Serverless Spark ワークスペースで Kerberos 認証を設定して有効にすることができます。この機能を有効にすると、クライアントは Kerberos 認証を使用してワークスペースに Spark タスクを送信する必要があります。これにより、タスク実行のセキュリティが向上します。
前提条件
プリンシパルを作成し、Kerberos keytab ファイルをエクスポートし、そのファイルを Alibaba Cloud Object Storage Service (OSS) にアップロード済みであること。
EMR on ECS クラスターを使用する場合、詳細については、「基本的な Kerberos の使用方法」をご参照ください。
Serverless Spark ワークスペースを作成済みであること。詳細については、「ワークスペースの管理」をご参照ください。
制限事項
ワークスペースは 1 つの Kerberos クラスターにのみバインドできます。
Kerberos 認証は Spark バッチジョブでのみサポートされます。
手順
ステップ 1: ネットワークの準備
Kerberos 認証を設定する前に、Serverless Spark とお使いの Virtual Private Cloud (VPC) との間のネットワーク接続を確保する必要があります。詳細については、「EMR Serverless Spark と他の VPC との間のネットワーク接続の確立」をご参照ください。
セキュリティグループルールを追加する際は、Kerberos サービスが使用する UDP ポートを開く必要があります。通常はポート 88 です。
ステップ 2: Kerberos 認証の設定
Kerberos 認証ページに移動します。
EMR コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、対象のワークスペースの名前をクリックします。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある をクリックします。
[Kerberos のバインド] をクリックします。
[Kerberos のバインド] ページで、パラメーターを設定し、[OK] をクリックします。
パラメーター
説明
Kerberos 名
カスタム名を入力します。
ネットワーク接続
作成したネットワーク接続を選択します。
Kerberos krb5.conf
krb5.confファイルの内容を入力します。krb5.confファイルは通常、サーバーの/etc/krb5.confパスにあります。お使いの環境に基づいてファイルの内容を取得します:EMR DataLake クラスターの Kerberos サービスを使用する場合、次のように内容を取得します:
EMR クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
次のコマンドを実行して
/etc/krb5.confの内容を表示し、手動でコピーします。cat /etc/krb5.conf内容を [Kerberos Krb5.conf] フィールドにコピーします。
他の EMR クラスターまたは自己管理の Kerberos サービスの場合、ファイル内の
hostnameを VPC のプライベート IP アドレスに置き換えます。
(オプション) ネットワークプロトコルの種類に基づいて、
krb5.confファイルに追加の設定を加えます。ステップ 1: ネットワークの準備 でネットワーク接続を設定した際に UDP ポート 88 を開いた場合、追加の設定は不要です。
ステップ 1: ネットワークの準備 でネットワーク接続に TCP プロトコルを使用した場合、
[libdefaults]の下にudp_preference_limit = 1を追加します。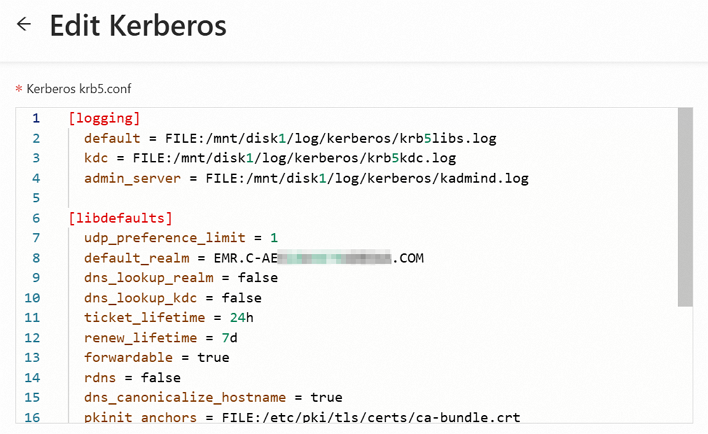
[アクション] 列で、[認証を有効化] をクリックします。
表示されるダイアログボックスで、[OK] をクリックします。
ステップ 3: Spark バッチジョブの送信
Kerberos 認証を有効にすると、Spark バッチジョブを送信するためにクライアント認証が必要になります。必要な設定なしでジョブを送信すると、エラーメッセージ spark.kerberos.keytab and spark.kerberos.principal not configured が返されます。
Spark バッチジョブを作成します。詳細については、「PySpark クイックスタート」をご参照ください。
新しい開発タブで、次の設定を追加し、[実行] をクリックします。
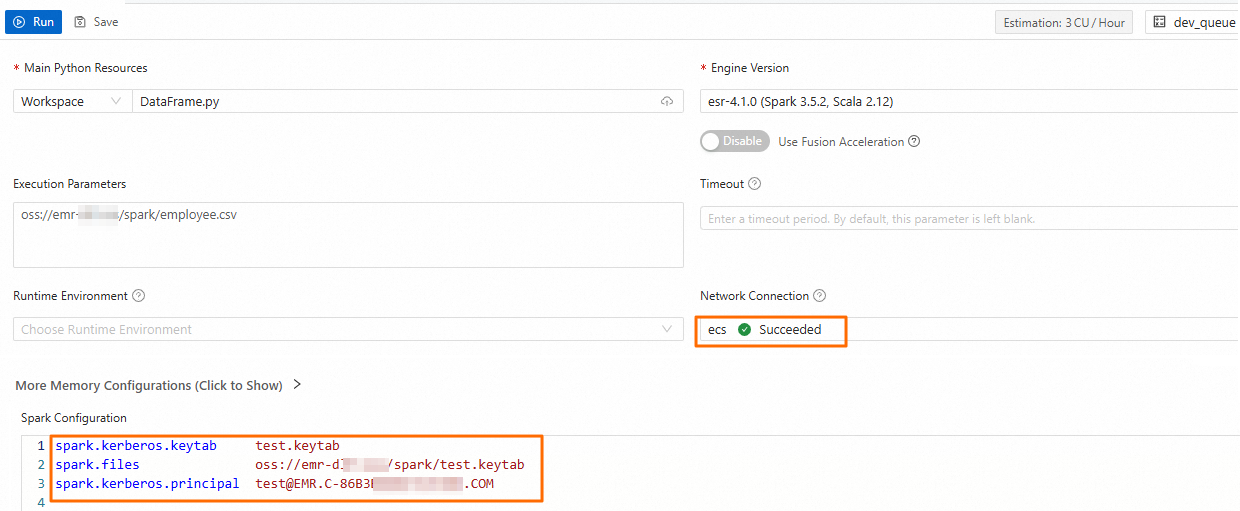
パラメーター
説明
ネットワーク接続
ステップ 1 で追加したネットワーク接続の名前を選択します。
Spark 設定
次のパラメーターを設定します。
spark.files oss://<bucketname>/path/test.keytab spark.kerberos.keytab test.keytab spark.kerberos.principal <username>@<REALM>パラメーターは次のように説明されます:
spark.files: OSS にアップロードされた keytab ファイルの完全なパス。spark.kerberos.keytab: keytab ファイルの名前。spark.kerberos.principal: keytab ファイル内のプリンシパルの名前。このプリンシパルは、Kerberos サービスでの身分認証に使用されます。ターゲットの keytab ファイル内のプリンシパル名を表示するには、klist -kt <keytab_file>コマンドを実行します。
Kerberos が有効な Hive Metastore に接続してメタデータを取得するには、[Spark 設定] セクションに次の情報を追加します。
spark.hive.metastore.sasl.enabled true spark.hive.metastore.kerberos.principal hive/<hostname>@<REALM>spark.hive.metastore.kerberos.principalパラメーターを、Hive Metastore が使用する keytab ファイルのプリンシパルに設定します。この keytab ファイルへのパスを見つけるには、EMR on ECS コンソールの Hive サービスの [設定] ページに移動します。[hive-site.xml] タブで、[hive.metastore.kerberos.keytab.file] パラメーターの値を見つけます。その後、klist -kt <path_to_Hive_Metastore_keytab_file>コマンドを実行してプリンシパルを取得できます。spark.hive.metastore.kerberos.principalパラメーターの値は次のフォーマットです:フォーマットは通常
hive/<hostname>@<REALM>です。<hostname>は Hive Metastore が実行されるノードの完全修飾ドメイン名で、hostname -fコマンドを実行して取得できます。<REALM>は KDC のレルムです。Hive Metastore エンドポイントがホスト名を使用する場合、フォーマットを
hive/_HOST@<REALM>に簡略化できます。接続時に、Spark は自動的に_HOSTを Hive Metastore エンドポイントのホスト名に置き換えます。この `_HOST` フォーマットは、複数の Hive Metastore を設定するために必要です。
ジョブの実行後、[実行記録] セクションに移動し、[アクション] 列の [詳細] をクリックします。
[ジョブ履歴] では、[開発ジョブ] ページで関連ログを表示できます。
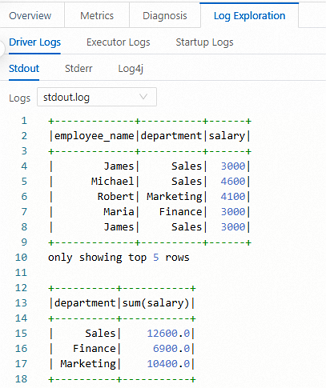
ステップ 4 (オプション): Kerberos が有効な Hive Metastore への接続
ワークスペースのデータカタログがメタデータを取得するために Kerberos が有効な Hive Metastore に接続する必要がある場合、外部 Hive Metastore を追加する際に keytab ファイルのパスとプリンシパル名を指定する必要があります。
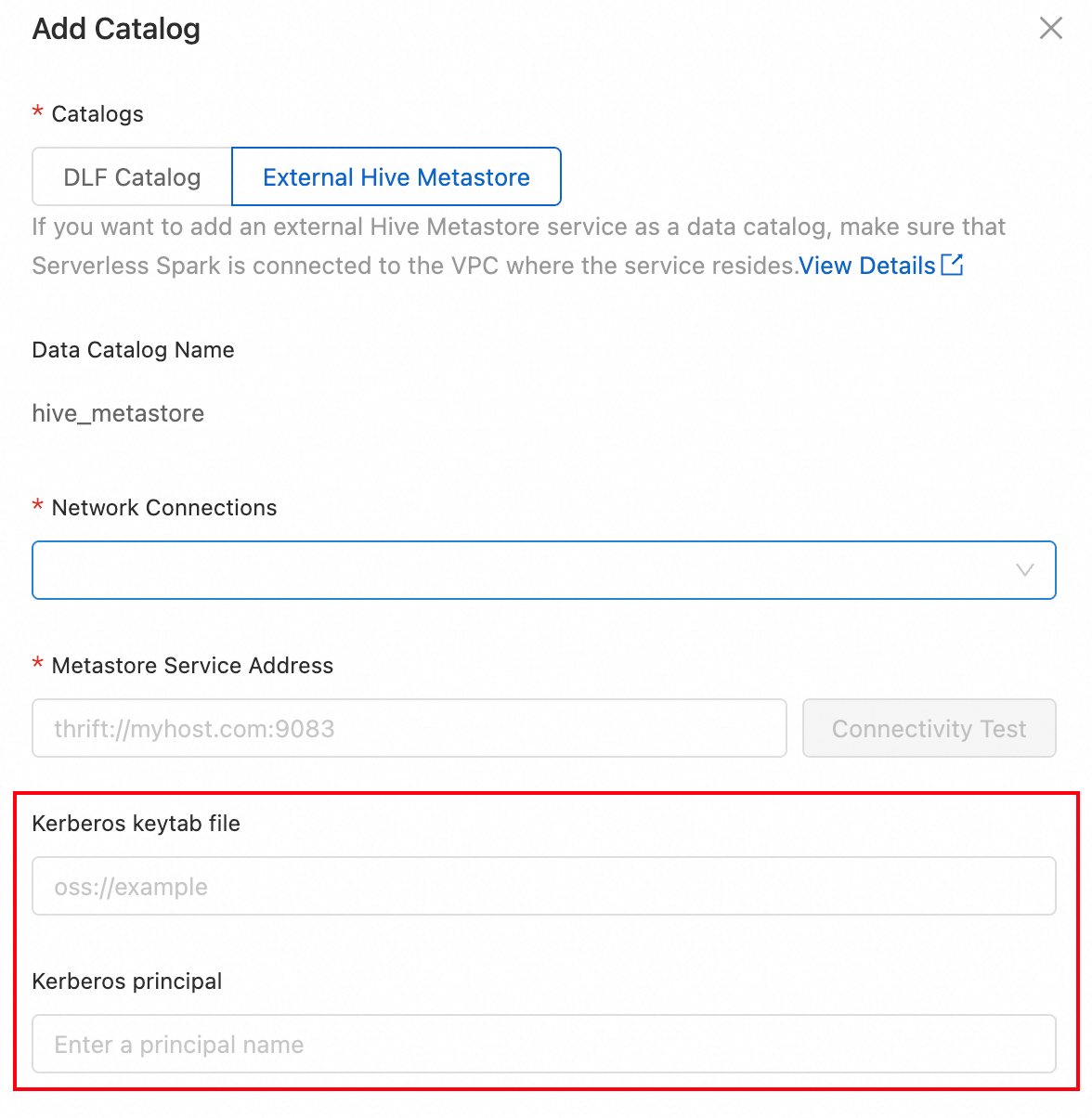
Kerberos Keytab ファイルパス: Kerberos keytab ファイルへのパス。
Kerberos プリンシパル: keytab ファイルからのプリンシパル名。このプリンシパルは、Kerberos サービスでの身分認証に使用されます。指定された keytab ファイル内のプリンシパル名を表示するには、
klist -kt <keytab_file>コマンドを実行します。