本トピックでは、MaxCompute を基盤として Hologres へメタデータマッピングおよびデータ同期タスクを作成する方法について説明します。
背景情報
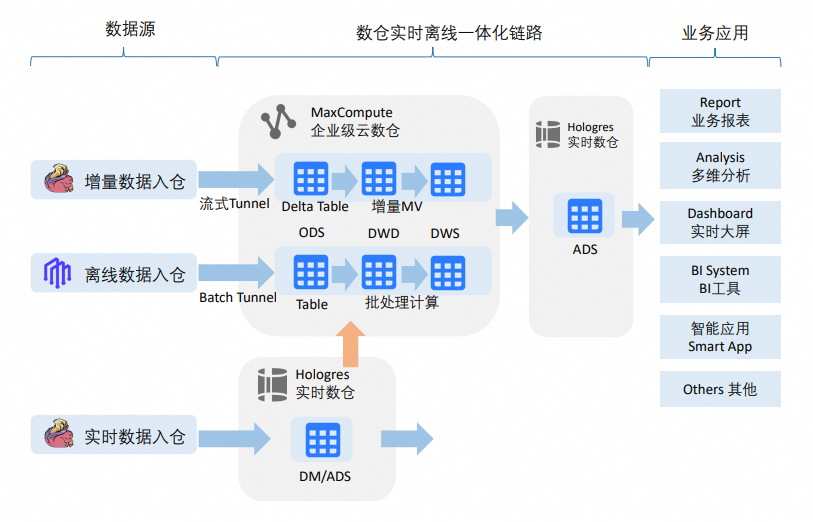
従来のデータウェアハウスアーキテクチャでは、上流のリアルタイムまたはバッチデータがデータウェアハウスに書き込まれ、オンライン分析処理(OLAP)エンジンで分析されます。このプロセスは、以下の図の上部に示されています。一方で、以下の図の下部に示すように、一部のシナリオでは MaxCompute から Hologres のデータを読み取る必要があります。具体的な例は以下のとおりです:
リアルタイムデータの公開およびアーカイブ:リアルタイムデータソースからのデータを、ビジネスアプリケーションに対して迅速に公開する必要があります。リアルタイムデータウェアハウスの要件が満たされた後、そのデータは企業レベルのデータウェアハウスの対応するレイヤーおよび主題領域へアーカイブされます。
ビジネス優先アプローチおよびデータ逆流:データウェアハウスを通じた統一的な処理を経ずに、まずビジネス要件を満たします。その後、データマートが安定化した段階で、データを企業レベルのデータウェアハウスへ逆流させ、DWD レイヤーおよび DWS レイヤーと統合する必要があります。
これらの 2 つのシナリオにおけるデータアクセス方法は以下のとおりです:
データウェアハウスモデルの反復および改善中に、リアルタイムデータウェアハウスのデータを閲覧する。
リアルタイムデータウェアハウスまたはデータマートから、定期的にデータを企業レベルのデータウェアハウスへアーカイブする。
企業レベルのデータウェアハウスで処理されたデータを、ビジネス消費用に Hologres の ADS レイヤーへ書き込む。
機能概要
本チュートリアルでは、MaxCompute から Hologres へメタデータマッピングパイプラインを構築する手順を紹介します。以下の特徴を備えています:
スキーマレベルのメタデータマッピング: RAM ロール認証を使用して、外部スキーマ経由で Hologres のメタデータおよびデータをリアルタイムで読み取り、スキーマレベルでのデータアクセスを実現します。
単一テーブルレベルのメタデータマッピング: Hologres のデータカタログからテーブルを選択し、ワンクリックで Hologres テーブルに対応する MaxCompute 外部テーブルを自動的に作成できます。
データ同期: 定期的な同期が必要なテーブルを、ワンクリックでデータ同期タスクとして設定できます。これにより、データを企業レベルのデータウェアハウスへ定期的に同期する要件を満たします。
MaxCompute と Hologres の間でデータの型のマッピングは異なります。一部の Hologres のデータの型は MaxCompute へ同期できません。詳細については、「MaxCompute と Hologres の間のデータの型のマッピング」をご参照ください。
データ同期ワークフロー
本チュートリアルは、Flink および Hologres を使用して構築されたリアルタイムデータウェアハウスを基盤としています。Hologres リアルタイムデータウェアハウスの DWD レイヤーにおいて、MaxCompute から Hologres のスキーマおよびテーブルへのマッピングと、DWD レイヤー内のテーブルからのデータ同期を実行するプロセスが追加されています。以下の図に、このプロセスの詳細を示します。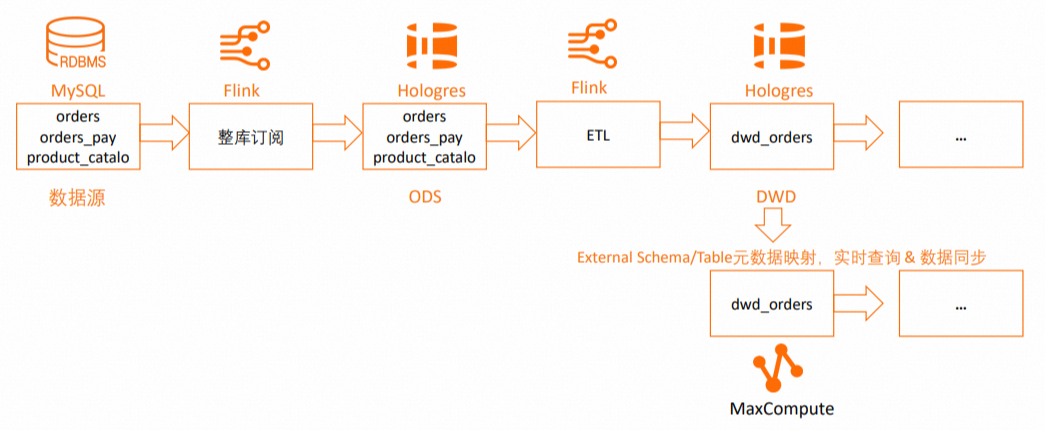
サポートされる機能:
外部スキーマを使用した Hologres スキーマへのマッピング。
外部テーブルを使用した Hologres テーブルへのマッピング。
Hologres テーブルを対象とした 1 回限りまたは定期的なデータ同期の指定。
操作手順
前提条件
RAM ロールを作成済みであること、および信頼ポリシーを設定済みであること。
RDS を有効化済みであること。
Hologres を有効化しました。
Flink を有効化しました。
ステップ 1:ApsaraDB RDS for MySQL インスタンスの作成およびデータソースの準備
ApsaraDB RDS for MySQL インスタンス、Hologres インスタンス、および Flink インスタンスは、同一のリージョンおよび同一のゾーンに配置され、同一の VPC を使用する必要があります。
Realtime Compute コンソールでは、ネットワーク接続診断機能を使用して、Flink ワークスペースと ApsaraDB RDS for MySQL インスタンスおよび Hologres インスタンス間のネットワーク接続を確認できます。詳細については、「ネットワーク接続診断の実行方法」をご参照ください。
RDS コンソールにログインします。
左側のナビゲーションウィンドウで、インスタンスをクリックします。その後、左上隅からリージョンを選択します。
インスタンス一覧ページで、インスタンスの作成をクリックします。
本例では、課金方法を「従量課金」に、データベースエンジンを「MySQL 8.0」に設定します。
インスタンス一覧ページで、対象インスタンスのインスタンス ID/名前をクリックして、詳細ページを開きます。
左側のナビゲーションウィンドウで、アカウント > をクリックします。
データベースログインアカウントを作成します。
左側のナビゲーションウィンドウで、データベースをクリックします。
データベースの作成をクリックし、以下のパラメーターを設定します:
パラメーター
必須
説明
例
データベース名
必須
長さ:2~64 文字。
先頭は英字で始まり、末尾は英字または数字で終わる必要があります。
小文字の英字、数字、アンダースコア(_)、ハイフン(-)のみ使用可能です。
インスタンス内で一意である必要があります。
データベース名に
-が含まれる場合、作成されたデータベースフォルダーの名前にある-は@002dに変換されます。
hologres_test権限付与元
任意
標準アカウントのみが表示されます。特権アカウントはすべてのデータベースに対して完全な権限を持ち、権限付与は不要です。
先ほど作成したログインアカウントを選択します。データベースへのログインをクリックします。左側のナビゲーションウィンドウで、データベースインスタンスを選択します。作成したデータベースをダブルクリックし、SQLConsole ページで、以下のステートメントを実行してテストテーブルを作成し、テストデータを書き込みます。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- テストデータを準備します。 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
ステップ 2:Hologres インスタンスおよびデータベースの作成
Hologres 管理コンソールにログインし、左上隅からリージョンを選択します。
インスタンスがない場合は、まずHologres インスタンスを購入します。
製品タイプとして、排他的インスタンス(従量課金)を選択します。
仕様として、コンピュートグループタイプを選択します。
仮想ウェアハウスの予約コンピューティングリソース:64 CUs を選択します。
インスタンスページで、対象インスタンス名をクリックします。
インスタンス詳細ページで、インスタンスへの接続をクリックします。
上部のタブから、メタデータ管理をクリックします。
データベースの作成をクリックします。表示されるダイアログボックスで、データベース名を入力し、他のパラメーターはデフォルト設定のままにします。
本例では、Hologres データベースの名前を
holodbとします。上部のタブから、セキュリティセンターをクリックします。
左側のナビゲーションウィンドウで、ユーザー管理を選択します。
ステップ 3:Flink における ApsaraDB RDS for MySQL の全データベース同期タスクの作成(ODS レイヤー)
Flink で ApsaraDB RDS for MySQL の全データベース同期タスクを作成し、ApsaraDB RDS for MySQL から Hologres データベース
holodbのpublicスキーマへデータを同期します。その後、Hologres のデフォルトコンピュートグループinit_warehouseを使用して ODS データをクエリできます。事前に MySQL のバイナリログを有効化する必要があります。ApsaraDB RDS for MySQL データベースで
show variables like "log_bin";コマンドを実行し、バイナリログが有効化されているか確認できます。詳細については、「MySQL サーバーの構成要件」をご参照ください。セッションクラスターを作成します。
Flink コンソールにログインし、左上隅からリージョンを選択します。
対象ワークスペース名をクリックします。左側のナビゲーションウィンドウで、を選択します。
セッションクラスターの作成をクリックします。
Hologres カタログを作成します。
対象ワークスペース名をクリックします。左側のナビゲーションウィンドウで、カタログ を選択します。
カタログ一覧ページで、カタログの作成をクリックします。カタログの作成ダイアログボックスで、Hologres を選択し、次へをクリックして、以下のパラメーターを設定します:
パラメーター
必須
説明
カタログ名
必須
MySQL カタログ名をカスタマイズできます。
エンドポイント
必須
VPC の選択のエンドポイントは、Hologres インスタンスの詳細ページのネットワーク情報セクションから取得できます:
hg****cn-cn-2****f-cn-shenzhen-vpc-st.hologres.aliyuncs.com:80。dbname
必須
Hologres データベースの名前。
username
必須
AccessKey ID。
password
必須
AccessKey Secret。
MySQL カタログを作成します。
カタログ一覧ページで、カタログの作成をクリックします。カタログの作成ダイアログボックスで、MySQL を選択し、次へをクリックして、以下のパラメーターを設定します:
パラメーター
必須
説明
カタログ名
必須
MySQL カタログのカスタム名。
ホスト名
必須
MySQL データベースの IP アドレスまたはホスト名。
ApsaraDB RDS for MySQL コンソールにログインし、データベースインスタンスの詳細ページで、データベース接続をクリックすると、内部エンドポイント、パブリックエンドポイント、および内部ポートを確認できます。
VPC 間またはインターネット経由でのアクセスには、ネットワーク接続を確立する必要があります。詳細については、「ネットワーク接続」をご参照ください。
ポート
デフォルト
サーバーへの接続に使用するポート。デフォルト値は 3306 です。
デフォルトデータベース
必須
デフォルトデータベースの名前。
ユーザー名
必須
MySQL データベースサーバーへの接続に使用するユーザー名。ApsaraDB RDS for MySQL コンソールにログインし、データベースインスタンスの詳細ページで、アカウントをクリックすると、ユーザー名を確認できます。
パスワード
必須
MySQL データベースサーバーに接続するために使用するパスワードです。 ApsaraDB RDS for MySQL コンソール にログインできます。データベースインスタンスの詳細ページで、[アカウント] をクリックしてパスワードを表示します。
Flink を使用して ApsaraDB RDS for MySQL から Hologres へデータを同期します。
対象ワークスペース名をクリックし、左側のナビゲーションウィンドウで、を選択します。
下書きタブで、
 をクリックして新しいフォルダーを作成します。
をクリックして新しいフォルダーを作成します。フォルダーを右クリックし、新規空白ストリーム下書きを選択します。新規下書きダイアログボックスで、名前を入力し、エンジンバージョンを選択します。
CREATE DATABASE IF NOT EXISTS <your hologres catalog>.<hologres database name> -- カタログ作成時に table_property.binlog.level パラメーターが設定されているため、CDAS を使用して作成されたすべてのテーブルでバイナリログが有効化されます。 AS DATABASE <your mysql catalog>.<mysql database name> INCLUDING all tables -- データウェアハウスへ取り込む上流データベースのテーブルを選択できます。 /*+ OPTIONS('server-id'='8001-8004') */ ; -- MySQL CDC インスタンスの server-id 範囲を指定します。右上隅のデプロイをクリックします。
デプロイメントページで、対象ジョブの名前をクリックして、構成ページを開きます。
対象ジョブのデプロイメント詳細ページの右上隅で、開始をクリックし、初期モードを選択して、開始をクリックします。
説明デフォルトでは、本例では Hologres データベースの public スキーマへデータを同期します。また、宛先の Hologres データベース内に指定したスキーマへデータを同期することもできます。詳細については、「CDAS の宛先カタログとしての利用」をご参照ください。スキーマを指定した場合、カタログを使用した際のテーブル名形式も変更されます。詳細については、「Hologres カタログの使用」をご参照ください。
ソーステーブルのデータ構造が変更された場合、ソーステーブルで削除、挿入、更新などのデータ変更が発生するまで、構造変更は結果テーブルには反映されません。
ステップ 4:Hologres へのデータのロード
テーブルグループは Hologres 内でデータを格納します。
holodb データベース内のテーブルグループ(例: order_dw_tg_default)のデータを、コンピュートグループ init_warehouse を使用してクエリするには、まずそのテーブルグループをコンピュートグループにロードする必要があります。その後、init_warehouse コンピュートグループを使用してデータのクエリおよび書き込みが可能になります。
HoloWeb 開発ページで、SQL エディターをクリックし、インスタンス名およびデータベース名を確認したうえで、以下のコマンドを実行します。
詳細については、「新規仮想ウェアハウスインスタンスの作成」をご参照ください。
Hologres 管理コンソールにログインし、左上隅からリージョンを選択します。
左側のナビゲーションウィンドウで、インスタンスを選択します。
インスタンスページで、対象インスタンス名をクリックします。
インスタンス詳細ページで、インスタンスへの接続をクリックします。
上部のタブから、SQL エディターをクリックします。
インスタンスおよびデータベース名を確認し、以下のコマンドを実行します。データがロードされた後、コンピュートグループが
holodb_tg_defaultテーブルグループからデータをロードしたことが確認できます。-- 現在のデータベース内のテーブルグループを表示します。 SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; -- テーブルグループをコンピュートグループにロードします。 CALL hg_table_group_load_to_warehouse ('<hologres database name>.<table group name>', '<your Virtual Warehouse name>', 1); -- テーブルグループのコンピュートグループへのロード状況を表示します。 SELECT * FROM hologres.hg_warehouse_table_groups;以下のコマンドを実行して、MySQL から Hologres へ同期された 3 つのテーブルのデータを表示します。
--- orders テーブルのデータをクエリします。 SELECT * FROM orders; --- orders_pay テーブルのデータをクエリします。 SELECT * FROM orders_pay; --- product_catalog テーブルのデータをクエリします。 SELECT * FROM product_catalog;
ステップ 5:Flink における DWD レイヤーのテーブルの作成
Hologres コネクタがサポートする特定カラムの更新機能を使用して、DWD レイヤーを構築します。INSERT ステートメントを使用することで、効率的な部分更新を実行できます。Hologres の列指向データストレージおよびハイブリッド行・列指向データストレージによる高性能なポイントクエリにより、さまざまなディメンションテーブルのデータをクエリできます。Hologres は強力なリソース隔離アーキテクチャを採用しており、書き込み、読み取り、分析ワークロード間の干渉を防止します。
Flink カタログ機能を使用して、Hologres の DWD レイヤーにワイドテーブル dwd_orders を作成します。
Flink コンソールにログインし、左上隅からリージョンを選択します。
対象ワークスペース名をクリックし、左側のナビゲーションウィンドウで、を選択します。
新規スクリプトタブで、
 をクリックして新しいクエリスクリプトを作成できます。
をクリックして新しいクエリスクリプトを作成できます。以下のコードを入力した後、右上隅の実行をクリックします。
-- ワイドテーブルのフィールドは NULL 許容とする必要があります。異なるストリームが同じ結果テーブルに書き込むため、各カラムには NULL 値が含まれる可能性があります。 CREATE TABLE <hologres catalog>.<hologres database>.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'プラットフォーム 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- カタログを介して Hologres の物理テーブルプロパティを変更します。 ALTER TABLE <hologres catalog>.<hologres database>.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' -- バイナリログのタイムアウトを 1 週間に設定します。 );運用データストア(ODS)レイヤーの
ordersテーブルおよびorders_payテーブルから、リアルタイムでバイナリログを消費します。対象ワークスペース名をクリックし、左側のナビゲーションウィンドウで、を選択します。
DWD という SQL ストリームジョブを作成します。以下のコードを SQL エディターにコピーし、デプロイおよび開始します。
ordersテーブルはproduct_catalogディメンションテーブルと結合され、その結果がリアルタイムデータエンリッチメントのためにdwd_ordersテーブルへ書き込まれます。BEGIN STATEMENT SET; INSERT INTO <your hologres catalog name>.<your hologres database name>.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM <your hologres catalog name>.<your hologres database name>.orders as o LEFT JOIN <your hologres catalog name>.<your hologres database name>.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; INSERT INTO <your hologres catalog name>.<your hologres database name>.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM <your hologres catalog name>.<your hologres database name>.orders_pay; END;ワイドテーブル
dwd_ordersのデータを表示します。Hologres インスタンスに接続し、HoloWeb 開発者ページで対象データベースにログインした後、SQL エディターで以下のコマンドを実行します。
SELECT * FROM dwd_orders;以下のような結果が返されます:
+------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+ | order_id | order_user_id | order_shop_id | order_product_id | order_product_catalog_name | order_fee | order_create_time | order_update_time | order_state | pay_id | pay_platform | pay_create_time | +------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+ | 100002 | user_002 | 12346 | 2 | phone_bbb | 4000.04 | 2023-02-15 15:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100004 | user_001 | 12347 | 4 | phone_ddd | 2000.02 | 2023-02-15 13:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 11111 | user_test | 12346 | 2 | phone_bbb | 4000.04 | 2025-12-15 00:00:00 | 2025-12-15 00:00:00 | 1 | NULL | NULL | NULL | | 100001 | user_001 | 12345 | 1 | phone_aaa | 5000.05 | 2023-02-15 16:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100007 | user_003 | 12347 | 4 | phone_ddd | 2000.02 | 2023-02-15 10:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100006 | user_001 | 12348 | 1 | phone_aaa | 1000.01 | 2023-02-15 11:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100005 | user_002 | 12348 | 5 | phone_eee | 1000.01 | 2023-02-15 12:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | | 100003 | user_003 | 12347 | 3 | phone_ccc | 3000.03 | 2023-02-15 14:40:56 | 2023-02-15 18:42:56 | 1 | NULL | NULL | NULL | +------------+---------------+---------------+------------------+----------------------------+------------+-------------------+-------------------+-------------+------------+--------------+-----------------+
DataWorks で MaxCompute プロジェクトと Hologres インスタンスを関連付けます。
MaxCompute に戻り、外部スキーマを作成します。
ステップ 6:DataWorks における MaxCompute および Hologres の計算リソースの関連付け
DataWorks コンソールにログインし、左上隅からリージョンを選択します。
DataWorks ワークスペースを作成します。本チュートリアルでは、ワークスペースの名前を
Hologres_DW_TESTとします。ワークスペースページで、対象ワークスペース名をクリックします。
ワークスペースの詳細ページで、左側のナビゲーションウィンドウからコンピューティングリソースをクリックします。
コンピューティングリソースページで、計算リソースの関連付けをクリックし、MaxComputeおよびHologresを選択します。
基本情報を入力します。詳細については、「計算リソースの関連付け」をご参照ください。
MaxCompute プロジェクトおよび Hologres インスタンスの追加および表示を行います。
左側のナビゲーションウィンドウで、を選択します。
ワークスペースを選択するセクションで、DataStudio へ移動をクリックします。
MaxCompute プロジェクトおよび Hologres インスタンスの追加および表示を行います。
ステップ 7:Hologres スキーマにマッピングされる MaxCompute 外部スキーマの作成
外部スキーマを使用して Hologres テーブルをマッピングする場合、MaxCompute でデータ定義言語(DDL)メタデータを含むテーブルを作成する必要はありません。Hologres のソーステーブルの構造またはデータの変更は検出され、MaxCompute でリアルタイムにクエリできます。
MaxCompute コンソールにログインし、左上隅からリージョンを選択します。
左側のナビゲーションウィンドウで、を選択します。
外部データソースページで、外部データソースの作成をクリックします。
外部データソースの追加ダイアログボックスで、パラメーターを設定します。以下の表にパラメーターを示します。
パラメーター
必須
説明
外部データソースタイプ
必須
Hologres を選択します。
外部データソース名
必須
カスタマイズ可能な名前。命名規則:
先頭は英字で始まり、小文字の英字、アンダースコア(_)、数字のみ使用可能です。
最大長:128 文字。
例:
holo_external_source。外部データソースの説明
任意
必要に応じて入力します。
接続モード
必須
デフォルトはクラシックネットワークアクセス (イントラネット)です。
InstanceID
必須
現在のリージョンで接続する Hologres インスタンスを選択します。
Host
必須
システムにより自動生成されます。
Port
必須
システムにより自動生成されます。
DBNAME
必須
接続先の Hologres データベースの名前。
認証と認可
必須
クラウドRAMロール
タスク実行者:Hologres 外部プロジェクトの外部データソースは、タスク実行者認証モードを使用するように設定する必要があります。
RoleARN
必須
RAM ロールの ARN。
左側のナビゲーションウィンドウで、を選択します。
基本情報セクションで、ARN を確認できます。
例:
acs:ram::124****:role/aliyunodpsdefaultrole。関連サービスの役割
必須
タスク実行者を選択した場合、関連サービスの役割は
acs:ram::124****:role/aliyunserviceroleformaxcomputeidentitymgmtです。外部データソースの追加プロパティ
任意
外部データソースの追加属性。これらを指定すると、この外部データソースを使用するジョブは、定義された動作に従ってソースシステムにアクセスします。
説明サポートされるパラメーターについては、今後の公式ドキュメントの更新をご確認ください。パラメーターは、製品機能の進化に伴い段階的にリリースされます。
ステップ 8:DataWorks における Hologres インスタンスおよび MaxCompute スキーマのマッピング
DataWorks コンソールにログインし、左上隅からリージョンを選択します。
左側のナビゲーションウィンドウで、を選択します。
ワークスペースを選択するセクションで、DataStudio へ移動をクリックします。
DataStudio ページで、左側のナビゲーションウィンドウの
 アイコンをクリックして、Data CATALOG を開きます。
アイコンをクリックして、Data CATALOG を開きます。Hologres データカタログを展開し、対象インスタンスのスキーマ(本チュートリアルでは
public)を右クリックし、MaxCompute へのメタデータマッピングを選択します。MaxCompute へのメタデータマッピングページで、Hologres ソースおよび MaxCompute ターゲットのパラメーターを設定します。
本チュートリアルにおける主要なパラメーター設定は以下のとおりです。その他のパラメーターはデフォルト値のままにしてください。
パラメーター名
説明
プロジェクト検索方法
DataWorks データソースからを選択します。
データソース
DataWorks に関連付けられた MaxCompute 計算リソースの名前を選択します。
外部スキーマ名
ソース Hologres スキーマのメタデータをマッピングする MaxCompute の外部スキーマの名前を指定します。
本チュートリアルでは、
publicと設定します。外部データソース
MaxCompute で作成された Hologres フェデレーテッドデータソースの名前を選択します。
本チュートリアルでは、
holo_external_sourceです。ページ左上隅の実行をクリックします。
タスクが実行されると、Hologres スキーマと同じ名前(public)の MaxCompute 外部スキーマが作成されます。
以下の SQL コマンドを実行して、Hologres のテーブルを閲覧し、MaxCompute でデータをクエリできます。
SET odps.namespace.schema=true; SELECT * FROM public.dwd_orders;
スキーマレベルのマッピングは成功しているものの、Data Catalog の MaxCompute フォルダーにマッピングされたテーブル名が表示されず、クエリが失敗する場合は、RAM ロールの権限設定が正しく行われているか確認してください。詳細については、「Hologres 外部テーブル」をご参照ください。
外部スキーマとは異なり、外部テーブルでは、Hologres のテーブルを MaxCompute の外部テーブルとして明示的に作成する必要があります。外部テーブルは、RAM ロールおよび二重署名の 2 種類の認証方式をサポートします。
RAM ロール:クロスアカウントロールの引き受けをサポートします。Hologres 側で以下の操作を完了する必要があります:
二重署名:現在のタスク実行者の ID を使用して認証を行います。つまり、現在のユーザーは、Hologres のテーブルに対する権限を持つ同一の ID を使用して、MaxCompute の外部テーブルを介して Hologres のデータにアクセスできます。詳細については、「Hologres 外部テーブル」をご参照ください。
ステップ 9:Hologres テーブルにマッピングされる MaxCompute 外部テーブルの作成
一部またはすべてのフィールドをマッピングできます。マッピングルールの詳細については、「Hologres 外部テーブル」のtblproperties パラメーターのセクションをご参照ください。
DataWorks コンソールにログインし、左上隅からリージョンを選択します。
左側のナビゲーションウィンドウで、を選択します。
ワークスペースを選択するセクションで、DataStudio へ移動をクリックします。
DataStudio ページで、左側のナビゲーションウィンドウの
アイコンをクリックして、Data CATALOG を開きます。Hologres データカタログを展開し、対象インスタンスの
dwd_ordersテーブル(publicスキーマ内)を右クリックし、MaxCompute へのメタデータマッピングを選択します。MaxCompute へのメタデータマッピングページで、Hologres ソースおよび MaxCompute 宛先のパラメーターを設定します。
本チュートリアルにおける主要なパラメーター設定は以下のとおりです。その他のパラメーターはデフォルト値のままにしてください。パラメーターの詳細については、「テーブルレベルのメタデータマッピング」をご参照ください。
パラメーター名
説明
インスタンス検索方法
DataWorks データソースからを選択します。
データソース
DataWorks に関連付けられた MaxCompute データソースの名前を選択します。
スキーマ
ソース Hologres スキーマのメタデータをマッピングする MaxCompute の外部スキーマの名前を指定します。
本チュートリアルでは、
defaultと設定します。外部テーブル
MaxCompute で作成する外部テーブルの名前を指定します。ソーステーブルのデータはこのテーブルにマッピングされます。デフォルトでは、外部テーブルの名前は Hologres のテーブルと同じになります。
外部テーブルの作成は 1 回限りの操作であり、メタデータは自動的に更新されません。メタデータを更新するには、現在の外部テーブルを削除し、手動で再度メタデータマッピングを作成する必要があります。
MaxCompute 外部テーブルへのアクセス権限
二重署名を選択します。
RAM ロール方式を使用する場合、Hologres 側でユーザーを追加し、データベース権限を付与する必要があります。
ライフサイクル
テーブルのライフサイクルを設定します。
ページ左上隅の実行をクリックします。
タスクが実行されると、新しい外部テーブルが左側のナビゲーションウィンドウの MaxCompute スキーマ配下に表示されます。
以下のステートメントを実行して、この外部テーブルのデータを MaxCompute でクエリできます。
SET odps.namespace.schema=true; SELECT * FROM dwd_orders;
ステップ 10:Hologres テーブルの定期的な同期タスクの作成
Hologres リアルタイムデータウェアハウスの DWD テーブルのデータを、MaxCompute の内部テーブルへ定期的にアーカイブするには、データ同期タスクを作成し、定期的なスケジュールを設定します。
DataWorks コンソールにログインし、左上隅からリージョンを選択します。
左側のナビゲーションウィンドウで、を選択します。
ワークスペースを選択するセクションで、DataStudio へ移動をクリックします。
DataStudio ページで、左側のナビゲーションウィンドウの
 アイコンをクリックして、DATA DTUDIO ページを開きます。その後、「新規プロジェクトフォルダーの作成」を行います。
アイコンをクリックして、DATA DTUDIO ページを開きます。その後、「新規プロジェクトフォルダーの作成」を行います。DataStudio ページで、左側のナビゲーションウィンドウの
アイコンをクリックして、Data CATALOG を開きます。Hologres データカタログを展開し、対象インスタンスの
dwd_ordersテーブル(publicスキーマ内)を右クリックし、MaxCompute へのデータ同期を選択します。MaxCompute へのメタデータマッピングページで、Hologres ソースおよび MaxCompute 宛先のパラメーターを設定できます。
本チュートリアルにおける主要なパラメーター設定は以下のとおりです。その他のパラメーターはすべてデフォルト値を使用できます。パラメーターの詳細については、「単一テーブルのメタデータマッピング」をご参照ください。
「[ノードの作成]」ダイアログボックスで、クラウドデータウェアハウス内のテーブルに
dwd_holo_ordersという名前を付け、「[OK]」をクリックします。Hologres データを MaxCompute に同期するための構成ページで、Hologres のソースと MaxCompute の宛先のパラメーターを設定します。本チュートリアルにおける主要なパラメーター設定は以下のとおりです。パラメーターの詳細については、「同期ノードの構成」をご参照ください。
パラメーター名
説明
データソース
DataWorks に関連付けられた Hologres データソースの名前を選択します。
スキーマ
データを格納するスキーマを選択します。
テーブル
MaxCompute 内部テーブルの名前を指定します。
本チュートリアルでは、
dwd_holo_ordersと設定します。ライフサイクル
テーブルのライフサイクルを設定します。
インポート方法
MaxCompute 内部テーブルへデータを書き込む方法を選択します。
上書き:元のデータを削除して新しいデータをターゲットテーブルに書き込む必要がある場合は、上書き方法を選択できます。
追加:既存のデータを保持し、新しいデータをターゲットテーブルに追加します。
Hologres へのアクセス権限
必要に応じて、以下のいずれかの方法で Hologres インスタンスにアクセスできます。
二重署名:現在の ID を使用して Hologres の権限検証を実行します。
現在の ID が MaxCompute テーブルに対する読み取り権限と、MaxCompute テーブルにマッピングされている Hologres ソーステーブルに対する権限を持っていることを確認してください。
RAM ロール:RAM ロールを指定してアクセスを認証します。
RAM ユーザーに
AliyunSTSAssumeRoleAccessアクセスポリシーを付与します。詳細については、「RAM ロールの権限付与パターン」をご参照ください。承認が完了したら、[RamRole] フィールドに指定された RAM ロールを設定します。
右側のパネルで [スケジューリング] をクリックします。[プロパティ] ページで、ワークフローとスケジューリング周期を設定します。詳細については、「ノードスケジューリング設定」をご参照ください。
ページの左上隅の[実行]をクリックします。
タスクが正常に実行されると、新しく作成された内部テーブルが左側のナビゲーションウィンドウの MaxCompute 配下に表示されます。以下の SQL ステートメントを使用して、このテーブルのデータを MaxCompute でクエリできます。
SET odps.namespace.schema=true; SELECT * FROM default.dwd_holo_orders;