ネットワーク接続により、EMR Serverless Spark ワークスペースを Virtual Private Cloud (VPC) に接続でき、Spark ジョブがその VPC 内のデータソースやサービスにアクセスできるようになります。このガイドでは、ネットワーク接続を設定して、Spark SQL および JAR ジョブを Hive Metastore (HMS) に接続する手順を説明します。
ワークスペースを VPC に接続すると、Spark タスクはその VPC を通じてトラフィックをルーティングします。タスクがパブリックエンドポイント(たとえば、パブリックネットワーク経由の OSS など)にも到達する必要がある場合は、VPC にインターネット NAT ゲートウェイをデプロイし、SNAT を設定してください。これを行わないと、パブリックエンドポイントは到達不能になります。詳細については、「インターネット NAT ゲートウェイの SNAT 機能を使用してインターネットにアクセスする」をご参照ください。
前提条件
開始する前に、以下が準備できていることを確認してください。
-
[EMR on ECS] ページに、Hive サービスを含み、[メタデータ] に [内蔵 MySQL] を使用する DataLake クラスターがあること。詳細については、「クラスターの作成」をご参照ください。
サポートされるゾーン
vSwitch は特定のゾーンでのみ利用可能です。
ステップ 1:ネットワーク接続の追加
-
EMR コンソールにログインします。
-
左側のナビゲーションウィンドウで、[EMR Serverless] > [Spark] を選択します。
-
[Spark] ページで、ワークスペース名をクリックします。
-
左側のナビゲーションウィンドウで、[ネットワーク接続] をクリックします。
-
[ネットワーク接続] ページで、[ネットワーク接続の作成] をクリックします。
-
[ネットワーク接続の作成] ダイアログボックスで、次のパラメーターを設定し、[OK] をクリックします。接続の [ステータス] が [成功] に変わると、接続は準備完了です。
パラメーター 説明 [名前] 接続の名前を入力します。 VPC ご利用の EMR クラスターと同じ VPC を選択します。利用可能な VPC がない場合は、[VPC の作成] をクリックして VPC コンソールで作成します。詳細については、「VPC と vSwitch」をご参照ください。 vSwitch ご利用の EMR クラスターと同じ VPC 内の vSwitch を選択します。vSwitch はサポートされているゾーン (サポートされるゾーン をご参照ください) にある必要があります。必要なゾーンに利用可能な vSwitch がない場合は、VPC コンソールで作成します。詳細については、「vSwitch の作成と管理」をご参照ください。 
ステップ 2:EMR クラスターへのセキュリティグループルールの追加
Spark ジョブが実行されると、トラフィックは vSwitch の CIDR ブロックからご利用の VPC に流れ込みます。そのトラフィックが HMS サービスに到達できるようにするには、EMR クラスターのセキュリティグループにインバウンドルールを追加します。
-
ステップ 1 で選択した vSwitch の CIDR ブロックを取得します。VPC コンソールにログインし、[vSwitch] ページに移動して CIDR ブロックを見つけます。
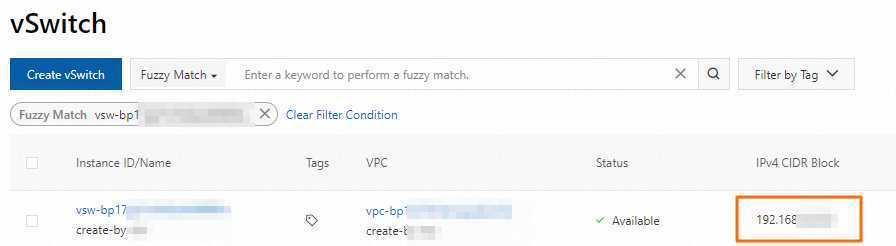
-
EMR on ECS コンソールにログインします。
-
[EMR on ECS] ページで、クラスター ID をクリックします。
-
[基本情報] タブの [セキュリティ] セクションで、[クラスターセキュリティグループ] の横にあるリンクをクリックします。
-
[セキュリティグループの詳細] ページの [ルール] セクションに移動し、[ルールの追加] をクリックします。次のパラメーターを設定し、[OK] をクリックします。
重要「[承認オブジェクト]」を
0.0.0.0/0に設定しないでください。過剰に許可されたルールは、クラスターをパブリックインターネットからの攻撃にさらします。パラメーター 値 [プロトコル] TCP (デフォルト)。Kerberos 認証の場合は、UDP を選択し、代わりにポート 88 をオープンします。詳細については、「Kerberos 認証の有効化」をご参照ください。 ソース ステップ 1 の vSwitch の CIDR ブロック。 [宛先 (現在のインスタンス)] アクセスを許可する宛先ポートを指定します。例: 9083。
(任意) ステップ 3:Hive テーブルのセットアップ
クエリ対象の Hive テーブルが既にある場合は、このステップをスキップしてください。
-
SSH を使用して EMR クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
-
Hive コマンドラインに入ります。
hive -
テーブルを作成します。
CREATE TABLE my_table (id INT, name STRING); -
サンプルデータを挿入します。
INSERT INTO my_table VALUES (1, 'John'); INSERT INTO my_table VALUES (2, 'Jane'); -
データを確認します。
SELECT * FROM my_table;
(任意) ステップ 4:JAR アーティファクトのビルドとアップロード
Spark SQL ジョブを使用する場合は、このステップをスキップしてください。
-
ローカルマシンに次のクラスを持つ Maven プロジェクトを作成します。
-
JAR をビルドします。
mvn packageこれにより、
sparkDataFrame-1.0-SNAPSHOT.jarがtarget/ディレクトリに生成されます。 -
JAR をワークスペースにアップロードします。
-
ご利用のワークスペースの EMR Serverless Spark ページで、左側のナビゲーションウィンドウの [アーティファクト] をクリックします。
-
[アーティファクト] ページで、[ファイルをアップロード] をクリックし、
sparkDataFrame-1.0-SNAPSHOT.jarをアップロードします。
-
ステップ 5:ジョブの作成と実行
JAR ジョブ
-
EMR Serverless Spark ページで、左側のナビゲーションウィンドウの [開発] をクリックします。
-
[新規] をクリックし、名前を入力し、[アプリケーション (バッチ)] > [JAR] を選択して、[OK] をクリックします。
-
ジョブエディターで、次のパラメーターを設定します。他のすべてのパラメーターはデフォルト値のままにします。[Spark 設定] には、
<hms-private-ip>を HMS マスターノードのプライベート IP アドレスに置き換えて、次のように入力します。パラメーター 値 メイン JAR リソース sparkDataFrame-1.0-SNAPSHOT.jarを選択します。[メインクラス] com.example.DataFrameExample[ネットワーク接続] ステップ 1 で作成したネットワーク接続を選択します。 Spark 設定 下記をご参照ください。 spark.hadoop.hive.metastore.uris thrift://<hms-private-ip>:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactoryプライベート IP アドレスを見つけるには、EMR クラスターの [ノード] ページに移動し、[emr-master] ノードグループを展開します。
-
[実行] をクリックします。
-
ジョブが完了したら、ページ下部の [実行記録] に移動し、[ログ] をクリックして [ログ探索] タブで出力を表示します。
Spark SQL ジョブ
-
Spark SQL セッションを作成して開始します。詳細については、「SQL セッションの管理」をご参照ください。セッションを設定する際に、以下を設定します。
-
[ネットワーク接続]:ステップ 1 で作成したネットワーク接続を選択します。
-
[Spark 設定]:
<hms-private-ip>を HMS マスターノードのプライベート IP アドレスに置き換えて、次のように入力します。spark.hadoop.hive.metastore.uris thrift://<hms-private-ip>:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactoryプライベート IP アドレスを確認するには、EMR クラスターの [ノード] ページに移動し、emr-master ノードグループの横にある
 アイコンをクリックします。
アイコンをクリックします。
-
-
EMR Serverless Spark ページで、左側のナビゲーションウィンドウの [開発] をクリックします。
-
 アイコンをクリックして新しいファイルを作成します。
アイコンをクリックして新しいファイルを作成します。 -
[新規] ダイアログボックスで、名前 (例:
users_task) を入力し、タイプを [SparkSQL] のままにして、[OK] をクリックします。 -
カタログ、データベース、および SQL セッションインスタンスを選択します。次のクエリを入力し、[実行] をクリックします。
外部メタストアを使用する SQL コードをワークフローにデプロイする場合は、テーブルを
db.table_name形式で指定し、[カタログ] オプションからcatalog_id.default形式でデフォルトのデータベースを選択します。SELECT * FROM default.my_table;結果は、ページ下部の [実行結果] セクションに表示されます。
