークレット情報を入力します";
static private final String host = "検索候補に関連付けられているアプリケーションが配置されているリージョンのホストを入力します";
OpenSearch openSearch;
OpenSearchClient openSearchClient;
static private final byte hits = 8; // 返される検索候補の最大数
static private final String suggestionName = "検索候補名を入力します"; // 検索候補名を入力します
@Before
public void setUp() {
// OpenSearch オブジェクトを初期化します
openSearch = new OpenSearch(accesskey, secret, host);
openSearchClient = new OpenSearchClient(openSearch);
}
@Test
public void TestEnv() {
// ファイルとデフォルトのエンコード形式を表示します
System.out.println(String.format("file.encoding: %s", System.getProperty("file.encoding")));
System.out.println(String.format("defaultCharset: %s", Charset.defaultCharset().name()));
// SuggestionClient オブジェクトを作成します
SuggestionClient suggestionClient = new SuggestionClient("app_name", suggestionName, openSearchClient);
String query = "検索クエリを入力します";
try {
SuggestParams suggestParams = new SuggestParams();
suggestParams.setQuery(query); // 検索クエリを設定します
suggestParams.setHits(10); // 返される検索候補の最大数を設定します
suggestParams.setUserId("12345678"); // user_id を設定します
// 中国語の同音異義語補完および取得機能はデフォルトで有効になっています。リクエストに re_search パラメーターを追加して、この設定を調整できます。
// ReSearch.findByValue(1) は機能を無効にします。ReSearch.findByValue(0) またはパラメーターを省略すると機能が有効になります。
suggestParams.setReSearch(ReSearch.findByValue(1));
SearchResult result = suggestionClient.execute(suggestParams);
System.out.println(result); // 取得結果を出力します
} catch (OpenSearchException e) {
e.printStackTrace();
} catch (OpenSearchClientException e) {
e.printStackTrace();
}
}
@After
public void clean() {
openSearch.clear();
}
}検索候補の Java SDK の詳細については、「検索候補デモ」をご参照ください。
取得結果の表示:
{
"request_id": "159851481919726888064081",
"searchtime": 0.006246,
"suggestions": [
{
"suggestion": "skirt fashion"
},
{
"suggestion": "skirt for petite dress"
},
{
"suggestion": "skirt polka dot dress"
},
{
"suggestion": "skirt youthful"
},
{
"suggestion": "skirt polka dot"
},
{
"suggestion": "skirt for petite"
},
{
"suggestion": "skirt for petite polka dot"
}
]
}注:取得結果で返される requestID は、検索リクエストを関連付けるために使用できます。
検索候補リクエストと検索リクエストの関連付け
検索候補リクエストと検索リクエストを関連付けることは、ビジネスに次の点で役立ちます。
候補によって誘導された検索のページビュー (PV)、誘導された検索のクリック率、および結果がほとんどまたはまったくない誘導された検索の割合など、検索に対する検索候補の効果を測定するためのメトリックを収集できます。これらのメトリックの詳細については、「検索候補レポート」をご参照ください。
関連付けられたリクエストデータに基づいて、検索候補のクリックなどのデータを取得できます。これにより、検索候補のソートモデルを最適化し、誘導された検索の効果を向上させることができます。
関連付け方法:
OpenSearch アプリケーションの検索リクエストで、リクエストが検索候補によって誘導された場合、パラメーター
from_request_id={from_request_id}を含めます。`from_request_id` は、検索リクエストのソースを示します。現在のクエリが検索候補、ホットクエリ、ヒントワードなどの機能からの推奨リストから来ている場合、その推奨リストの `request_id` をこのパラメーターに割り当てることができます。このガイダンスイベントを関連付けることで、アップストリーム機能のさまざまなメトリックを計算し、その有効性を測定し、最適化に役立つデータを取得できます。このパラメーターは、「検索処理ドキュメント」でも説明されています。
例:
検索候補 API クエリの結果からの requestID は 159851481919726888064081 です。この ID を検索リクエストに関連付けるには、次の例をご参照ください。
SearchParams searchParams = new SearchParams(config);
searchParams.setQuery("title:'skirt for petite'"); // 検索候補によって誘導
/// from_request_id パラメーターを追加します
Map<String, String> customParam =new HashMap<>();
customParam.put("from_request_id","159851481919726888064081");
searchParams.setCustomParam(customParam);
// クエリを実行し、データオブジェクトを返します
SearchResult execute = searcherClient.execute(searchParams);
// クエリデータを文字列として返します
String result = execute.getResult();
System.out.println(result);