ビジネスロジックを含む Python スクリプトを作成し、それを EMR Serverless Spark にアップロードすることで、PySpark ジョブを開発できます。このトピックでは、開発プロセスをガイドするための例を示します。
前提条件
Alibaba Cloud アカウントを持っていること。詳細については、「アカウント登録」をご参照ください。
必要なロールが付与されていること。詳細については、「Alibaba Cloud アカウントのロール権限付与」をご参照ください。
ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
手順
ステップ 1: テストファイルの準備
EMR Serverless Spark では、オンプレミスまたはスタンドアロンの開発プラットフォームで Python ファイルを開発し、そのファイルを EMR Serverless Spark に送信して実行できます。このクイックスタートでは、PySpark ジョブにすぐに慣れることができるように、テストファイルを提供しています。次のステップで使用するために、テストファイルをダウンロードしてください。
DataFrame.py と employee.csv をクリックして、テストファイルをダウンロードします。
DataFrame.py ファイルには、Apache Spark フレームワークを使用して OSS のデータを処理するコードが含まれています。
employee.csv ファイルには、従業員の名前、部署、給与などのデータリストが含まれています。
ステップ 2: テストファイルのアップロード
Python ファイルを EMR Serverless Spark にアップロードします。
リソースのアップロードページに移動します。
EMR コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、対象のワークスペースの名前をクリックします。
EMR Serverless Spark ページで、左側のナビゲーションウィンドウにある [ファイル] をクリックします。
[ファイル] ページで、[ファイルのアップロード] をクリックします。
[ファイルのアップロード] ダイアログボックスで、アップロードエリアをクリックして Python ファイルを選択するか、ファイルをエリアにドラッグします。
この例では、DataFrame.py ファイルをアップロードします。
データファイル (employee.csv) を Object Storage Service (OSS) コンソールにアップロードします。詳細については、「ファイルのアップロード」をご参照ください。
ステップ 3: ジョブの開発と実行
EMR Serverless Spark ページの左側のナビゲーションウィンドウで、[データ開発] をクリックします。
[開発] タブで、
 アイコンをクリックします。
アイコンをクリックします。表示されるダイアログボックスで、名前を入力し、[タイプ] に を選択し、[OK] をクリックします。
右上隅で、キューを選択します。
キューの追加方法の詳細については、「リソースキューの管理」をご参照ください。
新しいジョブタブで、次のパラメーターを設定します。他のパラメーターはデフォルト設定のままにします。次に、[実行] をクリックします。
パラメーター
説明
メイン Python リソース
前のステップで [ファイル] ページにアップロードした Python ファイルを選択します。この例では、DataFrame.py を選択します。
実行パラメーター
OSS にアップロードされたデータファイル (employee.csv) のパスを入力します。例: oss://<yourBucketName>/employee.csv。
ジョブの実行後、下の [実行記録] セクションで、ジョブの [アクション] 列にある [ログプローブ] をクリックします。
[ログプローブ] タブで、ログ情報を表示できます。
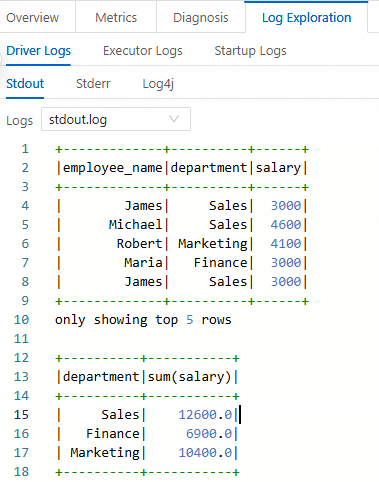
ステップ 4: ジョブの公開
公開されたジョブは、ワークフローのノードとして使用できます。
ジョブの実行後、右側の [公開] をクリックします。
[ジョブの公開] ダイアログボックスで、リリース情報を入力し、[OK] をクリックします。
ステップ 5: Spark UI の表示
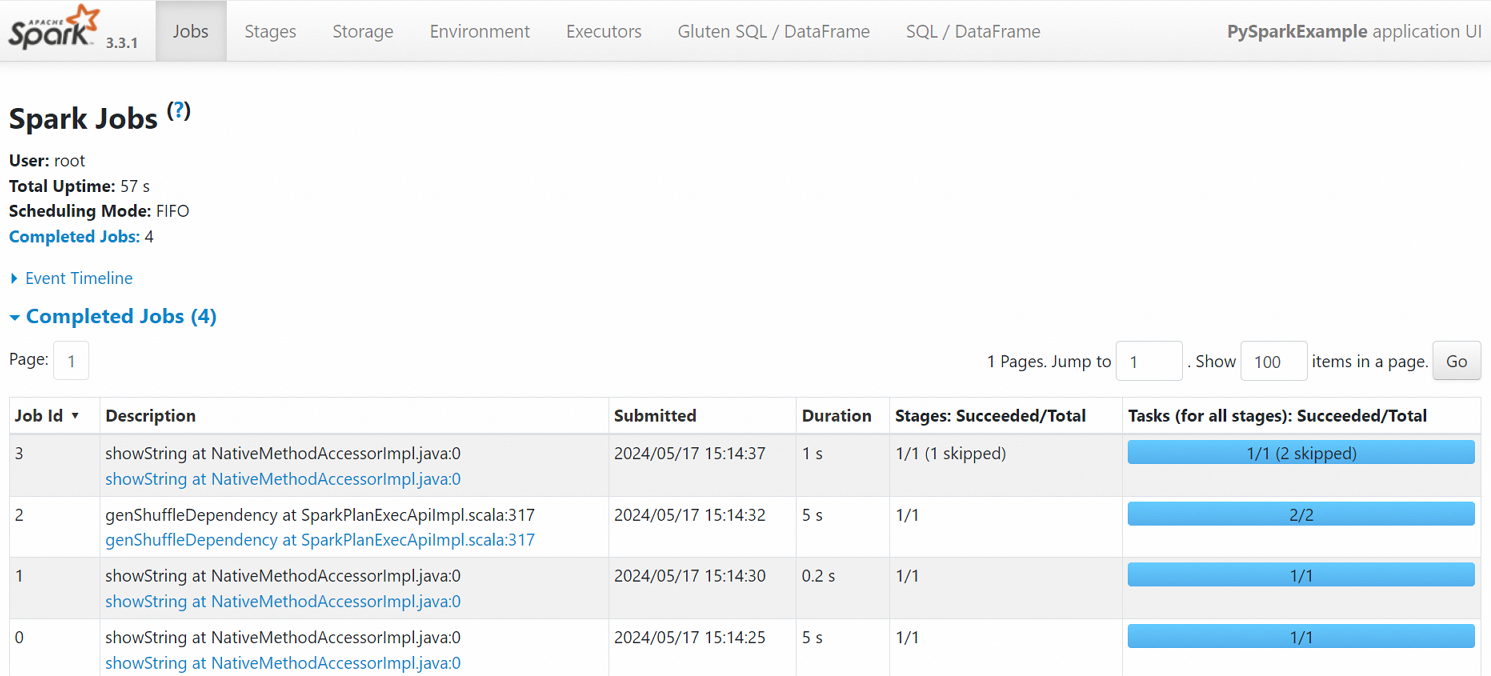
ジョブが正常に実行された後、Spark UI でそのステータスを表示できます。
左側のナビゲーションウィンドウで、[ジョブ履歴] をクリックします。
[アプリケーション] ページで、対象のジョブの [アクション] 列にある [Spark UI] をクリックします。
Spark ジョブページで、ジョブの詳細を表示できます。
参考
ジョブが公開された後、スケジューリングのためにワークフローで使用できます。詳細については、「ワークフローの管理」をご参照ください。ジョブ開発とオーケストレーションプロセスの完全な例については、「SparkSQL 開発のクイックスタート」をご参照ください。
PySpark ストリーミングジョブの開発方法の例については、「Serverless Spark を使用した PySpark ストリーミングジョブの送信」をご参照ください。