本記事では、ods_user_info_d(ユーザー情報)および ods_raw_log_d(アクセスログ)の各テーブルを MaxCompute に同期した後の処理方法について説明します。DataWorks の MaxCompute ノードを使用して、ユーザー プロファイルデータを生成します。本ガイドでは、シンプルなデータウェアハウス構成における DataWorks および MaxCompute を用いたデータ計算・分析の手順を示します。
前提条件
開始する前に、「データの同期」で説明されている手順を完了してください。
データ処理パイプラインの構築
前段階では、データを MaxCompute に同期しました。本段階では、このデータを処理して基本的なユーザー プロファイルデータを生成します。
DataStudio の左側ナビゲーションウィンドウで
 をクリックします。プロジェクト ディレクトリ から作成済みのワークフローを見つけ、クリックしてワークフロー キャンバスを開きます。
をクリックします。プロジェクト ディレクトリ から作成済みのワークフローを見つけ、クリックしてワークフロー キャンバスを開きます。以下の表は、本チュートリアルで使用されるサンプル ノードとその役割を示しています。
ノードタイプ
ノード名
ノードの役割
 MaxCompute SQL
MaxCompute SQLdwd_log_info_diビルトイン関数およびユーザー定義関数 (UDF) (
getregion) を使用して、ods_raw_log_dテーブルから生ログデータを解析し、dwd_log_info_diテーブルの複数のフィールドに出力を書き込みます。MaxCompute SQLdws_user_info_all_diユーザー情報テーブル (
ods_user_info_d) および処理済みログデータテーブル (dwd_log_info_di) からデータを集約し、その結果をdws_user_info_all_diテーブルに書き込みます。MaxCompute SQLads_user_info_1ddws_user_info_all_diテーブルからデータを処理し、基本的なユーザー プロファイルをads_user_info_1dテーブルに書き込みます。ノードをドラッグ&ドロップして接続し、依存関係を設定します。最終的なワークフローは次のようになります:
 説明
説明ワークフロー内では、子ノードのコードを解析することでシステムが自動的に依存関係を特定することもできますが、本チュートリアルではノード間の依存関係を手動で接続する方法を採用します。詳細については、「上流および下流の依存関係」および「自動解析メカニズム」をご参照ください。
ユーザー定義関数の登録
同期済みログデータを構造化されたテーブル形式に解析するために、getregion ユーザー定義関数 (UDF) を登録します。
本チュートリアルでは、IP アドレスを地理的リージョンに変換する関数に必要なリソースを提供します。このリソースをダウンロードし、DataWorks ワークスペースにアップロードした後、関数を登録してください。
この関数はチュートリアル専用であり、サンプル IP リソースを使用します。本番環境で IP アドレスを地理的位置にマッピングする必要がある場合は、専門の IP データプロバイダーから IP 変換サービスを取得してください。
リソース (ip2region.jar) のアップロード
ip2region.jar をダウンロードします。
説明ip2region.jarリソースは、チュートリアル専用のサンプルです。DataStudio ページの左側ナビゲーションウィンドウで
 をクリックします。
をクリックします。 > リソースの作成 > MaxCompute > Jar をクリックし、リソース名を設定します。説明
> リソースの作成 > MaxCompute > Jar をクリックし、リソース名を設定します。説明リソース名は、アップロードするファイル名と一致させる必要はありません。
ソース で ローカル を選択します。アップロードをクリック をクリックし、ダウンロードした
ip2region.jarファイルを選択します。データ ソース で、「環境の準備」の前段階でバインドした MaxCompute 計算リソースを選択します。
ツールバーで 保存 をクリックし、その後 公開 をクリックします。指示に従って、リソースを開発環境および本番環境の MaxCompute プロジェクトに公開します。
関数 (getregion) の登録
Resource Management ページで、
> 関数の作成 > MaxCompute > 関数 をクリックし、関数名を getregionに設定します。関数の登録 ページでパラメーターを構成します。以下の表は、本チュートリアルで重要なパラメーターを示しています。その他のパラメーターはデフォルト値のままとします。
パラメーター
説明
関数タイプ
OTHERを選択します。データ ソース
「環境の準備」の前段階でバインドした MaxCompute 計算リソースを選択します。
クラス名
org.alidata.odps.udf.Ip2Regionを入力します。リソース一覧
ip2region.jarを選択します。説明
IP アドレスをリージョンに変換します。
コマンド形式
getregion('ip')を入力します。パラメーターの説明
IP アドレスです。
ツールバーで 保存 をクリックし、その後 公開 をクリックします。指示に従って、関数を開発環境および本番環境の MaxCompute プロジェクトに公開します。
データ処理ノードの構成
本チュートリアルでは、各変換レイヤーごとに MaxCompute SQL をスケジュールしてデータを処理します。dwd_log_info_di、dws_user_info_all_di、および ads_user_info_1d の各ノードに対して、提供されたサンプル コードを構成します。
dwd_log_info_di ノードの構成
このノードのサンプル コードでは、登録済みの関数を使用して、上流テーブル ods_raw_log_d のフィールドを処理し、その結果を dwd_log_info_di テーブルに書き込みます。
DataStudio の左側ナビゲーションウィンドウで
をクリックします。プロジェクト ディレクトリ から作成済みのワークフローを見つけ、クリックしてワークフロー キャンバスを開きます。ワークフロー キャンバス上で
dwd_log_info_diノードにカーソルを合わせ、ノードを開く をクリックします。以下のコードをノード エディターに貼り付けます。
実行パラメーターを構成します。
MaxCompute SQL ノード エディターの右側ペインで、Run Configuration をクリックします。以下のパラメーターを構成します。これらのパラメーターは、「ステップ 4」でのテスト実行に使用されます。
パラメーター
説明
計算リソース
「環境の準備」の前段階でバインドした MaxCompute 計算リソースおよび対応するコンピューティング クォータを選択します。
リソースグループ
「環境の準備」の前段階で購入した Serverless リソースグループを選択します。
スクリプト パラメーター
構成は不要です。本チュートリアルのサンプル コードでは、ビジネス日付を表すために一律に
${bizdate}を使用しています。「次のステップ」でワークフローを実行する際に、現在の値 を20250223などの特定の定数に設定できます。タスクは実行時にこの定数で変数を置き換えます。(任意)スケジューリング構成を構成します。
本チュートリアルでは、スケジューリング パラメーターのデフォルト値をそのまま使用できます。MaxCompute SQL ページの右側ペインで、スケジューリング をクリックします。スケジューリング パラメーターの詳細については、「ノード スケジューリング構成」をご参照ください。
スケジューリング パラメーター:これはワークフロー全体でグローバルに構成されるため、個々のノードに対して構成する必要はありません。タスクやコード内で直接パラメーターを使用できます。
スケジューリングポリシー:子ノードの実行をワークフロー開始後に遅延させるために、開始時刻 パラメーターを設定できます。本チュートリアルでは遅延を設定しません。
ツールバーで 保存 をクリックします。
dws_user_info_all_di ノードの構成
このノードでは、ユーザー情報テーブル (ods_user_info_d) および処理済みログデータテーブル (dwd_log_info_di) からデータを集約し、その結果を dws_user_info_all_di テーブルに書き込みます。
ワークフロー キャンバス上で
dws_user_info_all_diノードにカーソルを合わせ、ノードを開く をクリックします。以下のコードをノード エディターに貼り付けます。
実行パラメーターを構成します。
MaxCompute SQL ノード エディターの右側ペインで、Run Configuration をクリックします。以下のパラメーターを構成します。これらのパラメーターは、「ステップ 4」でのテスト実行に使用されます。
パラメーター
説明
計算リソース
「環境の準備」の前段階でバインドした MaxCompute 計算リソースおよび対応するコンピューティング クォータを選択します。
リソースグループ
「環境の準備」の前段階で購入した Serverless リソースグループを選択します。
スクリプト パラメーター
構成は不要です。本チュートリアルのサンプル コードでは、ビジネス日付を表すために一律に
${bizdate}を使用しています。「次のステップ」でワークフローを実行する際に、現在の値 を20250223などの特定の定数に設定できます。タスクは実行時にこの定数で変数を置き換えます。(任意)スケジューリング構成を構成します。
本チュートリアルでは、スケジューリング パラメーターのデフォルト値をそのまま使用できます。MaxCompute SQL ページの右側ペインで、スケジューリング をクリックします。スケジューリング パラメーターの詳細については、「ノード スケジューリング構成」をご参照ください。
スケジューリング パラメーター:これはワークフロー全体でグローバルに構成されるため、個々のノードに対して構成する必要はありません。タスクやコード内で直接パラメーターを使用できます。
スケジューリングポリシー:子ノードの実行をワークフロー開始後に遅延させるために、開始時刻 パラメーターを設定できます。本チュートリアルでは遅延を設定しません。
ツールバーで 保存 をクリックします。
ads_user_info_1d ノードの構成
このノードでは、dws_user_info_all_di テーブル内のデータを処理し、その結果を ads_user_info_1d テーブルに書き込んで基本的なユーザー プロファイルを生成します。
ワークフロー キャンバス上で
ads_user_info_1dノードにカーソルを合わせ、ノードを開く をクリックします。以下のコードをノード エディターに貼り付けます。
実行パラメーターを構成します。
MaxCompute SQL ノード エディターの右側ペインで、Run Configuration をクリックします。以下のパラメーターを構成します。これらのパラメーターは、「ステップ 4」でのテスト実行に使用されます。
パラメーター
説明
計算リソース
「環境の準備」の前段階でバインドした MaxCompute 計算リソースおよび対応するコンピューティング クォータを選択します。
リソースグループ
「環境の準備」の前段階で購入した Serverless リソースグループを選択します。
スクリプト パラメーター
構成は不要です。本チュートリアルのサンプル コードでは、ビジネス日付を表すために一律に
${bizdate}を使用しています。「次のステップ」でワークフローを実行する際に、現在の値 を20250223などの特定の定数に設定できます。タスクは実行時にこの定数で変数を置き換えます。(任意)スケジューリング構成を構成します。
本チュートリアルでは、スケジューリング パラメーターのデフォルト値をそのまま使用できます。MaxCompute SQL ページの右側ペインで、スケジューリング をクリックします。スケジューリング パラメーターの詳細については、「ノード スケジューリング構成」をご参照ください。
スケジューリング パラメーター:これはワークフロー全体でグローバルに構成されるため、個々のノードに対して構成する必要はありません。タスクやコード内で直接パラメーターを使用できます。
スケジューリングポリシー:子ノードの実行をワークフロー開始後に遅延させるために、開始時刻 パラメーターを設定できます。本チュートリアルでは遅延を設定しません。
ツールバーで 保存 をクリックします。
データの処理
データを処理します。
ワークフローのツールバーで 実行 をクリックします。今回の実行で各ノードで定義されたパラメーター変数の値を設定します。本チュートリアルでは
20250223を使用しますが、必要に応じて値を変更できます。その後、OK をクリックし、実行が完了するまで待ちます。結果を確認します。
DataStudio の左側ナビゲーションウィンドウで
 をクリックして「データ開発」ページに移動します。その後、個人フォルダー領域で
をクリックして「データ開発」ページに移動します。その後、個人フォルダー領域で  をクリックして、拡張子が
をクリックして、拡張子が .sqlのファイルを作成します。ファイル名は任意に指定できます。ページ下部で、言語モードが
MaxCompute SQLであることを確認します。
SQL エディター ウィンドウで、以下の SQL 文を実行して、最終テーブル
ads_user_info_1dのレコード数を確認し、出力を検証します。-- パーティション フィルターは、実際の操作のビジネス日付に変更する必要があります。 -- 本チュートリアルでは、'bizdate' パラメーターを 20250223 に設定しました。 SELECT count(*) FROM ads_user_info_1d WHERE dt='20250223';コマンドが 0 より大きいカウントを返した場合、データ処理は完了しています。
データが返されない場合は、ワークフロー実行で構成された 今回の実行で使用する値 が、クエリ内の
dtで指定されたデータ タイムスタンプと一致しているか確認してください。ワークフローをクリックし、右側ペインで 実行履歴 をクリックした後、実行記録の アクション 列にある 表示 をクリックすると、ワークフロー実行ログ内のデータ タイムスタンプ値 (partition=[pt=xxx]) を確認できます。
ワークフローの公開
タスクを本番環境に公開して、スケジュールに従って自動的に実行できるようにします。ワークフローの公開手順は以下のとおりです。
本チュートリアルでは、「ワークフローのスケジューリング構成」で既にスケジューリング パラメーターを構成済みのため、公開前に各ノードに対して再度構成する必要はありません。
DataStudio の左側ナビゲーションウィンドウで
をクリックします。プロジェクト ディレクトリ から作成済みのワークフローを見つけ、クリックしてワークフロー キャンバスを開きます。ツールバーで 公開 をクリックして公開ダイアログボックスを開きます。
本番環境への公開を開始 をクリックします。表示される確認ダイアログボックスで、公開方法を選択します:
フルリリース:現在のワークフローおよびその内部のすべてのタスクを公開します。
インクリメンタルリリース:現在のワークフローおよび前回のリリース以降に変更されたノードのみを公開します。これは反復的な最適化や小規模な更新に適しています。
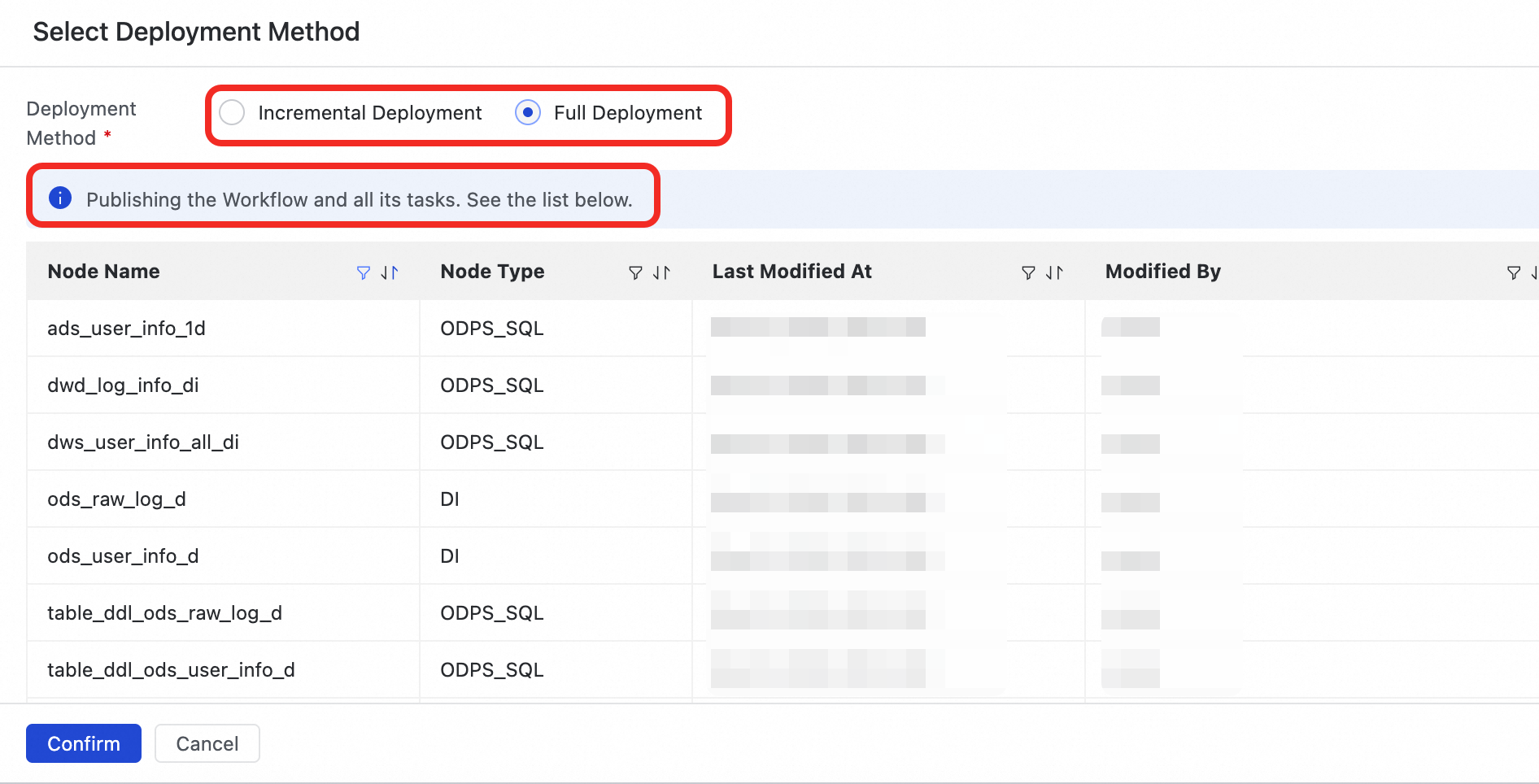
公開方法を確認後、システムが自動的にワークフローおよび選択されたノードを開発環境および本番環境にリリースします。処理を完了するには、プロンプトが表示されたら リリースの確認 をクリックします。

本番環境でのタスク実行
タスクを公開すると、翌日にインスタンスが生成されて実行されます。公開済みのワークフローを即座に実行して、本番環境で正常に動作することを検証するには、バックフィル データ 機能を使用できます。詳細については、「データ バックフィル インスタンス O&M」をご参照ください。
タスクが正常に公開された後、右上隅の オペレーションセンター をクリックします。
または、左上隅の
 アイコンをクリックし、 を選択します。
アイコンをクリックし、 を選択します。左側ナビゲーションウィンドウで、 をクリックします。定期タスク ページで、
workshop_start仮想ノードをクリックします。右側の DAG で、
workshop_startノードを右クリックし、 を選択します。バックフィルするタスクを選択し、ビジネス日付を設定して、送信してページへ移動 をクリックします。
バックフィル データ ページで、更新 をクリックして、すべての SQL タスクが成功するまで待ちます。
チュートリアル完了後、課金されないように、ノードのスケジューリング有効期間を設定するか、ワークフローのルートノード (仮想ノード workshop_start) を[フリーズ]することができます。
次のステップ
データの可視化:ユーザー プロファイル分析を完了した後、データ分析モジュールを使用して処理済みデータをチャートで可視化します。これにより、重要な情報を迅速に抽出し、ビジネスのトレンドに関する洞察を得ることができます。
データ品質のモニタリング:生成されたテーブルに対してデータ品質モニタリング ルールを構成して、ダーティデータを早期に検出しブロックすることで、その影響が広がるのを防ぎます。
データの管理:ユーザー プロファイル分析ワークフローが完了すると、対応するデータテーブルが MaxCompute に作成されます。これらのテーブルは Data Map モジュールで表示でき、データ系統を用いてテーブル間の関係を探索できます。
API を使用したデータサービスの提供:最終的な処理済みデータを取得した後、Data Service モジュールを使用して標準化された API を作成し、データを共有・活用することで、他のビジネスモジュールからの利用を可能にします。