MaxCompute はスキーマをサポートしています。スキーマを使用すると、プロジェクト内でテーブル、リソース、関数などのオブジェクトをより細かい粒度で管理できます。このトピックでは、スキーマの概念、関連する権限、およびその使用方法について説明します。
背景情報
MaxCompute プロジェクトは基本的な組織単位であり、マルチユーザー間の隔離とアクセスの制御における主要な境界です。
プロジェクトには、テーブル、リソース、関数などのオブジェクトが含まれます。以前は、これらのオブジェクトがプロジェクト直下に配置されており、プロジェクトが従来のデータベースと同様にデータベースまたはスキーマとして機能する必要がありました。この二重の役割により、概念が不明確になり、特に多数のテーブルやオブジェクトを含むプロジェクトでは使い勝手が悪くなっていました。MaxCompute では現在、スキーマがサポートされており、プロジェクト内のテーブル、リソース、関数を分類できるようになっています。階層構造を次の図に示します。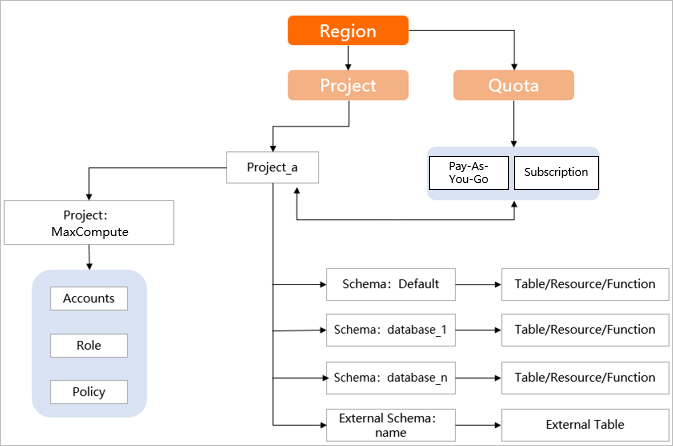
適用範囲
MaxCompute のスキーマ機能は継続的に改善されています。一部の既存の機能モジュールはまだこの機能に対応していません。これらのモジュールから MaxCompute に対して実行される操作は、set odps.namespace.schema=false モードでのみ使用できます。
開発ツール
MaxCompute クライアント v0.40.8 以降 はスキーマ機能をサポートしています。
MaxCompute Studio プラグイン 4.0.0 以降 はスキーマ機能をサポートしています。
ジョブの種類
Spark ジョブ 3.1.1 以降 はスキーマ機能をサポートしています。
Spark ジョブでは、次のパラメーターを設定してください。
spark.sql.catalog.odps.enableNamespaceSchema=trueMars および MapReduce ジョブは スキーマ機能をサポートしていません。
他のクラウドプロダクト
Hologres V1.3 以降 はスキーマ機能をサポートしています。Hologres インスタンスをスペックアップする方法については、「インスタンスのスペックアップ」をご参照ください。
PAI や Quick BI などの他のクラウドプロダクトは、カスタムスキーマ機能をサポートしていません。
Java SDK 0.40.8 以降、Java Database Connectivity (JDBC) 3.3.2 以降、および PyODPS 0.11.3.1 以降はスキーマ機能をサポートしています。
DataWorks は、テナントレベルまたはプロジェクトレベルでスキーマ機能を有効にした後でのみ、MaxCompute のスキーマと連携できます。詳細については、「DataWorks による MaxCompute スキーマのサポート」をご参照ください。
odps.namespace.schema=falseモードで作成されたビューおよびユーザー定義関数 (UDF) は、同じモードでのみアクセスできます。odps.namespace.schema=trueモードについても同様のルールが適用されます。
主な用語
スキーマ
スキーマは、プロジェクト内でテーブル、リソース、UDF を分類するために使用されるオブジェクトです。1 つのプロジェクトに複数のスキーマを含めることができます。
スキーマ構文スイッチ
スキーマ構文スイッチを有効にすると、システムは
project.schema.tableのセマンティクスを解析してスキーマ機能を使用できるようになります。スキーマ構文が有効な場合、
a.b.c形式の文はproject.schema.tableとして解析されます。a.b形式の文はschema.tableとして解析されます。スキーマ構文が無効な場合、
a.b.c形式の文は認識されません。a.b形式の文はproject.tableとして解析されます。このスイッチは、テナントレベルおよびジョブレベルで設定できます。
デフォルトスキーマ
スキーマ機能を使用するプロジェクトでは、各プロジェクトに DEFAULT という名前の組み込みスキーマが作成されます。このスキーマは削除できません。
テナントレベル設定
テナント全体から送信されるデータアクセスリクエストのデフォルトのセマンティクスを決定します。
ジョブレベル設定
この設定は現在のジョブのセマンティクスにのみ影響し、テナントレベル設定よりも優先度が高くなります。
set odps.namespace.schema=true | false;コマンドを実行して、スキーマ構文を有効または無効にできます。
機能の有効化
MaxCompute を初めて使用し、既存のプロジェクトがない場合は、テナントレベルの構文スイッチを有効にしてください。有効化後、すべての新規プロジェクトでスキーマ機能がサポートされるようになります。また、すべてのリクエストがデフォルトで
odps.namespace.schema = true構文に基づいて解析されます。MaxCompute コンソール にログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
テナント管理 ページで、テナントプロパティ タブをクリックします。
テナントプロパティ タブで、テナントレベルの情報スキーマ構文 を有効にします。
既存のプロジェクトが 10 個以下で、既存のジョブがほとんどない、または存在しない場合は、次の手順に従って環境をスキーマ機能に対応させてください。対応後、新規プロジェクトでスキーマ機能がサポートされるようになり、すべてのリクエストがデフォルトで
odps.namespace.schema=true構文に基づいて解析されます。まず、すべての既存プロジェクトをアップグレードしてスキーマをサポートさせます。
MaxCompute コンソール にログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
プロジェクト管理 ページで、対象のプロジェクトを見つけ、操作 列の スキーマレベルをサポートするためのアップグレード をクリックします。
次に、テナントレベルの情報スキーマ構文 を有効にします。
左側のナビゲーションウィンドウで、 を選択します。
テナント管理 ページで、テナントプロパティ タブをクリックします。
テナントプロパティ タブで、テナントレベルの情報スキーマ構文 を有効にします。
既存のプロジェクトおよびジョブがあり、新しいビジネス要件のために特定のプロジェクトをアップグレードしてスキーマ機能をサポートさせる必要がある場合は、次の手順に従ってください。アップグレード後、プロジェクト内にデフォルトで
Schemaという名前でDEFAULTが作成されます。MaxCompute コンソール にログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
プロジェクト管理 ページで、対象のプロジェクトを見つけ、操作 列の スキーマレベルをサポートするためのアップグレード をクリックします。
すべてのリクエストはデフォルトで
odps.namespace.schema = false構文に基づいて解析されます。アップグレード済みのプロジェクトでカスタムスキーマを作成した後は、カスタムスキーマ内のデータにアクセスするために、ジョブレベルでset odps.namespace.schema=true;を実行してスキーマ構文を有効にする必要があります。
スキーマ構文が有効な場合、アップグレードされていないプロジェクトのデータパスは
projectname.default.tablenameになります。スキーマ構文が無効な場合、アップグレード済みのプロジェクトはカスタムスキーマにアクセスできません。
projectname.tablenameパスは、Schemaという名前のDEFAULT内のデータのみを認識します。
注意事項
プロジェクトの作成
スキーマを使用する前に、MaxCompute プロジェクトを作成する必要があります。
MaxCompute コンソール でプロジェクトを作成する際、テナントレベルの構文スイッチが有効 (
odps.namespace.schema = true) になっている場合、プロジェクトはデフォルトでスキーマをサポートします。
スキーマの管理
コマンドを使用したスキーマの管理
スキーマの一覧を表示
SHOW schemas;スキーマの作成
CREATE schema <schema_name>;schema_name は、カスタムスキーマの名前を指定します。
スキーマ情報の表示
DESC schema <schema_name>;schema_name は、スキーマの名前を指定します。
スキーマの削除
DROP schema <schema_name>;schema_name は、スキーマの名前を指定します。
管理コンソールを使用したスキーマの管理
MaxCompute コンソール にログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
プロジェクト管理 ページで、対象のプロジェクトを見つけ、操作 列の 管理 をクリックします。
プロジェクト設定 ページで、Schema タブを選択します。
Schema タブは、スキーマをサポートするプロジェクトでのみ表示されます。
Schema タブでは、スキーマの一覧を表示したり、スキーマを作成または削除したりできます。
スキーマ内のオブジェクトの操作
project.schema.table 形式のコマンドを編集できます。
このトピックでテーブルオブジェクトについて記述されている内容は、ビュー、リソース、関数オブジェクトにも適用されます。
プロジェクト間でテーブルを操作する場合は、完全なコマンド形式 project.schema.table を使用する必要があります。
同一プロジェクト内でスキーマ間の操作を行う場合は、
schema.table形式を使用できます。a.b形式のコマンドの場合、aはスキーマとして、bはテーブルとして解析され、プロジェクトは現在のプロジェクトになります。同一プロジェクト内で、
use schema <schema_name>コマンドを実行して現在のスキーマを指定できます。その後、select * from aのようなコマンドを直接使用できます。この場合、aはテーブルであり、自動的に現在のプロジェクトおよび指定されたスキーマに解決されます。コンテキストでスキーマが指定されておらず、
select * from aのようなコマンドを使用する場合、aはテーブルです。これは自動的に現在のプロジェクトおよび default という名前のスキーマに解決されます。
例
例 1:同一プロジェクト (projectA) 内のスキーマでオブジェクトを操作する
default スキーマ内のオブジェクトを操作する
use projectA; set odps.namespace.schema=true;-- テナントレベルで設定されている場合は、ここで指定する必要はありません。 -- テーブル t_a の操作 create table t_a(c1 string,c2 bigint); INSERT OVERWRITE TABLE t_a VALUES ('a',1),('b',2),('c',3); select * from t_a; show tables; desc t_a; tunnel upload <path> t_a[/<pt_spc>]; tunnel download t_a[/pt_spc] <path>; -- リソース res_a.jar の操作 add jar <path>/res_a.jar ; desc resource res_a.jar; list resources; get resource res_a.jar D:\; drop resource res_a.jar; -- 関数 fun_a の操作 create function fun_a as 'xx' using 'res_a.jar'; desc function fun_a; list functions; drop function fun_a;パラメーターの説明は次のとおりです。
path:ファイルのストレージパスおよび名前。
pt_spc:最下位レベルのパーティションを指定する必要があります。形式は
partition_col1=col1_value1, partition_col2=col2_value1...です。
カスタムスキーマ (s_1 および s_2) 内のオブジェクトを操作する (スキーマ間の操作を含む)
use projectA; set odps.namespace.schema=true;-- テナントレベルで設定されている場合は、ここで指定する必要はありません。 -- s_1 下のテーブル t_c の操作 use schema s_1; create table t_c(c1 string,c2 bigint); INSERT OVERWRITE TABLE t_c VALUES ('a',1),('b',2),('c',3); select * from t_c; show tables; drop table t_c; tunnel upload <path> t_c[/<pt_spc>]; tunnel download t_c[/pt_spc] <path>; -- s_2 下のテーブル t_d の操作 create table s_2.t_d(c1 string,c2 bigint); insert into/overwrite table s_2.t_d values ('a',1),('b',2),('c',3); select * from s_2.t_d; show tables in s_2; drop table s_2.t_d; tunnel upload <path> s_2.t_d[/<pt_spc>]; tunnel download s_2.t_d[/pt_spc] <path>; -- s_1 下のリソース res_b.jar の操作 use schema s_1; add jar <path>/res_b.jar ; desc resource res_b.jar; list resources; get resource res_b.jar D:\; drop resource res_b.jar; -- s_2 下のリソース res_c.jar の操作 add jar xxx ;-- add resource コマンドは、現在のスキーマまたはプロジェクト内でのみ実行できます。スキーマ間またはプロジェクト間では実行できません。そのため、通常の操作を行うにはスキーマ s_2 に切り替える必要があります。 -- プロジェクト間またはスキーマ間の操作では、コロン (:) を使用してリソースの階層を区切ります。 desc resource s_2:res_c.jar; list resources in s_2; get resource s_2:res_c.jar D:\; drop resource s_2:res_c.jar; -- s_1 下の関数 fun_b の操作 use schema s_1; create function fun_b as 'xx' using 'res_b.jar' desc function fun_b; list functions; drop function fun_b; -- s_2 下の関数 fun_c の操作 create function s_2.fun_c as 'xx' using 's_2/resources/res_c.jar' drop function s_2.fun_c; desc function s_2.fun_c; list functions in s_2; drop function s_2.fun_c;
例 2:プロジェクト間の操作 (ProjectA から ProjectB 内のオブジェクトを操作する)
use projectA; set odps.namespace.schema=true; -- テナントレベルで設定されている場合は、ここで指定する必要はありません。 -- projectB のスキーマ s_3 内のテーブル t_f の操作 create table projectB.s_3.t_f(c1 string,c2 bigint); INSERT OVERWRITE TABLE projectB.s_3.t_f VALUES ('a',1),('b',2),('c',3); select * from projectB.s_3.t_f; show tables in projectB.s_3; desc projectB.s_3.t_f; drop table projectB.s_3.t_f; tunnel upload <path> projectB.s_3.t_f[/<pt_spc>]; tunnel download projectB.s_3.t_f[/pt_spc] <path>; -- projectB のスキーマ s_3 内のリソース res_f.jar の操作 add jar xxx ;-- add resource コマンドは、現在のスキーマまたはプロジェクト内でのみ実行できます。スキーマ間またはプロジェクト間では実行できません。そのため、通常の操作を行うには projectB に切り替え、スキーマ s_3 を使用する必要があります。 -- プロジェクト間およびスキーマ間の操作では、コロン (:) を使用してリソースの階層を区切ります。 desc resource projectB:s_3:res_f.jar; list resources in projectB.s_3; get resource projectB:s_3:res_f.jar D:\; drop resource projectB:s_3:res_f.jar; -- projectB のスキーマ s_3 内の関数 fun_f の操作 create function projectB.s_3.fun_f as 'xx' using 'projectB/schemas/s_3/resources/res_f.jar' desc function projectB.s_3.fun_f; list functions in projectB.s_3; drop function projectB.s_3.fun_f;
権限
スキーマオブジェクトに対する権限の付与
スキーマオブジェクトに対する CreateTable、CreateResource、CreateFunction などの操作の権限は、プロジェクトレベルで付与する必要があります。プロジェクトに対してこれらの操作権限を持っている場合、そのプロジェクト内のすべてのスキーマに対する権限も持っています。スキーマオブジェクトに対するアクセスの制御は、今後のリリースで実装される予定です。
説明スキーマ所有者は、デフォルトでスキーマおよびその内部のリソースに対するすべてのアクセス権限およびアクセスの制御権限を持ちます。
プロジェクトに対して CreateTable、CreateResource、および CreateFunction 権限を持っている場合、そのプロジェクト内のスキーマに対する対応する権限を自動的に継承します。
スキーマ内のリソースオブジェクトに対する権限
スキーマ内のリソースオブジェクトに対する権限を付与する場合は、完全なオブジェクト名 (
project.schema.table) を指定する必要があります。権限付与の構文は次のとおりです。テーブル、リソース、関数などの特定のオブジェクトに対する権限の一覧については、「MaxCompute 権限」をご参照ください。管理コンソールでも権限を付与できます。詳細については、「コンソールを使用したユーザー権限の管理」をご参照ください。-- ロールに、スキーマ内のすべてのテーブルに対する権限を付与します。 GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.* TO role {rolename}; -- ロールから、スキーマ内のすべてのテーブルに対する権限を取り消します。 REVOKE schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.* FROM role {rolename}; -- ロールまたはユーザーに、スキーマ内の特定のテーブルに対する権限を付与します。 GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.<tablename> TO {role|user} {rolename | USER name};-- ロールまたはユーザーに、スキーマ内の特定のテーブルに対する権限を付与します。 -- ロールまたはユーザーから、スキーマ内の特定のテーブルに対する権限を取り消します。 REVOKE schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.<tablename> FROM {role|user} {rolename | USER name}; -- テーブルに対する権限を表示します。 SHOW GRANTS ON TABLE <project_name>.<schema_name>.<tablename>;説明データセキュリティを確保するため、
GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.xxx* TO role {rolename};構文はサポートされていません。