このトピックでは、DataWorks の MaxCompute ノードを使用して、MaxCompute の ods_user_info_d_odps テーブルと ods_raw_log_d_odps テーブルのデータを処理し、ユーザーの基本情報と Web サイトアクセスログがテーブルに同期された後にユーザープロファイルデータを取得する方法について説明します。 また、DataWorks と MaxCompute の製品の組み合わせを使用して、同期されたデータを計算および分析し、データウェアハウスシナリオで簡単なデータ処理を完了する方法についても説明します。
前提条件
必要なデータが同期されています。 詳細については、「データの同期」をご参照ください。
ApsaraDB RDS for MySQL テーブル
ods_user_info_dに格納されているユーザーの基本情報は、[Data Integration] を使用して MaxCompute テーブルods_user_info_d_odpsに同期されます。Object Storage Service (OSS) オブジェクト
user_log.txtに格納されているユーザーの Web サイトアクセスログは、[Data Integration] を使用して MaxCompute テーブルods_raw_log_d_odpsに同期されます。
目的
ods_user_info_d_odps テーブルと ods_raw_log_d_odps テーブルを処理して、基本的なユーザープロファイルテーブルを取得します。
ods_raw_log_d_odpsテーブルのログ情報フィールドを複数のフィールドに分割し、dwd_log_info_di_odpsファクトテーブルを生成します。dwd_log_info_di_odpsファクトテーブルとods_user_info_d_odpsテーブルを uid フィールドに基づいて結合し、dws_user_info_all_di_odps集計テーブルを生成します。dws_user_info_all_di_odpsテーブルを処理して、ads_user_info_1d_odps という名前のテーブルを生成します。 dws_user_info_all_di_odps テーブルには、多数のフィールドと大量のデータが含まれています。 この場合、データ消費に時間がかかる場合があります。 そのため、さらなるデータ処理が必要です。
DataStudio ページに移動する
DataWorks コンソール にログインします。 上部のナビゲーションバーで、目的のリージョンを選択します。 左側のナビゲーションウィンドウで、 を選択します。 表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発に移動] をクリックします。
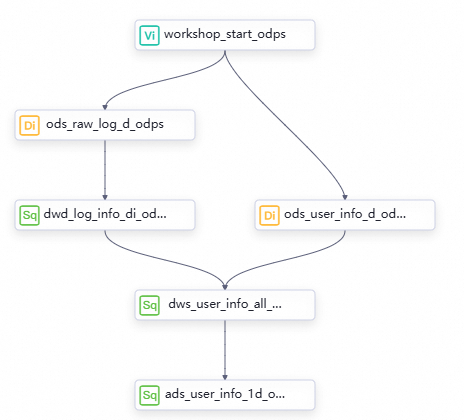
ステップ 1: ワークフローを設計する
データ同期 フェーズでは、必要なデータが MaxCompute テーブルに同期されます。 次の目的は、データをさらに処理して、基本的なユーザープロファイルデータを生成することです。
さまざまなレベルのノードとノードの作業ロジック
ワークフローキャンバスの上部で、[ノードの作成] をクリックして、データ処理のために次の表に示すノードを作成します。
ノードカテゴリ
ノードタイプ
ノード名
(出力テーブルにちなんで名付けられました)
コードロジック
MaxCompute
ODPS SQL
dwd_log_info_di_odps組み込み関数とユーザー定義関数 (UDF) を使用して
ods_raw_log_d_odpsテーブルのデータを分割し、dwd_log_info_di_odpsテーブルの複数のフィールドにデータを書き込みます。MaxCompute
ODPS SQL
dws_user_info_all_di_odpsユーザーの基本情報を格納するテーブルと、予備的に処理されたログデータを格納する dwd_log_info_di_odps テーブルを結合して、集計テーブルを生成します。
MaxCompute
ODPS SQL
ads_user_info_1d_odpsデータをさらに処理して、基本的なユーザープロファイルを生成します。
ワークフローの有向非巡回グラフ (DAG)
ノードをワークフローキャンバスにドラッグし、線を描画してノード間の依存関係を設定することにより、データ処理のワークフローを設計します。
ステップ 2: ワークフローを設定する
MaxCompute テーブルを作成する
処理済みデータを各レイヤーに格納するために使用する dwd_log_info_di_odps、dws_user_info_all_di_odps、および ads_user_info_1d_odps テーブルを作成します。 この例では、テーブルは迅速な方法で作成されます。 MaxCompute テーブル関連操作の詳細については、「MaxCompute テーブルの作成と管理」をご参照ください。
テーブル作成のエントリポイントに移動します。
[DataStudio] ページで、データ同期 フェーズで作成した [WorkShop] ワークフローを開きます。 [MaxCompute] を右クリックし、[テーブルの作成] を選択します。
MaxCompute テーブルのスキーマを定義します。
[テーブルの作成] ダイアログボックスで、テーブル名を入力し、[作成] をクリックします。 たとえば、
dwd_log_info_di_odps、dws_user_info_all_di_odps、ads_user_info_1d_odpsという名前の 3 つのテーブルを作成する必要があります。 次に、[DDL] タブに移動し、CREATE TABLE ステートメントを実行してテーブルを作成します。 前述のテーブルを作成するために使用されるステートメントは、以下のコンテンツで確認できます。テーブルを計算エンジンにコミットします。
テーブルのスキーマを定義した後、各テーブルの構成タブで [開発環境にコミット] と [本番環境にコミット] を順番にクリックします。 開発環境と本番環境の MaxCompute プロジェクトでは、システムは構成に基づいて MaxCompute プロジェクトに関連する物理テーブルを作成します。
ワークスペースの開発環境にテーブルをコミットすると、テーブルは開発環境の MaxCompute プロジェクトに作成されます。
ワークスペースの本番環境にテーブルをコミットすると、テーブルは本番環境の MaxCompute プロジェクトに作成されます。
説明ベーシックモードのワークスペースを使用する場合は、本番環境にのみテーブルをコミットする必要があります。 ベーシックモードのワークスペースとスタンダードモードのワークスペースの詳細については、「ベーシックモードのワークスペースとスタンダードモードのワークスペースの違い」をご参照ください。
DataWorks と MaxCompute の関係、およびさまざまな環境における MaxCompute 計算エンジンの詳細については、「DataWorks での MaxCompute ノード開発の使用上の注意」をご参照ください。
dwd_log_info_di_odps テーブルを作成する
dwd_log_info_di_odps テーブルをダブルクリックします。 表示されるテーブル構成タブで、[DDL] をクリックし、次の CREATE TABLE ステートメントを入力します。
CREATE TABLE IF NOT EXISTS dwd_log_info_di_odps (
ip STRING COMMENT 'リクエストを送信するために使用されるクライアントの IP アドレス',
uid STRING COMMENT 'ユーザーの ID',
time STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間',
status STRING COMMENT 'サーバーから返される状態コード',
bytes STRING COMMENT 'クライアントに返されるバイト数',
region STRING COMMENT 'IP アドレスに基づいて取得されるリージョン',
method STRING COMMENT 'HTTP リクエストのタイプ',
url STRING COMMENT 'URL',
protocol STRING COMMENT 'HTTP のバージョン番号',
referer STRING COMMENT 'ソース URL',
device STRING COMMENT '端末タイプ',
identity STRING COMMENT 'アクセス タイプ。クローラー、フィード、ユーザー、または不明の場合があります。'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;dws_user_info_all_di_odps テーブルを作成する
dws_user_info_all_di_odps テーブルをダブルクリックします。 表示されるテーブル構成タブで、[DDL] をクリックし、次の CREATE TABLE ステートメントを入力します。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_odps (
uid STRING COMMENT 'ユーザーの ID',
gender STRING COMMENT '性別',
age_range STRING COMMENT 'ユーザーの年齢層',
zodiac STRING COMMENT '星座',
region STRING COMMENT 'IP アドレスに基づいて取得されるリージョン',
device STRING COMMENT '端末タイプ',
identity STRING COMMENT 'アクセス タイプ。クローラー、フィード、ユーザー、または不明の場合があります。',
method STRING COMMENT 'HTTP リクエストのタイプ',
url STRING COMMENT 'URL',
referer STRING COMMENT 'ソース URL',
time STRING COMMENT 'yyyymmddhh:mi:ss 形式の時間'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;ads_user_info_1d_odps テーブルを作成する
ads_user_info_1d_odps テーブルをダブルクリックします。 表示されるテーブル構成タブで、[DDL] をクリックし、次の CREATE TABLE ステートメントを入力します。
CREATE TABLE IF NOT EXISTS ads_user_info_1d_odps (
uid STRING COMMENT 'ユーザーの ID',
region STRING COMMENT 'IP アドレスに基づいて取得されるリージョン',
device STRING COMMENT '端末タイプ',
pv BIGINT COMMENT 'ページビュー',
gender STRING COMMENT '性別',
age_range STRING COMMENT 'ユーザーの年齢層',
zodiac STRING COMMENT '星座'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14; getregion という名前の関数を作成する
実験のログデータの構造 をテーブルのデータに変換するには、関数などのメソッドを使用できます。 この例では、IP アドレスをリージョンに変換するために使用される関数に必要なリソースが提供されています。 DataWorks に関数を登録する前に、リソースをオンプレミスマシンにダウンロードし、ワークスペースにアップロードするだけです。
この関数で使用される IP アドレスリソースは、このチュートリアルでのみ使用できます。 正式なビジネスシナリオで IP アドレスと地理的な場所のマッピングを実装する必要がある場合は、専門の IP アドレス Web サイトから専門の IP アドレス変換サービスを探す必要があります。
リソースファイル ip2region.jar をアップロードする
ip2region.jar ファイルをダウンロードします。
説明ip2region.jarファイルは、このチュートリアルでのみ使用できます。[DataStudio] ページで、[WorkShop] ワークフローを開きます。 [MaxCompute] を右クリックし、 を選択します。
[アップロード] をクリックし、オンプレミスマシンにダウンロードされた ip2region.jar ファイルを選択して、[開く] をクリックします。
説明[MaxCompute にアップロード] を選択します。
リソース名は、アップロードされたファイルの名前と異なっていてもかまいません。
上部のツールバーの
 アイコンをクリックして、リソースを開発環境の MaxCompute プロジェクトにコミットします。
アイコンをクリックして、リソースを開発環境の MaxCompute プロジェクトにコミットします。
関数 getregion を登録する
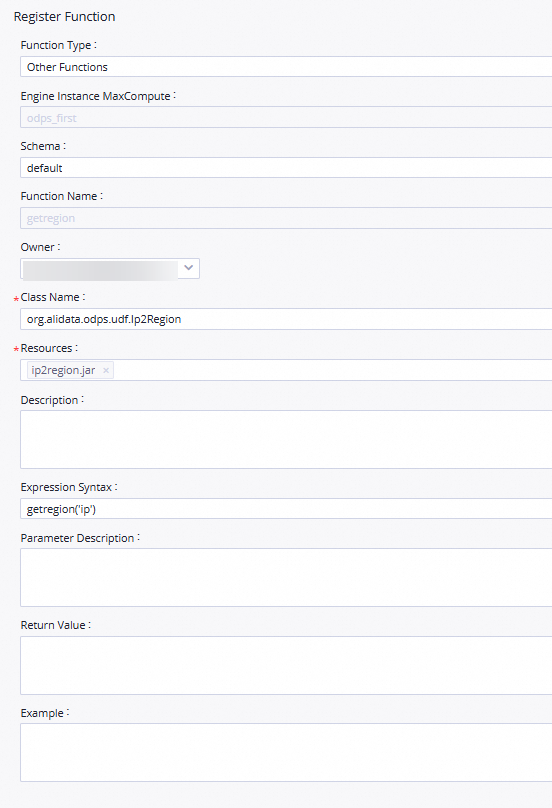
関数登録ページに移動します。
[DataStudio] ページで、WorkShop ワークフローを開き、[MaxCompute] を右クリックして、[関数の作成] を選択します。
関数名を入力します。
[関数の作成] ダイアログボックスで、[名前] パラメーターを
getregionに設定し、[作成] をクリックします。表示される構成タブの [関数の登録] セクションで、次の表に示すパラメーターを設定します。
パラメーター
説明
[関数タイプ]
関数のタイプ。
[MaxCompute エンジンインスタンス]
MaxCompute 計算エンジン。 このパラメーターの値は変更できません。
[関数名]
関数の名前。
[所有者]
関数の所有者。
[クラス名]
パラメーターを
org.alidata.odps.udf.Ip2Regionに設定します。[リソース]
パラメーターを
ip2region.jarに設定します。[説明]
パラメーターを「IP アドレスに基づくリージョン変換」に設定します。
[式の構文]
パラメーターを
getregion('ip')に設定します。[パラメーターの説明]
パラメーターを「IP アドレス」に設定します。
上部のツールバーの
アイコンをクリックして、関数を開発環境の計算エンジンにコミットします。
MaxCompute ノードを設定する
この例では、ODPS SQL ノードを使用して、各レイヤーのデータ処理ロジックを実装する必要があります。 異なるレイヤーの ODPS SQL ノード間には、強力なデータ系列が存在します。 データ同期フェーズでは、同期ノードの出力テーブルが、同期ノードの [プロパティ] タブの [出力] セクションに手動で追加されています。 そのため、この例でデータ処理に使用される ODPS SQL ノードのスケジューリング依存関係は、自動解析 機能を使用して、データ系列に基づいて自動的に設定できます。
dwd_log_info_di_odps ノードを設定する
ワークフローの構成タブで、dwd_log_info_di_odps ノードをダブルクリックします。 ノードの構成タブで、作成された関数を使用して祖先テーブル ods_raw_log_d_odps のフィールドを処理し、処理されたデータを dwd_log_info_di_odps テーブルに書き込む SQL コードを入力します。 データの処理方法の詳細については、「付録: データ処理の例」をご参照ください。
ノードコードを編集します。
-- シナリオ: 次の SQL ステートメントは、getregion 関数を使用して生のログデータの IP アドレスを解析し、正規表現などのメソッドを使用して解析されたデータを分析可能なフィールドに分割し、フィールドを dwd_log_info_di_odps テーブルに書き込みます。 -- この例では、IP アドレスをリージョンに変換するために使用される getregion 関数が準備されています。 -- 注: -- 1. DataWorks ノードで関数を使用する前に、関数の登録に必要なリソースを DataWorks にアップロードし、リソースを使用して関数を視覚的に登録する必要があります。 -- この例では、getregion 関数を登録するために使用されるリソースは ip2region.jar です。 -- 2. DataWorks でノードのスケジューリングパラメーターを設定して、スケジューリングシナリオで毎日増分データを目的のテーブルの関連パーティションに書き込むことができます。 -- 実際の開発シナリオでは、ノードのコードで ${変数名} 形式で変数を定義し、ノードの構成タブの [プロパティ] タブで変数にスケジューリングパラメーターを割り当てることができます。 これにより、スケジューリングパラメーターの値は、スケジューリングパラメーターの構成に基づいてノードコードで動的に置き換えることができます。 INSERT OVERWRITE TABLE dwd_log_info_di_odps PARTITION (dt='${bizdate}') SELECT ip , uid , time , status , bytes , getregion(ip) AS region -- UDF を使用して IP アドレスに基づいてリージョンを取得します。 , regexp_substr(request, '(^[^ ]+ )') AS method -- 正規表現を使用してリクエストから 3 つのフィールドを抽出します。 , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- 正規表現を使用してリファラーを明確にし、より正確な URL を取得します。 , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' -- agent パラメーターに基づいて端末情報とアクセス タイプを取得します。 WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_odps WHERE dt ='${bizdate}' ) a;スケジューリングプロパティを設定します。
ノードの構成タブで、右側のナビゲーションウィンドウの [プロパティ] をクリックします。 [プロパティ] タブで、ノードのスケジューリングプロパティと基本情報を設定します。 詳細については、「ノードのスケジューリングプロパティ」をご参照ください。 パラメーターについて、次の表で説明します。
セクション
説明
図
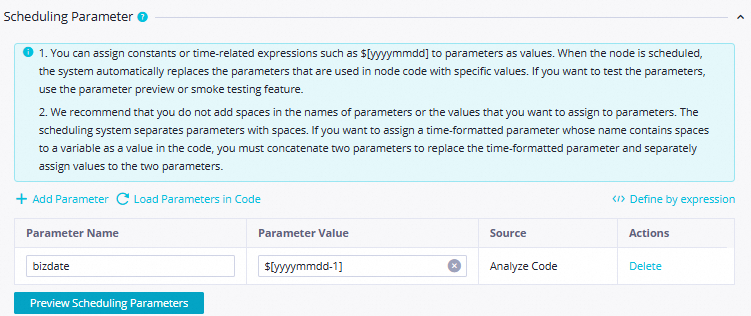
[スケジューリングパラメーター]
[スケジューリングパラメーター] セクションで次のパラメーターを設定します。
[パラメーター名]: 値を
bizdateに設定します。[パラメーター値]: 値を
$[yyyymmdd-1]に設定します。
[スケジュール]
[スケジューリングサイクル]: 値を
日に設定します。[スケジュールされた時間]: 値を
00:30に設定します。[再実行]: 値を「実行状態に関係なく許可」に設定します。
その他のパラメーターにはデフォルト値を使用します。
説明現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローのゼロ負荷ノード workshop_start のスケジュールされた時間によって決まります。 現在のノードは、毎日 00:30 以後に実行されるようにスケジュールされています。

[リソースグループ]
環境の準備 フェーズで購入したサーバーレスリソースグループを選択します。

[依存関係]
[ノードのコミット前にコードから自動的に解析] を [はい] に設定すると、
ods_raw_log_d_odpsテーブルを生成するods_raw_log_d_odpsノードをdwd_log_info_di_odpsノードの祖先ノードとしてシステムが設定できるようになります。dwd_log_info_di_odpsテーブルは、dwd_log_info_di_odps ノードの出力として使用されます。 これにより、これらのノードが dwd_log_info_di_odps ノードによって生成されたテーブルデータにクエリを実行するときに、dwd_log_info_di_odps ノードを他のノードの祖先ノードとして自動的に設定できます。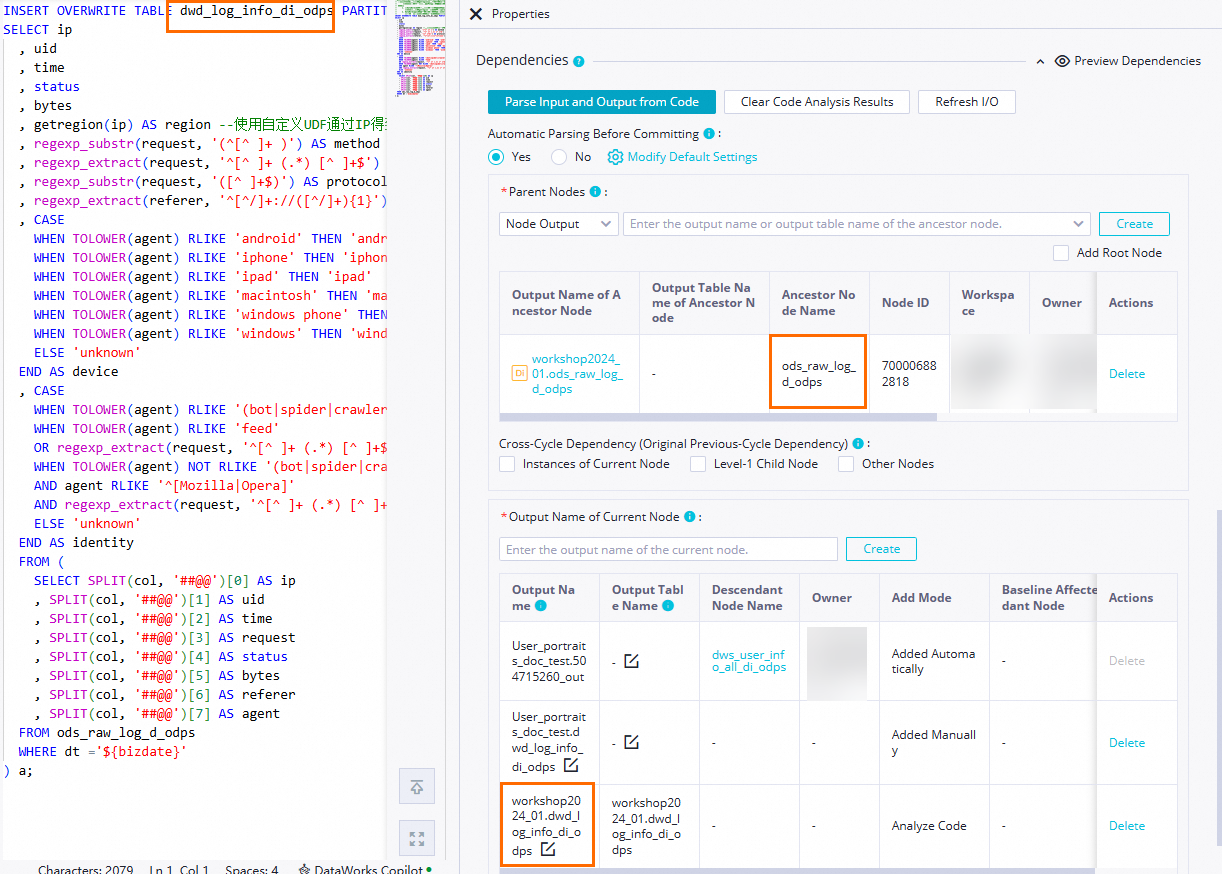 説明
説明現在のノードの祖先ノードを決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析されます。 出力ノード名は、[祖先ノードの出力の名前] として使用されます。現在のノードの出力を決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析され、ダウンストリームノードに出力されます。この例では、ビジネス要件に基づいて、その他に必要な構成項目を設定できます。 設定が完了したら、ノードの構成タブの上部にあるツールバーの
 アイコンをクリックして、ノードの設定を保存します。
アイコンをクリックして、ノードの設定を保存します。
dws_user_info_all_di_odps ノードを設定する
ワークフローの構成タブで、dws_user_info_all_di_odps ノードをダブルクリックします。 ノードの構成タブで、dwd_log_info_di_odps 祖先テーブルと ods_user_info_d_odps 祖先テーブルをマージし、マージされたデータを dws_user_info_all_di_odps テーブルに書き込む SQL コードを入力します。
ノードコードを編集します。
-- シナリオ: dwd_log_info_di_odps テーブル内の処理済みログデータと ods_user_info_d_odps テーブル内のユーザーの基本情報を集計し、集計されたデータを dws_user_info_all_di_odps テーブルに書き込みます。 -- 注: DataWorks でノードのスケジューリングパラメーターを設定して、スケジューリングシナリオで毎日増分データを目的のテーブルの関連パーティションに書き込むことができます。 -- 実際の開発シナリオでは、${変数名} 形式でノードのコードに変数を定義し、ノードの構成タブの [プロパティ] タブで変数にスケジューリングパラメーターを割り当てることができます。 これにより、スケジューリングパラメーターの値は、スケジューリングパラメーターの構成に基づいてノードコードで動的に置き換えることができます。 INSERT OVERWRITE TABLE dws_user_info_all_di_odps PARTITION (dt='${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM dwd_log_info_di_odps WHERE dt = '${bizdate}' ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d_odps WHERE dt = '${bizdate}' ) b ON a.uid = b.uid;スケジューリングプロパティを設定します。
ノードの構成タブで、右側のナビゲーションウィンドウの [プロパティ] をクリックします。 [プロパティ] タブで、ノードのスケジューリングプロパティと基本情報を設定します。 詳細については、「ノードのスケジューリングプロパティ」をご参照ください。 パラメーターについて、次の表で説明します。
セクション
説明
図
[スケジューリングパラメーター]
[スケジューリングパラメーター] セクションで次のパラメーターを設定します。
[パラメーター名]: 値を
bizdateに設定します。[パラメーター値]: 値を
$[yyyymmdd-1]に設定します。
[スケジュール]
[スケジューリングサイクル]: 値を
日に設定します。[スケジュールされた時間]: 値を
00:30に設定します。[再実行]: 値を「実行状態に関係なく許可」に設定します。
その他のパラメーターにはデフォルト値を使用します。
説明現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローのゼロ負荷ノード workshop_start のスケジュールされた時間によって決まります。 現在のノードは、毎日 00:30 以後に実行されるようにスケジュールされています。
[リソースグループ]
環境の準備 フェーズで購入したサーバーレスリソースグループを選択します。
[依存関係]
[ノードのコミット前にコードから自動的に解析] を [はい] に設定すると、
dwd_log_info_di_odpsテーブルとods_user_info_d_odpsテーブルを生成するdwd_log_info_di_odpsノードとods_user_info_d_odpsノードをdws_user_info_all_di_odpsノードの祖先ノードとしてシステムが設定できるようになります。dws_user_info_all_di_odpsテーブルは、dws_user_info_all_di_odps ノードの出力として使用されます。 これにより、これらのノードが dws_user_info_all_di_odps ノードによって生成されたテーブルデータにクエリを実行するときに、dws_user_info_all_di_odps ノードを他のノードの祖先ノードとして自動的に設定できます。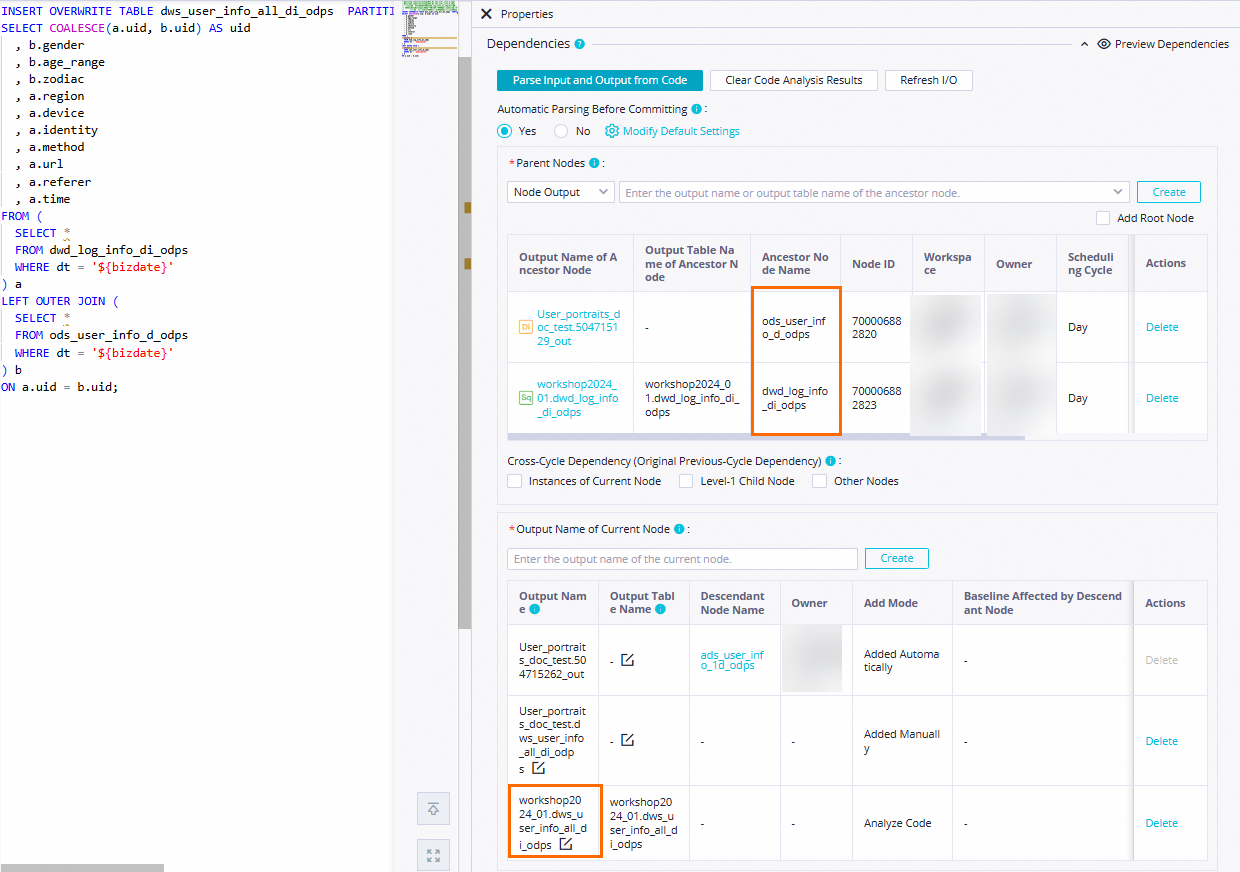 説明
説明現在のノードの祖先ノードを決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析されます。 出力ノード名は、[祖先ノードの出力の名前] として使用されます。現在のノードの出力を決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析され、ダウンストリームノードに出力されます。この例では、ビジネス要件に基づいて、その他に必要な構成項目を設定できます。 設定が完了したら、ノードの構成タブの上部にあるツールバーの
アイコンをクリックして、ノードの設定を保存します。
ads_user_info_1d_odps ノードを設定する
ワークフローの構成タブで、ads_user_info_1d_odps ノードをダブルクリックします。 ノードの構成タブで、 dws_user_info_all_di_odps 祖先テーブルを処理し、処理されたデータを ads_user_info_1d_odps テーブルに書き込む SQL コードを入力します。
ノードコードを編集します。
-- シナリオ: 次の SQL ステートメントは、ユーザーアクセス情報を格納するために使用される dws_user_info_all_di_odps ワイドテーブルを、ユーザーの基本プロファイルデータを格納するために使用される ads_user_info_1d_odps テーブルにさらに処理するために使用されます。 -- 注: DataWorks でノードのスケジューリングパラメーターを設定して、スケジューリングシナリオで毎日増分データを目的のテーブルの関連パーティションに書き込むことができます。 -- 実際の開発シナリオでは、${変数名} 形式でノードのコードに変数を定義し、ノードの構成タブの [プロパティ] タブで変数にスケジューリングパラメーターを割り当てることができます。 これにより、スケジューリングパラメーターの値は、スケジューリングパラメーターの構成に基づいてノードコードで動的に置き換えることができます。 INSERT OVERWRITE TABLE ads_user_info_1d_odps PARTITION (dt='${bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_odps WHERE dt = '${bizdate}' GROUP BY uid;スケジューリングプロパティを設定します。
ノードの構成タブで、右側のナビゲーションウィンドウの [プロパティ] をクリックします。 [プロパティ] タブで、ノードのスケジューリングプロパティと基本情報を設定します。 詳細については、「ノードのスケジューリングプロパティ」をご参照ください。 パラメーターについて、次の表で説明します。
セクション
説明
図
[スケジューリングパラメーター]
[スケジューリングパラメーター] セクションで次のパラメーターを設定します。
[パラメーター名]: 値を
bizdateに設定します。[パラメーター値]: 値を
$[yyyymmdd-1]に設定します。
[スケジュール]
[スケジューリングサイクル]: 値を
日に設定します。[スケジュールされた時間]: 値を
00:30に設定します。[再実行]: 値を「実行状態に関係なく許可」に設定します。
その他のパラメーターにはデフォルト値を使用します。
説明現在のノードが毎日実行されるようにスケジュールされる時間は、ワークフローのゼロ負荷ノード workshop_start のスケジュールされた時間によって決まります。 現在のノードは、毎日 00:30 以後に実行されるようにスケジュールされています。
[リソースグループ]
環境の準備 フェーズで購入したサーバーレスリソースグループを選択します。
[依存関係]
[ノードのコミット前にコードから自動的に解析] を [はい] に設定すると、
dws_user_info_all_1d_odpsテーブルを生成するdws_user_info_all_1d_odpsノードをads_user_info_1d_odpsノードの祖先ノードとしてシステムが設定できるようになります。 ads_user_info_1d テーブルは、ads_user_info_1d ノードの出力として使用されます。 これにより、これらのノードが ads_user_info_1d ノードによって生成されたテーブルデータにクエリを実行するときに、ads_user_info_1d ノードを他のノードの祖先ノードとして自動的に設定できます。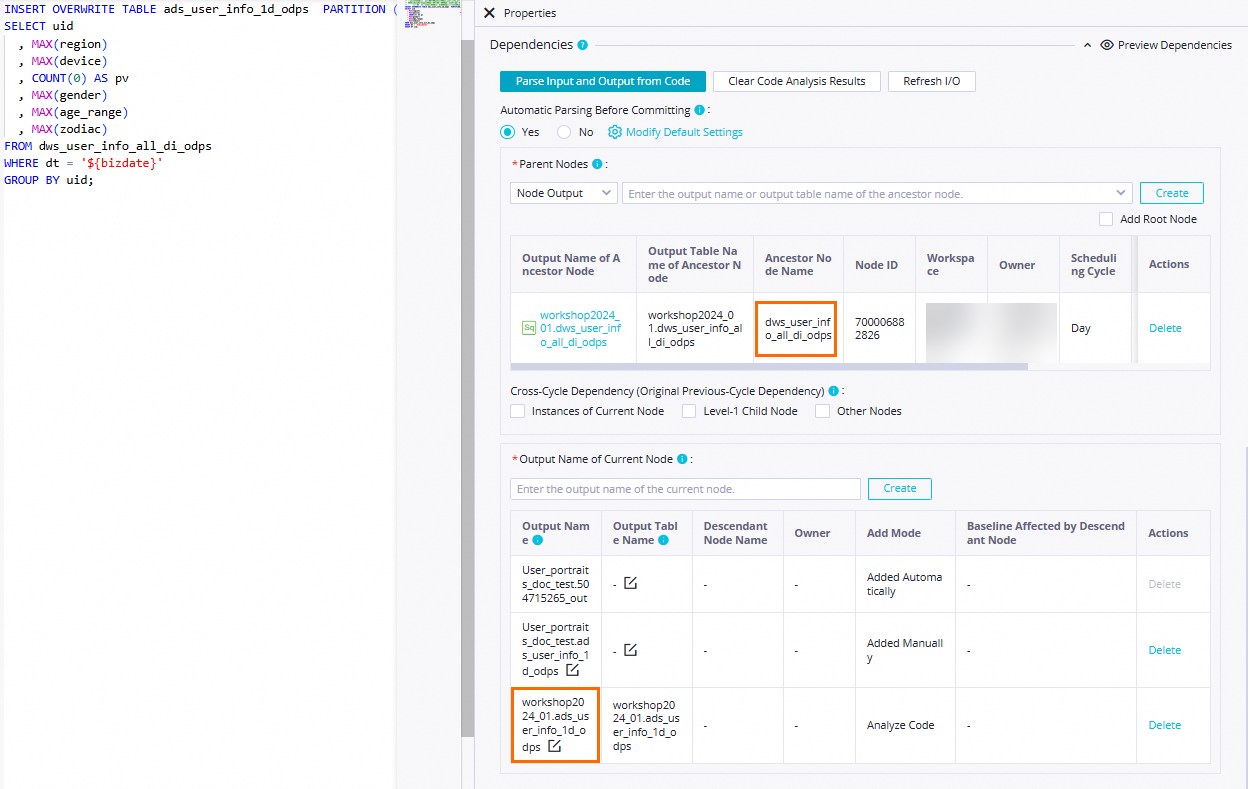 説明
説明現在のノードの祖先ノードを決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析されます。 出力ノード名は、[祖先ノードの出力の名前] として使用されます。現在のノードの出力を決定する: [コードから入力と出力を解析] をクリックすると、コード内のテーブル名が
本番環境の MaxCompute プロジェクト名.テーブル名形式で名前が付けられた出力ノードに解析され、ダウンストリームノードに出力されます。この例では、ビジネス要件に基づいて、その他に必要な構成項目を設定できます。 設定が完了したら、ノードの構成タブの上部にあるツールバーの
アイコンをクリックして、ノードの設定を保存します。
ステップ 3: ワークフローを実行する
ワークフローを実行する
[DataStudio] ページで、[ビジネスフロー] の下の
User profile analysis_MaxComputeワークフローをダブルクリックします。ワークフローの構成タブで、トップツールバーにある アイコンをクリックして、ノード間のスケジューリング依存関係に基づいてワークフロー内のノードを実行します。
アイコンをクリックして、ノード間のスケジューリング依存関係に基づいてワークフロー内のノードを実行します。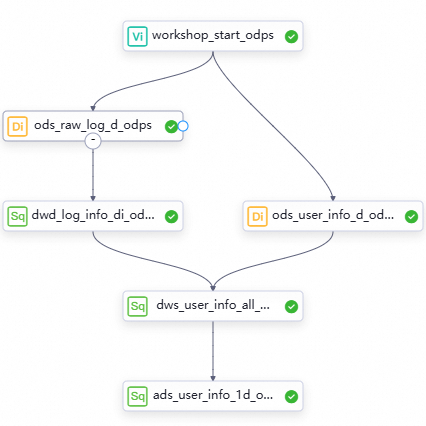
ステータスを確認します。
ノードステータスの表示: ノードが
 状態の場合、同期プロセスは正常です。
状態の場合、同期プロセスは正常です。ノード実行ログの表示: ノードを右クリックし、[ログの表示] を選択して、開発環境におけるユーザー プロファイル分析プロセス全体の各ノードのログを表示します。
同期結果を表示する
ワークフロー内のすべてのノードが ![]() 状態になったら、最終的に処理された結果テーブルをクエリできます。
状態になったら、最終的に処理された結果テーブルをクエリできます。
[DataStudio] ページの左側のナビゲーション ウィンドウで、
 をクリックします。
をクリックします。[アドホッククエリ] ウィンドウで、[アドホッククエリ] を右クリックし、[ノードの作成] > [ODPS SQL] を選択します。
ODPS SQL ノードで次の SQL 文を実行して、この例の最終結果テーブルを確認します。
// 読み取りおよび書き込み操作を実行するデータのデータ タイムスタンプを、パーティションのフィルター条件として指定する必要があります。たとえば、ノードが 2023 年 2 月 22 日に実行されるようにスケジュールされている場合、ノードのデータ タイムスタンプは 20230221 であり、これはノードのスケジュール時刻よりも 1 日前です。 select count(*) from ads_user_info_1d_odps where dt='Data timestamp';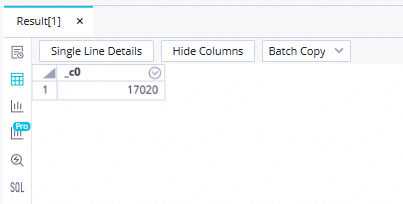 説明
説明この例では、ノードは開発環境である [DataStudio] で実行されます。したがって、データは、デフォルトで開発環境のワークスペースに関連付けられている MaxCompute プロジェクト workshop2024_01_dev 内の指定されたテーブルに書き込まれます。
ステップ 4: ワークフローをデプロイする
ノードは、本番環境にデプロイされた後にのみ自動的にスケジュールおよび実行できます。詳細については、以下のコンテンツをご参照ください。
ワークフローを開発環境にコミットする
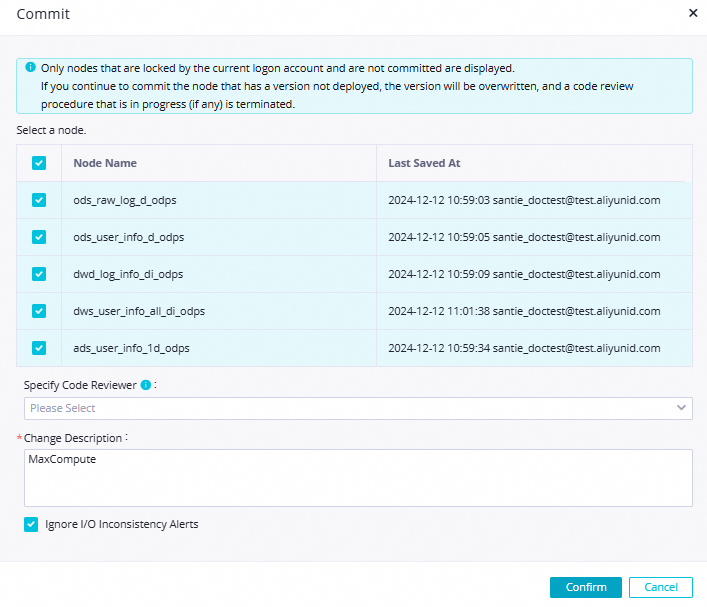
ワークフローの構成タブの上部ツールバーにある  アイコンをクリックして、ワークフロー内のすべてのノードをコミットします。[確認] ダイアログボックスで、次の図に示すようにパラメーターを構成し、 [確認] をクリックします。
アイコンをクリックして、ワークフロー内のすべてのノードをコミットします。[確認] ダイアログボックスで、次の図に示すようにパラメーターを構成し、 [確認] をクリックします。
ワークフローを本番環境にコミットする
ワークフローをコミットすると、ワークフロー内のノードは開発環境に入ります。開発環境のノードは自動的にスケジュールされないため、構成済みのノードを本番環境にデプロイする必要があります。
ワークフローの構成タブの上部ツールバーにある
 アイコンをクリックします。または、DataStudio 内のいずれかのノードの構成タブに移動し、右上隅にある [デプロイ] アイコンをクリックして、[デプロイタスクの作成] ページに移動します。
アイコンをクリックします。または、DataStudio 内のいずれかのノードの構成タブに移動し、右上隅にある [デプロイ] アイコンをクリックして、[デプロイタスクの作成] ページに移動します。目的のノードを同時にデプロイします。デプロイされるコンテンツには、ワークフローに関連するリソースと関数が含まれます。
ステップ 5: ワークフローで O&M およびスケジューリング操作を実行する
実際の開発シナリオでは、本番環境のデータバックフィル機能を使用して、過去の期間または将来の期間のデータをバックフィルできます。 このトピックでは、データバックフィルインスタンスで O&M およびスケジューリング操作を実行する方法について説明します。 Operation Center の機能の詳細については、「Operation Center」をご参照ください。
Operation Center ページに移動します。
ノードがデプロイされた後、ノードの構成タブの右上隅にある [Operation Center] をクリックします。
DataStudio ページの上部にある [Operation Center] をクリックして、[Operation Center] ページに移動することもできます。
自動トリガーされたタスクのデータをバックフィルします。
左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、
workshop_start_odpsワークフローのルートノードをクリックします。workshop_start_odpsノードを右クリックし、 を選択します。workshop_start_odpsノードのすべての子孫ノードを選択し、データタイムスタンプを入力して、[OK] をクリックします。 [パッチデータ] ページが表示されます。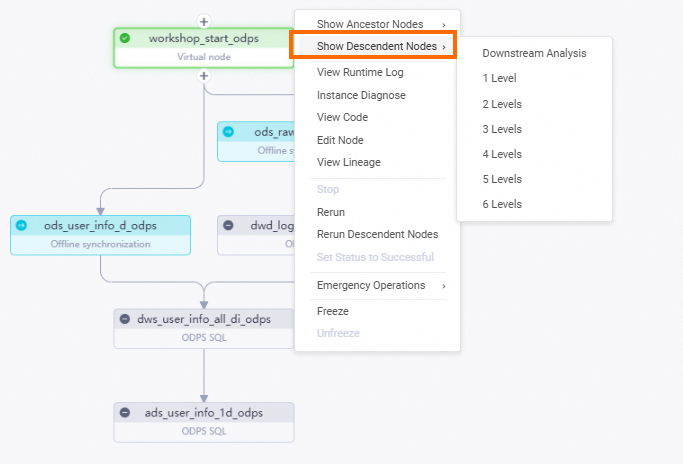
すべての SQL ノードが正常に実行されるまで [更新] をクリックします。
次の手順
ノードをデプロイした後、ワークフロー全体が完了します。作成されたテーブルの詳細を表示し、関連テーブルのデータを使用し、データ品質モニタリングを設定できます。詳細については、「データを管理する」、「API を使用してデータサービスを提供する」、「ダッシュボードでデータを視覚化する」、および「データ品質を監視する」をご参照ください。
付録:データ処理例
データ処理前
58.246.10.82##@@2d24d94f14784##@@2014-02-12 13:12:25##@@GET /wp-content/themes/inove/img/feeds.gif HTTP/1.1##@@200##@@2572##@@http://coolshell.cn/articles/10975.html##@@Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36データ処理後
